MongoDB之路
介绍
MongoDB属于NoSql的一种,且是属于NoSql中的基于分布式文件存储的文档型数据库。由C++语言编写,旨在为WEB应用提供可扩展的高性能数据存储解决方案。
# MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。它支持的数据结构非常松散,是类似json的bson(是一种类json的一种二进制形式的存储格式,简称Binary JSON)格式,因此可以存储比较复杂的数据类型。Mongo最大的特点是他支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。
MongoDB特点是高性能、易部署、易使用,存储数据非常方便,最大的特点在于它支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系型数据库单表
查询的绝大部分功能,而且还支持对数据建立索引。MongoDB的主要特点总结如下:
- 1)提供了一个面向集合的文档存储,易存储对象类型的数据,操作起来比较简单和容易的非关系型数据库
- 2)使用update()命令可以实现替换完成的文档(数据)或者一些指定的数据字段。
- 3)支持动态查询。
- 4)支持完全索引,包含内部对象,可以在MongoDB记录中设置任何属性的索引来实现更快的排序。
- 5)支持复制和故障恢复。
- 6)使用高效的二进制数据存储,包括大型对象(如视频等)。
- 7)GridFS是MongoDB中的一个内置功能,可以用于存放大量小文件。
- 8)自动处理碎片,以支持云计算层次的扩展性;如果负载的增加(需要更多的存储空间和更强的处理能力),它可以分布在计算机网络中的其它节点上,这就是所谓的分片。
- 9)支持RUBY,PYTHON,JAVA,C++,PHP,C``#等多种语言。
- 10)文件存储格式为BSON(一种JSON的扩展),MongoDB支持丰富的查询表达式,查询指令使用JSON形式的标记,可轻易查询文档中内嵌的对象和数组。
- 11)MongoDB允许在服务端执行脚本,可以用JavaScript编写某个函数,直接在服务端执行,也可以吧函数的定义存储在服务端,下次直接调用即可。
- 12)可通过网络访问,可以通过本地u或者网络创建数据镜像,这使得MongoDB含有更强的扩展性。
- 1)在集群分片中的数据分布不均匀
- 2)单机可靠性比较差
- 3)大数据量持续插入,写入性能有较大波动
- 4)磁盘空间占用比较大。空间占用大的原因如下:
- 空间的预分配:为避免形成过多的硬盘碎片,mongodb 每次空间不足时都会申请生成一大块的硬盘空 间,而且申请的量从 64M、128M、256M 那样的指数递增,直到2G为单个文件的最大体积。随着数据量 的增加,你可以在其数据目录里看到这些整块生成容量不断递增的文件。
- 字段名所占用的空间:为了保持每个记录内的结构信息用于查询,mongodb 需要把每个字段的 key-value 都以 BSON 的形式存储,如果 value 域相对于 key 域并不大,比如存放数值型的数据,则数据的 overhead 是最大的。一种减少空间占用的方法是把字段名尽量取短一些,这样占用 空间就小了,但这就要求在易读 性与空间占用上作为权衡了。
- 删除记录不释放空间:这很容易理解,为避免记录删除后的数据的大规模挪动,原记录空间不删除,只 标记“已删除”即可,以后还可以重复利用。
- 可以定期运行 db.repairDatabase()来整理记录,但这个过程会比较缓慢
-
-
缓存:由于性能很高,MongoDB 也适合作为信息基础设施的缓存层。在系统重启之后,由 MongoDB 搭建的持久 化缓存层可以避免下层的数据源过载
-
大尺寸,低价值的数据:使用传统的关系型数据库存储一些数据时可能会比较昂贵,在此之前,很多时候程序员往往会选择传统的文件进行存储
-
高伸缩性的场景:MongoDB 非常适合由数十或数百台服务器组成的数据库。MongoDB的路线图中已经包含对 MapReduce 引擎的内置支持
-
用于对象及 JSON 数据的存储:MongoDB 的 BSON 数据格式非常适合文档化格式的存储及查询
-
-
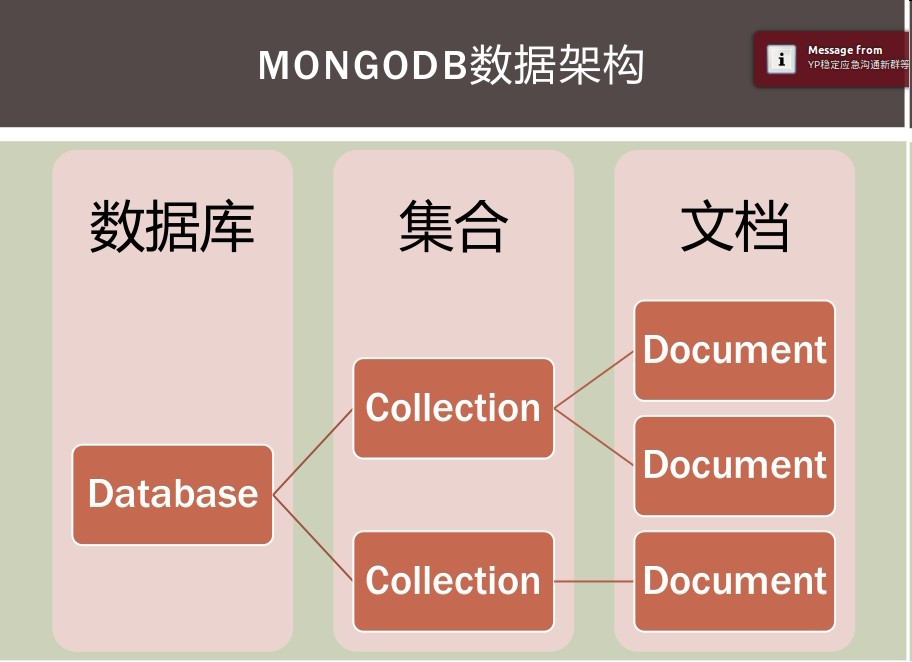
集合(collection)就是一组文档,类似数组
-
多个文档组成集合,多个集合组成数据库
key: 必须为字符串类型
value:可以包含如下类型
-
基本类型,例如,string,int,float,timestamp,binary 等类型
-
一个document
-
数组类型

