day10_操作系统
根据架构图—画出请求数据流 —根据数据流经过的节点分析问题
负载机—经过网络传输到—应用服务器—跑服务—空闲中间件连接池(web请求连接池)_处理代码—通过网络把sql发送到—数据库连接池—请求发送到数据库服务器—数据库执行sql语句—将数据结果通过网络返回应用服务器—应用服务器对进程和线程唤醒—返回数据结果继续执行代码—将返回结果return—通过网络返回客户端
分析原因:
负载机(硬件)—网络—应用服务器(硬件)—数据库服务器(硬件)—web容器连接池—数据库连接池—sql执行过程—代码的业务逻辑。(java会有jc一说)
分析操作系统
操作系统三大件
1、cpu:Cpu对操作系统影响最大-逻辑判断处理计算
2、内存:cpu工作需要的数据存在这里,相当于闪存和缓存,电脑重启后数据就释放了,例如qq进程强制被杀死,释放一块址空间、如果在重新开启就开辟一块内存地址空间。
备注:非关 系型数据库nosql存在内存里Redis存放的key-value键值存储,内存比磁盘块很多。
如果发生内存满了、所以电脑卡了、重启就全部清空内存了。
3、磁盘:存储最终需要的数据永久存储、关系型数据库mysql、oracle数据存在磁盘里例如存一些报表,
回收站清空时-清理的是磁盘、360提示清理垃圾、垃圾数据在磁盘上(里面还包含缓存的数据实际不会那么大)。
Cpu对操作系统影响最大-Cpu计算、逻辑判断的数据都存在内存里例如cpu进行if(a>0)逻辑判断但是数据a来自于内存。
4、固态硬盘:分散的读写速度更快 ,存储数据。
5、机械硬盘:读写是一个通道一个通道比较慢,存储数据。
6、二级缓存:lev1和lev2在cpu和内存之间、比内存速度更快。但是二级缓存很贵,现在已经没人用
7、磁盘的io:磁盘的读和写操作
8、一切问题揭io:数据库一般读写存在这个问题
读: Sql的执行一条sql语句,从内存里读取速度比较快,如果数据不再内存从磁盘读取到内存里在供cpu使用
发生的原因
select查询数据—数据不再内存里,数据在磁盘里
1) 不是热点数据:热点数据就是缓存在内存里的数据-常规数据,数据里缓存。(内存不足)
2) Sql语句写的有问题例如select * 查询量很大。—全部从磁盘把数据搬家过来,读出来在进行判断过程会很长。
写:数据库语句insert写入到内存,这条sql就完成了,内存会自动同步到磁盘,再从内存放到磁盘上去。磁盘同步速度不够快时,如果重新启动数据,数据就丢失了。
总结:cpu利用率—磁盘io读写的大小—Cpu利用率或者Cpu使用率是多少
指标
9、cpu利用率:时间片里面供应用程序工作的时间片+系统调度的时间片之和/总时间
top 命令查看cpu使用情况
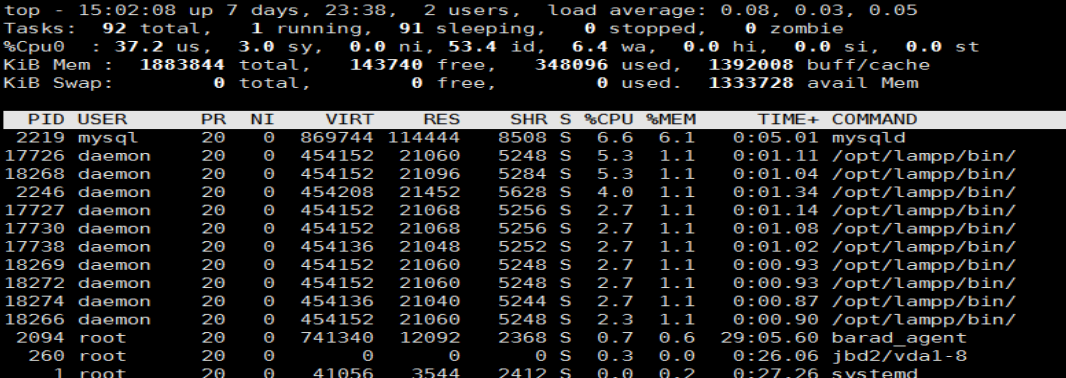
例如:开启qq、录制屏幕、聊天yy电脑不卡
Cpu工作原理 :
l Cpu时间切片:1s中切成65535份是串行操作,第一份供给a进程、第二份给b进程, 每份切换给不同的进程,cpu在同一瞬间只能处理同一个任务。时间片处理我们基本上看不到。
l 时间片在周期范围内完成了就是完成,时间片周期范围内没完成等待下一个时间片,如果等不到时间片就出现卡顿了
l Cpu把进程上下文切换:当前做什么事、回来再做什么事情。把当前进程状态保存起来、等待cpu切换回来继续执行。
3、cpu使用率:时间片切换出去之后,(时间片里面供应用程序工作的时间片(cpu读自己内存里的东西)+系统调度的时间片之和)/总时间。
例如:切片65535、供用户进程工作有10000个、供系统进程工作有20000个 cpu利用率0.45 =(10000+20000)/65535
用户进程读用户代码、系统进程读内存代码
11、cpu使用率越高-应用程序处理越慢的原因为:
供用户进程和系统进程工作时间比较多,没有被切的时间片越来越少。
l 如果占比100%或者占比到90%等待cpu大部分时间都在给用户进程和系统进程工作。
l 存在概率为:都在为系统进程和用户进程工作、切时间片的时间越来越少,进程排队等待时切片越来越长、等待cpu调度代码时间越来越长,程序越来越慢。
面试题:cpu、内存、磁盘什么关系
Cpu:逻辑判断、计算处理。
内存:cpu工作的那些数据要从这里读取、数据存放。
磁盘:最终存放数据的地方。
例如:
cpu相当于工人—材料由工人加工。
内存相当于车间—工人在车间加工原材料、材料在内存放着,加工后临时放车间在放到仓库。
磁盘相当于仓库—加工后的放到仓库。
如果想提升加工效率——加人、加熟练工种就是cpu的赫兹、加内存、加磁盘
Top命令
Cpu(s) :us 用户进程消耗的时间比、sy系统进程消耗的cpu时间比
Cpu使用占比=us+sy

面试题:
1、User是root 启动了一个java进程、他占用的是消耗用户cpu还是消耗系统cpu
