变量的存储变化
变量名不占空间
变量名:是一个标识符(identifier),用来指代一块内存区域,即变量,使用变量使我们操作内存以区域(area),以块(block)为单位,提高了方便性。
你的机器代码中,是不会出现变量名的;变量名是给我们程序员操作内存来使用的。
想想在汇编年代,没有变量名,我们操作内存,都是用地址来直接操作的,还要控制区域大小;当然汇编语言已经有了简单的变量。
对于编译器,它会搜集我们的变量名,比如我们定义了一个全局的int a;那么编译器都为我们做了什么呢?
它会为程序预留4个字节的空间(假设在32位平台),并把我们的变量名“a”保存进符号表,并用这个符号表的索引对应实际的空间。
如果下面出现b = a;那么它就会根据符号表找到变量的真正的物理位置,取得它的值,赋给b。
这是写编译器需要做的,我们需要建立符号表。
但是实际在汇编层次上,操作的都是地址而已,不存在任何名称了。
除了变量名不是内存地址,其他名都是地址。对么?
所谓的其他名无非是函数名、标识符常量名、指针名、数组名、结构名、类名等等。
比如指针名、数组名、函数名就是地址,它们分别表示指针所指向元素的地址、数组的首地址和函数的入口地址。
变量名虽然不直接表示地址,但可用取地址符号&来获得它所代表的变量的存放地址。因为在定义变量的同时会分配给它相应的空间。
但类和结构只有事例化时才为它分配空间,从而不能用取地址符号&来获得类名或结构名的地址。
变量名是用来标识某个内存块的
地址就是地址啦,如是变量名的话,用取地址运算符&就可以得到它标识的内存块的地址,
而指针变量呢,它本身也是一个变量名,只不过它标识的那块内存存放的是一个地址值
变量是地址的别名..就像刚生的小孩,你只知道他在地球上的某个位置,而不能叫出他名字,给你取个名
定义int a;时,编译器分配4个字节内存,并命名该4个字节的空间名字为a(即变量名),当用到变量名a时,就是在使用那4个字节的内存空间.
5是一个常数,在程序编译时存放在代码的常量区存放着它的值(就是5),当执行a=5时,程序将5这个常量拷贝到a所在的4个字节空间中,就完成了赋值操作.
a是我们对那个整形变量的4个字节取的"名字",
是我们人为给的,实际上计算机并不存储a这个名字,只是我们编程时给那4个字节内存取个名字好用.实际上程序在编译时,所有的a都转换为了那个地址空间了.编译成机器代码后,没有a这个说法了.a这个名字只存在于我们编写的代码中.
5不是被随机分配的,而总是位于程序的数据段中,可能在不同的机器上在数据段中的位置可能不一致,它的地址其实不能以我们常用到的内存地址来理解,因为牵扯到一个叫"计算机寻址方式"的问题,所以写很多都解释不清楚。
汇编语言部分~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
数据寄存器(AX、BX、CX、DX) 寄存器AX通常称为累加器(Accumulator),用累加器进行的操作可能需要更少时间。累加器可用于乘、除、输入/输出等操作,它们的使用频率很高;
寄存器BX称为基地址寄存器(Base Register)。它可作为存储器指针来使用;
寄存器CX称为计数寄存器(Count Register)。在循环和字符串操作时,要用它来控制循环次数;
寄存器DX称为数据寄存器(Data Register)。在进行乘、除运算时,它可作为默认的操作数参与运算,也可用于存放I/O的端口地址;
变址寄存器(SI、DI) 我们主要针对于数据的存储进行操作
寄存器SI和DI称为变址寄存器(Index Register),它们主要用于存放存储单元在段内的偏移量,用它们可实现多种存储器操作数的寻址方式,为以不同的地址形式访问存储单元提供方便
1、常用寻址方式
- 隐含寻址 含义:操作数隐含的由累加器给出。(即某指令由固定的操作数,不需要给出)例子:8086汇编语言 CWD;把AX中的内容按符号位拓展成DX,AX双字
