读写分离 代码实操测试
需要基础:多数据源
==> 查看mybatisplus官方提供 https://baomidou.com/pages/a61e1b/#dynamic-datasource
1、引入pom依赖
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>dynamic-datasource-spring-boot-starter</artifactId>
<version>${version}</version>
</dependency>2、配置
spring:
datasource:
dynamic:
primary: master #设置默认的数据源或者数据源组,默认值即为master
strict: false #严格匹配数据源,默认false. true未匹配到指定数据源时抛异常,false使用默认数据源
datasource:
master:
url: jdbc:mysql://xx.xx.xx.xx:3306/dynamic
username: root
password: 123456
driver-class-name: com.mysql.jdbc.Driver # 3.2.0开始支持SPI可省略此配置
slave_1:
url: jdbc:mysql://xx.xx.xx.xx:3307/dynamic
username: root
password: 123456
driver-class-name: com.mysql.jdbc.Driver
slave_2:
url: ENC(xxxxx) # 内置加密,使用请查看详细文档
username: ENC(xxxxx)
password: ENC(xxxxx)
driver-class-name: com.mysql.jdbc.Driver
#......省略
#以上会配置一个默认库master,一个组slave下有两个子库slave_1,slave_2# 多主多从 纯粹多库(记得设置primary) 混合配置
spring: spring: spring:
datasource: datasource: datasource:
dynamic: dynamic: dynamic:
datasource: datasource: datasource:
master_1: mysql: master:
master_2: oracle: slave_1:
slave_1: sqlserver: slave_2:
slave_2: postgresql: oracle_1:
slave_3: h2: oracle_2:3、使用 @DS
@DS 可以注解在方法上或类上,同时存在就近原则 方法上注解 优先于 类上注解。
|
注解
|
结果
|
|
没有@DS
|
默认数据源
|
|
@DS("dsName")
|
dsName可以为组名也可以为具体某个库的名称
|
@Service
@DS("slave")
public class UserServiceImpl implements UserService {
@Autowired
private JdbcTemplate jdbcTemplate;
public List selectAll() {
return jdbcTemplate.queryForList("select * from user");
}
@Override
@DS("slave_1")
public List selectByCondition() {
return jdbcTemplate.queryForList("select * from user where age >10");
}
}4、配置好后写个测试
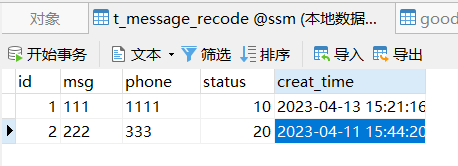
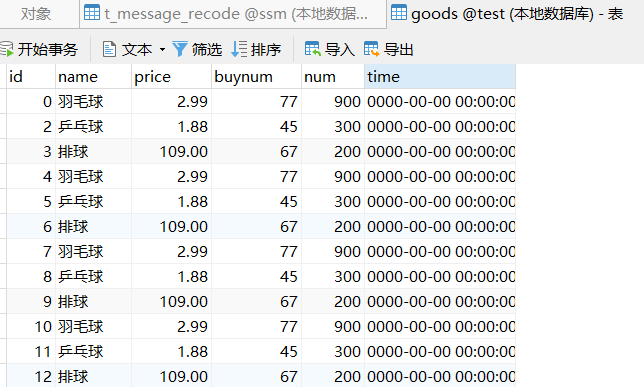
找两个数据库的两个表,我们想做的测试是将一个表的某条数据拿到插入另一张表中。
例如将 t_message_recode 表的 creat_time 数据插入到 goods表中。
先写两个PO
@Data
@TableName("t_message_recode")
public class SourcePO {
private Long id;
private Date creatTime;
}@Data
@TableName("goods")
public class TestPO {
private Long id;
private Date time;
}再写对应Mapper,注意加上@DS注解
@Mapper
@DS("master")
public interface SourceMapper extends BaseMapper<SourcePO> {
}@Mapper
@DS("slave_1")
public interface TestMapper extends BaseMapper<TestPO> {
}最后进行简单的逻辑编写测试
@RestController
public class TestController {
@Resource
private SourceMapper sourceMapper;
@Resource
private TestMapper testMapper;
/**
* 读写分离测试
* @return
*/
@GetMapping("test1")
public String aa(){
SourcePO sourcePO=sourceMapper.selectById(2L);
TestPO testPO=new TestPO();
testPO.setId(13L);
testPO.setTime(sourcePO.getCreatTime());
testMapper.insert(testPO);
return "success";
}
}测试结果:
日志表示添加数据源成功

浏览器输入地址返回“success”
数据库内已经添加数据
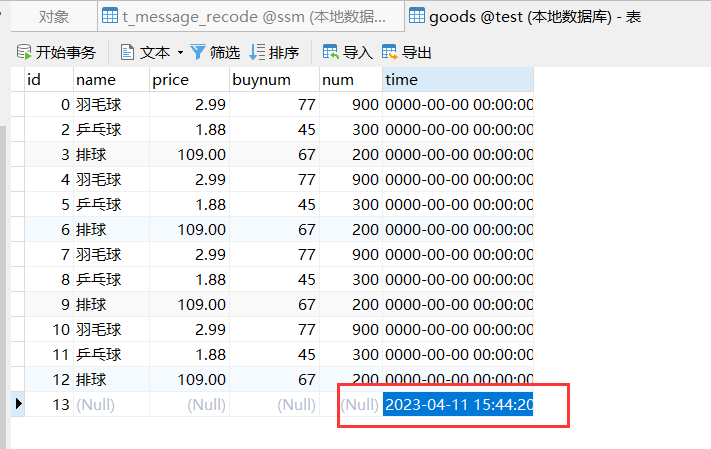
测试成功!
一主一从怎么实现读写分离
读 ---- 从从开始读,写 ---- 从master开始写 ----->怎么实现?
最简单方法:主对应maper里只写增删改操作,从对应的mapper里只写查询操作。
但是这种简单的方法肯定不对,这种重复性的动作应该交给代码来做。
我们可以想到什么?--->没学mybatis的时候怎么连接数据库? ---> jdbc
mybatis本质还是jdbc,只是sql不用像jdbc一样,写法复杂。
--->所以我们可以通过sql出现uptate、insert、delete时,就认为是增删改操作;出现select就认为是查询。 或者通过标签判断、<\update> ...
当检测到是查询就将数据源测换到从库,检测到是增删改就切换到主库。
数据源切换
mybatis-mate
高效简单的Mybatis原生插件多数据源扩展组件
- 注解 @Sharding
|
属性
|
类型
|
必须指定
|
默认值
|
描述
|
|
value
|
String
|
是
|
""
|
分库组名,空使用默认主数据源
|
|
strategy
|
Class
|
否
|
RandomShardingStrategy
|
分库&分表策略
|
- 配置
mybatis-mate:
sharding:
health: true # 健康检测
primary: mysql # 默认选择数据源
datasource:
mysql: # 数据库组
- key: node1
...
- key: node2
cluster: slave # 从库读写分离时候负责 sql 查询操作,主库 master 默认可以不写
...
postgres:
- key: node1 # 数据节点
...- 注解
@Mapper
@Sharding("mysql")
public interface UserMapper extends BaseMapper<User> {
@Sharding("postgres")
Long selectByUsername(String username);
}- 切换指定数据库节点
// 切换到 mysql 从库 node2 节点
ShardingKey.change("mysqlnode2");

 浙公网安备 33010602011771号
浙公网安备 33010602011771号