
MYSQL数据库高级用法
一,视图
1,为什么需要有视图
* 对于复杂的查询,往往是有多个数据表进行关联查询而得到,而这种语句往往比较复杂,也可能非常频繁的使用。
比如这样的SQL语句
select goods.name,goods_cates.name,goods_brands.name
from goods
join goods_cates on goods.cate_id = goods_cates.id
join goods_brands on goods.brand_id = goods_brands.id;
为了简化用户复杂的操作,我们可以考虑使用视图。
2,视图简介
视图就是一个能够把复杂SQL语句的功能封装起来的一个虚表。所以我们在创建视图的时候,主要的工作就落在创建这条SQL查询语句上。
视图是对若干张基本表的引用,一张虚表,只查询语句执行结果的字段类型和约束,不存储具体的数据(基本表数据发生了改变,视图也会跟着改变);
方便操作,特别是查询操作,减少复杂的SQL语句,增强可读性;
3,定义视图
建议以v_开头
create view 视图名称 as select语句;
# 同基本表的表结构一直 视图在保存基本表字段信息的时候字段不能重复
# 因此需要对select结果集中的字段进行重命名
create view v_goods_info
as
select goods.name gname,goods_cates.name gcname ,goods_brands.name gbname
from goods
join goods_cates on goods.cate_id = goods_cates.id
join goods_brands on goods.brand_id = goods_brands.id;
create view v_goods_info as select g.*,c.name as cate_name ,b.name as brand_name from goods as g left join goods_cates as c on g.cate_id = c.id left join good
4,查看视图
查看表会将所有的视图也列出来
show tables;
5,使用视图
视图的用途就是查询,
select * from v_goods_info;
6,删除视图
drop view 视图名称;
例:
drop view v_stu_sco;
7,总结
- 视图封装了对多张基本表的复杂操作,简化用户操作
- 视图只是一个虚表,并不存储任何基本表的表数据,当用户使用视图的时候 视图会从基本表中取出
- 通过视图可以对用户展示指定字段从而屏蔽其他字段数据,更加安全
二,事务
1,事务简介
例如:
A用户和B用户是银行的储户,现在A要给B转账500元,那么需要做以下几件事:
- 检查A的账户余额>500元;
- A 账户中扣除500元;
- B 账户中增加500元;
正常的流程走下来,A账户扣了500,B账户加了500,皆大欢喜。
那如果A账户扣了钱之后,系统出故障了呢?A白白损失了500,而B也没有收到本该属于他的500。
以上的案例中,隐藏着一个前提条件:A扣钱和B加钱,要么同时成功,要么同时失败。事务的需求就在于此