- 立即寻址 含义:指令中直接给出相应的操作数。 例子: MOV AX,1234H;——1234H就是采用立即寻址
- 寄存器直接寻址 含义:指令中给出寄存器号R,操作数存放在R中 E=R,S=(E)=( R ) 例子:MOV AX,BX——操作数在BX中
- 寄存器间接寻址 含义:指令中给出寄存器号R,R中存放操作数的有效地址 E=( R ),S=(E)=(( R )) 例子:MOV AX,[SI]
- 直接寻址 含义:指令中给出操作数的有效地址 E=A,S=(E)=(A)例子:MOV AX,[1234H]
- 间接寻址 含义:指令中给出存放有效地址E的存储单元地址。 E=(A),S=(E)=((A)) 理论上讲可以多次间接寻址,但大多数计算机只允许一次(由于A的寻址范围不足以覆盖整个存储空间)
- 相对寻址 含义:指令中给出相对于PC的偏移量A E=(PC)+A,S=(E)=((PC)+A) 注:A是个带符号数,一般用补码表示,若A的位数与PC不一致,需要带符号填充。
- 基址寻址 含义:指令中给出相对于基址寄存器R的偏移量 E=( R )+A,S=(E)=(( R )+A) 注:A是个带符号数,一般用补码表示,若A的位数与R不一致,需要带符号填充。
- 变址寻址 含义:指令中给出相对变址寄存器R的偏移量 E=( R )+A,S=(E)=(( R )+A) 注:A是个带符号数,一般用补码表示,若A的位数与R不一致,需要带符号填充。
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
C语言中变量只是标识对应存储单元内的存储内容。与地址的对应关系
int a=3;
a---&a一一对应啊,变量名只是一个便于记忆识别的名称,编译器会将他编译成相应的内存地址的.变量都要占据一定的内存。通过定义该变量的指针, [类型]* 指针名=你要指向的变量名那么该指针中存储的就是你的变量的内存地址。 &你的变量名 这样就可以直接获取到你的变量地址或者定义引用 [类型]& 引用名=变量名该引用可通过变量的地址来对变量进行修改.
~~~~~~~~~~~~~~~~~~~~~~~~~
变量名是给编译器看的,编译器根据变量是局部还是全局分配内存地址或栈空间,所谓的变量名在内存中不存在,操作时转换成地址数存放在寄存器中了。
编译器会将合法的变量名放到一个叫“符号表”的一个表中。
每个符号对应一个地址。当你调用此变量时,就会根据此符号表找到对应的地址,然后进行操作。
~~~~~~~~~~~~~~~~~~~~~~~~~~~~
所谓在编译期间分配空间指的是静态分配空间(相对于用new动态申请空间),如全局变量或静态变量(包括一些复杂类型的常量),它们所需要的空间大小可以明确计算出来,并且不会再改变,因此它们可以直接存放在可执行文件的特定的节里(而且包含初始化的值),程序运行时也是直接将这个节加载到特定的段中,不必在程序运行期间用额外的代码来产生这些变量。
其实在运行期间再看“变量”这个概念就不再具备编译期间那么多的属性了(诸如名称,类型,作用域,生存期等等),对应的只是一块内存(只有首址和大小),所以在运行期间动态申请的空间,是需要额外的代码维护,以确保不同变量不会混用内存。比如写new表示有一块内存已经被占用了,其它变量就不能再用它了; 写delete表示这块内存自由了,可以被其它变量使用了。(通常我们都是通过变量来使用内存的,就编码而言变量是给内存块起了个名字,用以区分彼此)
内存申请和释放时机很重要,过早会丢失数据,过迟会耗费内存。特定情况下编译器可以帮我们完成这项复杂的工作(增加额外的代码维护内存空间,实现申请和释放)。从这个意义上讲,局部自动变量也是由编译器负责分配空间的。进一步讲,内存管理用到了我们常常挂在嘴边的堆和栈这两种数据结构。
最后对于“编译器分配空间”这种不严谨的说法,你可以理解成编译期间它为你规划好了这些变量的内存使用方案,这个方案写到可执行文件里面了(该文件中包含若干并非出自你大脑衍生的代码),直到程序运行时才真正拿出来执行!