MongoDB下载地址 <!--PS:包含windows、Linux、macos,在MongoDB2.2版本后不再支持windows XP -->

windows版本:下载安装包,一直下一步即可。
Linux版本:下载 ---->解压缩
wget https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-4.0.10.tgz
tar xzvf mongodb-linux-x86_64-4.0.10.tgz
体系结构

-
-
分片集群部署中,数据和查询的路由服务(mongos)
-
shell客户端(mongo)
-
导入导出工具(mongoimport / mongoexport)
-
备份恢复工具(mongodump / mongorestore)
-
拉取并重放oplog的工具(mongooplog)
-
监控工具(mongostat、mongotop、mongosniff)
-
GridFS的命令行操作工具(mongofiles)
-
性能测试工具(mongoperf,暂时只能测I/O)
-
查看bson文件的工具(bsondump)
在一台服务器上,可以启动多个mongod服务。但在实际生产部署中,通常还是建议一台服务器部署一个mongod实例,这样不仅减少资源竞争,而且服务器故障也不会同时影响到多个服务。
在 安装目录/bin 下,有一个 mongod.exe 的应用程序
PS:在windows下需配置环境变量(在安装目录下找到bin目录,将路径添加至环境变量中)
在4.0版本在安装完成时已生成Windows服务,只需 net start MongoDB ,然后启个客户端输入 mongo
基本指令
show dbs //等同于 show databases use 库名 //进入数据库 PS:没有库也可以进入,当插入第一条数据会自动创建库 db //代表当前所在数据库 show collections //等同于 show tables 查看所有集合(表)
db.collection.insert({ "key" : "value" })
在MongoDB中,插入操作以单个集合为目标。MongoDB中的所有写入操作都是单个文档级别的 原子操作。
-
db.collection.insertOne()版本3.2中的新功能 -
db.collection.insertMany()版本3.2中的新功能

查询
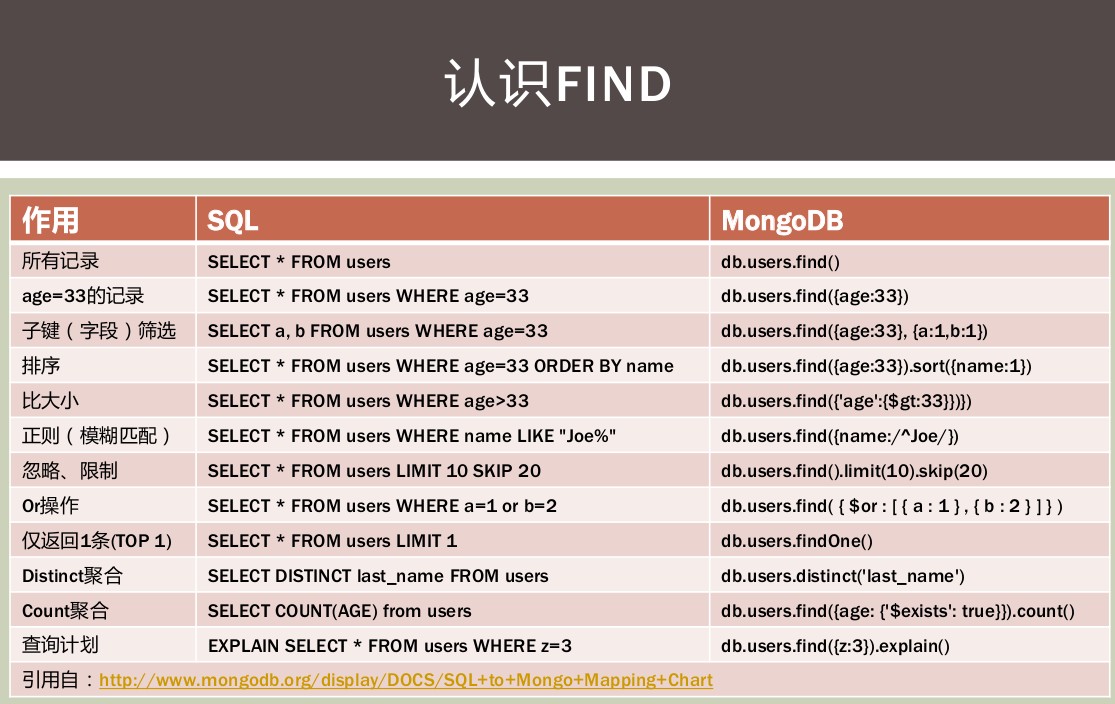
查询文档集合
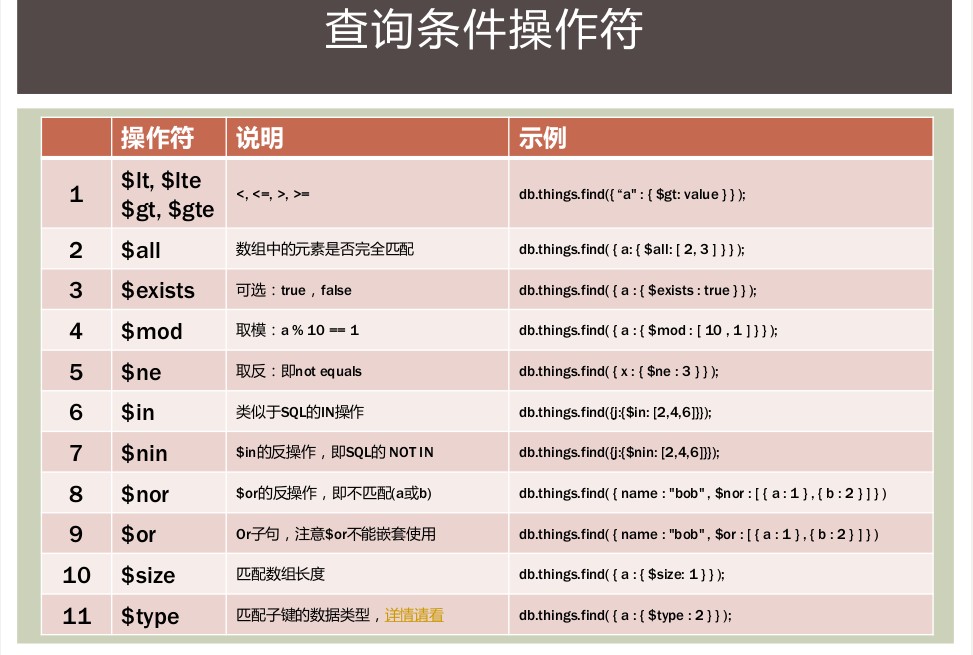
db.collection.find() 可以指定过滤条件

db.collection.update(<query>, <update>, upsert, multi, writeConcern) #可以指定过滤条件
- <query> : update的查询条件,类似sql update查询内where后面的。
- <update> : update的对象和一些更新的操作符(如$,$inc...)等,也可以理解为sql update查询内set后面的
- upsert:可选,如果不存在update的记录,是否插入objNew, true为插入,默认是false,不插入。
- multi : 可选,默认是false,只更新找到的第一条记录,如果这个参数为true,就把按条件查出来多条记录全部更新。
- writeConcern :可选,抛出异常的级别。
在MongoDB中,更新操作以单个集合为目标。MongoDB中的所有写入操作都是单个文档级别的原子
-
db.collection.updateOne()版本3.2中的新功能 -
db.collection.updateMany()版本3.2中的新功能 -
db.collection.replaceOne()版本3.2中的新功能


#只更新第一条记录 年龄小于20的youth设置为yes db.collection.update( { "age" : { $lt : 20 } } , { $set : { "youth" : "yes"} } ); #全部更新 年龄小于20的 youth设置为yes db.collection.update( { "age":{ $lt : 20 } },{ $set : { "youth" : "yes"} },false,true ); #只添加一条记录 给年龄大于30的 一个 添加"youth" : "no" db.collection.update( { "age":{ $gt : 20 } },{ $set : { "youth" : "no"} },true,false ); #全部添加 给年龄大于30的 全部 添加"youth" : "no" db.collection.update( { "age":{ $gt : 30 } },{ $set : { "youth" : "no"} },true,true );


