
oracle中merge into用法总结
merge into的形式:
MERGE INTO table_name alias1
USING (table|view|sub_query) alias2
ON (join condition)
WHEN MATCHED THEN
UPDATE SET alias1.col1=:col1_val, alias1.col2 = :col2_val
WHEN NOT MATCHED THEN
INSERT(column_list) VALUES (column_values);
作用:在alias2中Select出来的数据,每一条都跟alias1进行ON (join condition)的比较,如果匹配,就进行更新的操作(Update),如果不匹配,就进行插入操作(Insert)。如果select没有数据,则更新和插入操作都不执行。
也可以单表只更新:
merge into list_parts t1 using(select refnum,price from(select refnum,price,row_number()over(partition by refnum order by createtime desc) rn from list_pro) where rn = 1)t2 on(t1.refnum = t2.refnum) when matched then update set t1.price = t2.price where t1.parentId = '1';
或者:
MERGE INTO T T1 USING (SELECT count(1) cnt FROM t where t.a='1001') T2 ON ( T2.cnt>0) WHEN MATCHED THEN UPDATE SET T1.b = T2.b WHEN NOT MATCHED THEN INSERT (a,b) VALUES('1001',2);
两张表操作有很多可选项,如下:
1.正常模式
2.只update或者只insert
3.带条件的update或带条件的insert
4.全插入insert实现
5.带delete的update(觉得可以用3来实现)
下面一一测试。
测试建以下表:

create table A_MERGE ( id NUMBER not null, name VARCHAR2(12) not null, year NUMBER ); create table B_MERGE ( id NUMBER not null, aid NUMBER not null, name VARCHAR2(12) not null, year NUMBER, city VARCHAR2(12) ); create table C_MERGE ( id NUMBER not null, name VARCHAR2(12) not null, city VARCHAR2(12) not null ); commit;
其表结构截图如下图所示:
A_MERGE表结构:
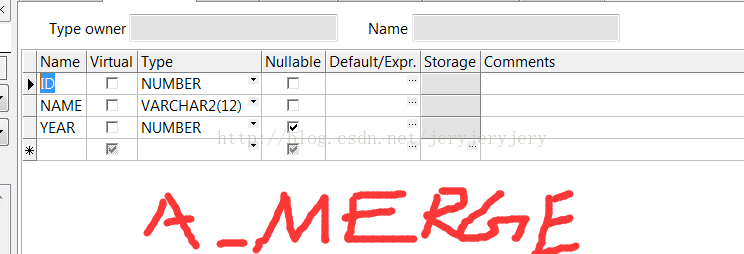
B_MERGE表结构
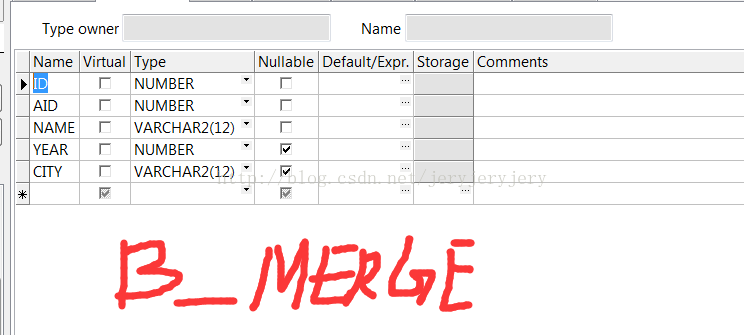
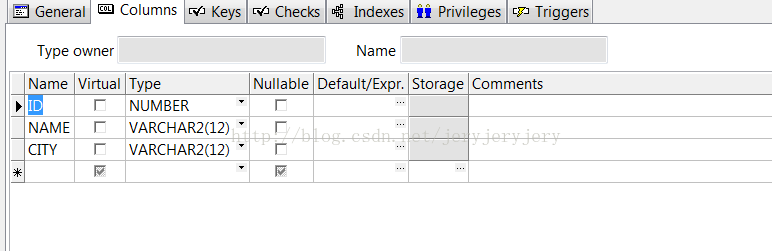
C_MERGE表结构
1.正常模式
先向A_MERGE和B_MERGE插入测试数据:
insert into A_MERGE values(1,'liuwei',20); insert into A_MERGE values(2,'zhangbin',21); insert into A_MERGE values(3,'fuguo',20); commit; insert into B_MERGE values(1,2,'zhangbin',30,'吉林'); insert into B_MERGE values(2,4,'yihe',33,'黑龙江'); insert into B_MERGE values(3,3,'fuguo',,'山东'); commit;
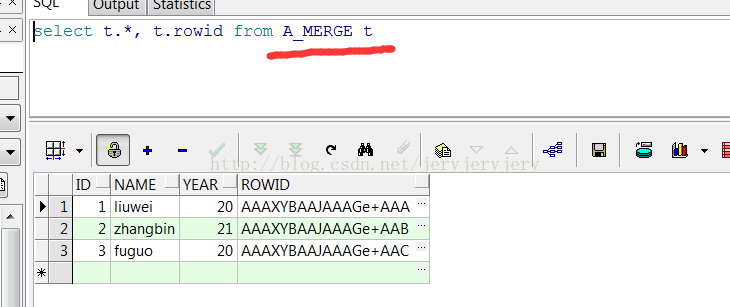
此时A_MERGE和B_MERGE表中数据截图如下:
A_MERGE表数据:
B_MERGE表数据:
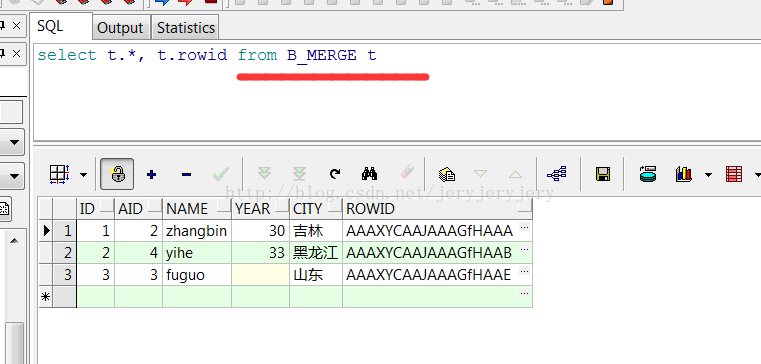
然后再使用merge into用B_MERGE来更新A_MERGE中的数据:
MERGE INTO A_MERGE A USING (select B.AID,B.NAME,B.YEAR from B_MERGE B) C ON (A.id=C.AID) WHEN MATCHED THEN UPDATE SET A.YEAR=C.YEAR WHEN NOT MATCHED THEN INSERT(A.ID,A.NAME,A.YEAR) VALUES(C.AID,C.NAME,C.YEAR); commit;
此时A_MERGE中的表数据截图如下:
2.只update模式
首先向B_MERGE中插入两个数据,来为了体现出只update没有insert,必须有一个数据是A中已经存在的
另一个数据时A中不存在的,插入数据语句如下:
insert into B_MERGE values(4,1,'liuwei',80,'江西'); insert into B_MERGE values(5,5,'tiantian',23,'河南'); commit;
此时A_MERGE和B_MERGE表数据截图如下:
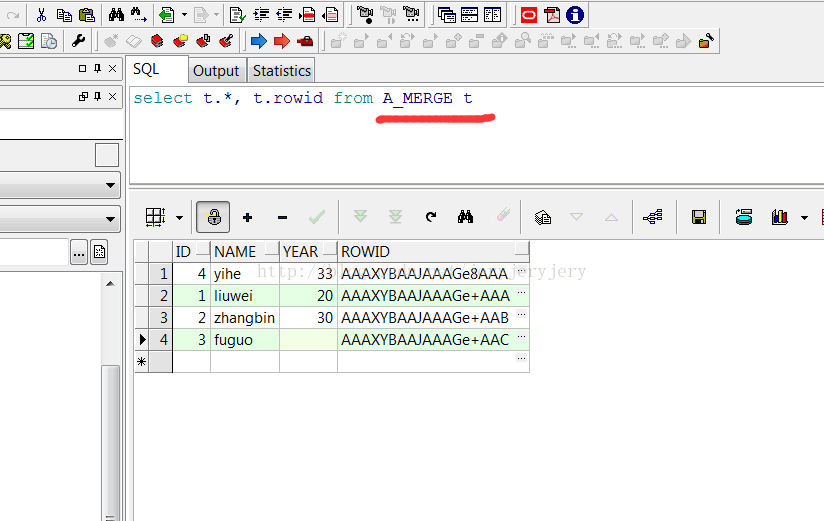
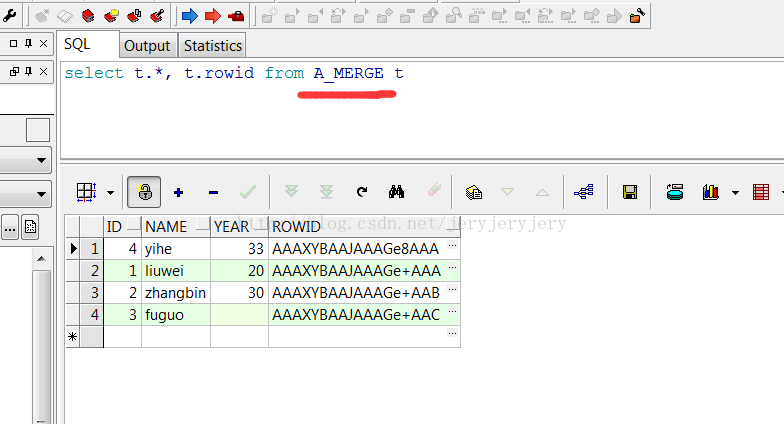
A_MERGE表数据截图:
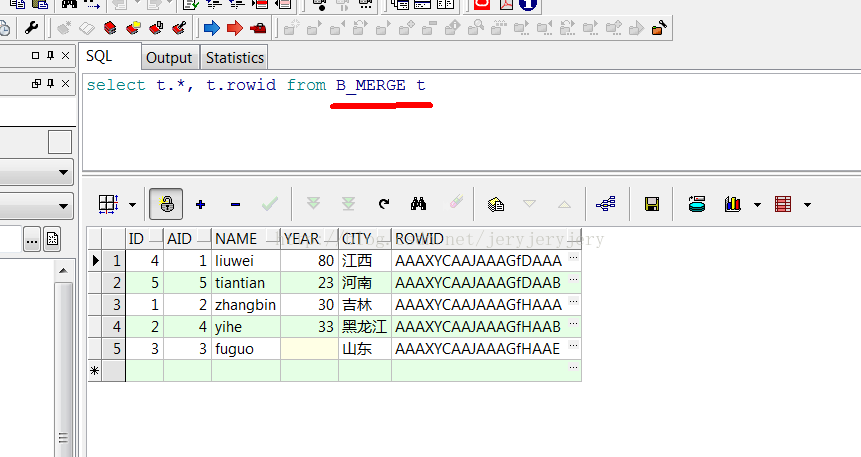
B_MERGE表数据截图:
然后再次用B_MERGE来更新A_MERGE,但是仅仅update,没有写insert部分。
merge into A_MERGE A USING (select B.AID,B.NAME,B.YEAR from B_MERGE B) C ON(A.ID=C.AID) WHEN MATCHED THEN UPDATE SET A.YEAR=C.YEAR; commit;