l 消耗用户cpu、root也是用户
2、java进程会写日志再往磁盘写数据,写日志部分是用户cpu还是系统cpu(用户再往系统里写)
l 消耗系统cpu-写磁盘时用户进程调用系统内核,切换到系统内核,系统内核调用底层命令接口在写日志
Us:用户消耗的cpu使用率 sy:系统消耗cpu使用率

Top 命令下的负载
负载load average:三个参数代表:过去1分钟、5分钟、15分钟平均负载(负载高系统就慢)

(1) 负载如何计算:cpu正在调度的进程以及cpu等待io进程之和
命令vmstat 下图r就是代表在cpu运行的进程cpu正在调度的进程、b等待io的进程,负载=r+b


面试题
1、负载高、cpu就一定高吗?负载低cpu就一定低吗?(不一定,有关系但是不是绝对关系)
例如:一个进程有大量复杂的计算会造成cpu很高、但负载就一个。
时间片都给了一个进程、一个进程cpu使用率很高,但是进程队里只显示一个Runing的所以负载不高。
反过来—有很多个进程运行只占用了cpu的20%多的时间片,但是系统还有大量进程等待、等待其他的外部io的返回、
负载:Runing+io等待所以负载变大。
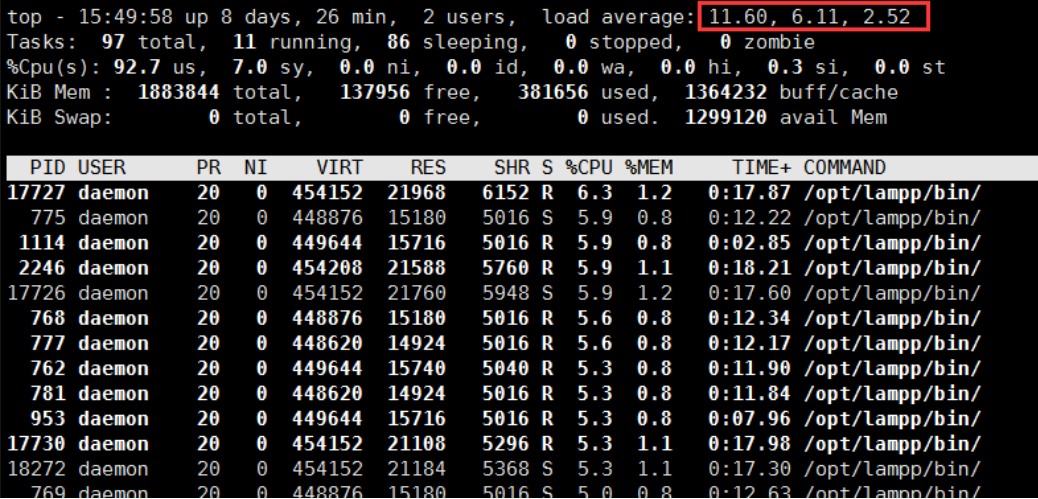
进程状态为(有点懵逼)Tasks状态Running、Sleeping、stopped、zombie
正在调度的进程叫Running—等待io也叫中断状态、等待一个外部设备的输入或等待io的一个返回结果、然后在继续进行处理。
中断可恢复:等待外部输入例如input操作不知道什么时候返回结果
中断不可恢复:不断不可干预、会给个返回结果例如io系统内核在工作不可控制
第一种情况:三个进程,启动进程之后都显示Running状态,都没拿时间片cpu还没调度,A跑的快拿到时间片A真running
系统负载为:1
A-Running-Running(真)
B-B-Running-
C-Running-
第二种情况:
A-Running-Running(真)------中断状态(中断不可恢复(中断过程不可以干预、极短时间范围内给一个结果))
B-B-Running------Running(真)
C-Running------Running(未拿到时间片)
系统负载为:2
第三种情况:
A-Running-Running(真)------中断状态(中断不可恢复(中断过程不可以干预、极短时间范围内给一个结果))-----中断不可恢复
B-B-Running------Running(真)-----等待input操作(外部设备输入、可恢复中断-不可预期状态懵逼)不算负载因为不是等待io
C-Running------Running(未拿到时间片)----Running(真)
系统负载为:2
第四种情况:
A-Running-Running(真)---中断状态(中断不可恢复(中断过程不可以干预、极短时间范围内给一个结果))---中断不可恢复--中断恢复Running
B-B-Running------Running(真)-----等待input操作(外部设备输入、可恢复中断-不可预期状态懵逼)不算负载因为不是等待io
C-Running------Running(未拿到时间片)----Running(真)---可能是等待io
系统负载为:2
操作系统性能好坏—看cpu使用率还要看负载
负载怎么去理解
例如:三条车道马路—三台以内最合理—如果四个车去跑就得有人排队等待—跑的车辆越多等待的就越多。
负载多少合理:取决于cpu颗粒数—一般建议是cpu颗粒数的 70%到80%,几核cpu就是几个cpu
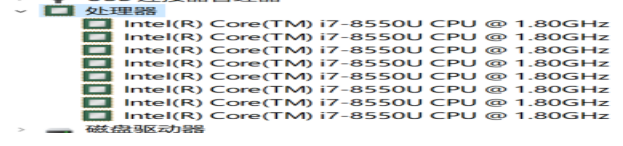
如何查看cpu核数 :top 在按1 我们是单核cpu
负载:正在调度的进程和正在等待io的进程(外部设备不算是io 中断可恢复,不是等待io都不算负载数)

Cpu使用率多少合适?
IO密集型应用:(生活中用的比较多,建议cpu(s):us+sy不超过80%)读数据库从磁盘里取数据、把数据存到磁盘。
Cpu计算型应用:大部分时间都是计算特别消耗cpu
如何查看几核CPU
我的电脑—属性—设备管理器—处理器
1、调用java进程怎么看出是占用用户cpu?
Java进程启动属于root用户启动、java所有的行为都属于用户占用用户cpu
调用系统内核信号量才能算占用系统cpu。
2、非关系型数据库—key和value为啥存在内存里?
等后面课有详细介绍redis缓存
缓存数据库:临时存储、缓存访问更快,缓存数据放在内存里、直接就返回了,重启之后没有数据,需要同步过程从磁盘里读取出来的。
Tasks:进程的状态
① Running状态运行状态(初始化的running看不到)。