事务Transaction,是指作为一个基本工作单元执行的一系列SQL语句的操作,要么完全地执行,要么完全地都不执行。
从一个帐号扣款并使另一个帐号增款,这两个操作要么都执行,要么都不执行。这两个操作必须保证全部成功或者什么都不做,不允许出现成功1个失败一个的情况。
2,事务四大特性ACID
- 原子性(Atomicity)
- 一致性(Consistency)
- 隔离性(Isolation)
- 持久性(Durability)
以下内容出自《高性能MySQL》第三版,了解事务的ACID有助于我们更好的理解事务运作。
下面举一个银行应用是解释事务必要性的一个经典例子。假如一个银行的数据库有两张表:支票表(checking)和储蓄表(savings)。现在要从用户Jane的支票账户转移200美元到她的储蓄账户,那么至少需要三个步骤:
- 检查支票账户的余额高于或者等于200美元。
- 从支票账户余额中减去200美元。
- 在储蓄帐户余额中增加200美元。
上述三个步骤的操作必须打包在一个事务中,任何一个步骤失败,则必须回滚所有的步骤。
可以用START TRANSACTION语句开始一个事务,然后要么使用COMMIT提交将修改的数据持久保存,要么使用ROLLBACK撤销所有的修改。事务SQL的样本如下:
- start transaction;
- select balance from checking where customer_id = 10233276;
- update checking set balance = balance - 200.00 where customer_id = 10233276;
- update savings set balance = balance + 200.00 where customer_id = 10233276;
- commit;
一个很好的事务处理系统,必须具备这些标准特性:
1)原子性(atomicity)
一个事务必须被视为一个不可分割的最小工作单元,整个事务中的所有操作要么全部提交成功,要么全部失败回滚,对于一个事务来说,不可能只执行其中的一部分操作,这就是事务的原子性
2)一致性(consistency)
数据库总是从一个一致性的状态转换到另一个一致性的状态。(在前面的例子中,一致性确保了,即使在执行第三、四条语句之间时系统崩溃,支票账户中也不会损失200美元,因为事务最终没有提交,所以事务中所做的修改也不会保存到数据库中。)
3)隔离性(isolation)
通常来说,一个事务所做的修改在最终提交以前,对其他事务是不可见的。(在前面的例子中,当执行完第三条语句、第四条语句还未开始时,此时有另外的一个账户汇总程序开始运行,则其看到支票帐户的余额并没有被减去200美元。)
4)持久性(durability)
一旦事务提交,则其所做的修改会永久保存到数据库。(此时即使系统崩溃,修改的数据也不会丢失。)
3,事务的使用
表的引擎类型必须是innodb类型才可以使用事务,这是mysql表的默认引擎
查看表的创建语句,可以看到engine=innodb
-- 选择数据库
use jing_dong;
-- 查看goods表
show create table goods;
mysql root@(none):jing_dong> show create table goods;
