LINUX之文本处理命令grep sed awk
可用head和tail显示文本第几行到第几行
如要显示1.txt的第20到22行:head -22 1.txt | tail -3 1.txt
xargs:将输入参数放到args里并与后面凭借 如:echo "/" | xargs ls -l 显示根目录下所有的东西
grep:用于过滤
以这样一个文本为例 1.txt
#line1
after
after
before
before
#line6
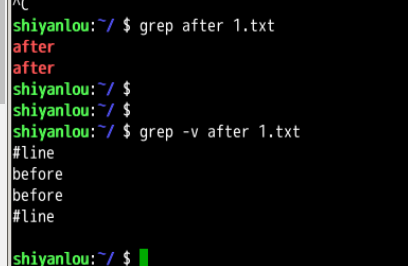
这是grep最简单的用法,如果加 -v 就是除after其余都匹配
如果想真正把grep用好,就要结合正则表达式来使用
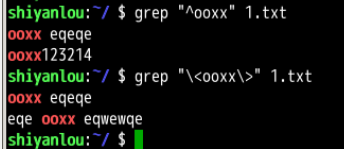
第一个匹配以ooxx开头的单词,第二个匹配含有ooxx单词的行
sed:用于修改编辑(stream editor,行编辑器)
sed是一种流编辑器,他一次处理一行内容,处理时,把当前处理的行存储在临时的 缓冲区中,称为模式空间(pattern space)。
接着用sed命令处理缓冲其余的内容,处理完成后,吧缓冲区的内容送往屏幕。然后读入下一行,执行下一个循环。
典型用法:sed [option]... 'script' inputfile ...
以下以这个文本为例
apple 1 banana 2 orange 3
常用选项:
-n:不输出模式空间内容到屏幕,即不自动打印
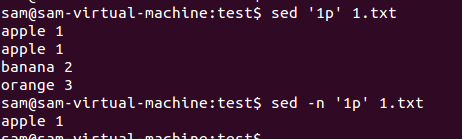
若不加-n,会把文本的所有的内容都打印一遍,并把符合规则的第一行打印出来,加-n则不会输出文本内容
-e:多点编辑
-f:把脚本内容添加到待执行的命令中
-i:更改文件中的内容
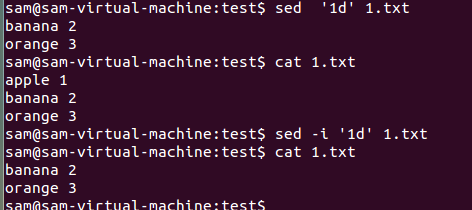
不加-i,用cat查看没删掉,加了-i发现删掉了
-r:在脚本中使用扩展的正则表达式
编辑命令:
p:匹打印当前模式空间的内容,追加到默认的输出之后

从第1行步进2行显示,即显示奇数行,如果偶数行则从第2行步进。
d:删除模式空间匹配的行,并立即启用下一轮循环
a[\]text:在指定行后面追加文本,支持使用\n追加多行
i[\]text:在指定行前插入文本
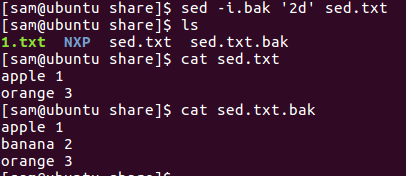
在-i后面加.bak(当然可以取任意名字)会生成一个备份文件,原文件被修改了,但会备份一个修改前的文件
c[\]text:一行替换为多行文本

反斜杠加不加都ok,以上都是
s/.../.../ 内容替换指定内容
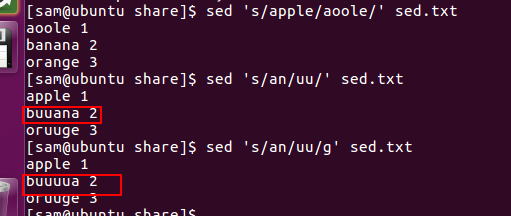
如果不加g,即使一行有多个也只替换第一个
w /path/file:保模式匹配的行至指定文件
r /path/file:读取指定文件的文本至模式空间中匹配的行后
=:为模式空间中的行打印行号
!:模式空间中匹配行取反处理
awk:是一种可以处理数据,产生格式化报表的语言。惹味每一行是一条记录,记录与记录的分隔符是换行符,每一列是一个字段,字段与字段的分隔符默认是一个或多个空格或tab制表符。
awk [option] [begin]{programs} [end][file]
apple 1 good peach 2 nice banana:3:bad orange:4:delicious
-F fs指定描绘一行中数据字段的文件分隔符,默认为空格
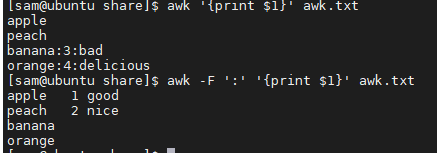
如果不加-F,则打印3,4行的第一列数据为全部数据,如果加了,则第1,2行数据为全部数据,没被:分隔
当然,还可以把分割的数据按指定的字符去分割,可以看到,3,4行数据以‘-’分割

-f file指定读取程序的文件名
-v var=value 定义程序中是使用的变量和默认值
awk程序运行的优先级
1)begin:在开始处理数据流之前,可选项
2)program:如何处理数据流,必选项
3)end:处理完数据流后执行,可选项
对字段的提取(提取一个文本中的一列数据并打印)
$0:表示整行文本
$1:不i奥i是文本行中的第一个数据字段
$N:表示文本行中的第N个数据字段
$NF:表示文本行中的最后一个数据字段
对记录的提取(提取一个文本中的一行数据并打印)
记录的提取有两种方法,1:行号,2:正则表达式
NR:指定行号


 浙公网安备 33010602011771号
浙公网安备 33010602011771号