redis其他-5
1 双写一致性,redis和mysql数据同步,方案
- 1 先更新数据库,再更新缓存(一般不用)
- 2 先删缓存,再更新数据库(在存数据的时候,请求来了,缓存不是最新的)
- 3 先更新数据库,再删缓存(推荐用)
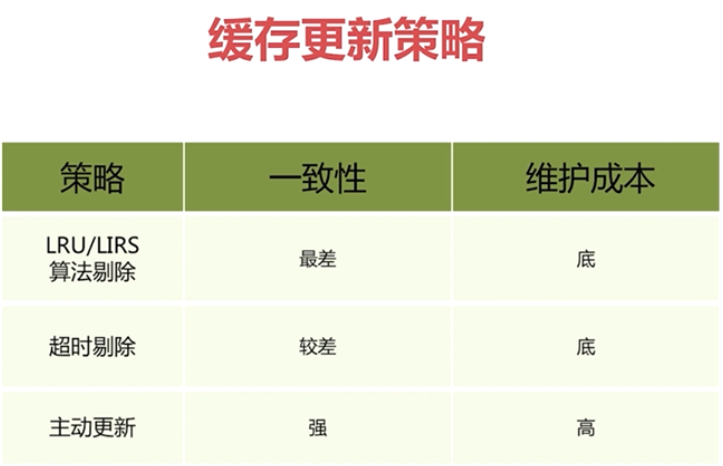
2 缓存更新策略
- LRU/LFU/FIFO算法剔除
- maxmemory-policy,超过最大内存,新的放不进去了,淘汰策略
- LRU -Least Recently Used,没有被使用时间最长的(保证热点数据)
- LFU -Least Frequenty User,一定时间段内使用次数最少的
- FIFO -First In First Out,先进先出
3 如何保证redis中数据是最热的,配置lru的剔除算法
- 配置文件中:maxmemory-policy:volatile-lru
4 LFU配置 Redis4.0之后为maxmemory_policy淘汰策略添加了两个LFU模式
- 配置
- maxmemory-policy:volatile-lfu
- lfu-log-factor 10
- lfu-decay-time 1
- lfu-log-factor可以调整计数器counter的增长速度,lfu-log-factor越大,counter增长的越慢。
- lfu-decay-time是一个以分钟为单位的数值,可以调整counter的减少速度
5 缓存粒度控制
使用Redis来做缓存,底层使用MySQL来做数据存储源,这种架构下大部分请求由Redis处理,少部分请求到达MySQL。从MySQL中获取一个用户的所有信息,然后缓存到Redis的数据结构中。
此时需要面对一个问题:缓存这个用户的所有数据信息,还是缓存用户需要的用户信息字段。
可以从三个角度来考虑:
(1)通用性:从通用性角度考虑,缓存全量属性更好。
因为当用户数据表字段发生改变时,不需要修改程序就可以直接同步修改之后的用户信息到Redis缓存中供用户使用,但是这样会占用更多的内存空间。
(2)占用空间:从占用空间的角度考虑,缓存部分属性更好。
因为当用户数据表字段发生改变时而用户需要这个字段信息时,就需要修改程序源代码来把修改之后的用户信息同步缓存到Redis中,这种情况下占用的内存空间比全量属性占用的内存空间要少。
(3)代码维护:从代码维护角度考虑,表面上缓存全量属性更好。
因为不管数据源中的数据表结构如何改变,都会把所有的数据同步到Redis缓存中,而不需要修改程序源代码,但是在大多数情况下,并不会使用到全量数据,只需要缓存需要的数据就可以了。因此从内存空间消耗及性能方面考虑,缓存部分属性更好
6 缓存穿透,缓存击穿,缓存雪崩
缓存穿透(恶意的)
描述:
缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求,如发起为id为“-1”的数据或id为特别大不存在的数据。这时的用户很可能是攻击者,攻击会导致数据库压力过大。
解决方案:
1 接口层增加校验,如用户鉴权校验,id做基础校验,id<=0的直接拦截;
2 从缓存取不到的数据,在数据库中也没有取到,这时也可以将key-value对写为key-null,缓存有效时间可以设置短点,如30秒(设置太长会导致正常情况也没法使用)。这样可以防止攻击用户反复用同一个id暴力攻击
3 通过布隆过滤器实现,mysql中所有数据都放到布隆过滤器,请求来了,先去布隆过滤器查,如果没有,表示非法,直接返回
缓存击穿
描述:
缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力
解决方案:
设置热点数据永远不过期。
缓存雪崩
描述:
缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至down机。和缓存击穿不同的是, 缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
解决方案:
1 缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。
2 如果缓存数据库是分布式部署,将热点数据均匀分布在不同搞得缓存数据库中。
3 设置热点数据永远不过期。