② sleeping属于中断中的一种 截图中的“s”(中断可恢复)。
对于一个cpu来说只能是1个Running状态,其他的都是sleeping状态。如果多个Running状态处理不过来
中断可受控制状态:sleeping等待能变成running状态。
中断不受控制状态:比如没法人为干预这个状态-比如磁盘里io的输入和返回不可改变状态
kill -9 杀进程,偶尔有杀不掉、这个进程不可中断不可干预。
v 负载要看调度的进程
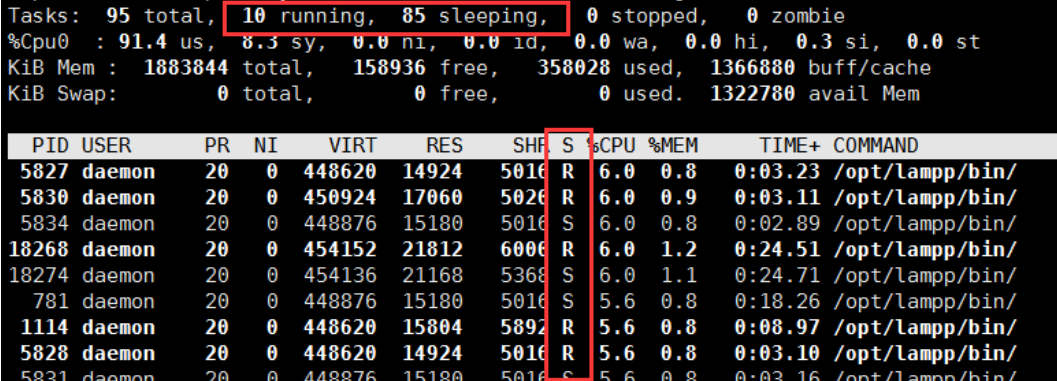
每隔2s获取结果命令— vmstat 2

监控分析状态
Cpu:看使用率和负载(top)
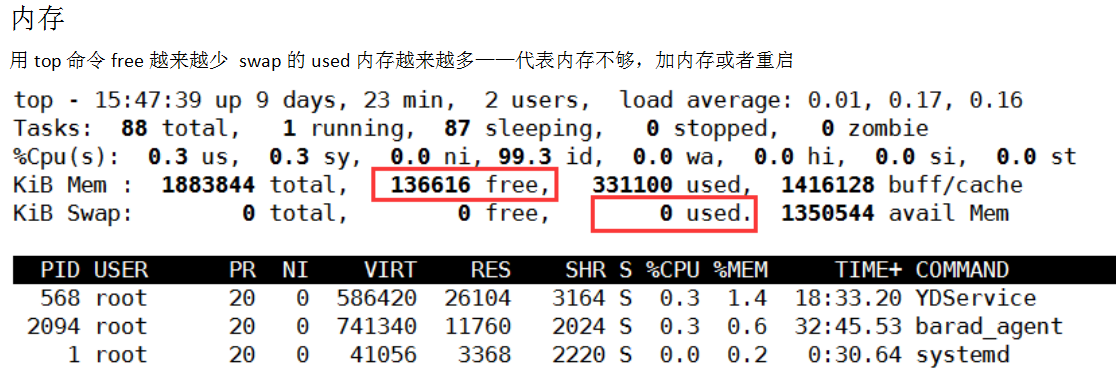
内存:剩余的内存
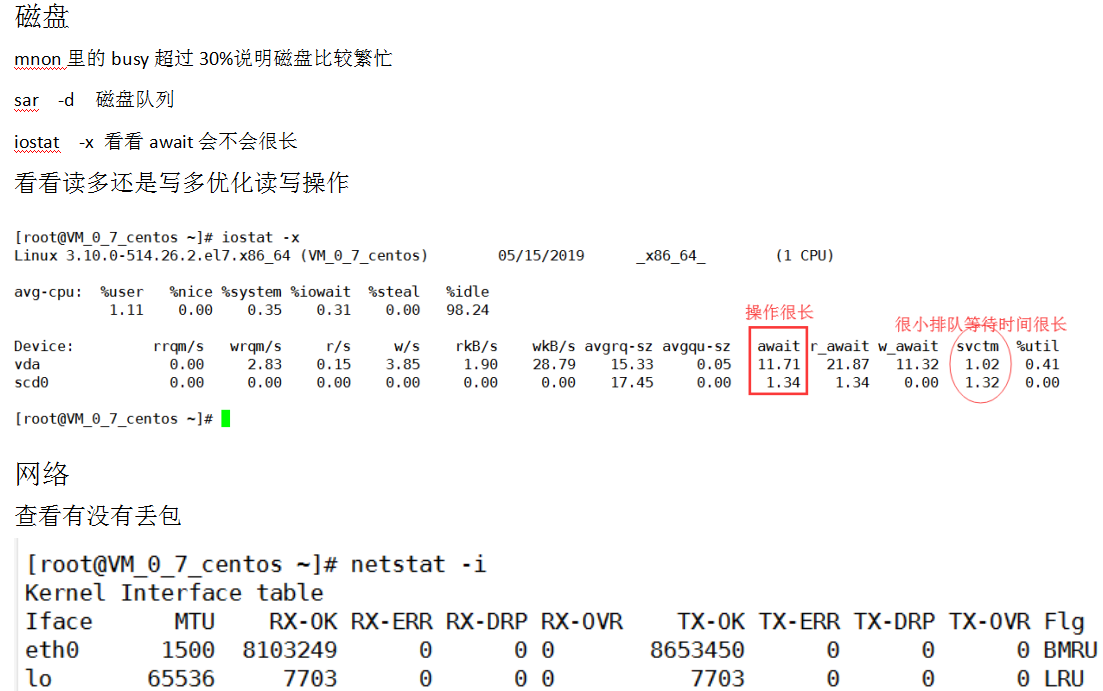
磁盘:磁盘的读写、磁盘的队列、磁盘繁忙程度
假如:带宽是100Mbps 同时上传1兆文件,同时最大能上传多少个文件?算法100/8 = 文件数(1MB=8b)才是真正的网速
网络带宽:上行带宽已发送、下行带宽已接收有限的饱和后,请求过来要排队或者丢包,带宽饱和之后请求过来排队,网络带宽被占满出现排队或者丢包
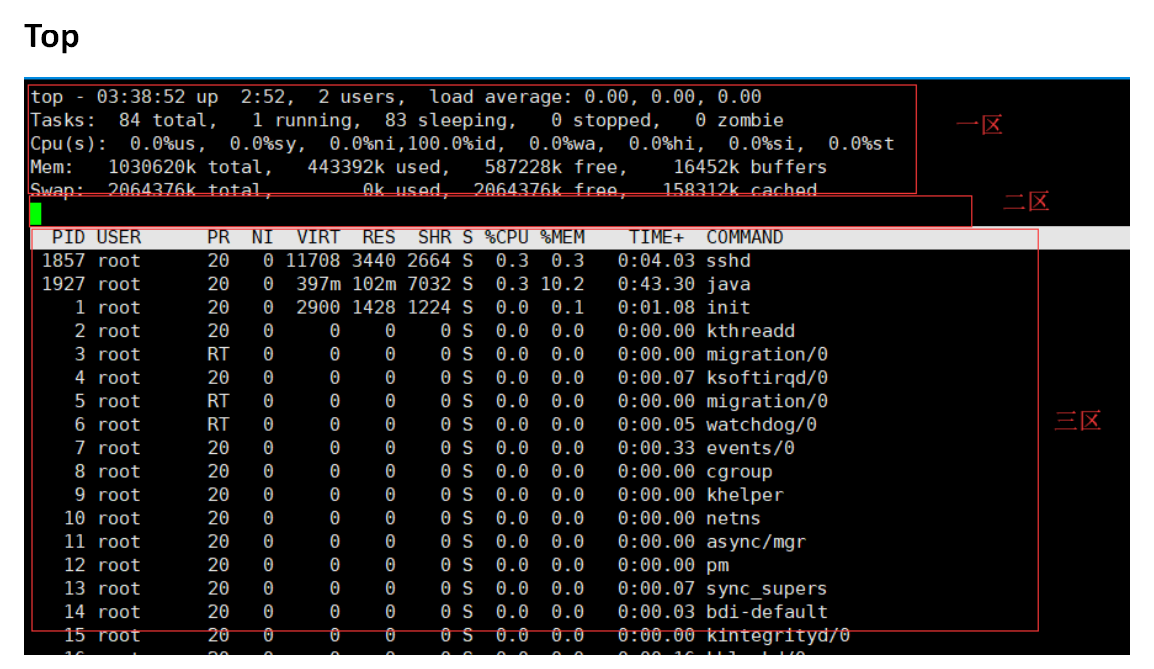
分别介绍区域
第一区域
Top开机启动多长时间,当前连接的几个用户、负载数。

Tasks 进程区:总进程、运行进程running、中断进程sleeping(中断可恢复)、停止进程stopped、僵尸状态zombie。
还有两个状态没有列出来—中断不可恢复一个状态

Cpu(s)总体cpu,按一下键盘1就展示出Cpu的细化
Us:用户进程所占用的cpu
Sy:系统进程
Ni:优先级高的进程占用的cpu对应下面的也有NI
id:空闲进程
wa:等待io占用的进程
hi: 硬中断、Si: 软中断
St:强制内存交换
Mem: 内存各项指标
v 内存和磁盘没有关系
Swap虚拟内存
物理内存:你电脑有多少内存真正意义的内存。
虚拟内存:虚拟内存在磁盘上开辟了一块空间当内存使用,虚拟内存在磁盘上,但是共用内存里的一块区域。磁盘开辟也在内存上已经分配过不在使用的一块一起使用大部分占用的磁盘。重启之后虚拟内存也会重新分配(现在用的不多了、可以不关注)