+-------+--------------------------------------------------------+
| Table | Create Table |
+-------+--------------------------------------------------------+
| goods | CREATE TABLE `goods` ( |
| | `id` int(10) unsigned NOT NULL AUTO_INCREMENT, |
| | `name` varchar(150) NOT NULL, |
| | `cate_id` int(10) unsigned NOT NULL, |
| | `brand_id` int(10) unsigned NOT NULL, |
| | `price` decimal(10,3) NOT NULL DEFAULT '0.000', |
| | `is_show` bit(1) NOT NULL DEFAULT b'1', |
| | `is_saleoff` bit(1) NOT NULL DEFAULT b'0', |
| | PRIMARY KEY (`id`), |
| | KEY `cate_id` (`cate_id`) |
| | ) ENGINE=InnoDB AUTO_INCREMENT=25 DEFAULT CHARSET=utf8 |
+-------+--------------------------------------------------------+
1)开启事务
- 开启事务后执行修改命令,变更会维护到本地缓存中,而不维护到物理表中
begin;
或者
start transaction;
2)提交事务
- 将缓存中的数据变更维护到物理表中
commit;
3,回滚事务
- 放弃缓存中变更的数据 表示事务执行失败 应该回到开始事务前的状态
rollback;
4,验证事务的ACID特性
1)验证提交
- 为了演示效果,需要打开两个终端窗口,使用同一个数据库,操作同一张表(用到之前的jing_dong数据)
step1:连接
- 终端1:查询商品分类信息
select * from goods_cates;
step2:增加数据
- 终端2:开启事务,插入数据
begin;
insert into goods_cates(name) values('小霸王游戏机');
- 终端2:查询数据,此时有新增的数据
select * from goods_cates;
step3:查询
- 终端1:查询数据,发现并没有新增的数据
select * from goods_cates;
step4:提交
- 终端2:完成提交
commit;
step5:查询
- 终端1:查询,发现有新增的数据
select * from goods_cates;
2)验证回滚
- 为了演示效果,需要打开两个终端窗口,使用同一个数据库,操作同一张表
step1:连接
- 终端1
select * from goods_cates;
step2:增加数据
- 终端2:开启事务,插入数据
begin;
insert into goods_cates(name) values('小霸王游戏机');
- 终端2:查询数据,此时有新增的数据