前戏
from pymongo import MongoClient def getconn(): try: conn = MongoClient('127.0.0.1',27017) return conn except: print('数据库连接失败') conn = getconn()
#查看数据库 dblist = conn.list_database_names() print(dblist) #查看集合 collection_list = conn['user'].list_collection_names() print(collection_list)


#集合数据 data = [ { 'author': '小红', 'title': 'MySQL底层原理', 'content': '信息存储在硬盘里,硬盘是由很多的盘片组成,通过盘片表面的磁性物质来存储数据。' '把盘片放在显微镜下放大,可以看到盘片表面是凹凸不平的,凸起的地方被磁化,代表数字 1,凹的地方没有被磁化,代表数字 0,因此硬盘可以通过二进制的形式来存储表示文字、图片等的信息。' '硬盘有很多种,但是都是由盘片、磁头、盘片主轴、控制电机、磁头控制器、数据转换器、接口、缓存等几个部分组成', 'tags': ['MySQL', 'PostgreSQL'], 'comments': [ {'name': 'WangQQ', 'detail': '写的什么垃圾。。。', 'date': '2019-07-27 13:38:49'}, {'name': 'RengPL', 'detail': '写的看不懂--!', 'date': '2019-07-27 13:48:49'}, {'name': 'HongLP', 'detail': '天天摸鱼', 'date': '2019-07-27 13:58:49'}], 'readcount': 999 }, {'author': 'NiXin', 'title': '1+1等于几', 'content': '有的人说1+1=2,因为这是老师从小告诉我们的;而有的人说1+1=11,这是两个1的组合;但是有些人就认为1+1=1,他们觉得1个团队加上另一个团队,会组成了一个更强大的团队!', 'tags': '十万个为什么', 'comments': [ {'name': 'WangQQ', 'detail': '标题党', 'date': '2019-07-27 13:38:49'}, {'name': 'RengPL', 'detail': '好像很有道理', 'date': '2019-07-27 13:48:49'}, {'name': 'HongLP', 'detail': '你有个bug', 'date': '2019-07-27 13:58:49'}], 'readcount': 998 }, {'author': '洪哥', 'title': '论摸鱼的重要性', 'content': '摸鱼是一种方法,是一种探索,更是一种乐趣!!!', 'tags': '座右铭', 'comments': [ {'name': 'WangQQ', 'detail': '点赞!', 'date': '2019-07-27 13:38:49'}, {'name': 'RengPL', 'detail': '。。。', 'date': '2019-07-27 13:48:49'}, {'name': '小红', 'detail': '学习中。。。', 'date': '2019-07-27 13:58:49'}], 'readcount': 1998, 'isTop': True }, {'author': 'WangQQ', 'title': 'ElasticSearch', 'content': 'ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。' 'Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。ElasticSearch用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。' '官方客户端在Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和许多其他语言中都是可用的。