重启之后虚拟内存要重新分配。
Mem:内存大小
Cache缓存:
缓存:频繁操作的数据缓存起来、直接去缓存区下次读取。
缓存区,是高速缓存,是位于CPU和主内存之间的容量较小但速度很快的存储器,因为CPU的速度远远高于主内存的速度,CPU从内存中读取数据需等待很长的时间,而 Cache保存着CPU刚用过的数据或循环使用的部分数据,这时从Cache中读取数据会更快,减少了CPU等待的时间,提高了系统的性能。
Buffer缓冲:把要同步到磁盘的文件要缓冲起来,慢慢往磁盘里写。
备注:缓冲和缓存不占用total的内存数。
总结:内存使用率
Java程序不需要关注内存的使用率-初始化的时候就会分配一块很大的内存空间、例如内存4G启动的时候就分配3G超过了75%,分配了没被使用所以不需要看。
学习JVM时候关注 Mjava=heap+noheap+direct m
对于非java程序—内存慢慢长就要关注了,不要内存溢出了

命令交换区输入命令
• l : 平均负载及系统运行时间显示开关
• m : 内存及交换空间使用率显示开关
• t : 当前任务及CPU状态显示开关
• 1 : 汇总显示CPU状态或分开显示每个CPU状态
• c: 查看路径
• H: 查看进程下的线程

第三区域
top 命令后按“1”—cpu(s)不会超出100%,整个cpu平均使用率。
任务区红框里的cpu—进程cpu可能超过100%跟cpu的核数有关系(与cpu核数有关 例如8核cpu cpu可以最高展示800%)
PID:进程任务
PPID:父进程
交换区输入 ?—显示所有输入的选项显示出来帮助文档
RES物理内存 SHR共享内存
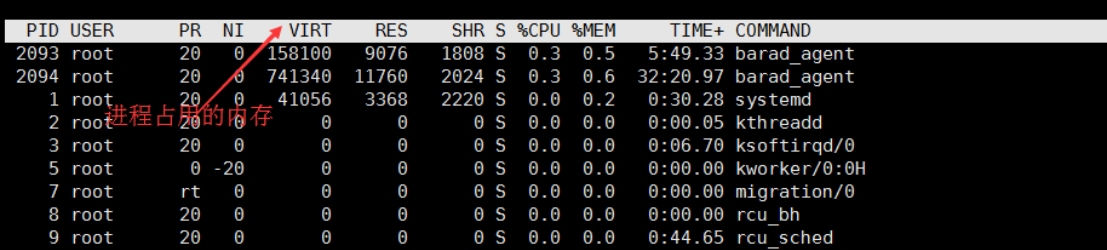
自己看ppt介绍任务区的值
top :看cpu的使用率和负载
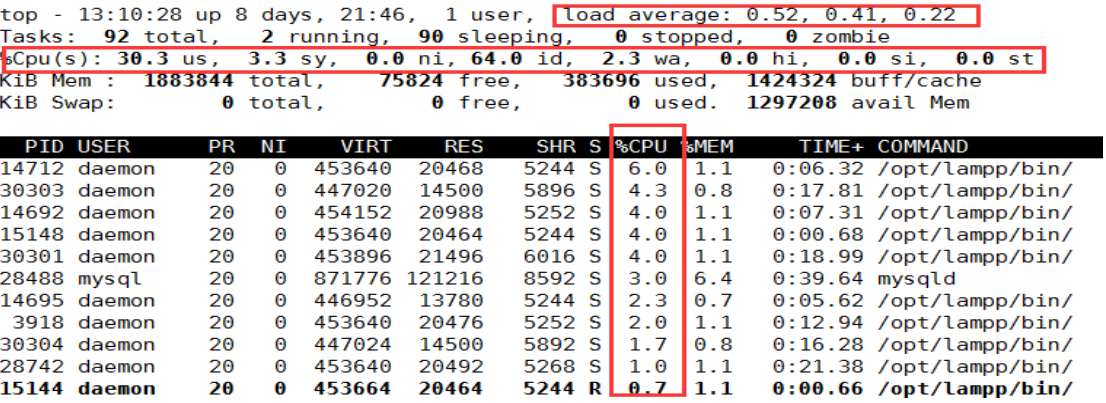
uptime:看负载

sar命令:
sar 默认-u
sar -q
plist-sz 当前系统进程和线程之和


监控系统:
Cpu-—top、vmstat两个命令
cpu使用率us、sy、id、wa,负载、进程队列
iostat
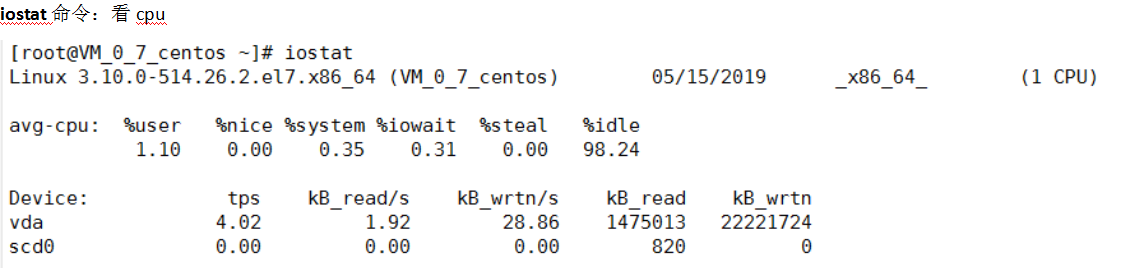
监控内存 :
内存_物理内存有没有富裕的、虚拟内存有没有被占用
top

