
阿里、网易、滴滴共十次前端面试碰到的问题
前一段时间一直在不断地面试,无奈个人技术能力有限、项目经验缺乏,最终都没有进入到HR面试环节,全~~挂~~了~~
面试了这么多,结果不是太好,有点儿受打击,也促使我近期静下心来反思自己的问题:哪些技术知识掌握的还不错,哪些还有待提高,哪些是需要去恶补的。
阿里面试了三个部门,都是在二面挂的,网易和滴滴也是各两轮技术面试,加一起就是十次面试经历。在此回忆总结一下,既是给社区朋友的一个参考,反馈社区,更是给自己一个好好的总结。
HTML
-
HTML5新增了哪些内容或API,使用过哪些
-
新增特性整理
1、简化的文档类型和字符集
(1)文档类型
<!DOCTYPE HTML>
之所以如此简单,是因为HTML5不再是SGML( Standard Generalized Markup language,标准通用标记语言)的一部分,而是独立的标记语言,不需要再考虑文档类型
(2)字符集
<meta charset="UTF-8">
只需要utf-8即可
2、富有语义化的新结构元素
<header>
<h1>HTML5新结构<h1/>
<nav>导航部分</nav>
<p></p>
</header><section> <h1></h1> <p>不再全是div</p>
。。。 </section>
<footer>
</footer>section元素 可以认为div是section元素,一个普通的分块元素,可用来定义网站中的特定的可区别的区域
header元素包括标题,logo,导航和其他页眉的内容,可以在网站上加多个header,就像给内容加多个标题
hgroup元素 即将标题进行分组的元素
footer元素版权声明和作者信息,包涵一些链接
nav元素主要用于主导航菜单
article元素独立成文且以其他格式重用的内容应该置于一个article元素中
aside元素用途包涵内容周围的相关内容
3、新增的内联元素
<figure> <p>图片</p> <img src="img1.jpg" width="100" height="100"> </figure>figure元素一个典型用途是包含图像,代码和其他内容对主要内容进行说明,删除不会影响主内容
figcaption元素主要用于figure的标题
mark元素突出显示以表示引用的内容,或者突出显示与用户当前活动相关的内容,他不同于en或strong元素
time元素,当需要在内容中显示时间或者日期时,则建议使用time元素
time元素可以包涵两个属性,一个datetime表示在元素中指定的确切日期和世家,pubdate表示文章或者整个文档发布时time元素所指定的日期和时间
meter元素用于定义度量衡,规定最大最小宽高,通常要结合css一起作用,效果如下:
![技术分享]()
progress元素用于定义一个进度条,有max(完成值)和value(进度条当前值)两个属性。
4、支持动态页面
1)菜单<menu>
用于表单中组织控件列表,常用属性如下:
![技术分享]()
定义一个选择列表的例子:
<menu> <li><input type="checkbox"/>a</li> <li><input type="checkbox"/>b</li> <li><input type="checkbox"/>c</li> </menu> <!--目前主流浏览器都不支持-->2)右键菜单<menitem>
![技术分享]()
3)在<script>标签中使用async属性
用于指定异步执行的脚本
4)<detail>元素
用于描述文档或文档某个部分的细节
<details> <summary>details</summary> <p>用于描述文档细节<p> </details>效果:
![技术分享]()
展开后:
![技术分享]()
5、全新的表单设计
HTML5 新的 Input 类型
HTML5 拥有多个新的表单输入类型。这些新特性提供了更好的输入控制和验证。
- url
- number
- range
- Date pickers (date, month, week, time, datetime, datetime-local)
- search
- color
HTML5 的新的表单元素:
- datalist
- keygen
- output
新的 form 属性:
- autocomplete
- novalidate
新的 input 属性:
- autocomplete
- autofocus
- form
- form overrides (formaction, formenctype, formmethod, formnovalidate, formtarget)
- height 和 width
- list
- min, max 和 step
- multiple
- pattern (regexp)
- placeholder
- required
autocomplete 属性规定 form 或 input 域应该拥有自动完成功能。
当用户在自动完成域中开始输入时,浏览器应该在该域中显示填写的选项:
实例:
<form action="/example/html5/demo_form.asp" method="get" autocomplete="on">
First name:<input type="text" name="fname" /><br />
Last name: <input type="text" name="lname" /><br />
