
http协议
一,什么是http协议
HTTP协议就是超文本传输协议(HyperText Transfer Protocol),通俗理解是浏览器和web服务器传输数据格式的一种协议约定,都是基于tcp协议发送的字符串或二进制的数据。
HTTP协议是基于TCP协议的,发送数据之前需要建立好连接
HTTP协议是万维网的数据通信的基础。设计HTTP最初的目的是为了提供一种发布和接收HTML页面<网页>的方法。
二,http协议下浏览器请求基本流程:
浏览器请求的基本流程如下:
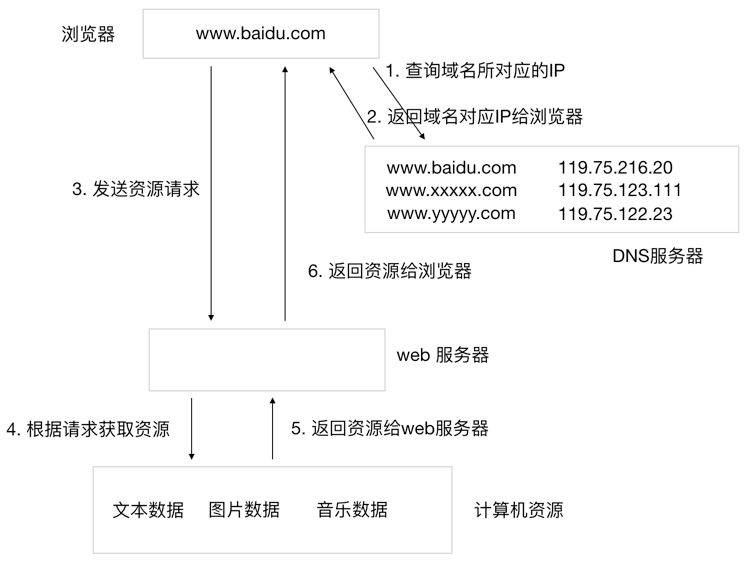
- 用户输入网址.
- 浏览器请求DNS服务器, 获取域名对应的IP地址.
- 请求连接该IP地址服务器.
- 发送资源请求. (HTTP协议)
- web服务器接收到请求, 并解析请求, 判断用户意图.
- 获取用户想要的资源.
- 将资源返回给web服务器程序.
- web服务器程序将资源数据通过网络发送给浏览器.
- 浏览器解析请求的数据并且完成网页数据的显示.
三,什么是网址(URL)
网址又称为URL,URL的英文全拼是(Uniform Resoure Locator),表达的意思是统一资源定位符,通俗理解就是网络资源地址。
四,URL的组成部分
URL的组成部分大概分为三部分:
- 协议部分
- 域名部分
- 资源路径部分
比如: http://news.china.com.cn/2018-06/12/content_52060465.html 中:
URL的格式为:
协议部分: http://:
域名部分: news.china.com.cn
资源路径部分: /2018-06/12/content_52060465.html
五,什么是域名
我们在访问一台服务器的时候, 需要记住该服务器的IP地址, 由于IP地址不利于人们记忆, 所以推出的域名技术. 域名是由一串用点分隔的名字组成的 Internet 上某一台计算机或计算机组的名称, 用于在数据传输时标识计算机的位置.
域名可以用来表示一个单位、机构或可以利用个人在 Internet上 的确定的名称或位置. 域名是惟一的. 客户可以利用这个名字找寻有关的产品和服务信息.
六,什么是DNS
由于我们用域名来标识计算机的位置, 但是网络上标识主机的唯一标识是IP地址, 所以就需要记录一下, 一个域名和IP地址的对应关系, 这个对应关系就存储在DNS服务器中, 当我们向DNS发出请求时, DNS会返回给我们域名所对应的IP地址.
总结:
1,浏览器访问服务器其实就是请求和响应的过程
2,URL通俗理解就是请求资源在网络中的地址
3,通过域名可以解析出来一个ip地址,域名是方便大家记忆某台主机地址的。
七,开发者工具界面中选项的作用
1,元素(Elements):用于查看或修改HTML元素的属性、CSS属性、监听事件、断点等.
2,控制台(Console):控制台一般用于执行一次性代码, 查看JavaScript对象, 查看调试日志信息或异常信息.
3,源代码(Sources):该页面用于查看页面的HTML文件源代码、JavaScript源代码、CSS源代码, 此外最重要的是可以调试JavaScript源代码, 可以给JS代码添加断点等.
4,网络(Network):网络页面主要用于查看 header 等与网络连接相关的信息.
注意: Network 中的每一项就是一次请求/响应过程, 点击每一项, 可查看本次请求响应的报文信息.