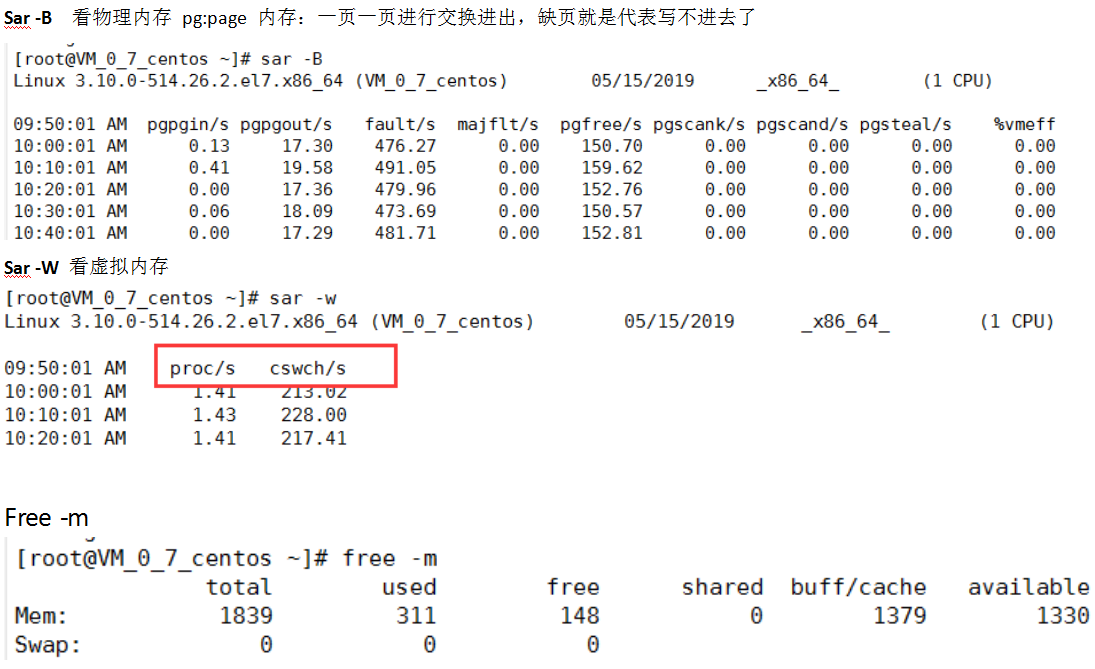
磁盘
磁盘主要看队列:await单位也是毫秒、syctm(5毫秒以内、固态硬盘应该更快)的时间。
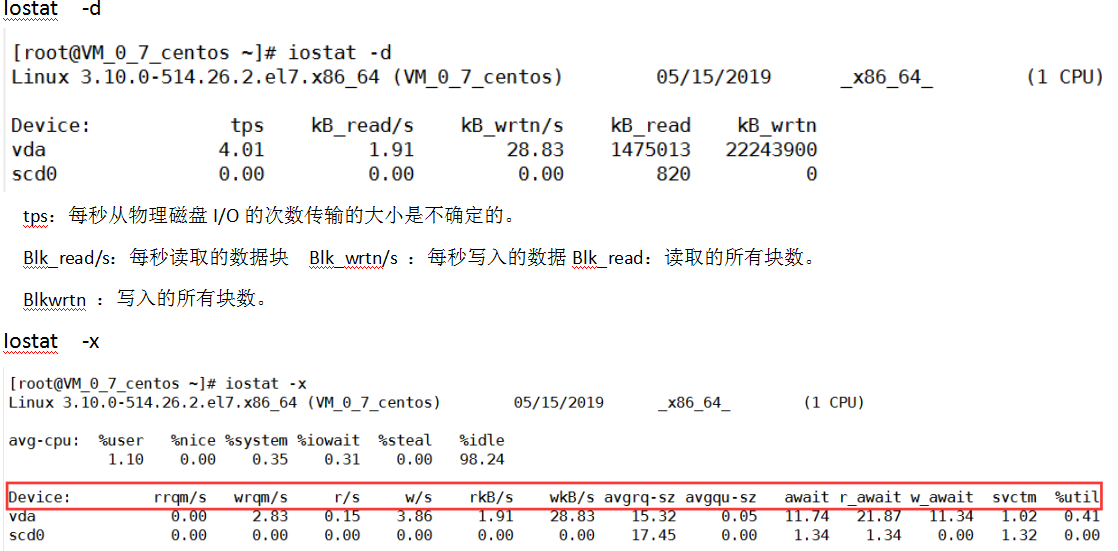
rrqm/s:每秒进行 merge(合并) 的读操作次数,即 delta(rmerge)/s 。
wrqm/s:每秒进行 merge 的写操作次数,即 delta(wmerge)/s 。
r/s:每秒完成的读 I/O 设备次数,即 delta(rio)/s 。
w/s: 每秒完成的写 I/O 设备次数,即 delta(wio)/s 。
rsec/s:每秒读扇区数,即 delta(rsect)/s。
wsec/s:每秒写扇区数,即 delta(wsect)/s
rkB/s:每秒读K字节数,是 rsect/s 的一半,因为每扇区大小为512字节。
wkB/s:每秒写K字节数,是 wsect/s 的一半
avgrq-sz:平均每次设备I/O操作的数据大小 (扇区),即delta(rsect+wsect)/delta(rio+wio) 。
avgqu-sz:平均I/O队列长度,即 delta(aveq)/s/1000 (因为aveq的单位为毫秒)。磁盘有多少任务要做
Await:请求队列中等待时间+svctm(服务时间) 单位是毫秒,按照每次IO平均。 ,即 delta(ruse+wuse)/delta(rio+wio) 。
一般地系统IO响应时间应该低于5ms,如果大于10ms就比较大了。 这个时间包括了队列时间和服务时间,也就是说,一
般情况下,await大于svctm,它们的差值越小,则说明队列时间越短,反之差值越大,队列时间越长,说明系统出了问题。
Svctm:平均每次设备I/O操作的服务时间 (毫秒),即 delta(use)/delta(rio+wio) 。
%util:一秒中有百分之多少的时间用于 I/O 操作,或者说一秒中有多少时间 I/O 队列是非空的,
即 delta(use)/s/1000 (因为use的单位为毫秒)

Iface:表示网络设备的接口名称。
MTU:表示最大传输单元,单位为字节。
RX-OK/TX-OK:表示已经准确无误地接收/发送了多少数据包。
RX-ERR/TX-ERR:表示接收/发送数据包时候产生了多少错误。
