【mongoDB高级篇②】大数据聚集运算之mapReduce(映射化简)
简述
mapReduce从字面上来理解就是两个过程:map映射以及reduce化简。是一种比较先进的大数据处理方法,其难度不高,从性能上来说属于比较暴力的(通过N台服务器同时来计算),但相较于group以及aggregate来说,功能更强大,并更加灵活。
- 映射过程:先把某一类数据分组归类,这里的映射过程是支持分布式的,一边遍历每一台服务器,一边进行分类。
- 化简过程:然后再在分组中进行运算,这里的化简过程也是支持分布式的,在分类的过程中直接运算了。也就是说如果是一个求和的过程,先在a服务器分组求和,然后再在b服务器分组求和····最后再把化简以后的数据进行最终处理。在映射化简的过程都是每台服务器自己的CPU在运算,大量的服务器同时来进行运算工作,这就是大数据基本理念。
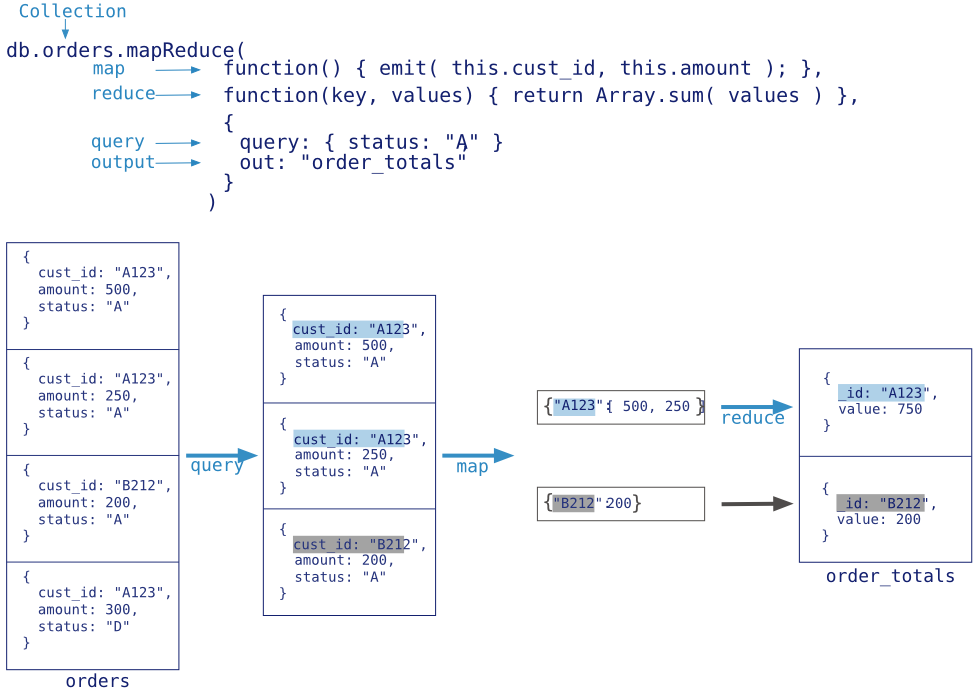
在这个映射化简操作中,MongoDB对每个输入文档(例如集合中满足查询条件的文档)执行了map操作。映射操作输出了键值对结果。对那些有多个值的关键字,MongoDB执reduce操作,收集并压缩了最终的聚合结果。然后MongoDB把结果保存到一个集合中。化简函数还可以把结果输出到finalize函数,进一步对聚合结果做处理,当然这步是可选的。
在MongoDB中,所有的映射化简函数都是使用JavaScript编写,并且运行在 mongod 进程中。映射化简操作使用一个集合中文档作为输入,并且可以在映射阶段之前执行任意的排序和限定操作。 mapReduce 命令可以把结果作为一个文档来返回,也可以把结果写入集合。输入集合和输出集合可以是分片的。
语法参数
更多参考: http://docs.mongodb.org/manual/reference/command/mapReduce/
map: function() {emit(this.cat_id,this.goods_number); }, # 函数内部要调用内置的emit函数,cat_id代表根据cat_id来进行分组,goods_number代表把文档中的goods_number字段映射到cat_id分组上的数据,其中this是指向向前的文档的,这里的第二个参数可以是一个对象,如果是一个对象的话,也是作为数组的元素压进数组里面;
reduce: function(cat_id,all_goods_number) {return Array.sum(all_goods_number)}, # cat_id代表着cat_id当前的这一组,all_goods_number代表当前这一组的goods_number集合,这部分返回的就是结果中的value值;
out: <output>, # 输出到某一个集合中,注意本属性来还支持如果输出的集合如果已经存在了,那是替换,合并还是继续reduce? 另外还支持输出到其他db的分片中,具体用到时查阅文档,筛选出现的键名分别是_id和value;
query: <document>, # 一个查询表达式,是先查询出来,再进行mapReduce的
sort: <document>, # 发往map函数前先给文档排序
limit: <number>, # 发往map函数的文档数量上限,该参数貌似不能用在分片模式下的mapreduce
finalize: function(key, reducedValue) {return modifiedObject; }, # 从reduce函数中接受的参数key与reducedValue,并且可以访问scope中设定的变量
scope: <document>, # 指定一个全局变量,能应用于finalize和reduce函数
jsMode: <boolean>, # 布尔值,是否减少执行过程中BSON和JS的转换,默认true,true时BSON-->js-->map-->reduce-->BSON,false时 BSON-->JS-->map-->BSON-->JS-->reduce-->BSON,可处理非常大的mapreduce。
verbose: <boolean> # 是否产生更加详细的服务器日志,默认true
实例
简单应用实例
# 求每组的库存总量
var map = function(){
emit(this.cat_id,this.goods_number);
}
var reduce = function(cat_id,numbers){
return Array.sum(numbers);
}
db.goods.mapReduce(map,reduce,{out:'res'})
# 查看Array支持的方法
for(var i in Array){
printjson(i);
}
"contains"
"unique"
"shuffle"
"tojson"
"fetchRefs"
"sum"
"avg"
"stdDev"
# 求每个栏目的平均价格
var map = function(){
emit(this.cat_id,this.shop_price);
}
var reduce = function(cat_id,prices){
var avgprice = Array.avg(prices);
return Math.round(avgprice,2);
}
db.goods.mapReduce(map,reduce,{out:'res'});
# 求出每组的最大价格
var map = function(){
emit(this.cat_id,this.shop_price);
}
//错误操作 ↓↓ 应该在finalize函数中做处理
var reduce = function(cat_id,prices){
var max = 0;
for(var i in prices){
if(i > max)
max = i;
}
return max;
}
var reduce = function(cat_id,prices){
return {cat_id:cat_id,prices:prices};
}
var finalize = function(cat_id, prices) {
var max = 0;
if(prices.prices !== null){
var obj = prices.prices;
for(var i in obj){
if(obj[i] > max)
max = obj[i]
}
}
return max == 0 ? prices : max;
}
db.goods.mapReduce(map,reduce,{out:'res1',finalize:finalize,query:{'shop_price':{$gt:0}}});
# 获得每组的商品集合
var map = function(){
emit(this.cat_id,this.goods_name);
}
var reduce = function(cat_id,goods_names){
return {cat_id:cat_id,goods_names:goods_names}
}
var finalize = function(key, reducedValue) {
return reducedValue == null ? 'none value' : reducedValue; //对reduce的值进行二次处理
}
db.runCommand({
mapReduce:'goods',
map:map,
reduce:reduce,
finalize:finalize,
out:'res2'
})
# 对于price大于100的才进行分组映射
## 方法1:
var map = function(){
if(this.shop_price > 100){
emit(this.cat_id,{name:this.goods_name,price:this.shop_price});
}
}
var reduce = function(cat_id,goods_names){
return {cat_id:cat_id,goods_names:goods_names}
}
db.runCommand({
mapReduce:'goods',
map:map,
reduce:reduce,
out:'res2'
})
## 方法2 首推此方法
var map = function(){
emit(this.cat_id,{name:this.goods_name,price:this.shop_price});
}
var reduce = function(cat_id,goods_names){
return {cat_id:cat_id,goods_names:goods_names}
}
db.runCommand({
mapReduce:'goods',
map:map,
reduce:reduce,
query:{'shop_price':{$gt:100}},
out:'res2'
})
官网实例
# 数据结构
{
_id: ObjectId("50a8240b927d5d8b5891743c"),
cust_id: "abc123",
ord_date: new Date("Oct 04, 2012"),
status: 'A',
price: 25,
items: [ { sku: "mmm", qty: 5, price: 2.5 },
{ sku: "nnn", qty: 5, price: 2.5 } ]
}
# 计算每个顾客的总金额
var mapFunction1 = function() {
emit(this.cust_id, this.price);
};
var reduceFunction1 = function(keyCustId, valuesPrices) {
return Array.sum(valuesPrices);
};
db.orders.mapReduce(
mapFunction1,
reduceFunction1,
{ out: "map_reduce_example" }
)
# 计算订单总量和每种 sku 订购量的平均值
var mapFunction2 = function() {
for (var idx = 0; idx < this.items.length; idx++) {
var key = this.items[idx].sku;
var value = {
count: 1,
qty: this.items[idx].qty
};
emit(key, value);
}
};
var reduceFunction2 = function(keySKU, countObjVals) {
reducedVal = { count: 0, qty: 0 };
for (var idx = 0; idx < countObjVals.length; idx++) {
reducedVal.count += countObjVals[idx].count;
reducedVal.qty += countObjVals[idx].qty;
}
return reducedVal;
};
var finalizeFunction2 = function (key, reducedVal) {
reducedVal.avg = reducedVal.qty/reducedVal.count;
return reducedVal;
};
db.orders.mapReduce(
mapFunction2,
reduceFunction2,
{
out: { merge: "map_reduce_example" },
query: { ord_date:
{ $gt: new Date('01/01/2012') }
},
finalize: finalizeFunction2
}
)
-------------------------END-------------------------
博客园的阅读体验比起sf的要差很多,所以博客已迁移至segmentfault。 链接:https://segmentfault.com/blog/nixi8 部分文档已整理到看云 https://www.kancloud.cn/@xiaoa
博客园的阅读体验比起sf的要差很多,所以博客已迁移至segmentfault。 链接:https://segmentfault.com/blog/nixi8 部分文档已整理到看云 https://www.kancloud.cn/@xiaoa

 浙公网安备 33010602011771号
浙公网安备 33010602011771号