merge完之后A_MERGE表数据截图如下:可以发现仅仅更新了AID=1的年龄,没有插入AID=4的数据
3.只insert模式
首先改变B_MERGE中的一个数据,因为上次测试update时新增的数据没有插入到A_MERGE,这次可以用。
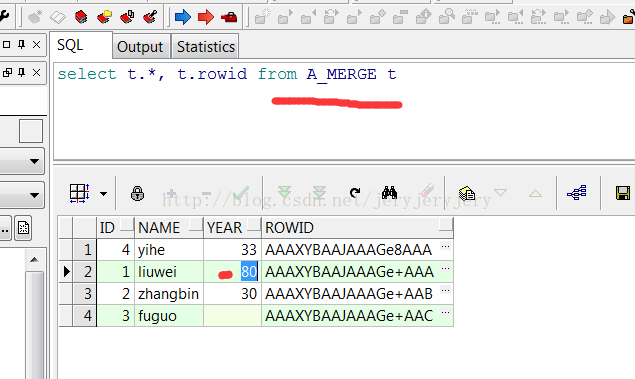
update B_MERGE set year=70 where AID=2; commit;
此时A_MERGE和B_MERGE的表数据截图如下:
A_MERGE表数据:
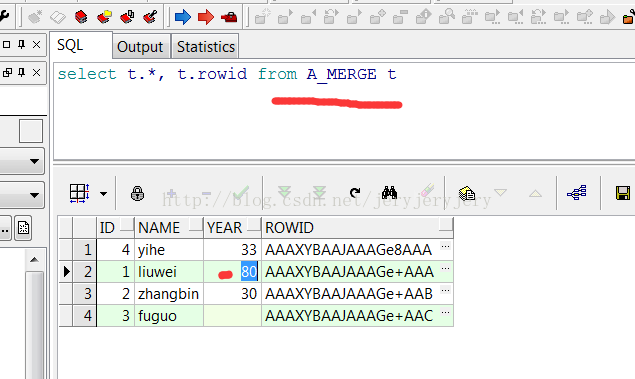
B_MERGE表数据:
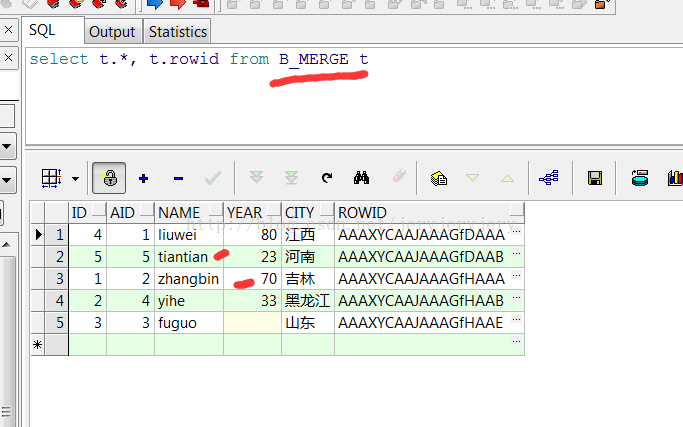
然后用B_MERGE来更新A_MERGE中的数据,此时只写了insert,没有写update:
merge into A_MERGE A USING (select B.AID,B.NAME,B.YEAR from B_MERGE B) C ON(A.ID=C.AID) WHEN NOT MATCHED THEN insert(A.ID,A.NAME,A.YEAR) VALUES(C.AID,C.NAME,C.YEAR); commit;
此时A_MERGE的表数据截图如下:
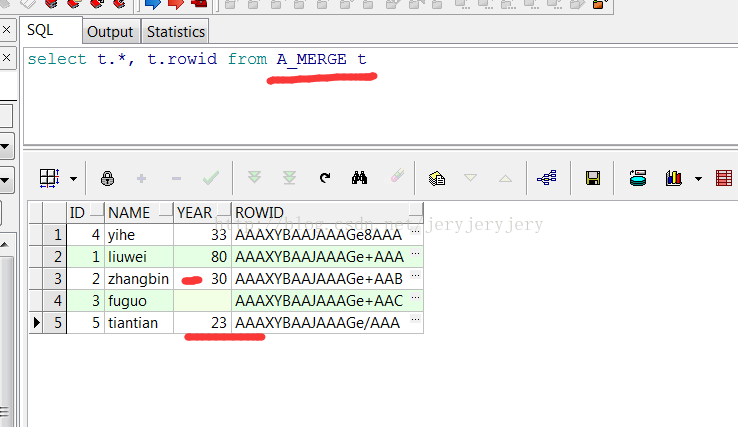
4.带where条件的insert和update。
我们在on中进行完条件匹配之后,还可以在后面的insert和update中对on筛选出来的记录再做一次条件判断,用来控制哪些要更新,哪些要插入。
测试数据的sql代码如下,我们在B_MERGE修改了两个人名,并且增加了两个人员信息,但是他们来自的省份不同,
所以我们可以通过添加省份条件来控制哪些能修改,哪些能插入:
update B_MERGE set name='yihe++' where id=2; update B_MERGE set name='liuwei++' where id=4; insert into B_MERGE values(6,6,'ningqin',23,'江西'); insert into B_MERGE values(7,7,'bing',24,'吉安'); commit;
