redis API的使用-2
1.基本API使用
1.1 通用命令
####1-keys
#打印出所有key
keys *
#打印出所有以he开头的key
keys he*
#打印出所有以he开头,第三个字母是h到l的范围
keys he[h-l]
#三位长度,以he开头,?表示任意一位
keys he?
#keys命令一般不在生产环境中使用,生产环境key很多,时间复杂度为o(n),用scan命令
####2-dbsize 计算key的总数
dbsize #redis内置了计数器,插入删除值该计数器会更改,所以可以在生产环境使用,时间复杂度是o(1)
###3-exists key 时间复杂度o(1)
#设置a
set a b
#查看a是否存在
exists a
(integer) 1
#存在返回1 不存在返回0
###4-del key 时间复杂度o(1)
删除成功返回1,key不存在返回0
###5-expire key seconds 时间复杂度o(1)
expire name 3 #3s 过期
ttl name #查看name还有多长时间过期
persist name #去掉name的过期时间
###6-type key 时间复杂度o(1)
type name #查看name类型,返回string
### 7 其他
info命令:内存,cpu,主从相关
client list 正在连接的会话 (./src/redis-cli -a 123456 client list)
client kill ip:端口
dbsize 总共有多少个key
flushall 清空所有
flushdb 只清空当前库
select 数字 选择某个库 总共16个库
monitor 记录操作日志,夯住(日志审计)
2.2 字符串命令
###1---基本使用get,set,del
get name #时间复杂度 o(1)
set name lqz #时间复杂度 o(1)
del name #时间复杂度 o(1)
###2---其他使用incr,decr,incrby,decrby
incr age #对age这个key的value值自增1
decr age #对age这个key的value值自减1
incrby age 10 #对age这个key的value值增加10
decrby age 10 #对age这个key的value值减10
#统计网站访问量(单线程无竞争,天然适合做计数器)
#缓存mysql的信息(json格式)
#分布式id生成(多个机器同时并发着生成,不会重复)
###3---set,setnx,setxx
set name lqz #不管key是否存在,都设置
setnx name lqz #key不存在时才设置(新增操作)
set name lqz nx #同上
set name lqz xx #key存在,才设置(更新操作)
###4---mget mset
mget key1 key2 key3 #批量获取key1,key2.。。时间复杂度o(n)
mset key1 value1 key2 value2 key3 value3 #批量设置时间复杂度o(n)
#n次get和mget的区别
#n次get时间=n次命令时间+n次网络时间
#mget时间=1次网络时间+n次命令时间
###5---其他:getset,append,strlen
getset name lqznb #设置新值并返回旧值 时间复杂度o(1)
append name 666 #将value追加到旧的value 时间复杂度o(1)
strlen name #计算字符串长度(注意中文) 时间复杂度o(1)
###6---其他:incrybyfloat,getrange,setrange
increbyfloat age 3.5 #为age自增3.5,传负值表示自减 时间复杂度o(1)
getrange key start end #获取字符串制定下标所有的值 时间复杂度o(1)
setrange key index value #从指定index开始设置value值 时间复杂度o(1)
1.3 hash命令
###1---hget,hset,hdel
hget key field #获取hash key对应的field的value 时间复杂度为 o(1)
hset key field value #设置hash key对应的field的value值 时间复杂度为 o(1)
hdel key field #删除hash key对应的field的值 时间复杂度为 o(1)
#测试
hset user:1:info age 23
hget user:1:info ag
hset user:1:info name lqz
hgetall user:1:info
hdel user:1:info age