select * from goods_cates;
step3:查询
- 终端1:查询数据,发现并没有新增的数据
select * from goods_cates;
step4:回滚
- 终端2:完成回滚
rollback;
step5:查询
- 终端1:查询数据,发现没有新增的数据
select * from goods_cates;
5,总结
事务有原子性、一致性、隔离性、持久性
- 原子性强调事务中的多个操作时一个整体
- 一致性强调数据库中不会保存不一致状态
- 隔离性强调数据库中事务之间相互不可见
- 持久性强调数据库能永久保存数据,一旦提交就不可撤销
三,索引
- 能够说出索引的作用
- 能够写出创建索引的 SQL 语句
- 能够写出查看索引的 SQL 语句
- 能够写出删除索引的 SQL 语句
1,为什么需要索引
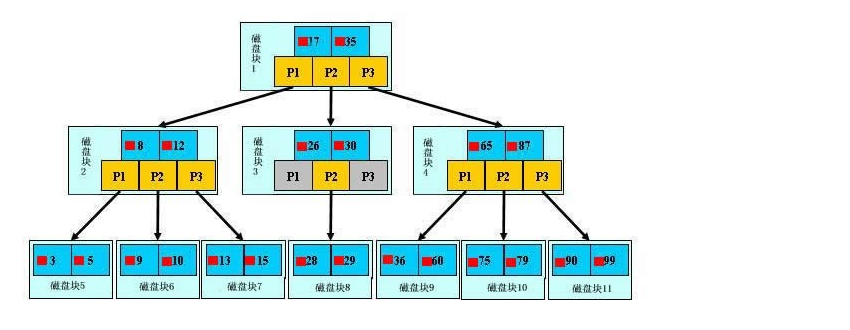
思考: 如何在一个图书馆中找到一本书的 在图书馆中如果其他辅助手段只能一条道走到黑,一本书->一本书的扫,终于经过1个小时的连续扫描发现你需要看的那本书在一分钟之前被人借走了。这种就是顺序查找。 图书馆管理员发现这个问题,于是决定减少这样的(>﹏<)悲剧故事。 为同学们购置了一套图书馆管理系统,大家要找书籍先在系统上查找到书籍所在的房屋编号和货架编号,然后就可以直接大摇大摆的去取书了。我们把这种能够帮助我们快速查询数据的线索就称之为索引。
一般的应用系统对比数据库的读写比例在10:1左右(即有10次查询操作时有1次写的操作),
而且插入操作和更新操作很少出现性能问题,
遇到最多、最容易出问题还是一些复杂的查询操作,所以查询语句的优化显然是重中之重。当数据库中数据量很大时,查找数据会变得很慢,我们就可以使用索引来提高数据库的查询效率。
索引是什么
索引是一种特殊的文件(InnoDB数据表上的索引是表空间的一个组成部分),它们包含着对数据表里所有记录的位置信息。
更通俗的说,数据库索引好比是一本书前面的目录,能加快数据库的查询速度.
2,索引原理
除了词典,生活中随处可见索引的例子,如火车站的车次表、图书的目录等。它们的原理都是一样的,通过不断的缩小想要获得数据的范围来筛选出最终想要的结果,同时把随机的事件变成顺序的事件,也就是我们总是通过同一种查找方式来锁定数据。
数据库也是一样,但显然要复杂许多,因为不仅面临着等值查询,还有范围查询(>、<、between、in)、模糊查询(like)、并集查询(or)等等。数据库应该选择怎么样的方式来应对所有的问题呢?我们回想字典的例子,能不能把数据分成段,然后分段查询呢?最简单的如果1000条数据,1到100分成第一段,101到200分成第二段,201到300分成第三段……这样查第250条数据,只要找第三段就可以了,一下子去除了90%的无效数据。
3,索引的使用
- 查看表中已有索引
show index from 表名;
- 创建索引
- 如果指定字段是字符串,需要指定长度,建议长度与定义字段时的长度一致
- 字段类型如果不是字符串,可以不填写长度部分
create index 索引名称 on 表名(字段名称(长度))
- 删除索引:
drop index 索引名称 on 表名;
4,验证索引是否能够提升查询性能
1)创建测试表testindex
