第一次个人作业
一.作业内容
1. 对源文件(*.txt,*.cpp,*.h,*.cs,*.html,*.js,*.java,*.py,*.php等)统计字符数、单词数、行数、词频,统计结果以指定格式输出到默认文件中,以及其他扩展功能,并能够快速地处理多个文件。
2. 使用性能测试工具进行分析,找到性能的瓶颈并改进
3. 对代码进行质量分析,消除所有警告
4. 设计10个测试样例用于测试,确保程序正常运行(例如:空文件,只包含一个词的文件,只有一行的文件,典型文件等等)
5. 使用Github进行代码管理
6. 撰写博客
要求
1. 统计文件的字符数
2. 统计文件的单词总数
3. 统计文件的总行数
4. 统计文件中各单词的出现次数
5. 对给定文件夹及其递归子文件夹下的所有文件进行统计
6. 统计两个单词(词组)在一起的频率,输出频率最高的前10个。
7. 在Linux系统下,进行性能分析,过程写到blog中(附加题)
二.需求分析
本次作业要求对任意文件夹下所有文件中的字符、单词、词组做统计分析,输出频率最高的10个词和词组,并将统计结果输出到result文件中。
还需满足以下几个方面:
1.单词、词组由甲方定义
2.能够在Linux和windows下运行;
3.对程序进行性能分析、优化;
4.博客的撰写、作业进程的记录与分析;
5.要求输出的准确度较高。
三、代码规范
根据个人的习惯和一些常用规范,制定了以下规范:
1. 变量的定义,尽量用英文名定义变量,若变量名太长,改用拼音缩写定义;
2.对于每个代码块,使用 Tab 缩进;
3.注释采用英文注释;
4.定义变量不同行,
5.相似的变量和函数,采用加后缀“z”来区分;
6.少使用全局变量;
7.采用C语言编程。
四、设计方案
依据作业内容和要求,设计步骤为文件路径获取;逐个打开文件;字符统计、行数统计、单词统计、词组统计;单词、词组排序;输出结果。
以下是具体的设计方案:
1、 文件路径获取
对于windows系统,采用_findfirst、_findnext、_findclose三个函数对文件名递归获取;
对于linux系统系统,采用opendir、 readdir 、closedir三个函数对文件名递归获取。
将获取文件名存入89.txt中,方便以后读取。
2、 逐个打开文件
用文件指针逐个打开文件;
用fgets()函数读取文件中每个字符。
3、 字符统计
采用判断条件 “ch >= 32&&ch <=126”,判断是否为字符,计数。
4、行数统计
采用判断条件 “ch==“\n””,判断是否为字符,计数。
对最后一行没有换行符的文件单独计数。
5、 单词统计
采用哈希表存储词组,方便单词插入和查询。
哈希函数:
对每个单词前四个字母设计哈希函数。
单词插入:
每读一个单词,由哈希函数计算,插入哈希表中。
单词比较:
对于相同单词,采用老师定义的单词标准,替换原来哈希表的单词,计数加一;
没有相同的单词,直接插入哈希表。
6、词组统计
重新遍历一遍哈希表,对于词组中每个单词,都有用单词哈希表中的单词替换;
单词采用字符串函数构成词组;
将词组插入词组哈希表中,判断准则与单词统计一致。
7、单词 词组排序
遍历一遍单词、词组哈希表,存入申请的数组中;
采用快速排序函数qsort()对单词、词组排序;
储存数组中的前十位作为结果。
8、输出结果
采用fprint()函数输入进“result.txt”文件中;
结果检查和测试。
五、自测结果及训练集结果
(1)自测集结果
本次采用了10个较典型自测集(单个小txt文本、单个大txt文本、非txt文件、多个文件等自测集)进行测试。
对于较小的文件,采用一个个数出来进行检验;
对于较大的文件,采用与其他同学对比进行检验;
检验结果为小文件与真实值完全一致;
大文件与其他同学top10数据完全一致,字符数、行数会有微小差别,原因可能是定义不同。
限于篇幅,给出一个典型文件的结果,其他结果读者可运行后面的整体代码自测。
新建文件夹.txt
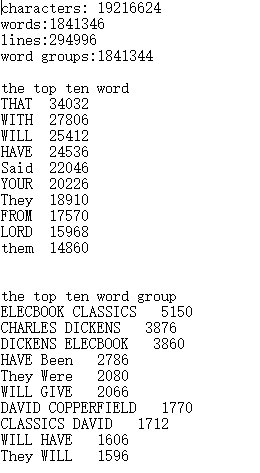