###2---hexists,hlen
hexists key field #判断hash key 是否存在field 时间复杂度为 o(1)
hlen key #获取hash key field的数量 时间复杂度为 o(1)
hexists user:1:info name
hlen user:1:info #返回数量
###3---hmget,hmset
hmget key field1 field2 ...fieldN #批量获取hash key 的一批field对应的值 时间复杂度是o(n)
hmset key field1 value1 field2 value2 #批量设置hash key的一批field value 时间复杂度是o(n)
###4--hgetall,hvals,hkeys
hgetall key #返回hash key 对应的所有field和value 时间复杂度是o(n)
hvals key #返回hash key 对应的所有field的value 时间复杂度是o(n)
hkeys key #返回hash key对应的所有field 时间复杂度是o(n)
###小心使用hgetall
##1 计算网站每个用户主页的访问量
hincrby user:1:info pageview count
hincrby userinfopagecount user:1:info count
##2 缓存mysql的信息,直接设置hash格式
1.4 列表类型
# 有序队列,可以从左侧添加,右侧添加,可以重复,可以从左右两边弹出
########插入操作
#rpush 从右侧插入
rpush key value1 value2 ...valueN #时间复杂度为o(1~n)
#lpush 从左侧插入
#linsert
linsert key before|after value newValue #从元素value的前或后插入newValue 时间复杂度o(n) ,需要遍历列表
linsert listkey before b java
linsert listkey after b php
############删除操作
lpop key #从列表左侧弹出一个item 时间复杂度o(1)
rpop key #从列表右侧弹出一个item 时间复杂度o(1)
lrem key count value
#根据count值,从列表中删除所有value相同的项 时间复杂度o(n)
1 count>0 从左到右,删除最多count个value相等的项
2 count<0 从右向左,删除最多 Math.abs(count)个value相等的项
3 count=0 删除所有value相等的项
lrem listkey 0 a #删除列表中所有值a
lrem listkey -1 c #从右侧删除1个c
ltrim key start end #按照索引范围修剪列表 o(n)
ltrim listkey 1 4 #只保留下表1--4的元素
##########查询操作
lrange key start end #包含end获取列表指定索引范围所有item o(n)
lrange listkey 0 2
lrange listkey 1 -1 #获取第一个位置到倒数第一个位置的元素
lindex key index #获取列表指定索引的item o(n)
lindex listkey 0
lindex listkey -1
llen key #获取列表长度
##########修改操作
lset key index newValue #设置列表指定索引值为newValue o(n)
lset listkey 2 ppp #把第二个位置设为ppp
1.5 集合操作
sadd key element #向集合key添加element(如果element存在,添加失败) o(1)
srem key element #从集合中的element移除掉 o(1)
scard key #计算集合大小
sismember key element #判断element是否在集合中
srandmember key count #从集合中随机取出count个元素,不会破坏集合中的元素(抽奖)
spop key #从集合中随机弹出一个元素
smembers key #获取集合中所有元素 ,无序,小心使用,会阻塞住
sdiff user:1:follow user:2:follow #计算user:1:follow和user:2:follow的差集
sinter user:1:follow user:2:follow #计算user:1:follow和user:2:follow的交集
sunion user:1:follow user:2:follow #计算user:1:follow和user:2:follow的并集