create table test_index(title varchar(10));
2)使用python程序(ipython也可以)通过pymsql模块 向表中加入十万条数据
注意: 可能当前终端在前面验证事务的时候已经关闭了自动提交。 因此最简单的方式就是重开mysql终端。
from pymysql import connect
def main():
# 创建Connection连接
conn = connect(host='localhost',port=3306,database='jing_dong',user='root',password='mysql',charset='utf8')
# 获得Cursor对象
cursor = conn.cursor()
# 插入10万次数据
for i in range(100000):
cursor.execute("insert into test_index values('ha-%d')" % i)
# 提交数据
conn.commit()
if __name__ == "__main__":
main()
3)查询
- 开启运行时间监测:
set profiling=1;
- 查找第1万条数据ha-99999
select * from test_index where title='ha-99999';
- 查看执行的时间:
show profiles;
- 为表title_index的title列创建索引:
create index title_index on test_index(title(10));
- 执行查询语句:
select * from test_index where title='ha-99999';
- 再次查看执行的时间
show profiles;
4,总结
- 索引可以明显提高某些字段的查询效率
- 索引使用
- 创建 create index xxx on 表名(字段名[(索引长度 字符串类型才需要指定)])
- 查看 show index for xxx
- 索引的副作用-索引虽好 不要贪杯
- 要注意的是,建立太多的索引将会影响更新和插入的速度,因为它需要同样更新每个索引文件。对于一个经常需要更新和插入的表格,就没有必要为一个很少使用的where字句单独建立索引了,对于比较小的表,排序的开销不会很大,也没有必要建立另外的索引。
- 建立索引会占用磁盘空间
四,用户管理
1,MySQL账户管理
-
在我们之前登录MySQL的时候我们都是直接使用的root用户,root用户属于数据库系统中的超级管理员,有权限对mysql进行任何想要做的操作。
-
如果在生产环境下操作数据库时也是全部直接使用root账户连接,这就和悬崖边跳舞差不多。所以 创建特定的账户,授予这个账户特定的操作权限,然后连接进行操作 比如常规的crud 才是正道。
-
MySQL账户体系:根据账户所具有的权限的不同,MySQL的账户可以分为以下几种
- 服务实例级账号:,启动了一个mysqld,即为一个数据库实例;如果某用户如root,拥有服务实例级分配的权限,那么该账号就可以删除所有的数据库、连同这些库中的表
- 数据库级别账号:对特定数据库执行增删改查的所有操作
- 数据表级别账号:对特定表执行增删改查等所有操作
- 字段级别的权限:对某些表的特定字段进行操作