(2)训练集结果
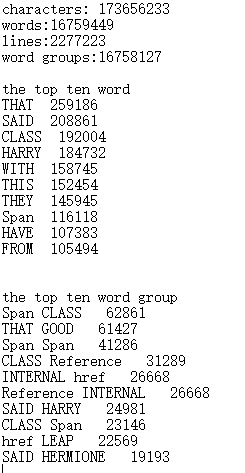
对于助教发布的newsample训练集,测试结果如下:
官方结果如下:
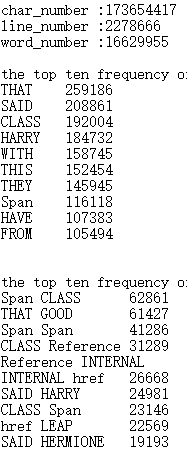
通过比较可以看出,字符数、行数、单词数误差在0.5%以内,原因可能是定义不同;
top10的词组和单词排序顺序和频数是完全一致的,结果良好。
七、核心代码
一些关键函数如下:
(1)遍历文件每个字符
1 void a_cha(FILE *fp) 2 { 3 char ch; 4 char word[WORDLEN];//统计单词 5 int state = OUTWORD;//是否单词结尾 6 int k = 0;//单词位数 7 ch = fgetc(fp); 8 do 9 { 10 if (ch < 0 || ch>127) 11 continue; 12 if (ch >= 32&&ch <=126) 13 { 14 num1++;} 15 16 if (ch =='\n') { 17 num3++; //统计行数。 18 num3_ = ch; //保存上一字符。 19 } 20 21 if (isalpha(ch)|| (ch >= 48 && ch <= 57)) //读到单词 则认为此时为在单词中 22 { 23 if (isalpha(ch))//字母 24 { 25 state = INWORD; 26 27 *(word + k) = ch; //将采集到的单词放在临时字符数组中 28 k++; 29 } 30 else//数字 31 { 32 if (k <= 3) 33 { 34 k = 0; 35 state = OUTWORD; 36 continue; 37 } 38 else 39 { 40 state = INWORD; 41 *(word + k) = ch; //将采集到的数字放在临时字符数组中 42 k++; 43 } 44 45 } 46 } 47 else if ( state == INWORD) 48 { 49 if (k <= 3) 50 { 51 k=0; 52 state = OUTWORD; 53 continue; 54 } 55 else 56 { 57 state = OUTWORD; //如果原状态在单词中,下一个为非字母,则状态变为在单词外,一个单词的采集结束 58 *(word + k) = '\0'; 59 60 insertaword(word); //将单词插入散列表 61 num2++; 62 k = 0; 63 } 64 } 65 66 } while ((ch = fgetc(fp)) != EOF); 67 68 if (num3_ != '\n') { 69 num3++;//处理末行 70 } 71 fclose(fp); 72 }
(2)哈希函数
unsigned int worfkey( char* word) //计算采集到的新单词的关键码值 { char p[4]; int key; for (int i = 0;i <= 3;i++) { if (*(word+i) >= 'A'&&*(word+i) <= 'Z') //大写转小写 p[i] = *(word+i) + ('a' - 'A'); else p[i] = *(word+i); } key = 17576*(*p-97)+676 * (*(p + 1) - 97) + 26 * (*(p + 2) - 97) + *(p + 3) - 97; return key; //返回该单词对应的关键码值 }
(3)哈希表插入单词(数组)