RX-DRP/TX-DRP:表示接收/发送数据包时候丢弃了多少数据包。
RX-OVR/TX-OVR:表示由于误差而丢失了多少数据包。
Flg表示接口标记,其中
B 已经设置了一个广播地址。
L 该接口是一个回送设备。
M 接收所有数据包(混乱模式)。
N 避免跟踪。
O 在该接口上,禁用A R P。
P 这是一个点到点链接。
R 接口正在运行。
U 接口处于“活动”状态。
其中RX-ERR/TX-ERR、 RX-DRP/TX-DRP和RX-OVR/TX-OVR的值应该都为0,如果不为0,并且很大,那么网
络质量肯定有问题,网络传输性能也一代会下降。
分析
Cpu有没有性能问题如何判断?
v 先看系统负载—如果负载高>cpu颗粒数的几倍、肯定出现等待情况
如何排查:
① cpu使用率:us+sy不超过80%
② 如果cpu使用率不高就看cpu队列vmstat、sar -q—调度cpu的进程过多、还是等待io的队列过多
v cpu使用率过高分析使用过高的原因
- us高(查看哪个用户进程占用cpu过高)如果是java 找进程下的哪个线程、把线程栈信息打印出来看看正在执行什么 方法。(java的线程栈是一个快照信息、这个线程正在调用的方法就定位到方法—读代码修改方法)
- sy高—io和中断导致
系统内存调度占用、io等待造成(看磁盘的队列、看磁盘繁忙程度nmon命令-磁盘繁忙超过30%有问题磁盘io看磁盘读还是写导致,如果是读导致代表内存不够、如果是写导致系统写操作太多了减少写操作或者合并)、
中断切换top(hi、si硬中断软中断),vmstat(system里的in、cs代表中断和上下文切换),
上下文切换:频繁进程抢占看看有没有进程优先级top可以看、时间片没执行完强制执行下一个任务说明程序慢。
v 进程队列
- cpu队列vmstat、sar -q看调度cpu的进程过多、还是等待io的过多(大量等待io返回看看在等待什么的返回)。等待cpu和运行cpu过高,启动多了、时间片没有干完活。
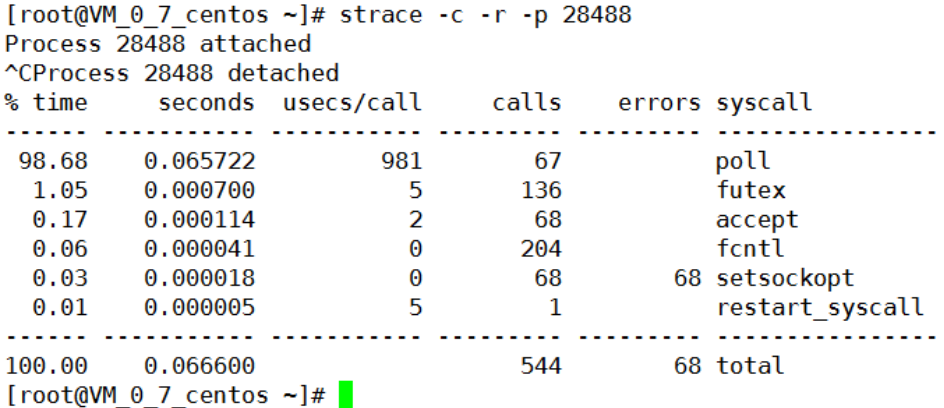
终极命令:strace --哪个进程sy使用率过高
strace --跟踪进程
-c:统计每种系统调用所执行的时间,调用次数,出错次数。
-p:跟踪指定的进程。
-r:打印每一个系统调用的相对时间。
对系统内核很熟、要知道代码哪个地方调用模块、被测接口要用到这个模块。