sdiff|sinter|suion + store destkey... #将差集,交集,并集结果保存在destkey集合中
1.6 有序集合
zadd key score element #score可以重复,可以多个同时添加,element不能重复 o(logN)
zrem key element #删除元素,可以多个同时删除 o(1)
zscore key element #获取元素的分数 o(1)
zincrby key increScore element #增加或减少元素的分数 o(1)
zcard key #返回元素总个数 o(1)
zrank key element #返回element元素的排名(从小到大排)
zrange key 0 -1 #返回排名,不带分数 o(log(n)+m) n是元素个数,m是要获取的值
zrange player:rank 0 -1 withscores #返回排名,带分数
zrangebyscore key minScore maxScore #返回指定分数范围内的升序元素 o(log(n)+m) n是元素个数,m是要获取的值
zrangebyscore user:1:ranking 90 210 withscores #获取90分到210分的元素
zcount key minScore maxScore #返回有序集合内在指定分数范围内的个数 o(log(n)+m)
zremrangebyrank key start end #删除指定排名内的升序元素 o(log(n)+m)
zremrangebyrank user:1:rangking 1 2 #删除升序排名中1到2的元素
zremrangebyscore key minScore maxScore #删除指定分数内的升序元素 o(log(n)+m)
zremrangebyscore user:1:ranking 90 210 #删除分数90到210之间的元素
2 高级api使用
2.1 慢查询(假设redis性能不高了,如何取排除)2.1 慢查询(假设redis性能不高了,如何取排除)
所谓慢查询日志就是系统在命令执行前后计算每条命令的执行时间,当超过预设阈值,就将这条命令的相关信息(例如:发生时间、耗时、命令的详细信息)记录下来,
Redis客户端执行一条命令分为4个部分:
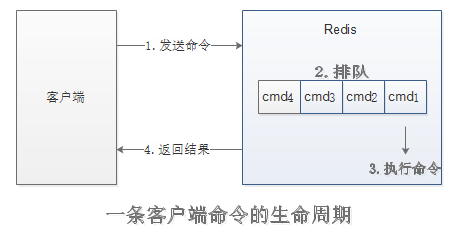
注意:慢查询只会记录执行命令的时间,没有慢查询并不代表客户端没有超时问题。
Redis提供了slowlog-log-slower-than和slowlog-max-len配置来解决这个问题。
从字面意思就可以看出,slowlog-log-slower-than就是那个预设阈值,它的单位是微妙(1秒=1000毫秒=1000000微秒),默认值10000。
假如执行了一条“很慢”的命令(例如keys *),如果它的执行时间超过了10000微秒,那么它将被记录在慢查询日志中。
如果slowlog-log-slower-than=0,那么系统会记录所有的命令;如果slowlog-log-slower-than<0,那么对任何命令都不会记录。
从字面意思看,slowlog-max-len只能说明慢查询日志最多存储多少条,并没有说明存放在那里?
实际上Redis使用了一个列表来存储慢查询日志,slowlog-max-log就是列表的最大长度。
一个新的命令满足慢查询条件时被插入到这个列表中,当慢查询日志列表已经处于最大长度时,列表中最早插入的那条记录将被移除,
在Redis中有两种修改配置的方法,一种是修改配置文件,另一种是使用config set命令动态修改。
例如下面使用config set命令将slowlog-log-slower-than设置为20000微秒,slowlog-max-len设置为1000:
config set slowlog-log-slower-than 20000
config set slowlog-max-len 1000
config rewrite #如果要Redis将配置持久化到本地配置文件,要执行config rewrite命令,它会重写配置文件。
虽然慢查询日志是存放在Redis内存列表中,但是Redis并没有暴露这个列表的键,
而是通过一组命令来实现对慢查询日志的访问和管理,下面介绍这几个命令:
(1)获取慢查询日志
命令:slowlog get [n]
(2)获取慢查询日志列表当前的长度
命令:slowlog len
(3)慢查询日志重置
命令:slowlog reset
实际是对慢查询日志列表做清理操作。
2.2注意事项
慢查询功能可以有效的帮助我们找到Redis可能存在的瓶颈,但在实际使用过程中要注意以下几点:
(1)slowlog-max-len配置建议:线上建议调大慢查询列表,记录慢查询时Redis会对长命令做截断操作,并不会占用大量内存。
增大慢查询列表可以减缓慢查询被剔除的可能。
(2)slowlog-log-slower-than配置建议:默认值超过10毫秒判定为慢查询,需要根据Redis并发量调整该值。
由于Redis采用单线程响应命令,对于高流量的场景,如果命令执行时间在1毫秒以上,那么Redis最多可以支撑OPS不到1000,因此对于高OPS的场景的Redis建议设置1毫秒。
(3)慢查询只记录命令执行时间,并不包括命令排队和网络传输时间。因此客户端执行命令的时间会大于命令实际执行的时间。
因为命令执行排队机制,慢查询会导致其他命令级联阻塞,因此当客户端出现请求超时,
需要检查该时间点是否有对应的慢查询,从而分析出是否为慢查询导致的命令级联阻塞。
(4)由于慢查询日志是一个先进先出的队列,也就是说如果慢查询比较多的情况下,可能会丢失部分慢查询命令,
为了防止这种情况发生,可以定期执行slowlog get命令将慢查询日志持久化到其他存储中(例如,MySQL),
然后可以制作出可视化界面进行查询。
2.3 pipline和watch
Redis 为了支持事务,提供了 5 个相关的命令,他们分别是 MULTI,EXEC, WATCH,UNWATCH 和 DISCARD。我们先介绍 MULTI 和 EXEC 的用法,MULTI 和 EXEC 支持了 Redis 的基本事务的用法。接下来介绍 WATCH,UNWATCH 和 DISCARD,这3个命令则支持更高级的 Redis 事务的用法。
事务允许一次执行多个命令,并且带有以下两个重要的保证:
- 事务是一个单独的隔离的操作:事务中的所有命令会按顺序执行,事务在执行过程中,不会被其他客户端发来的命令请求所打断
- 事务是一个原子的操作:事务中的命令要么全部被执行,要么全部都不执行
Pipeline的使用比较简单,以下是一个简单的例子,更详细的说明可以参考 redis-py 的官方文档。
import redis
r = redis.Redis(host='127.0.0.1', port=6379)
r.set('lee', 'leo')
# 使用 pipeline() 方法创建一个事务型流水线对象 Pipeline
pipe = r.pipeline()
# 以下的 SET 和 GET 命令会被在客户端缓存起来
pipe.set('foo', 'bar')
pipe.get('lee')
# execute() 会将上面缓存起来的所有命令被发送到服务端,
# 并返回所有命令回复的列表
res = pipe.execute()
print(res)
-----------------------------------------
输出为上述两个命令回复的列表:
[True, ‘leo’]
在执行 EXEC 命令之前,Redis 不会执行任何实际的操作,所以用户没办法根据读取到的数据来做决定。Redis 提供了 WATCH 和 UNWATCH 命令来实现更高级的 Redis 事务操作。
使用 MULTI 和 EXEC 封装 Redis 来实现对键增加 1 的原子性操作。但是由于增加 1 的操作依赖于前面读取键值命令的结果,所以单纯使用 MULTI 和 EXEC 也没法实现我们想要的结果。
有了 WATCH,我们就可以轻松地解决这类问题了,我们编写的 Python 的代码如下:
import redis
r = redis.Redis(host='127.0.0.1', port=6379)
with r.pipeline() as pipe:
while True:
try:
# 监视我们需要修改的键
res = pipe.watch('mykey')
# 由于调用了 WATCH 命令,接下来的 pipe 对象的命令都会立马
# 发送到 Redis 服务端执行,故我们可以正常拿到执行的结果
val = pipe.get('mykey')
print('val: %s' % val)
if val:
val = int(val) + 1
else:
val = 1
# 现在,我们重新将 pipe 对象设置为将命令包裹起来执行的形式
pipe.multi()
pipe.set('mykey', val)
# 最后,将包裹起来的命令一起发送到 Redis 服务端以事务形式执行
pipe.execute()
# 如果没抛 WatchError 异常,说明事务被成功执行
break
except redis.WatchError:
# 如果其他客户端在我们 WATCH 和 事务执行期间,则重试
continue
读上面的代码大家可能有个疑问:Pipeline对象不是执行execute()时才一次性将所有命令发送到 Redis 服务端执行么,怎么在代码的中间就可以拿到命令执行的结果了?