根据DB-Engines的排名显示,Elasticsearch是最受欢迎的企业搜索引擎,其次是Apache Solr,也是基于Lucene。', 'tags': 'NoSQL', 'comments': [ {'name': 'HongLP', 'detail': '写的不错,和百度百科一样么', 'date': '2019-07-27 13:38:49'}, {'name': 'RengPL', 'detail': '666', 'date': '2019-07-27 13:48:49'}, {'name': '小红', 'detail': '详细说说ES源码呗?', 'date': '2019-07-27 13:58:49'}], 'readcount': 1020, }, {'author': 'RengPL', 'title': 'redis', 'content': 'redis是一个key-value存储系统。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。' '这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。' '区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。', 'tags': '座右铭', 'comments': [ {'name': 'WangQQ', 'detail': 'redis为什么叫redis', 'date': '2019-07-27 13:38:49'}, {'name': 'nixin', 'detail': '点赞!!', 'date': '2019-07-27 13:48:49'}, {'name': '小红', 'detail': '有点6', 'date': '2019-07-27 13:58:49'}], 'readcount': 1203, }, { 'author': '小红', 'title': '如何快速写代码', 'content': 'Pycharm中的宏功能可以帮助我们快速的插入常用的代码,教程百度一堆,当然复制粘贴是必不可少的。', 'tags': ['MySQL', 'PostgreSQL'], 'comments': [ {'name': 'WangQQ', 'detail': '又水了一篇', 'date': '2019-07-28 13:38:49'}, {'name': 'RengPL', 'detail': '一本正经偷懒', 'date': '2019-07-28 13:48:49'}, {'name': 'HongLP', 'detail': '很对', 'date': '2019-07-28 13:58:49'}], 'readcount': 78 }, { 'author': 'NiXin', 'title': 'MongoDB高级聚合查询', 'content': '聚合查询----> https://www.cnblogs.com/zhoujie/p/mongo1.html', 'tags': 'MongoDB', 'comments': [ {'name': 'WangQQ', 'detail': '日常点踩', 'date': '2019-07-28 13:38:49'}, {'name': 'RengPL', 'detail': '。。。', 'date': '2019-07-28 13:48:49'}, {'name': 'HongLP', 'detail': '很对,很对', 'date': '2019-07-28 13:58:49'}], 'readcount': 178 }, {'author': '洪哥', 'title': '明天吃什么', 'content': '这篇文章的意义是很有意义的,表达了老夫对明日的憧憬。。(巴拉巴拉)。。。。