八,HTTP 请求报文协议分析
Request Headers 中就是请求的报文数据内容. 下面就是我们要请求的报文示例数据:
GET / HTTP/1.1
Host: www.baidu.com
Connection: keep-alive
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8,zh-TW;q=0.7
Cookie:BAIDUID=DF38C56A5F133B3DFC53B75AEAF3D9BF:FG=1; BIDUPSID=DF38C56A5F133B3DFC53B75AEAF3D9BF; PSTM=1499759906; BD_UPN=12314353; sugstore=0; H_PS_PSSID=1429_21112_27509; MCITY=-340%3A; ispeed_lsm=3;1,GET / HTTP/1.1 (叫做请求行. 里面包含3个信息, 以空格隔开:)
第一个叫做请求方法, 除了 GET 方法之外, 还有 POST 方法, 除此之外还有其他方法, 这两种最常用. GET 主要用于从服务器获得数据, POST 主要用于从浏览器提交数据到服务器. 比如像百度首页提供的上传图片的功能, 就是用POST方式.
第二个表示请求的资源路径. 当请求的URL是 https://www.baidu.com/, 那么我们会发现 路径会显示 '/', 那么如果请求的URL是 https://www.baidu.com/index.html, 我们会发现路径显示是 '/index.html'.
第三个表示 HTTP 协议的版本, 那么既然有 1.1版本, 前置版本肯定是1.0了,那么两个版本有什么区别呢? 实现长连接、加入host字段、加入post字段
2,Host
表示浏览器要请求的主机地址. 请求不同的网站, 会有不同的主机地址.
3,Connection
表示浏览器和服务器之间的连接方式, 浏览器和服务器连接是长连接还是短连接.
4,User-Agent
用户代理, 我们使用谷歌浏览器和火狐浏览器分别请求百度, 那么会发现 User-Agent 的值是不一样的, 它主要是用于浏览器告诉服务器自己的身份, 比如浏览器端使用的操作系统是什么版本, 浏览器是什么版本等等. 服务器端为什么需要知道这个信息呢? 我们后面会讲到爬虫,爬虫程序主要是从服务器端获取数据, 那么服务器端就会有反爬机制, 服务器不希望爬虫来获取数据, 所以通过该项可以知道客户端是否是爬虫程序. 如果爬虫程序想伪装成一个浏览器的请求, 就必须设置此项.
5,Accept
表示浏览器告诉服务器, 自己能够接收并识别的文件类型.
6,Accept-Encoding
表示浏览器能够处理的压缩方式. 为什么需要压缩呢? 当网页数据量大的时候, 压缩之后可以提高传输速率, 提高用户体验.
7,Accept-Language
浏览器可以接收的文本语言, 如果非中文编码可能会出现乱码.
8,Cookie
过去浏览器的访问记录
注意:
HTTP请求报文可以分为GET请求和POST请求报文,要注意的是GET请求没有请求体,POST请求有请求体信息

九,HTTP 响应报文协议分析
Response Headers 中就是回复的报文数据内容. 下面就是我们要回复的报文示例数据:
HTTP/1.1 200 OK
Connection: Keep-Alive
Content-Encoding: gzip
Content-Type: text/html; charset=utf-8
Date: Wed, 14 Mar 2018 09:52:48 GMT
Server: BWS/1.1
1,第一行 HTTP/1.1 200 OK 叫做响应行, 共分成3部分
第一部分 HTTP/1.1 表示 HTTP协议的版本
第二部分是一个数字, 这个数字表示响应状态码, 用户向服务器发出了请求, 如果服务器正常返回响应报文, 那么状态码一般都是200
第三部分的 "OK" 表示原因短语, 表示对前面状态码的简单描述. 这里需要说的是, 响应的状态码除了 200 之外, 还有其他的状态码,
下面是常见的状态码:302 redirect、404 NOT FOUND、500 Internal Server Error、
2,第二行下面的所有内容, 我们叫做响应头. Content-Type 表示响应内容的文本格式和编码方式.

HTTP协议响应报文分为4部分,每部分之间使用\r\n进行分割
响应行
响应头
空行(\r\n)
响应体
十,长连接和短连接
十一,模拟浏览器的代码实现
import socket
import re
import threading
def service_client(new_socket):
while True :
info = new_socket.recv(1024)
if info :
file_name = ''
ret = re.match(r'[^/]+([^ ]*)',info.decode('utf-8'))
if ret:
file_name = ret.group(1)
print(file_name)
if file_name == '/':
file_name = '/index.html'
try :
file_name = open('./html'+file_name,'rb')
except:
response = 'HTTP/1.1 404 Not Found \r\n'
response += '\r\n'
response += 'you can not find the file!!!'
new_socket.send(response.encode('utf-8'))
else:
response_body = file_name.read()
file_name.close()
response_head = 'HTTP/1.1 200 OK \r\n'
response_head += 'Content-Length: %d \r\n' % len(response_body)
response_head += '\r\n'
response = response_head.encode('utf-8') + response_body
new_socket.send(response)
else:
new_socket.close()
break
def main():
tcp_socket = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
tcp_socket.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1)
tcp_socket.bind(('',8880))
tcp_socket.listen(128)
while True :
new_socket,idcode = tcp_socket.accept()
p = threading.Thread(target = service_client,args = (new_socket,))
p.start()
#new_socket.close()
tcp_socket.close()
if __name__ == '__main__':
main()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号