我尝试从由底向上来解释题主的疑问,顺便推荐王爽的《汇编语言》,看了前几章题主应该就明白了,了解一点汇编,CPU工作原理和编译知识还是有必要的
1.机器语言
机器语言是机器指令的集合。电子计算机的机器指令是-列二进制数字。计算机将之转变为一列高低电平,以使计算机的电子器件受到驱动,进行运算。
如应用8086CPU 完成运算s=768+12288-1280,机器码如下:
101100000000000000000011
000001010000000000110000
001011010000000000000101
每行代表一个指令,我只是搬运工,反正看不懂,现在估计也找不到几个不靠工具看得懂这玩意的人了~
[关于变量名]:机器语言中没有变量名的概念,一切操作都是直接对地址进行
2.汇编语言
早期的程序员们很快就发现了使用机器语言带来的麻烦,它是如此难于辨别和记忆,给整个产业的发展带来了障碍。于是汇编语言产生了。
汇编语言与机器语言是每个指令是一一对应的,最终由汇编器把写有汇编语言的文本文件编译成可执行程序。
例如:将寄存器BX内的数据到AX中(寄存器是CPU内部的一组存储器,大多数指令都需要先将内存里的数据读入寄存器后才能开始运算。AX,BX是其中两个寄存器的代号)
机器指令:1000100111011000
汇编指令:mov ax,bx
[关于变量名]:汇编语言中就有变量的概念。在编译时由汇编器计算相关变量的偏移或实际地址,在编译出的二进制机器语言中直接使用该地址操作内存。
程序员们后来发现,用汇编语言写程序还是麻烦,因为它和机器指令意义对应,更加接近CPU的思维,而不是人的思维。于是发明了很多高级语言,C就是其中的一种。
C语言编译的过程,实际上首先通过 “编译器”将C语言翻译成汇编语言,再通过“汇编器”将汇编语言转化成机器代码,对于编译器来讲,将C转化成汇编的时候,不是一一对应的关系,也就是说几行C代码,可能翻译成几十行汇编。而汇编语言指令和机器代码指令,从某种意义来讲,是一个东西,两者是一一对应的关系。