- 存储程序级别的账号:对存储程序进行增删改查的操作
注意:进行账户操作时,需要使用root账户登录,这个账户拥有最高的实例级权限。账户的操作主要包括创建账户、删除账户、修改密码、授权权限等。
2,授予权限
需要使用实例级账户登录后操作,以root为例
主要操作包括:
- 查看所有用户
- 修改密码
- 删除用户
1)查看所有用户
- 所有用户及权限信息存储在mysql数据库的user表中
- 查看user表的结构
desc user;
- 主要字段说明:
- Host表示允许访问的主机
- User表示用户名
- authentication_string表示密码,为加密后的值
查看所有用户
select host,user,authentication_string from user;
结果
mysql> select host,user,authentication_string from user;
+-----------+------------------+-------------------------------------------+
| host | user | authentication_string |
+-----------+------------------+-------------------------------------------+
| localhost | root | *E74858DB86EBA20BC33D0AECAE8A8108C56B17FA |
| localhost | mysql.sys | *THISISNOTAVALIDPASSWORDTHATCANBEUSEDHERE |
| localhost | debian-sys-maint | *EFED9C764966EDB33BB7318E1CBD122C0DFE4827 |
+-----------+------------------+-------------------------------------------+
3 rows in set (0.00 sec)
2)创建账户、授权
- 需要使用实例级账户登录后操作,以root为例
- 常用权限主要包括:create、alter、drop、insert、update、delete、select
- 如果分配所有权限,可以使用all privileges
1))创建账户&授权
grant 权限列表 on 数据库 to '用户名'@'访问主机' identified by '密码';
示例1
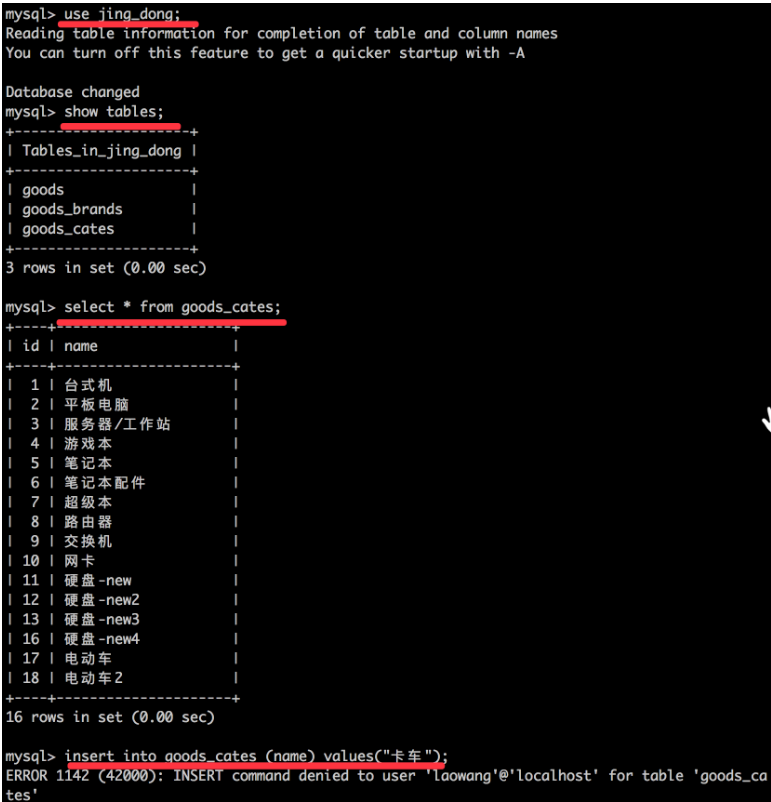
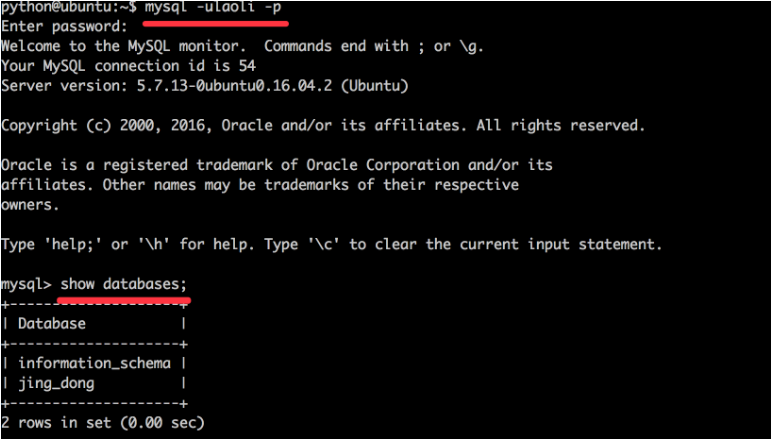
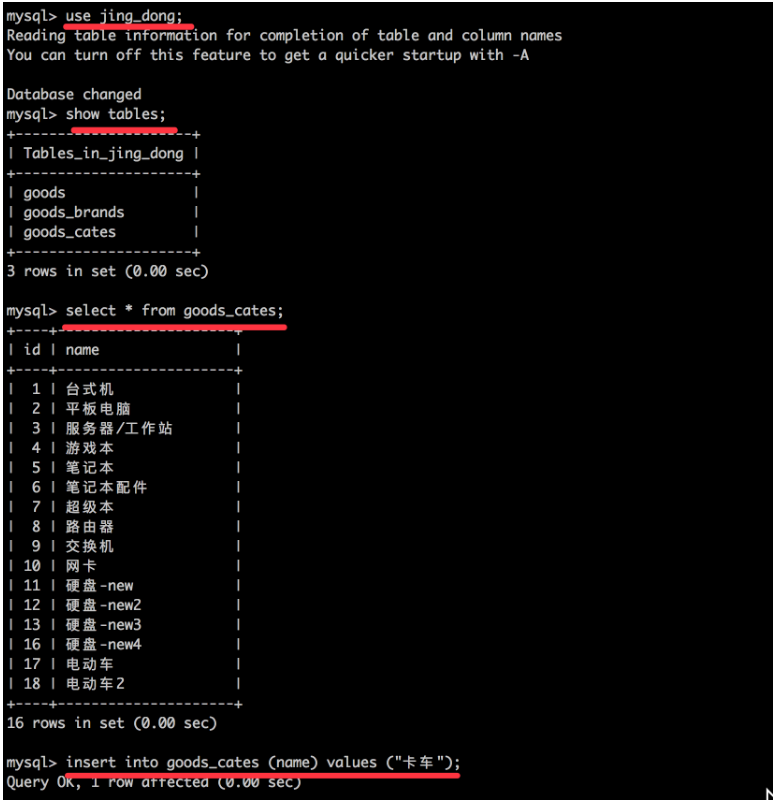
创建一个laowang的账号,密码为123456,只能通过本地访问, 并且只能对jing_dong数据库中的所有表进行读操作
step1:使用root登录
mysql -uroot -p
回车后写密码,然后回车
step2:创建账户并授予所有权限
grant select on jing_dong.* to 'laowang'@'localhost' identified by '123456';
说明