A_MGERGE表数据截图如下:
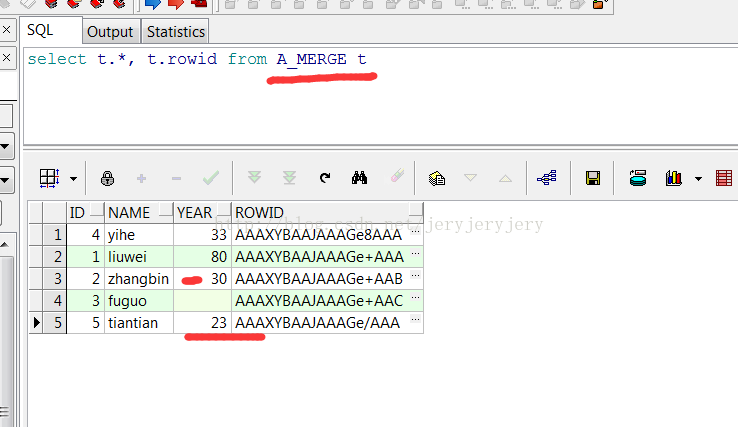
B_MERGE表数据:
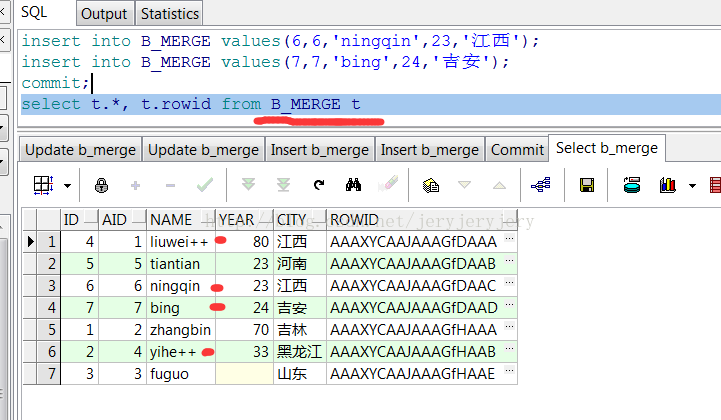
然后再用B_MERGE去更新A_MERGE,但是分别在insert和update后面添加了条件限制,控制数据的更新和插入:
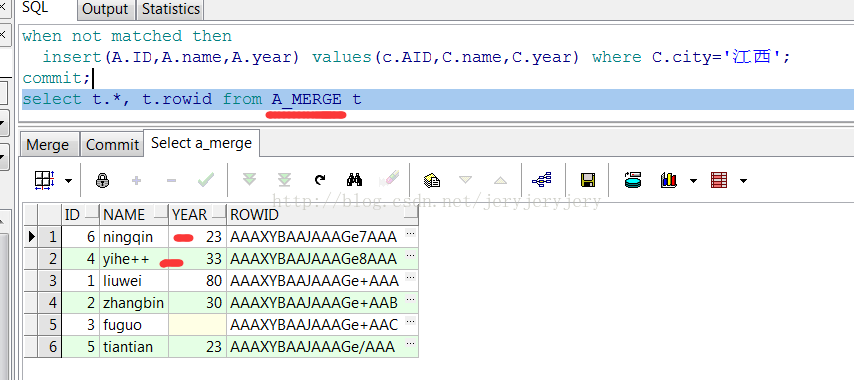
merge into A_MERGE A USING (select B.AID,B.name,B.year,B.city from B_MERGE B) C ON(A.id=C.AID) when matched then update SET A.name=C.name where C.city != '江西' when not matched then insert(A.ID,A.name,A.year) values(c.AID,C.name,C.year) where C.city='江西'; commit;
此时A_MERGE截图如下:
5.无条件的insert。
有时我们需要将一张表中所有的数据插入到另外一张表,此时就可以添加常量过滤谓词来实现,让其只满足
匹配和不匹配,这样就只有update或者只有insert。这里我们要无条件全插入,则只需将on中条件设置为永假
即可。用B_MERGE来更新C_MERGE代码如下:
C_MERGE表在merge之前的数据截图如下:
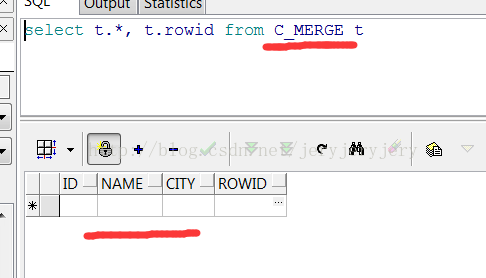
B_MERGE数据截图如下:
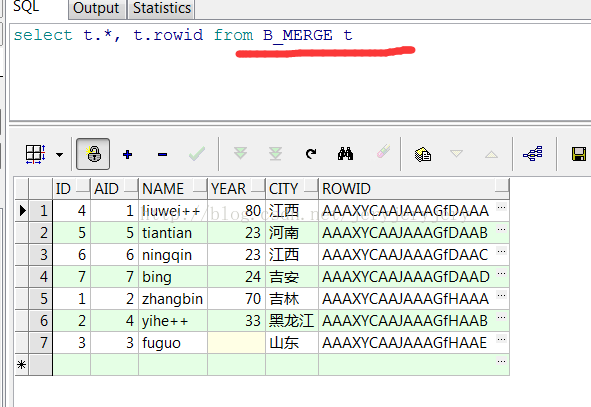
C_MERGE表在merge之后数据截图如下:
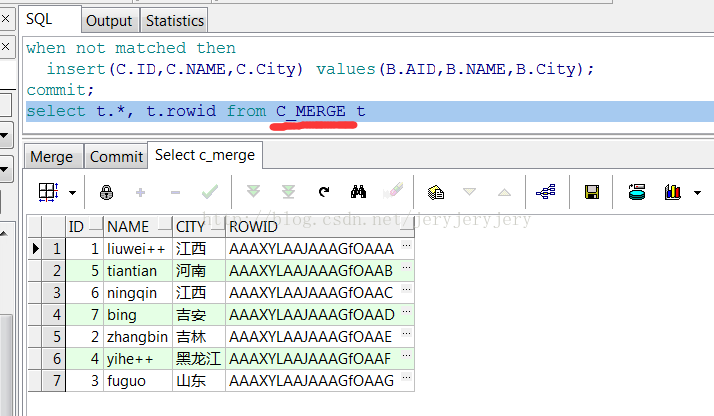
