java链表详解 理论+代码+图示
1、定义
链表是一种物理存储结构上非连续存储结构,数据元素的逻辑顺序是通过链表中的引用链接次序实现的。(即链表是一个个节点组成的,这些节点物理上不连续,但逻辑上连续)
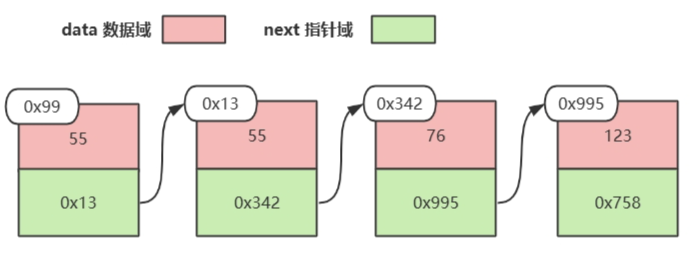
一个节点就是一个Node对象。
2、链表结构
单向、双向;
带头、不带头;
循环、非循环;
以上情况组合起来就有8种链表结构
(双向) 单向、带头、循环
(双向) 单向、带头、不循环
(双向) 单向、不带头、循环
(双向) 单向、不带头、不循环
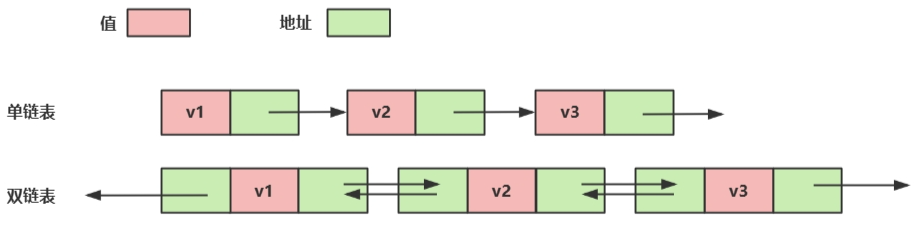
2.1单向或者双向
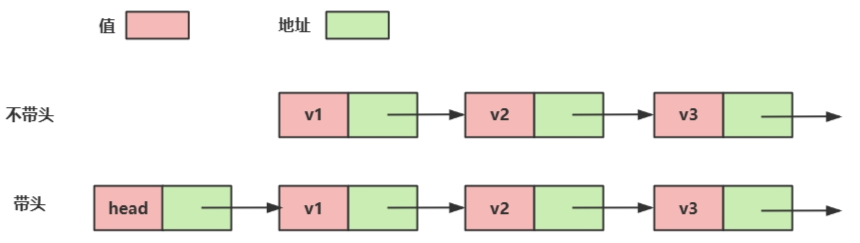
2.2带头或者不带头
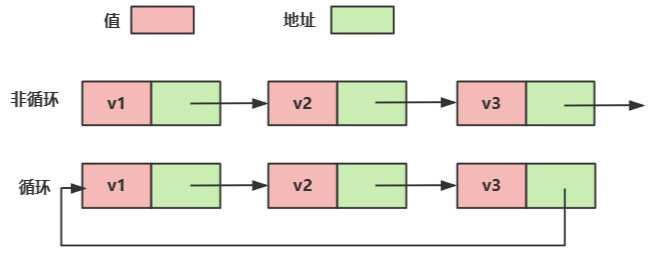
2.3循环或者非循环
2.4常用
虽然有这么多链表结构,但实际我们最常用的还是两种结构: 无头单向非循环链表、带头双向循环链表
2.4.1无头单向非循环链表(单链表):

结构简单,一般不会单独用来存储数据。实际中更多的是作为其他数据结构的子结构,如哈希桶,图的邻接表等。另外这种结构在笔试面试中很多。 第一个节点称之为头节点,最后一个节点称之尾节点,单向链表的尾节点的next域为null,因为尾节点不再指向任何一个节点。
2.4.2带头单向非循环链表

用一个专门的节点作为头节点,这个节点没有data数据域,只有next指针域,这个指针用来存储第一个数据节点的地址,且这个头节点是无法删除的,他就像一个哨兵,指向我们第一个数据节点。
2.4.2带头双循环链表:

结构最复杂,一般用在单独存储数据。双循环链表的所有后继指针形成了一个环,所有前趋指针也形成了一个环 (一共两个环)。这样的话,给定一个数据结点,无论访问链表的后继结点还是前趋结点,都非常灵活和方便。 3、单链表代码实现
※注意事项:
①单链表中头节点很烦人,不论是插入还是删除均需考虑头节点,因为其没有前驱。
②所有的点操作(".")均需注意空指针情况
自定义链表对象
class ListNode {
public int val;//存储数据的值
public ListNode next;//存储下一个节点的地址
//这里为什么使用Node引用,单链表的所有节点都是Node类的对象
//构造函数,可以直接创建有值的节点
public ListNode(int val) {
//不知道下一个节点位置,只需要val
this.val = val;
}
//方便输出查看结果,写一个toString
@Override
public String toString() {
return "ListNode{" +
"val=" + val +
", next=" + next +
'}';
}
}
ListNode node1=new ListNode(); //创建一个新节点
node1.val=88; //值为88,地址为空
ListNode node2=new ListNode(7); //创建一个值为7的节点
node1.next=node2; //让第一个节点的next存储下一个节点的地址头插法
public static void addFirst(int[] arr){
ListNode head=null;
for (int i = 0; i < arr.length; i++) {
ListNode node=new ListNode();
node.val=arr[i];
node.next=head;
head=node;
}
System.out.println(head);
}尾插法
//尾插法
public static void addLast(int[] arr){
//定义虚拟头指向链表的第一个节点
ListNode head=null;
for (int i = 0; i < arr.length; i++) {
//添加新节点
ListNode newnode = new ListNode(arr[i]);
//如果链表为空,头节点直接指向新节点
if (head == null) {
head = newnode;
} else { //链表不为空
//定义游标遍历链表,找到尾节点
ListNode cur = head;
while (cur.next != null) {
cur = cur.next;
}
//将新节点地址赋给尾节点的next域
cur.next = newnode;
}
}
输出一下这个链表
System.out.println(head);
}任意位置插入
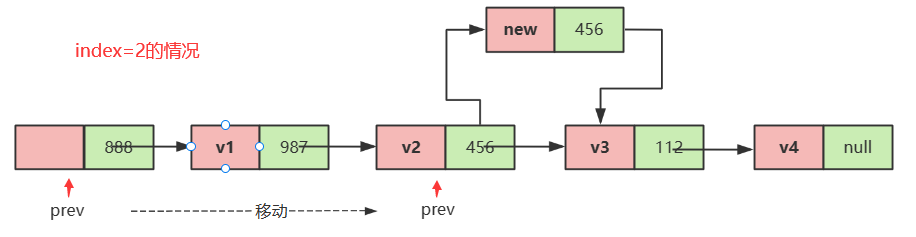
static int size=0;
public static void insert(int index,int val){
if(index<0 || index>size){
System.out.println("插入位置不合理");
return;
}
//如果链表为空
if (head==null){
//头插法
ListNode node=new ListNode(val);
node.next=head;
head=node;
}else {
ListNode newnode=new ListNode(val);
//从头开始遍历,到index的前驱
ListNode prev=head;
for (int i = 0; i < index-1; i++) {
prev=prev.next;
}
//先让新节点和后面的节点连接
newnode.next=prev.next;
//再让前驱与新节点连接
prev.next=newnode;
//添加节点,长度加一
size++;
}
System.out.println(head);
}单链表的头删
为了使用删除功能,我们统一把head写到外边。
头删逻辑很简单,直接让记录着头节点的head往后移动一个节点即可。
public static void removeFirst(){
if(head==null){
System.out.println("空链表");
}
head=head.next;
System.out.println(head);
}单链表的尾删
同样使用游标遍历整个链表,找到尾部节点,则让尾部节点的前一个节点的next域为空。
这里巧妙的运用了cur.next.next
public static void removeFirst(){
if(head==null){
System.out.println("空链表");
}
ListNode cur=head;
while (cur.next.next!=null){
cur=cur.next;
}
cur.next=null;
System.out.println(head);
}删除指定位置
public static void remove(int index){
if(head==null){
System.out.println("空链表");
return;
}
//定义游标遍历到目标前驱位置
ListNode pre=head;
for (int i = 0; i < index-1; i++) {
pre=pre.next;
}
//找到前驱位置后,将前驱位置的下一个的下一个赋值给前驱位置的next域(即目标位置的下一个节点地址赋值给前驱的next域)
cur.next=cur.next.next;
System.out.println(head);
}删除指定元素(第一个值为val的元素)
public static void remove(int val){
if(head==null){
System.out.println("空链表");
return;
}
//如果头节点的值就是所找的值,则使用头删法
if(head.val==val){
//头删
head=head.next;
System.out.println(head);
return;
}
//如果不是头节点,则开始遍历链表
ListNode pre=head;
//使用pre.next!=null遍历
//为什么不使用pre.next.val!=val作为条件遍历? --因为当val不存在在链表中时,会产生空指针的情况
while(pre.next!=null){
if(pre.next.val==val){
//找到的要删除节点
ListNode x=pre.next;
pre.next=x.next;
}
pre=pre.next;
}
//特殊条件,如果将链表遍历到最后也没找到这个值,则return
if (pre.next==null){
System.out.println("没有");
return;
}
System.out.println(head);
}删除所有的val值
如果只遍历一遍链表,时间复杂度时On。如果使用上边的方法,想要删掉重复的val值,有几个val则就需要遍历几遍,时间复杂度会非常大。 那么这么实现?