-
- 可以操作python数据库的所有表,方式为:
jing_dong.* - 访问主机通常使用 百分号% 表示此账户可以使用任何ip的主机登录访问此数据库
- 访问主机可以设置成 localhost或具体的ip,表示只允许本机或特定主机访问
- 可以操作python数据库的所有表,方式为:
-
- 查看用户有哪些权限
show grants for laowang@localhost;
step3:退出root的登录
quit
step4:使用laowang账户登录
mysql -ulaowang -p
回车后写密码,然后回车
- 登录后效果如下图
示例2
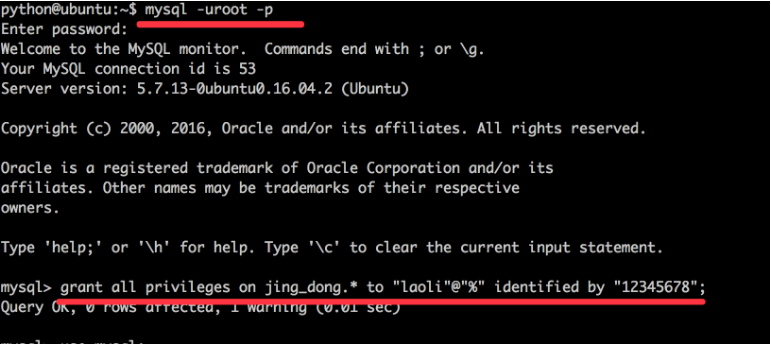
创建一个laoli的账号,密码为12345678,可以任意电脑进行链接访问, 并且对jing_dong数据库中的所有表拥有所有权限
grant all privileges on jing_dong.* to "laoli"@"%" identified by "12345678"
3,账户操作
1)修改权限
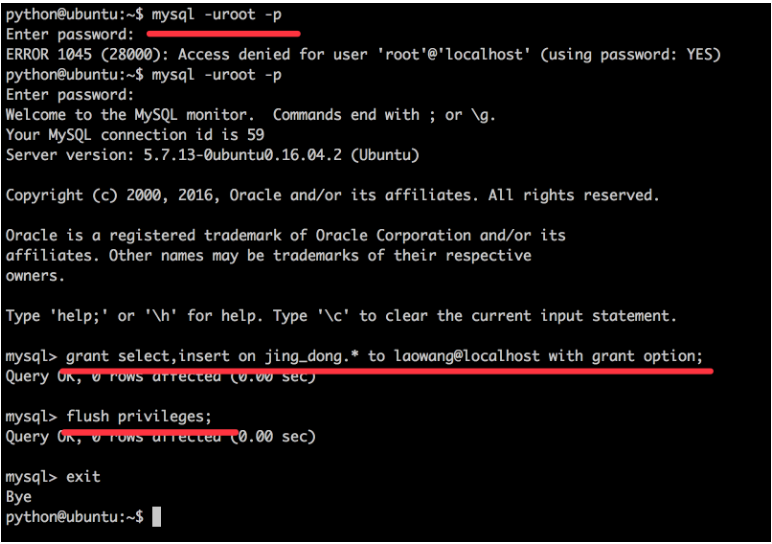
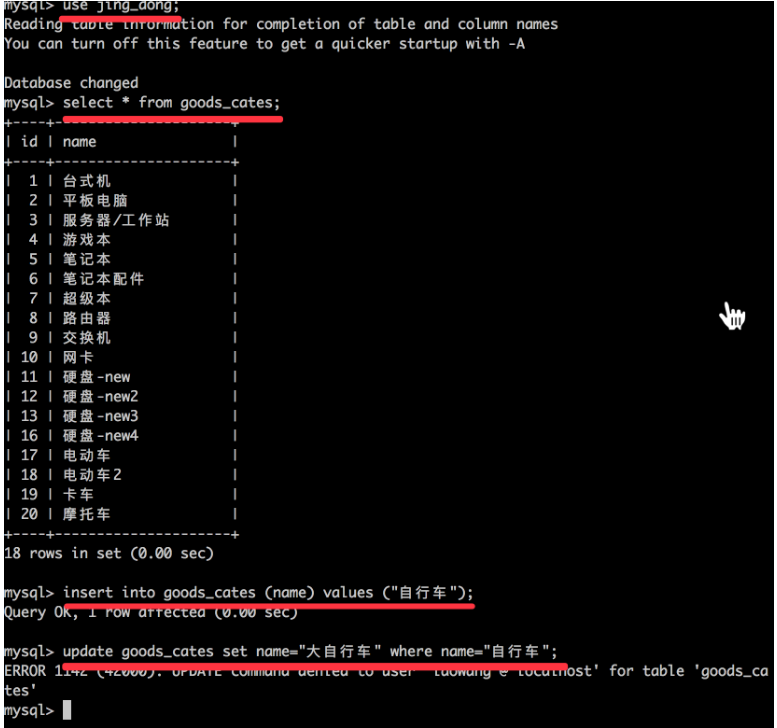
grant 权限名称 on 数据库 to 账户@主机 with grant option;
2)修改密码
使用root登录,修改mysql数据库的user表
-
使用password()函数进行密码加密
update user set authentication_string=password('新密码') where user='用户名';
例:
update user set authentication_string=password('123') where user='laowang'; -
注意修改完成后需要刷新权限
刷新权限:flush privileges
3)远程登录(危险-慎用)
如果向在一个Ubuntu中使用mysql命令远程连接另外一台mysql服务器的话,通过以下方式即可完成,但是此方法仅仅了解就好了,不要在实际生产环境中使用
修改 /etc/mysql/mysql.conf.d/mysqld.cnf 文件
vim /etc/mysql/mysql.conf.d/mysqld.cnf

然后重启msyql
service mysql restart
在另外一台Ubuntu中进行连接测试
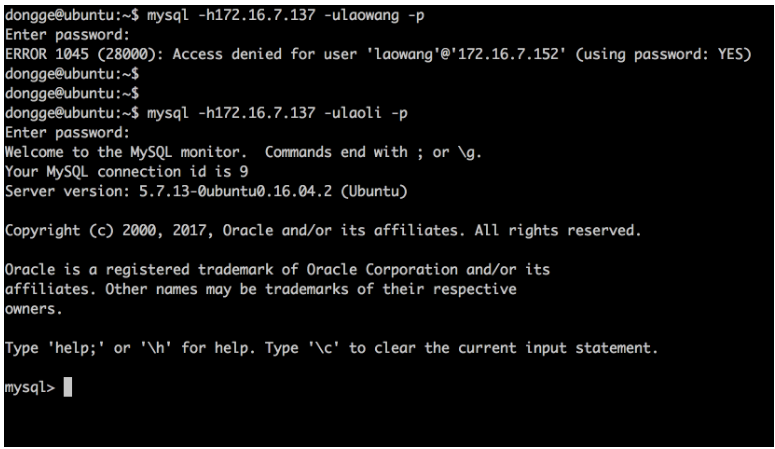
如果依然连不上,可能原因:
1) 网络不通
通过 ping xxx.xxx.xx.xxx可以发现网络是否正常
2)查看数据库是否配置了bind_address参数
本地登录数据库查看my.cnf文件和数据库当前参数show variables like 'bind_address';
如果设置了bind_address=127.0.0.1 那么只能本地登录
3)查看数据库是否设置了skip_networking参数
如果设置了该参数,那么只能本地登录mysql数据库
4)端口指定是否正确
4)删除账户
- 语法1:使用root登录
drop user '用户名'@'主机';
例:
drop user 'laowang'@'%';