好了又水一篇。', 'tags': '座右铭', 'comments': [ {'name': 'WangQQ', 'detail': '西兰花我的最爱', 'date': '2019-07-29 13:38:49'}, {'name': 'RengPL', 'detail': '随便吃点', 'date': '2019-07-29 13:48:49'}, {'name': '小红', 'detail': '剁椒鱼头,你值得拥有', 'date': '2019-07-29 13:58:49'}], 'readcount': 250, }, {'author': 'WangQQ', 'title': '计算机英语入门篇', 'content': '《计算机入门英语(学与练)》是1999年海天出版社出版的图书,作者是王小红。', 'tags': 'NoSQL', 'comments': [ {'name': 'HongLP', 'detail': '写的不错,和百度百科一样么', 'date': '2019-07-27 13:38:49'}, {'name': 'RengPL', 'detail': '英语十八级路过', 'date': '2019-07-27 13:48:49'}, {'name': '小红', 'detail': '???', 'date': '2019-07-27 13:58:49'}], 'readcount': 768, }, {'author': 'RengPL', 'title': 'python数据分析', 'content': '《Python数据分析(影印版)》由麦金尼撰写,他是pandas库的主要作者。《Python数据分析(影印版)》也是一本具有实践性的指南,指导那些使用Python进行科学计算的数据密集型应用。', 'tags': 'python', 'comments': [ {'name': 'WangQQ', 'detail': '分析分析', 'date': '2019-07-30 13:38:49'}, {'name': 'nixin', 'detail': '赞👍', 'date': '2019-07-30 13:48:49'}, {'name': '小红', 'detail': '头给你打烂。。', 'date': '2019-07-30 13:58:49'}], 'readcount': 975, }, ]
data = {'city':'shanghai'}
db.insert_one(data) #新增一条 insert_one
data = [{'city':'shanghai'},{'city':'beijin'},{'city':'guangzhou'}]
db.insert_many(data) #新增多条 insert_many
查询
q1=db.find_one({"name":'xiaohong'})
print(q1) # 查询一条 find_one
alldata = db.find()
for i in alldata : print(i) #查询所有
#1、查询指定字段的数据
#我们可以使用 find() 方法来查询指定字段的数据,将要返回的字段对应值设置为 1。
for i in db.find({ },{"_id":0,"name":1,"hobby":1}) : print(i)
#2、查询所有文章的标题和内容
conn.user.article.find({},{"_id":0,"title":1,"content":1})
#3、查询作者为‘小红’的文章
conn.user.article.find_one({"author":{"$eq":"小红"}})
#4、查询除了‘小红’以外的所有文章
conn.user.article.find({"author":{"$ne":"小红"}})
#5、查询阅读数大于1000 并且 小于1200的
conn.user.article.find({"readcount":{"$gt":1000,"$lt":1200}})
#6、查询作者为‘小红’或者‘洪哥’的文章 或操作
conn.user.article.find({"$or":[{"author":"小红"},{"author":"洪哥"}]})
#7、查询文章标签包含‘NoSQL’或者‘MySQL’的 文章
conn.user.article.find({"tags":{"$in":["MySQL","NoSQL"]}})
#8、查询文章内容里包含数字1的文章
conn.user.article.find({"content":{"$regex":"1"}}) #有疑问 正则写法问题(/1/)
#9、查询标签数为2个的文章
conn.user.article.find({"tags":{"$size":2}})
##内嵌文档查询
#1、查询‘小红’评论过的文章
conn.user.article.find({"comments.name":"小红"})
#假设每页有3篇数据,按阅读量倒序,取第二页的数据
conn.user.article.find({}).skip(3).limit(3).sort("readcount",-1)
更新
conn.user.user.update_one({"查询条件"},{"修改器"}) #update_many 修改全部