void insertaword( char* word) { unsigned int place = worfkey(word); //调用关键码值计算函数 hashele* p = hashform[place]; //指针进行遍历操作 while (p) //遍历该单词的关键码值对应的链表,看是否有相同单词 { if (compare(p->word, word) == 0)//if (strcmp(p->word, word) == 0) //如果对应的单词相同则该结构体的计数变量加一 { p->num++; storeword(p->word, word); return; } p = p->next; //遇到相同单词前继续遍历 } hashele* newele = (hashele*)malloc(sizeof(hashele)); //在该关键码值的链表中没有找到该单词,则准备插入 newele->num = 1; strcpy(newele->word, word); newele->next = hashform[place]; //将新表元插入到链表 hashform[place] = newele; }
(4)单词比较函数
int compare(char* word1, char* word2)//比较两个单词是否相同 { int len1, len2,i; int m, n; if (stricmp(word1, word2) == 0) return 0; else { len1 = strlen(word1); len2 = strlen(word2); for (i = len1 - 1;i >= 0;i--) if (isalpha(*(word1 + i))) { m = i; break; } for (i = len2 - 1;i >= 0;i--) if (isalpha(*(word2 + i))) { n = i; break; } if (m != n) return 1; else if (strnicmp(word1, word2, m+1) == 0)//window return 0; else return 1; } }
(5)快速排序函数
void qsot(void) //快排 { int i; num2_ = 0; hashele* p; for (i = 0; i < KEYMAX; ++i) //遍历散列表,将所有单词对应的结构体放入临时指针数组里 { if (hashform[i]) { p = hashform[i]; while (p) { *(sort + num2_) = p; num2_++; p = p->next; } } } qsort(sort, num2_, sizeof(sort[0]), comp); //调用qsort函数进行排序 }
整体代码在github中发布。
代码链接https://github.com/nkzyc/homework1/tree/master/PB15061357
八、代码质量及debug过程
编程过程中,遇到大大小小数十处bug,以下列出比较典型的bug和解决方案。
(1)单词数统计
一开始单词数和助教结果总有差别,后来发现是判断逻辑问题。
一开始对字符ASCII码小于0或大于127不予计数,而实际结果是这些字符也要作为分隔符来区分单词。
ch = fgetc(fp); do { //if (ch < 0 || ch>127) //continue; ........ } while ((ch = fgetc(fp)) != EOF);
(2)数组越界问题
对于一些非txt文件,单词长度可能特别长,合理采取单词长度上限防止数组越界,本次作业定义如下:
#define WORDLEN 200 //设置单词字母最多为200个 #define WORDLENz 400 //设置词组字母最多为400个
(3)文件打开问题
递归查询文件名存入特定数组,而后利用文件打开函数fopen时必须要求输入字符串长度完全一致,否则无法成功打开文件,本次作业采用如下方法
打开。
