

Rdbms的索引设计思路
一、数据结构
B-tree:
1) 平衡树,子树高度一致,M阶即M叉树
2) 叶节点间相互独立
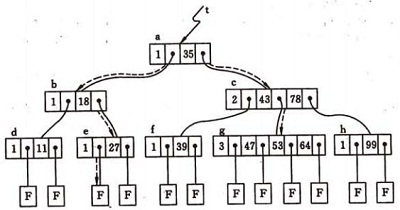
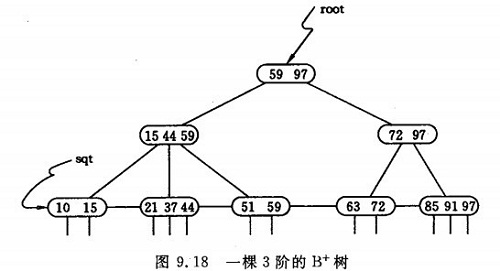
B+TREE:
1) 继承B-TREE
2)n 棵子树的结点中含有n 个key;
3)所有的叶子结点中包含了全部关键码的信息,及指向含有这些关键码记录的指针,且叶子结点本身依关键码的大小自小而大的顺序链接。
4)所有的非终端结点可以看成是索引部分,结点中仅含有其子树根结点中最大(或最小)关键码。
那么更深层次的区别在哪里:
1. 数据(point/record) 在哪里? 如果按b-tree组织,数据有可能在 叶节点 中,有可能在 非叶节点中,对于B+tree,所有数据都在leaf中。
2. 非leaf节点的存储效能
2.1 B-TREE中,不管 non-leaf-NODE(中间层的节点)中存储的是 value的point,还是value的真实record,都需要耗费空间(内存、硬盘)存储这部分point/record
2.2 B+TREE中,non-leaf-node 只存储index,(本身自己还会在leaf中出现,自身的value在leaf中能找到)
2.3 有何意义?
=> B+TREE每个中间层节点能表达的索引范围更大,系统不管读一次内存/硬盘(例如4K),能得到的索引更多,对于读取多个值的场景,索引查找过程中,内存分页/磁盘扇区复用的概率比B-TREE更高。对于写,B+TREE需要多写几层,也不好说就比B-TREE写的快。
=> seek的过程,B-TREE看运气,可能从ROOT跑到一半就找到值了,B+TREE所有都一样,固定的都需要从ROOT跑到LEAF。
3. 范围查询, B+TREE更优秀
例如 col between 100 and 500, 如果是B-TREE, 查找需要2次,100所在点, 500所在的点,然后中序(先序?后序?)遍历这两个点中间的所有NODE,才能得到所有数据(因为数据在NODE内)。如果是B+TREE,只需要找一次,先找到100所在点,然后顺着 LEAF-LinkedNodeList一直往下走,碰到500停下来即可。(如oracle b+tree table就是如此)
二、Leaf-Node的存储方式
1. cluster index
key后面带着的就是record, leaf-node就是data-node, 还有各种说法,例如什么index中key的顺序与data的顺序一致,都是一个意思。
zhangsan: zhangsan, male, 18, class 3, 32012121918231999
wanger: wanger, male, 18, class 3, 32321912831911123
2. non-cluster index
key后面带着的是*recode,或者说地址,或者说point,一个意思。
zhangsan: 0x3211FF12, 或者 4:page707,21, 最后 -> zhangsan, male, 18, class 3, 32012121918231999
wanger: 0x3241D5EB, 或者 17:page707, 22, 最后-> wanger, male, 18, class 3, 32321912831911123
那么区别在哪里?
1. non-cluster scan/seek到了leaf-node, 还需要再 get一次相应 address。而cluste-index不需要
2. non-cluster 中,兄弟(zhangsan,wanger)的index在一起,但实际record 往往不在一起,是否会产生大量缺页中断? 而cluster就可以充分的利用os的文件系统的预读特性(顺序读写, not随机读写),在大量读的场景,效率更高。
3. 一个表,只能有一个cluster-index,因为record只存一份(一致性、代价的考虑么?),其他都是non-cluster-index,non-cluster-index的value指向 cluster-index的key。
4. cluster-index对写的要求高, 写速度依赖写顺序、页分裂、树调整、空鼓等。
5. 多个表,共有一个key做外键,那么可以将此key做成cluster-index-space, 让表关联操作的消耗更低。
例如, student, student-score. 可以一个block中存储两个表的数据,(oracle的做法)
BLOCK 101: 两个表的数据都有
0x10000000 TABLE_student: zhangsan, male, 19, ..................
0x10000010 TABLE_score: zhangsan, english, 90
BLOCK 102:
0x10001000 TABLE_student: wanger, male, 20 , ...................
0x10001010 TABLE_score: wanger, english, 88
也可以做两个block之间的关联,如 (sqlserver 的做法)
BLOCK 201: 只有一个表
0x20000000 TABLE_student: zhangsan, male, 19, ..................
0x20001000 TABLE_student: wanger, male, 20 , ...................
BLOCK 202: 只有一个表
0x10000010 TABLE_score: zhangsan, english, 90
0x10001010 TABLE_score: wanger, english, 88
当然,这个例子只是1:1关系的简单结构, n:n的关系更复杂一些,说到底,就是因为cluster-index保证了大家都是有序的,所以join操作的时候快一些。
三、Update 、 Delete对索引的影响
倾斜:首先 B-/+ Tree在数据结构上保证了不会倾斜。
一般的rdbms引擎,都会为索引块预留一定的空间,例如oracle为每个block预留1/4的空间(与table的高水标记一致),可以使部分的update和insert操作在block内完成而不引起 tree的调整。
update、delete 会引起索引块的 “空洞” , 不同于算法上B-/+TREE的delete、update操作会立刻调整树,实际rdbms中只有 手动调用、block满了、满足一定的条件(如平衡度),系统才会对文件系统中的实际数据进行调整,当然有一定的代价,局部的如多几次io,全局的如索引暂时不可用。
故而在写、改、删频繁的场景下,如果空洞过多(例如每个block删了50%的数据),索引效能就会下降。