#1、将名字为‘xiaohong’的年龄改为26
conn.user.user.update_one({"name":"xiaohong"},{"$set":{"age":26}})
#2、给所有的用户添加‘city’字段,值为‘shanghai’
conn.user.user.update_many({},{"$set":{"city":"shanghai"}})
#删除字段 就改为"$unset"
#3、给所有用户年龄加 1
conn.user.user.update_many({},{"$inc":{"age":1}}) #前提是age类型为int型
删除
#删除单条 conn.usser.user.delete_one() #删除多条 delete_many() #删除集合 conn.usser.user.drop() #删除了user库中的user集合
聚合查询
MongoDB中聚合(aggregate)主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果。有点类似sql语句中的 count(*)。
| 表达式 | 描述 | 实例 |
|---|---|---|
| $sum | 计算总和 | db.article.aggregate([{$group:{_id:"$author",num_tutorial:{$sum:"$readcount"}}}]) |
| $avg | 计算平均值 | db.article.aggregate([{$group:{_id:"$author",num_tutorial:{$avg:"$readcount"}}}]) |
| $min | 获取集合中所有文档对应值得最小值 | db.article.aggregate([{$group:{_id:"$author",num_tutorial:{$min:"$readcount"}}}]) |
| $max | 获取集合中所有文档对应值得最大值 | db.article.aggregate([{$group:{_id:"$author",num_tutorial:{$max:"$readcount"}}}]) |
| $push | 在结果文档中插入一个值到数组中 | db.article.aggregate([{$group : {_id : "$author", tags : {$push: "$tags"}}}]) |
| $addToSet | 在结果文档中插入值到一个数组中,但不创建副本 | db.article.aggregate([{$group : {_id : "$author", tags : {$addToSet: "$tags"}}}]) |
| $first | 根据资源文档的排序获取第一个文档数据 | db.article.aggregate([{$group : {_id : "$author", tags : {$first: "$tags"}}}]) |
| $last | 根据资源文档的排序获取最后一个文档数据 | db.article.aggregate([{$group : {_id : "$author", tags : {$last: "$tags"}}}]) |
管道在Unix和Linux中一般用于将当前命令的输出结果作为下一个命令的参数。
MongoDB的聚合管道将MongoDB文档在一个管道处理完毕后将结果传递给下一个管道处理。管道操作是可以重复的。
表达式:处理输入文档并输出。表达式是无状态的,只能用于计算当前聚合管道的文档,不能处理其它的文档。
聚合框架中常用的几个操作:
#$project:修改输入文档的结构。可以用来重命名、增加或删除域,也可以用于创建计算结果以及嵌套文档。 db.article.aggregate({$project:{_id:0,title:1,author:1}}) #$match:用于过滤数据,只输出符合条件的文档。$match使用MongoDB的标准查询操作。 db.article.aggregate([{$match:{readcount:{$gt:500,$lt:1000}}},{$group:{_id:"$author",count:{$sum:1}}}]) #$limit:用来限制MongoDB聚合管道返回的文档数。 db.article.aggregate([{$match:{readcount:{$gt:500,$lt:1000}}},{$limit:2}]) #$skip:在聚合管道中跳过指定数量的文档,并返回余下的文档。 