- 语法2:使用root登录,删除mysql数据库的user表中数据
delete from user where user='用户名';
例:
delete from user where user='laowang';
-- 操作结束之后需要刷新权限
flush privileges
- 推荐使用语法1删除用户, 如果使用语法1删除失败,采用语法2方式
忘记 root 账户密码怎么办 ?
五,MYSQL主从
一,将主MYSQL备份到从MYSQL中
1,主数据库备份:
mysqldump -uroot -p 数据库名 > XX.sql; # 将主MYSQL备份到本地
例:
mysqldump -uroot -p --all-databases --lock-all-tables > ./master_db.sql
--all-databases : 导出所有数据库
--lock-all-tables:执行操作室锁住所有表,防止操作室有数据修改
./master_db.sql:导出的备份数据(sql文件)位置,可自己指定
2,通过ssh将备份数据导入到从数据库中:
1)在主数据库中将备份数据通过ssh传到从服务器中
scp -r master_db.sql 用户名@ip地址:/目标文件地址
2)将从服务器中的数据恢复到从数据库中
mysqldump -uroot -p 数据库名 < XX.sql; # 将本地恢复到主MYSQL
二,配置主、从 MYSQl数据库
1,配置主MYSQl数据库
1)sodu vim /etc/mysql/my.cnf 中
打开server-id、log_bin的注释,确定主从的server-id不一致(可用ip地址代替)
2)重新启动mysql服务
sudo service mysql restart
2,配置从MYSQl数据库
1)sodu vim /etc/mysql/my.cnf 中
打开server-id的注释,确定主从的server-id不一致(可用ip地址代替)
log_bin可注释掉
2)重新启动mysql服务
sudo service mysql restart
三,登入主服务器中的mysql,创建用于从服务器同步数据使用的账号
mysql -uroot -p;
GRANT REPLICATION SLAVE ON *.* TO 'slave'@'%' identified by 'slave';
PLUSH PRIVILEGES;
四,登入从服务器数据库中,输入命令:
1)show master status; # 现在主服务器中查询主服务器日志文件名、主服务器日志文件位置
2)登入从服务器数据库中,输入命令
change master to master_host = '',master_user = 'slave',master_password = 'slave',
master_log_file = 'mysql-bin.000006',master_log_pos=590;
master_host :主服务器的ip地址
master_log_file :前面查到的主服务器日志文件名
aster_log_pos:前面查到的主服务器日志文件位置
五,检查
1,在从服务器数据库中输入命令:
show slave status \G;
2,出现如下图表示成功:

