索引技术
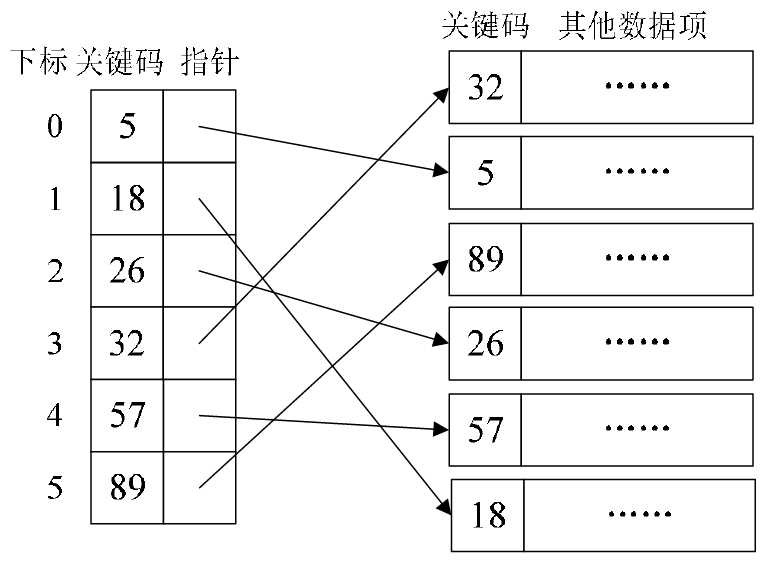
稠密索引:在线性索引中,将数据集中的每个记录对应一个索引项
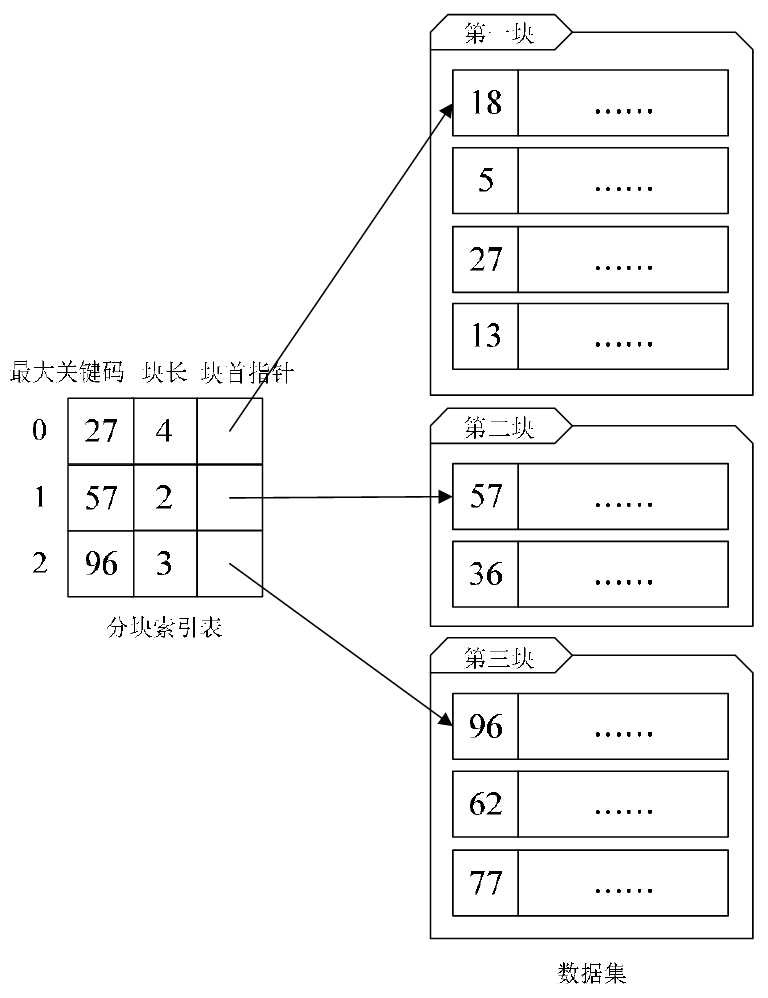
分块索引:把数据集的记录分成了若干块
满足两个条件:
- 块内无序,即每一块内的记录不要求有序。当然,你如果能够让块内有序对查找来说更理想,不过这就要付出大量时间和空间的代价,因此通常我们不要求块内有序。
- 块间有序,例如,要求第二块所有记录的关键字均要大于第一块中所有记录的关键字,第三块的所有记录的关键字均要大于第二块的所有记录关键字......因为只有块间有序,才有可能在查找时带来效率。
分块索引的索引项结构分三个数据项:
- 最大关键码:它存储每一块中的最大关键字,这样的好处就是可以使得在它之后的下一块中的最小关键字也能比这一块最大的关键字要大;
- 块长:存储了块中的记录个数,以便于循环时使用;
- 块首地址:用于指向块首数据元素的指针,便于开始对这一块中记录进行遍历。
倒排索引
我们来看样例,现在有两篇极短的英文“文章”——其实只能算是句子,我们暂认为它是文章,编号分别是1和2。
1.Books and friends should be few but good.(读书如交友,应求少而精。)
2.A good book is a good friend.(好书如挚友。)
假设我们忽略掉如“books”、“friends”中的复数“s”以及如“A”这样的大小写差异,我们可以整理出这样一张单词表,如下表所示,并将单词做了排序,也就是表格显示了每个不同的单词分别出现在哪篇文章中,比如“good”它在两篇文章中都有出现,而“is”只是在文章2中才有。英文单词 文章编号
a 2
and 1
be 1
book 1,2
but 1
few 1
friend 1,2
good 1,2
is 2
should 1
有了这样一张单词表,我们要搜索文章,就非常方便了。如果你在搜索框中填写“book”关键字。系统就先在这张单词表中有序查找“book”,找到后将它对应的文章编号1和2的文章地址(通常在搜索引擎中就是网页的标题和链接)返回,并告诉你,查找到两条记录,用时0.0001秒。由于单词表是有序的,查找效率很高,返回的又只是文章的编号,所以整体速度都非常快。
如果没有这张单词表,为了能证实所有的文章中有还是没有关键字“book”,则需要对每一篇文章每一个单词顺序查找。在文章数是海量的情况下,这样的做法只存在理论上可行性,现实中是没有人愿意使用的。
在这里这张单词表就是索引表,索引项的通用结构是:
次关键码,例如上面的“英文单词”;
记录号表,例如上面的“文章编号”。
这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号