由于执行的是 WATCH 命令,接下来的execute_command()方法会调用immediate_execute_command()方法。进入immediate_execute_command()方法查看其代码,可以看到其对于每次调用的命令都会立马发送给 Redis 服务端执行,其获取返回结果。也就是说,通过pipe.watch()的调用,程序可以顺利拿到执行 Redis 命令中间结果的值。
取消监视 UNWATCH
UNWATCH 命令用来取消对所有键的监视。如果在执行 WATCH 命令之后,EXEC 命令已经执行了的话(无论事务是否成功执行),那么就不需要再执行 UNWATCH 了。这是因为当 EXEC 被调用时,Redis 对所有键的监视都会被取消。另外,由于 DISCARD 命令在取消事务的同时也会取消对所有对键的监视,所以 DISCARD 命令执行以后,也没必要执行 UNWATCH 了
放弃事务 DISCARD
当执行 DISCARD 命令时,事务会被放弃,事务队列会被清空
2.4 位图 (本质就是字符串)
redis位图数据结构bitmap将很多小的整数储存到一个长度较大的位图中, 又或者将一个非常庞大的键分割为多个较小的键来进行储存,从而非常高效地使用内存,使得redis能够应用在诸多场景中, 如用户签到、统计活跃用户、用户在线状态等
redis位图是通过一个bit位来表示某个元素对应的值或者状态, 其中的key就是对应元素本身,当然redis位数组是自动扩展,如果设置了某个偏移位置超出了现有的内容范围,就会自动将位数组进行零扩充。
位图不是特殊的数据结构,它的内容其实就是普通的字符串,也就是byte数组。可以使用普通的get/set直接获取和设置整个位图的内容,从redis2.2.0版本开始新增了setbit,getbit,bitcount等几个bitmap相关命令, 也可以使用位图操作getbit/setbit等将byte数组看成「位数组」来处理。
8个bit组成一个Byte,可以通过setbit/getbit来操作单个位但是比较麻烦,但这也正是bitmap本身会极大的节省储存空间, 当然也可以通过bitfield命令来操作多个位。
127.0.0.1:6379> set s hello
OK
# 统计所有`1`的个数
127.0.0.1:6379> bitcount s
(integer) 21
# 统计第一个字符中1个个数
127.0.0.1:6379> bitcount s 0 0
(integer) 3
# 统计前两个字符中1的个数
127.0.0.1:6379> bitcount s 0 1
(integer) 7
# 第一个0 位置
127.0.0.1:6379> bitpos s 0
(integer) 0
#第一个1 位置
127.0.0.1:6379> bitpos s 1
(integer) 1
#从第二个字符开始的第一个1位置
127.0.0.1:6379> bitpos s 1 1 1
(integer) 9
#从第三个字符开始的第一个1位置
127.0.0.1:6379> bitpos s 1 2 2
(integer) 17
127.0.0.1:6379>
注意事项:
- string类型最大长度为512M。
- 注意setbit时的偏移量,当偏移量很大时,可能会有较大耗时。
- 位图不是绝对的好,有时可能更浪费空间
2.5 HyperLogLog
pfadd urls www.baidu.com
pfadd urls www.baidu.com # 放不进去
pfcount urls # 取出来只有1
布隆过滤器(有误差)
应用场景
说明:
- 基数不大,数据量不大就用不上,会有点大材小用浪费空间
- 有局限性,就是只能统计基数数量,而没办法去知道具体的内容是什么
- 和bitmap相比,属于两种特定统计情况,简单来说,HyperLogLog 去重比 bitmap 方便很多
- 一般可以bitmap和hyperloglog配合使用,bitmap标识哪些用户活跃,hyperloglog计数
一般使用:
- 统计注册 IP 数
- 统计每日访问 IP 数
- 统计页面实时 UV 数
- 统计在线用户数
- 统计用户每天搜索不同词条的个数
2.6 geo
### 移动端有定位,往后台传,就是经纬度
geoadd cities:locations 116.28 39.55 beijing
geoadd cities:locations 117.12 39.08 tianjin
geoadd cities:locations 114.29 38.02 shijiazhuang
geoadd cities:locations 118.01 39.38 tangshan
geoadd cities:locations 115.29 38.51 baoding
# 计算北京到唐山的直线距离
geodist cities:locations beijing tianjin km
# 计算北京周五150千米内的城市
georadiusbymember cities:locations beijing 150 km