[关于变量名]:C语言中处处是变量,即使是个指针,它自身也是个4字节的变量才能储存一个地址(32位程序)。编译后,有输出文件包括以下两种:
- 可执行文件(xxxx.exe),一段二进制文件,其中代码段(代码段,数据段啥的也可以百度了解)的机器指令CPU可以直接识别执行。
- 符号文件(xxxx.pdb),记录了变量和地址的对应信息。仅供调试使用,程序运行时不需要该文件。
变量的存储在高级语言中万物皆对象的思想 所以不同于C语言
在高级语言中,变量是对内存及其地址的抽象。
对于python而言,python的一切变量都是对象,变量的存储,采用了引用语义的方式,存储的只是一个变量的值所在的内存地址,而不是这个变量的只本身。
引用语义:在python中,变量保存的是对象(值)的引用,我们称为引用语义。采用这种方式,变量所需的存储空间大小一致,因为变量只是保存了一个引用。也被称为对象语义和指针语义。
值语义:有些语言采用的不是这种方式,它们把变量的值直接保存在变量的存储区里,这种方式被我们称为值语义,例如C语言,采用这种存储方式,每一个变量在内存中所占的空间就要根据变量实际的大小而定,无法固定下来。
值语义和引用语义的区别:
值语义: 死的、 傻的、 简单的、 具体的、 可复制的
引用语义: 活的、 聪明的、 复杂的、 抽象的、 不可复制的
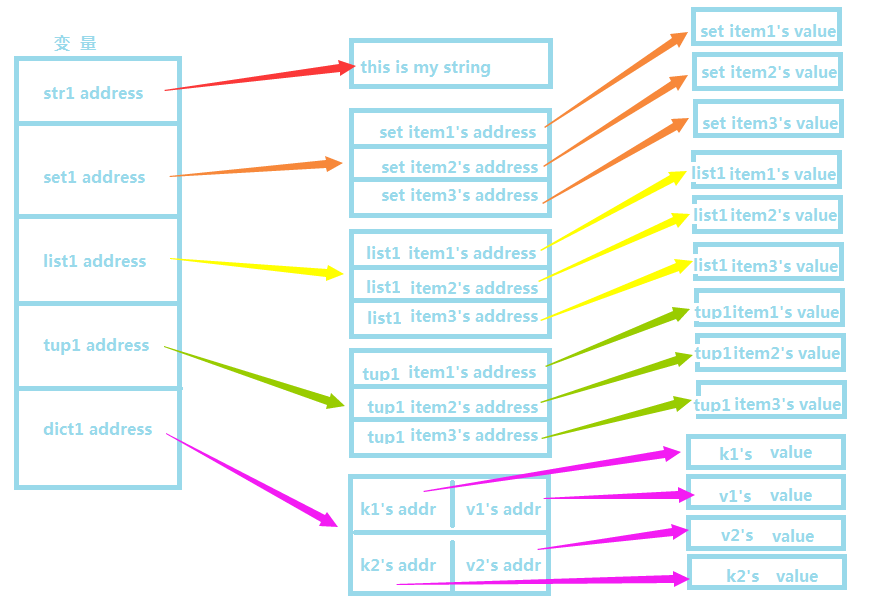
由于python中的变量都是采用的引用语义,数据结构可以包含基础数据类型,导致了在python中每个变量中都存储了这个变量的地址,而不是值本身;
下面这个图就是C语言和python的区别
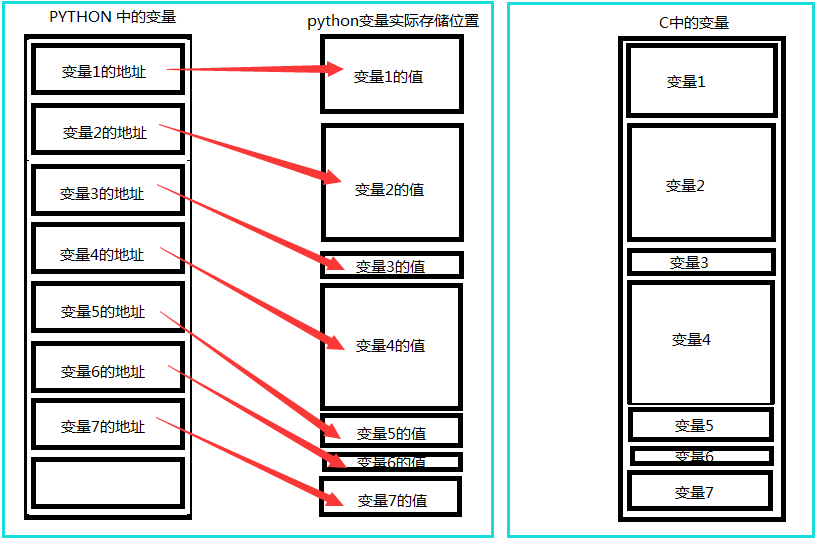
由于python中的变量都是采用的引用语义,数据结构可以包含基础数据类型,导致了在python中数据的存储是下图这种情况,每个变量中都存储了这个变量的地址,而不是值本身;对于复杂的数据结构来说,里面的存储的也只只是每个元素的地址而已。