6.带delete的update
MERGE提供了在执行数据操作时清除行的选项. 你能够在WHEN MATCHED THEN UPDATE子句中包含DELETE子句.
DELETE子句必须有一个WHERE条件来删除匹配某些条件的行.匹配DELETE WHERE条件但不匹配ON条件的行不会被从表中删除.
但我觉得这个带where条件的update差不多,都是控制update,完全可以用带where条件的update来实现。
注意:
1,更新的字段,不允许有关联条件的字段(join condition)。比如条件是 A.ID=B.ID,那么使用“SET A.ID=B.ID”将报出一个莫名其妙的提示错误;
2,update语句不是正常的sql语句,update set alias1.col1=:col1_val,alias1.col2=:col2_val;
3,insert语句不是正常的sql语句,insert(cols) values(col_values);
4,merge语句是全量更新,假如该字段传一个空值,则会把数据库中本来有值的字段更新成空值;
5,using (select :col1 col1 from dual) t on(s.col1=t.col1),其中col1最好是主键,这样搜索速度会快点。
6,using (select col1, id from table1 order by id) t,id最好是主键或者唯一索引,加order by id,是为了排序,这样顺序匹配可以避免ora-00060 dead-lock detect死锁问题。
本文转自:https://blog.csdn.net/jeryjeryjery/article/details/70047022


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 理解Rust引用及其生命周期标识(上)
· 浏览器原生「磁吸」效果!Anchor Positioning 锚点定位神器解析
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?