db.article.aggregate([{$match:{readcount:{$gt:500,$lt:1000}}},{$skip:2}]) #$unwind:将文档中的某一个数组类型字段拆分成多条,每条包含数组中的一个值。 db.article.aggregate([{$unwind:"$tags"},{$project:{_id:0,title:1,author:1}}]) #$sort:将输入文档排序后输出。 db.article.aggregate([{$sort:{readcount:-1}},{$project:{_id:0,author:1,title:1,readcount:1}}]) #$geoNear:输出接近某一地理位置的有序文档。 没太理解,没试验过
MapReduce
Map-Reduce是一种计算模型,简单的说就是将大批量的工作(数据)分解(MAP)执行,然后再将结果合并成最终结果(REDUCE)。
MongoDB提供的Map-Reduce非常灵活,对于大规模数据分析也相当实用。
>db.collection.mapReduce( function() {emit(key,value);}, //map 函数 function(key,values) {return reduceFunction}, //reduce 函数 { out: collection, query: document, sort: document, limit: number } )
-
map :映射函数 (生成键值对序列,作为 reduce 函数参数)。
-
reduce 统计函数,reduce函数的任务就是将key-values变成key-value,也就是把values数组变成一个单一的值value。。
-
out 统计结果存放集合 (不指定则使用临时集合,在客户端断开后自动删除)。
-
query 一个筛选条件,只有满足条件的文档才会调用map函数。(query。limit,sort可以随意组合)
-
sort
-
limit 发往map函数的文档数量的上限(要是没有limit,单独使用sort的用处不大)
集群部署
主从复制
是一个简单的数据库同步备份的集群技术,这种方式很灵活,可用于备份,故障恢复,读扩展等。最基本的设置方式就是建立一个主节点和一个或多个从节点,每个从节点要知道主节点的地址。采用双机备份后主节点挂掉了后从节点可以接替主机继续服务。所以这种模式比单节点的高可用性要好很多。
已经不推荐使用!主从模式,需要手工指定集群中的 Master。如果 Master 发生故障,一般都是人工介入,指定新的Master。 这个过程对于应用一般不是透明的,往往伴随着应用重新修改配置文件,重启应用服务器等。

副本集是将数据同步在多个服务器的过程。
-
保障数据的安全性
-
数据高可用性 (24*7)
-
灾难恢复
-
无需停机维护(如备份,重建索引,压缩)
-
分布式读取数据(读写分离)
MongoDB复制原理
mongodb的复制至少需要两个节点。其中一个是主节点,负责处理客户端请求,其余的都是从节点,负责复制主节点上的数据。
mongodb各个节点常见的搭配方式为:一主一从、一主多从。
主节点记录在其上的所有操作oplog,从节点定期轮询主节点获取这些操作,然后对自己的数据副本执行这些操作,从而保证从节点的数据与主节点一致。
客户端从主节点读取数据,在客户端写入数据到主节点时, 主节点与从节点进行数据交互保障数据的一致性。
副本集集群Master故障的时候,副本集可以自动投票,选举出新的Master,并引导其余的Slave服务器连接新的Master,而这个过程对于应用是透明的。可以说MongoDB的副本集是自带故障转移功能的主从复制。

oplog是MongoDB复制的关键。oplog是一个固定集合,位于每个复制节点的local数据库里,记录了所有对数据的变更。每次客户端向主节点写入数据,就会自动向主节点的oplog里添加一个条目,其中包含了足够的信息来再现数据。一旦写操作被复制到某个从节点上,从节点的oplog也会保存一条关于写入的记录。每个oplog条目都由一个BSON时间戳进行标识,所有从节点都使用这个时间戳来追踪它们最后应用的条目。
#复制过程 当Primary节点完成数据操作后,Secondary会做出一系列的动作保证数据的同步: 1)检查自己`local`库的 oplog.rs集合找出最近的时间戳。 2)检查Primary节点`local`库 oplog.rs集合,找出大于此时间戳的记录。 3)将找到的记录插入到自己的 oplog.rs集合中,并执行这些操作。 注意:在副本集的环境中,要是所有的Secondary都宕机了,只剩下Primary。最后Primary会变成Secondary,不能提供服务。