while (!feof(fp1)) { memset(szTest, 0, sizeof(szTest)); fgets(szTest, sizeof(szTest)-1,fp1); a = strlen(szTest); if ((fp2 = fopen(mystrncpy(szTest, a), "r")) == NULL) { if (a ==0) break; else printf("The file %s can not be opened.\n",szTest); break; } else a_cha(fp2); }
(4)单词比较问题
根据作业要求的单词定义,采用直接比较算法很繁琐,本次实验采用从后往前查找第一个非数字字符,再比较,极大简化了算法设计。
len1 = strlen(word1); len2 = strlen(word2); for (i = len1 - 1;i >= 0;i--) if (isalph(*(word1 + i))) { m = i; break; } for (i = len2 - 1;i >= 0;i--) if (isalph(*(word2 + i))) { n = i; break; } if (m != n) return 1; else if (strnicmp(word1, word2, m+1) == 0)//window return 0; else return 1;
(5)移植问题
linux中使用的库函数与windows库函数有不同,移植时注意库函数调用的问题。
九、性能分析
本次采用vs自带性能分析,分析结果如下:
(1)

a_cha 和 b_cha分别为单词和数组统计函数,占用大量时间。
(2)
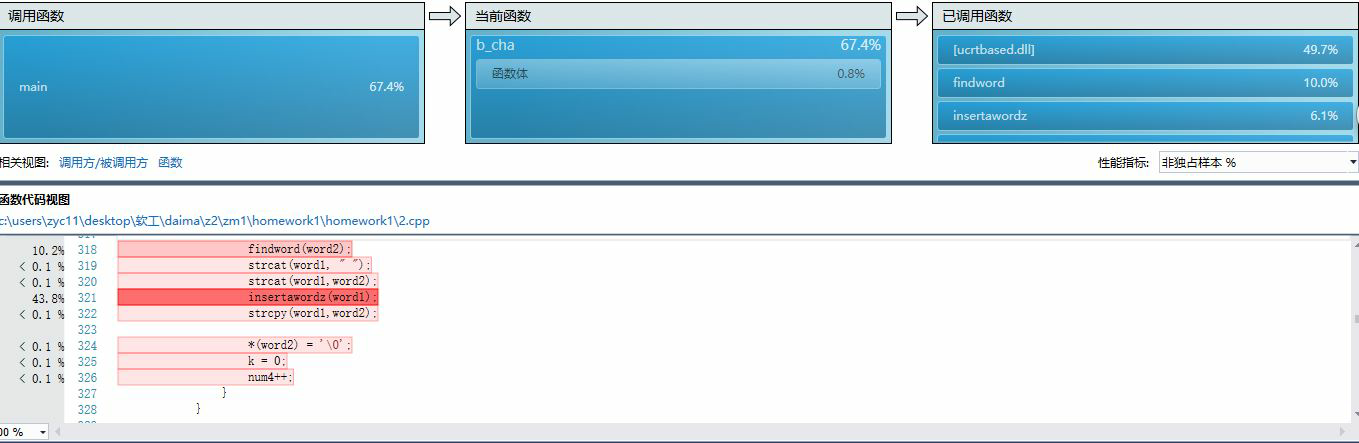
插入单词占用大量时间,分析原因是之前大小写比较函数采用自己写的循环,占用大量时间;改进为系统库函数,大量缩短时间。
十.展示PSP
|
PSP2.1 |
任务内容 |
计划完成需要的时间(min) |
实际完成需要的时间(min) |
|
Planning |
计划 |
30 |
30 |
|
Estimate |
估计这个任务需要多少时间,并规划大致工作步骤 |
30 |
30 |
|
Development |
开发 |
1390 |
1985 |
|
Analysis |
需求分析 (包括学习新技术) |
60 |
120 |
|
Design Spec |
生成设计文档 |
20 |
20 |
|
Design Review |
设计复审 (和同事审核设计文档) |
20 |
30 |
|
Coding Standard |
代码规范 (为目前的开发制定合适的规范) |
30 |
15 |
|
Design |
具体设计 |
60 |
60 |
|
Coding |
具体编码 |
1000 |
1500 |
|
Code Review |
代码复审 |
100 |
120 |
|
est |
测试(自我测试,修改代码,提交修改) |
100 |
120 |
|
Reporting |
报告 |
200 |
200 |
|
Test Report |
测试报告 |
60 |
60 |
|
Size Measurement |
计算工作量 |
20 |
20 |
|
Postmortem & Process Improvement Plan |
事后总结 ,并提出过程改进计划 |
120 |
150 |
|
Summary |
合计 |
1620 |
2245 |
十.总结经验
本次作业后,有以下一些体会
合理制定计划。本次PSP表格提升了编程的效率,并使时间利用更加合理。虽然没有按照计划完成,但使时间利用更加高效了。
debug查错误。本次实验发现了很多bug,基本是采用debug设置断点查出来的。通过这次作业,加深了我对查错的理解。
linux环境熟悉。这次移植加深了我的Linux操作系统的理解。
库函数使用。能用库函数尽量使用库函数,出错误概率越少,封装好后CPU利用更高。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号