---引入两个变量pre和cur,也就是双指针,但是这两个指针是跟屁虫。
如图,初始状态下,pre的起点是head,二cur的起点是head.next。pre是cur的前一个节点。
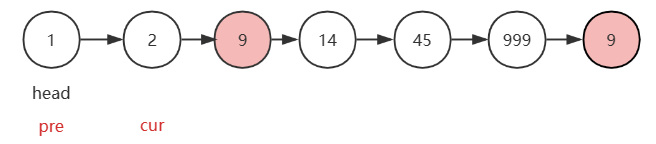
在遍历过程中,通过比较cur.val与val值来寻找关键节点。如果说cur.val != val,那么cur和pre指针均需要向前走。
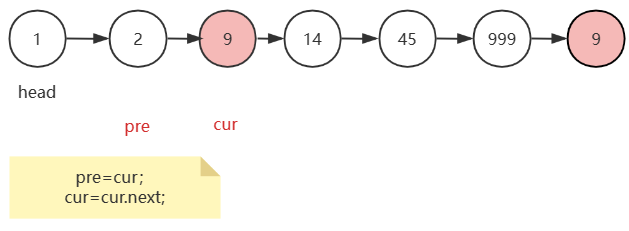
当走到下图这个位置,即cur到了我们需要删除的节点位置时,pre.next 直接指向 cur.next,此时cur所指的节点便成功删除。完成后接着让cur向后走。
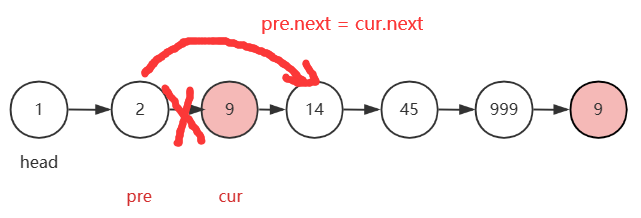
注意:当cur.val==val时,我们完成删除一个节点操作后,只需让cur向后走,不急着让pre跟上,因为可能出现两个连续的待删除元素。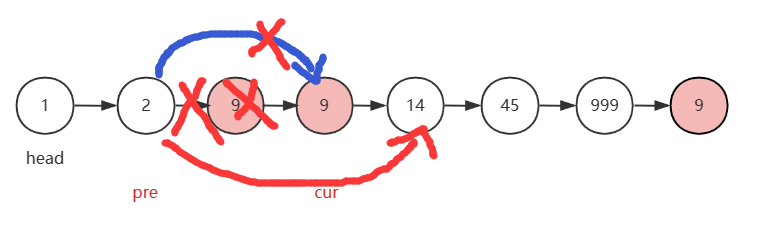
而且,如果pre跟上cur的话,原链表没办法重新链接
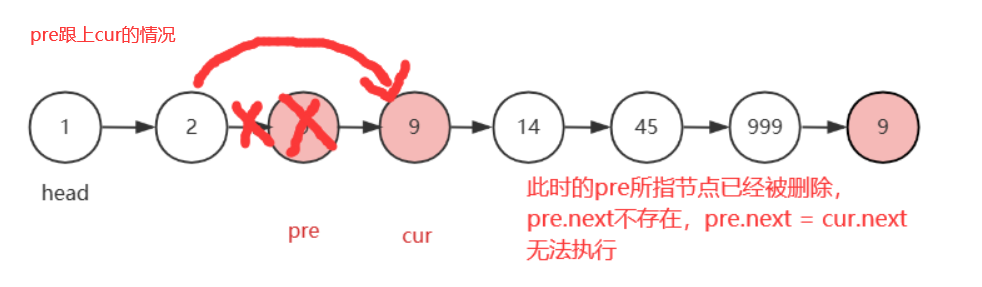
public static void removeAll(int val){
//特殊条件,链表为空
if(head==null){
return;
}
//定义两个跟屁虫游标
ListNode pre=head;
ListNode cur=head.next;
//如果第一个节点待删除,则头节点直接后移
if(head.val==val){
//头删
head=head.next;
}
//循环查找还有没有需要删除的节点
//注意这里的判定条件,如果你写cur.next!=null则无法删除最后一个元素,因为到最后一个元素会停止循环
//判定条件为cur!=null的话会将最后一个元素也进行判定
while (cur!=null){
//找到待删除节点,直接让pre.next指向cur.next,从而跳过待删节点
//cur=cur.next仅让cur后移,跟屁虫pre不紧跟cur,为了判断是否有待删节点连续出现的情况
if(cur.val==val){
pre.next=cur.next;
cur=cur.next;
}else{ //如果没有找到则两指针都向后移动
pre=cur;
cur=cur.next;
}
}
System.out.println(head);
}下一篇讲解双链表的代码实现~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号