集群中的各节点还会通过传递心跳信息来检测各自的健康状况。当主节点故障时,多个从节点会触发一次 新的选举操作,并选举其中的一个成为新的主节点(通常谁的优先级更高,谁就是新的主节点),心跳信息默认每 2 秒传递一次。

#选举机制 Mongodb副本集选举采用的是Bully算法,这是一种协调者(主节点)竞选算法,主要思想是集群的每个成员都可以声明它是主节点并通知其他节点。 别的节点可以选择接受这个声称或是拒绝并进入主节点竞争,被其他所有节点接受的节点才能成为主节点。 节点按照一些属性来判断谁应该胜出,这个属性可以是一个静态 ID,也可以是更新的度量像最近一次事务ID(最新的节点会胜出) 副本集的选举过程大致如下: 1)得到每个服务器节点的最后操作时间戳。每个 mongodb 都有 oplog 机制会记录本机的操作,方便和主服 务器进行对比数据是否同步还可以用于错误恢复。 2)如果集群中大部分服务器 down 机了,保留活着的节点都为 secondary 状态并停止,不选举了。 3)如果集群中选举出来的主节点或者所有从节点最后一次同步时间看起来很旧了,停止选举等待人来操作。 4)如果上面都没有问题就选择最后操作时间戳最新(保证数据是最新的)的服务器节点作为主节点。 副本集选举的特点: 选举还有个前提条件,参与选举的节点数量必须大于副本集总节点数量的一半(建议副本集成员为奇数。最多12个副本节点,最多7个节点参与选举) 如果已经小于一半了所有节点保持只读状态。集合中的成员一定要有大部分成员(即超过一半数量)是保持正常在线状态,3个成员的副本集,需要至少2个从属节点是正常状态。 如果一个从属节点挂掉,那么当主节点down掉 产生故障切换时,由于副本集中只有一个节点是正常的,少于一半,则选举失败。 4个成员的副本集,则需要3个成员是正常状态(先关闭一个从属节点,然后再关闭主节点,产生故障切换,此时副本集中只有2个节点正常,则无法成功选举出新主节点)。
同步延迟问题
数据同步时“从节点”将“主节点”上的写操作同步到自己这边再进行执行。在MongoDB中,所有写操作都会产oplog,oplog 是每修改一条数据都会生成一条,如果你采用一个批量 update 命令更新了 N 多条数据, 那么抱歉,oplog 会有很多条,而不是一条。所以同步延迟就是写操作在主节点上执行完后,从节点还没有把 oplog 拿过来再执行一次。而这个写操作的量越大,主节点与从节点的差别也就越大,同步延迟也就越大了。 如果主从延迟过大,主节点上会有很多数据更改没有同步到从节点上。这时候如果主节点故障,就有 两种情况: 1)主节点故障并且无法恢复,如果应用上又无法忍受这部分数据的丢失,我们就得想各种办法将这部 数据更改找回来,再写入到从节点中去。可以想象,即使是有可能,那这也绝对是一件非常恶心的活。 2)主节点能够恢复,但是需要花的时间比较长,这种情况如果应用能忍受,我们可以直接让从节点提 供服务,只是对用户来说,有一段时间的数据丢失了,而如果应用不能接受数据的不一致,那么就只能下线整个业务,等主节点恢复后再提供服务了。
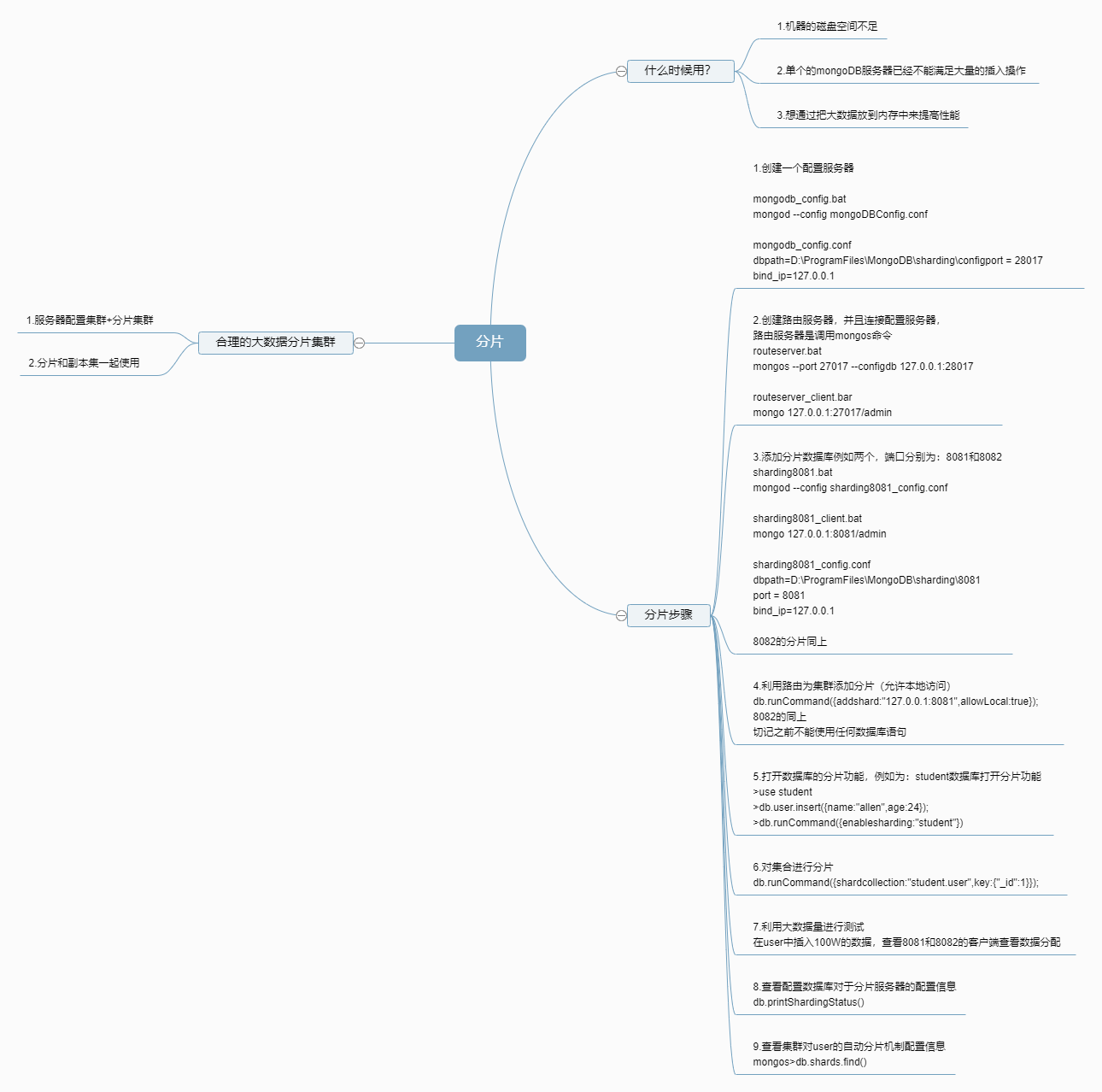
分片 (sharding)是指将数据库拆分,将其分散在不同的机器上的过程。将数据分散到不同的机器上,不需要功能强大的服务器就可以存储更多的数据和处理更大的负载。
为何需要水平分片 1)减少单机请求数,将单机负载,提高总负载 2)减少单机的存储空间,提高总存空间
-
MongoDB事务需要4.0+版本
-
需要搭建好mongodb副本集,单个server不支持事务
#开始事务 session.start_transaction() try: hello_collection.insert({"world":1}) world_collection.insert({"hello":1}) except: # 操作异常,中断事务 session.abort_transaction() else: session.commit_transaction() finally: session.end_session()
持久化原理
mongodb与mysql不同,mysql每一次操作都会直接写入硬盘,mongo则是写入内存,然后持久化到硬盘中。mongodb在启动时,会初始化一个线程不断循环,用于在一定时间周期内来从defer队列中获取要持久化的数据并写入磁盘的journal (日志),和mongofile(数据)中,周期为90毫秒。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号