Pycharm机器学习 环境配置
1.先安装python(类似于java中的jdk)
- 从官网下载python,python2和python3语法有点不同,选自己熟悉的即可(这有个坑,tensorflow目前不支持python3.7及以上的版本,所以建议,直接下载python3.6就ok了)
- 点击install for all users,然后路径最好直接放在c盘下面(查找文件夹方便)
- 安装的时候注意选择add enviriment variables(这样就不用自己配置环境变量了,美滋滋)
2.安装pycharm(这个是python的IDE,也可以选用jupyter notebook)
- 官网下载pycharm
- 激活码 http://idea.imsxm.com
3.安装numpy,scipy,panadas,matplotlib,sciki-learn等机器学习库
(在线安装方式)
- 1.直接打开windows命令行界面
- 2.输入python,启动python编译器
- 3.输入pip install +包名(如numpy,scipy,pandas,matplotlib,keras,tensorflow,scikit-learn),就可以自动安装了
(离线安装方式,先下载安装包,再安装)
下载地址:http://www.lfd.uci.edu/~gohlke/pythonlibs/#matplotlib (库名中带有cp的标识的是版本号,如果python是3.6的,则cp后面数字应该为36)
NumPy-数学计算基础库:N维数组、线性代数计算、傅立叶变换、随机数等。
SciPy-数值计算库:线性代数、拟合与优化、插值、数值积分、稀疏矩阵、图像处理、统计等。
Pandas-数据分析库:数据导入、整理、处理、分析等。
matplotlib-会图库:绘制二维图形和图表
scikit-learn:Simple and efficient tools for data mining and data analysis
Accessible to everybody, and reusable in various contexts
Built on NumPy, SciPy, and matplotlib
Open source, commercially usable - BSD license
- 安装如下:
- 在第一步安装好的文件夹python中,新建一个Scripts的文件夹
- 把下载的五个类库放到该文件夹中
- 打开windows命令行,用命令行定位到该文件夹:cd c:\python36\Scripts
- 按顺序安装五个类库,安装命令为:pip install +下载的类库名字;如果想卸载的话,命令为:pip uninstall+下载的类库名字
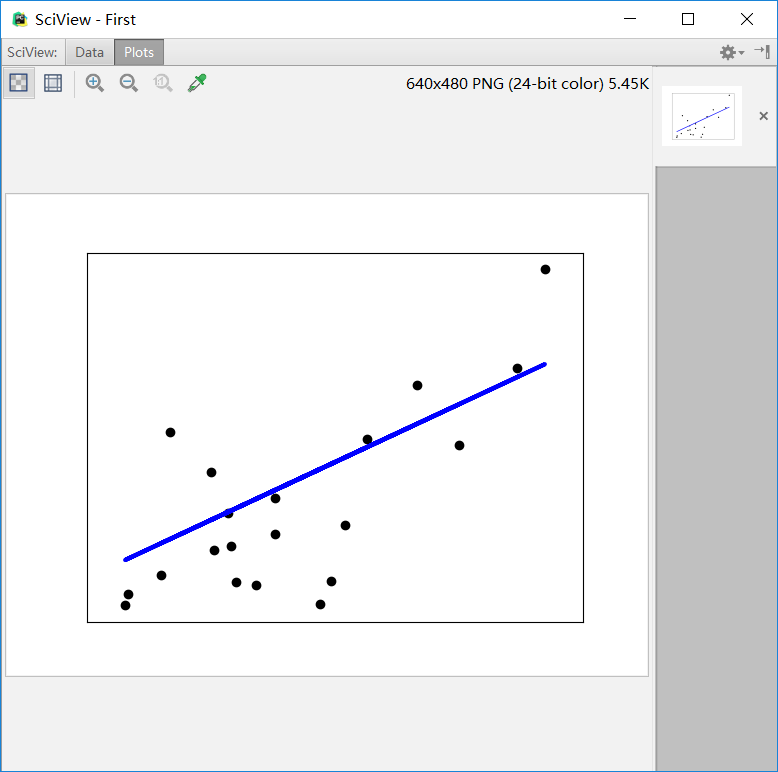
4.用pycharm跑程序,测试是否安装成功
# Code source: Jaques Grobler
# License: BSD 3 clause
#linear_model
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets, linear_model
from sklearn.metrics import mean_squared_error, r2_score
# Load the diabetes dataset
diabetes = datasets.load_diabetes()
# Use only one feature
diabetes_X = diabetes.data[:, np.newaxis, 2]
# Split the data into training/testing sets
diabetes_X_train = diabetes_X[:-20]
diabetes_X_test = diabetes_X[-20:]
# Split the targets into training/testing sets
diabetes_y_train = diabetes.target[:-20]
diabetes_y_test = diabetes.target[-20:]
# Create linear regression object
regr = linear_model.LinearRegression()
# Train the model using the training sets
regr.fit(diabetes_X_train, diabetes_y_train)
# Make predictions using the testing set
diabetes_y_pred = regr.predict(diabetes_X_test)
# The coefficients
print('Coefficients: \n', regr.coef_)
# The mean squared error
print("Mean squared error: %.2f"
% mean_squared_error(diabetes_y_test, diabetes_y_pred))
# Explained variance score: 1 is perfect prediction
print('Variance score: %.2f' % r2_score(diabetes_y_test, diabetes_y_pred))
# Plot outputs
plt.scatter(diabetes_X_test, diabetes_y_test, color='black')
plt.plot(diabetes_X_test, diabetes_y_pred, color='blue', linewidth=3)
plt.xticks(())
plt.yticks(())
plt.show()
如果安装成功,运行结果图如下: