

基于快照隔离的MVCC与write skew问题

总结
1、write skew 问题,是基础版多版本并发控制方案,在版本提交时,只处理了 写 - 写 冲突,而未处理存在控制依赖关系的 读 - 写 冲突。
2、对于相同数据的写入操作保证了并发安全,但当该写入操作依赖的数据,被其他事务修改的情况发生时,就会出现并发问题。
3、对于一个事务涉及的数据全部加锁(保证线程(事务)对所有共享数据访问的并发安全),便是串行化的隔离级别了。
4、针对事务将并发问题进行细化,并将解决不同程度的并发问题定义为不同的隔离级别,是对效率与安全进行权衡的一种方式。
5、经过对 mysql5.7 版本的测试,发现在一些特殊情况下未出现 write skew 问题,且有时会表现为晚执行的事务发生阻塞(某种锁机制实现?),具体实现方式后面再学习。
6、mysql 未完全解决 write skew 与 Lost update 问题(Oracle更是压根未提供RR隔离级别)。因此如果有读已提交隔离级别无法解决的场景时,尽量使用应用层面的锁来解决并发问题。
Mysql (5.7)测试
RR 隔离级别下的事务表现
数据库事务隔离级别为可重复读:

快照读
测试数据:

事务 1:
start transaction;
update test set A=B where ID = '11';
commit;
事务2:
start transaction;
select * from test where ID = '11';
commit;
执行顺序:
2(start) , 1(start) , 1(update) , 1(commit) , 2(select)
执行发现,虽然 A 已经更新了数据,将 A 更新为了 2 ,但由于 2 事务的 start 早于 A 事务,2 事务读取到的仍然是 1 事务提交前的数据。

也就是 1 事务读取到的数据,是1事务开始时,该条数据的快照,即读取为快照读而非当前读。
快照读导致的 Lost update
测试数据

事务1
start transaction;
select * from test;
select @varB:=B from test where ID = '11';
update test set A=@varB where ID = '11';
commit;
事务2
start transaction;
update test set B=5 where ID = '11';
commit;
执行顺序:
1(start) , 1(select) , 2(start) , 2(update) ,2(commit) ,1(select) , 1(update) , 1(commit)
按照预期,事务2先将 B 改为 5 并提交,然后事务 1 将 A 赋值为 B ,A , B 的值都应该是 5 。
但测试结果为,A,B 的值为 1,,5

这是因为在事务2开启之前,事务1已经开启了,事务1内读到的数据为事务1开启前的快照读。
特殊情况
如果上述事务执行顺序中:
1(start) , 1(select) , 2(start) , 2(update) ,2(commit) ,1(select) , 1(update) , 1(commit)
标红的 1(select) 未执行,则标蓝的 1(select) 可以读到最新的数据,而不是事务开始前的数据快照。
也就是说mysql5.7(InnoDB)对多版本并发控制进行了优化,事务中第一次读取的数据,使用的是当前读。
另外,如果事务语句改为:
start transaction; update test set A=B where ID = '11'; commit;
结果发现,在事务 1 提交之前,事务 2 的 update 语句一直处于阻塞状态:

也就是在该写法下,mysql检查到了两个事务的冲突,且使用了某种锁机制对数据进行了保护。这也是对多版本并发控制机制的一种优化。
一个实际生产中的例子
《Lost Update问题:一次分布式锁与数据库事务的纠缠与解决》
基于快照隔离的多版本并发控制方案
以下搬自知乎,原文链接:《基于快照隔离的多版本并发控制方案》
多版本并发控制 MVCC (Multiversion Concurrency Control) ,通常都具有较高的并发性能,特别是读多写少的场景,所以在商业和开源数据库中都有广泛应用。比如 MySQL 使用的快照隔离就是一种非常受欢迎的多版本并发控制方案。
快照隔离在每个事务开始时为事务提供一个数据库的“快照”,快照里所有数据都是数据库中当前已经提交的数据。每个事务在与其他并发事务完全隔离的情况下对快照进行读写。因为快照中的数据都是已提交的,所以只读事务不会和任何活跃的读写事务冲突,更不会和其他只读事务冲突,所以只读事务永远不会被阻塞或被中止。
并发执行且需要更新数据库的事务之间可能会有潜在冲突。所以在快照隔离中,所有事务的更新操作都写在各自的私有空间里,事务在准备好提交后需要先先向并发管理器申请验证,通过验证的事务才允许将其更改提交到数据库,没通过验证的事务会被中止。
实现原理
每个事务在启动时会被分配一个时间戳,称其为 start_ts 好了,也可以等到执行事务的第一个操作(读或写)时分配。每个事务在请求验证时会被分配另一个时间戳,称其为 commit_ts 好了。这里的时间戳并非特指时钟时间,只是可以用时钟时间实现,但必须保证为每个事务分配的时间戳都是不同的,所以一般使用一个递增的计数器来实现,计数器有个初始值,并在每个事务到达验证阶段时递增一次。
如果两个事务的 start_ts 和 commit_ts 形成的区间有重叠,则说明它们是并发事务。也就是说,只要 t1.start_ts <= t2.start_ts <= t1.commit_ts 或 t2.start_ts <= t1.start_ts <= t2.commit_ts,则 t1 和 t2 是并发执行的。
每个事务的更改操作都写到各自的私有空间里,通过验证后并不是直接将更新应用到数据库,而是创建一个对应数据项的新版本。版本信息里会有一个时间戳,该时间戳代表该版本的创建时间,也就是事务的 commit_ts(因为这个新版本在事务通过验证才会写入到数据库中,所以对于数据库来说其创建时间就是事务的 commit_ts)。
当某个事务 t 读取数据项时,读取到的是数据项所有版本中时间戳小于等于 t.start_ts(事务 t 的起始时间戳)的最近一个版本。因此,事务 t 看不到自身启动之后其他事务提交的更改,只能看到自己启动之前已提交的更改。所以,事务 t 看到的是数据库的一个快照(可重复读)。
先提交者获胜
使用先提交者获胜的方案中,先申请提交的事务优先。
当一个事务 t1 申请验证时,被分配一个 commit_ts,然后经历验证过程,其中一部分过程如下:
- 检查是否有任何和
t1并发执行的事务已经将更新写入到数据库,并且包含t1将要更新的数据项。这个过程可以通过依次检查t1将要更新的数据项,看看这些数据项是否有一个版本的时间戳落在[t1.start_ts, t1.commit_ts]范围中。 - 如果找到了这样的数据项,则
t1中止。 - 如没找到这样的数据项,则
t1提交并将更新写入到数据库中。
对于有更新冲突的并发事务,肯定是先通过上面测试过程的事务被提交,而后进行上面测试过程的事务被中止,所以该方案称为“先提交者获胜”。
先更新者获胜
在先更新者获胜方案中,先更新的事务优先。
事务 t1 在更新某个数据项之前,需要先获得该数据项的写锁。如果该事务还没获得锁,则需要经过以下步骤:
- 如果数据项已经被其他并发事务更新,则
t1中止。 - 如果相关数据项的锁已经被其另一个并发事务
t2持有,导致t1无法继续执行,则t1需要等待t2中止或提交: - 如果
t2中止,锁被释放,t1获得锁。t1获得锁后,检查将要更新的每个数据项,如果找到某个数据的某个版本的时间戳落在[t1.start_ts, t1.commit_ts],则t1中止,否则t1继续执行。 - 如果
t2提交了,则t1必须中止。(t2提交了,说明t2已经更新过数据项了,所以t1不能继续更新了)
事务提交或中止时都必须释放锁。
该方案中,有更新冲突的并发事务,先尝试更新的事务会先获得数据项写锁并将更新提交到数据库,随后尝试更新数据项的事务都会被中止,所以称为“先更新者获胜”。但如果第一个获得锁的事务因为某种原因中止了,则锁会被下一个尝试更新的事务获得,还是符合越先更新越优先的原则。
快照隔离和一致性约束
使用快照隔离有一个值得特别注意的问题,那就是一致性约束。由于快照隔离下的事务运行在各自的空间中,看不到其他事务的更改,就算每个事务保证自己没有破坏数据库的一致性约束,但多个事务合起来的结果还是可能会破坏一致性,所以数据库系统应该根据数据库的当前状态检测一致性约束,而不是在单个快照上检查。例如,主键约束、唯一键、外键约束,两个并发事务可能会创建两个相同主键的记录并提交,单独在每个事务的快照上检查,都没有破坏一致性,但两个事务合起来就有了主键冲突。
对于数据库无法保证的业务层的一致性约束,例如要求两个记录的特定字段和大于 1000,则只能由应用层逻辑保证。
快照隔离的 write skew 问题
write skew 描述
快照隔离通过版本时间戳和私有空间让事务看不到其他并发事务的修改,所以只读事务可以和其他任意事务并发执行而不出现问题,通过验证阶段且修改了相同数据项的并发事务只有一个能提交,从而避免了更新丢失问题。但如果两个并发事务都修改了对方读取的数据项,则它们的执行结果可能是无法通过串行化执行得到的。
举个例子,假设事务 1 和事务 2 都读取了数据项 a、b,事务 1 将 a 的值更新为 b 值,事务 2 将 b 的值更新为 a 的值。操作序列为 r1[a=100]r1[b=200]r2[a=100]r2[b=200]w1[a=200]w2[b=100] 后跟任意顺序的 c1 和 c2。
本来在数据库中 a 的值为 100,b 的值为 200,上面的执行序列中,t1 将 a 的值更新为等于 b 的旧值(200),t2 将 b 的值更新为 a 的旧值(100),最后的结果是 a、b 交换了值,a 的值为 200,b 的值为 100。
如果是串行执行,且事务 1 先执行、事务 2 后执行,即执行序列为 r1[a=100]r1[b=200]w1[a=200]c1...r2[a=200]r2[b=200]w2[b=200]c2,最后执行得到的结果是 a 和 b 的值都等于 200。
如果是串行执行,且事务 2 先执行、事务 1 后执行,即执行序列为 r2[a=100]r2[b=100]w2[b=100]c2...r1[a=100]r1[b=100]w1[a=100]c1,最后的执行结果是 a 和 b 的值都等于 100。
在上面的示例中,无论事务 1 和事务 2 以哪种顺序串行执行,最后得到的结果和快照隔离中的并发执行结果都不一样。所以说快照隔离达不到可串行化隔离级别。
上面这种不可串行化的的本质是并发事务更新了各自进行数据项更新所有依赖的数据项。这种问题称为 write skew(翻译成写偏斜或写偏序)。
另一个更经典的例子,来自 Serializable vs. Snapshot Isolation Level - Microsoft Tech Community,假设数据库里有黑色和白色的小球,事务 1 要把黑色的小球染成白色,事务 2 要把白色的小球染成黑色。在快照隔离下,两个事务并发执行的结果如下图:
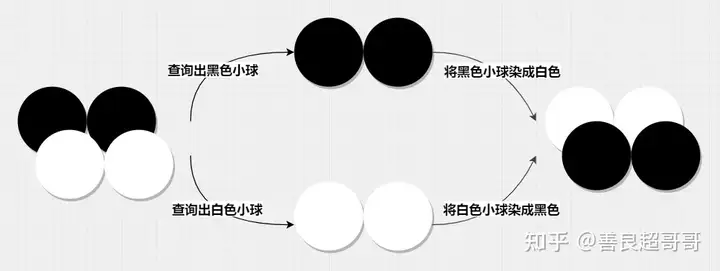
两个事务并发执行,将小球重新染色
可以看到,快照隔离下,两个并发事务的执行结果是将黑白小球换了个颜色。
两个事务串行执行的结果如下图:
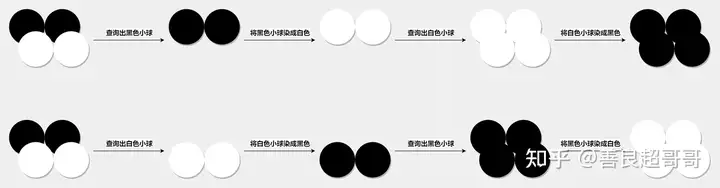
两种顺序的串行执行
在串行执行的情况下,如果事务 1 先执行,最终的结果是所有小球都变成了黑色;如果是事务 2 先执行,最终的结果是所有小球都变成了白色。
解决方案
目前存在三类方案可以解决快照隔离的 write skew 问题。
- 对快照隔离进行改进和扩展,使其达到可串行化的隔离级别,改进后的方案称为可串行化的快照隔离。以后再讨论。
- 对纯读事务事务快照隔离方案,对其他事务使用隔离级别更高的并发控制方案。
- write skew 说到底是一种读-写冲突,并发事务修改了彼此依赖的不同数据项。而快照隔离的验证机制只能检测到写-写冲突,读写冲突被掩盖,导致并发执行的结果不能串行化。如果将读-写冲突转成写-写冲突,那快照隔离的验证机制就能检测到读-写冲突了。所以有的数据库系统会提供机制(例如
for update语句)让程序员将读操作标记为写操作,对于需要保证从串行化的读写事务,可以用这种机制让并发事务的读-写冲突变成写-写冲突,从而被事务隔离的验证机制检测到。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?
2020-06-28 Leetcode 873 最长斐波那契子序列 记忆化递归与剪枝DP
2020-06-28 Leetcode1372 最长交错路径,记忆化递归