E-mail: <input type="email" name="email" autocomplete="off" /><br />
<input type="submit" />
</form>
<p>请填写并提交此表单,然后重载页面,来查看自动完成功能是如何工作的。</p>![技术分享]()
结果:
![技术分享]()
6、强大的绘图功能和多媒体功能
1)canvas 可以动态地绘制各种效果精美的图形,结合js就能让网页图形动起来
2)SVG 绘制可伸缩的矢量图形
3)audio和 video 可以不依赖任何插件播放音频和视频
7、打造桌面应用的一系列新功能
离线缓存 Web Storage(为HTML5开发移动应用提供了基础)
传统的web应用程序中,数据处理都由服务器处理,html只负责展示数据,cookie只能存储少量的数据,跨域通信只能通过web服务器。
HTML5扩充了文件存储的能力,多达5MB,支持WebSQL等轻量级数据库,可以开发支持离线web应用程序。
HTML5 Web Storage API可以看做是加强版的cookie,不受数据大小限制,有更好的弹性以及架构,可以将数据写入到本机的ROM中,还可以在关闭浏览器后再次打开时恢复数据,以减少网络流量。
同时,这个功能算得上是另一个方向的后台“操作记录”,而不占用任何后台资源,减轻设备硬件压力,增加运行流畅性。
8、获取地理位置信息
新增Geolocation API,可以通过浏览器获取用户的地理位置,不再需要借助第三方地址数据库或专业的开发包,提供很大的方便。
9、支持多线程
新增Web Worker对象,可以在后台运行js脚本,也就是支持多线程,从而提高了页面加载效率。
10、废弃的标签
1.表现性元素
2.框架类元素
3.属性类
4.其他类
-
HTML5新增了哪些标签
-
标签 标记意义及用法分析/示例 属性/属性值/描述 <article> 定义独立的内容,如论坛帖子、报纸文章、博客条目、用户评论等内容。 支持HTML5的全局属性和事件属性。 <aside> 定义两栏或多栏页面的侧边栏内容,如联系我们、客服、网站公告等内容。 支持HTML5的全局属性和事件属性。 <audio> 定义音频内容,如音乐或其他音频流。 autoplay autoplay 自动播放。 controls controls 显示控件。 loop loop 自动重播。 preload preload 预备播放。如果使用 “autoplay”,则忽略该属性。 src url 音频的URL。 支持HTML5的全局属性和事件属性。
<audio src=”audio.wav”> 您的浏览器不支持 audio 标签。(注:可以在开始标签和结束标签之间加上此文本内容,这样若浏览器不支持此元素,就可以显示出这个信息。)
</audio>
<canvas> 定义图形,如图表和其他图像。(注:<canvas> 只是图形容器,我们必须使用脚本来绘制图形。) height pixels 设置 canvas 的高度。 width pixels 设置 canvas 的宽度。 支持HTML5的全局属性和事件属性。
<canvas id=”myCanvas”></canvas> <script type=”text/javascript”>
var canvas=document.getElementById(‘myCanvas’);
var ctx=canvas.getContext(‘2d’);
ctx.fillStyle=’#FFFF00′;
ctx.fillRect(0,0,20,30);
</script>
<command> 标记定义一个命令按钮,比如单选按钮、复选框或按钮。只有当 command 元素位于 menu 元素内时,该元素才是可见的。否则不会显示这个元素,但是可以用它规定键盘快捷键。 checked checked 定义是否被选中。仅用于 radio 或 checkbox 类型 disabled disabled 定义 command 是否可用 icon url 定义作为 command 来显示的图像的url label text 为 command 定义可见的 label radiogroup groupname 定义 command 所属的组名。仅在类型为 radio 时使用 type checkbox command
radio
定义该 command 的类型。默认是 “command” 支持HTML5的全局属性和事件属性。
<menu> <command onclick=”alert(‘Hello!’)”>Click here.</command>
</menu>
<datalist> 定义选项列表,需与 input 元素配合使用,通过input 元素的 list 属性来绑定,用来定义 input 可能的值。datalist 及其选项不会被显示出来,它仅仅是合法的输入值列表。 支持HTML5的全局属性和事件属性。 <input id=”fruits” list=”fruits” /> <datalist id=”fruits”>
<option value=”Apple”>
<option value=”Banana”>
</datalist>
<details> 用于描述文档或文档某个部分的细节。 open open 定义 details 是否可见 支持HTML5的全局属性和事件属性。
<details> <summary>Some title.</summary>
<p>Some details about the title.</p>
</details>
<embed> 定义外部的可交互的内容或插件。 height pixels 设置嵌入内容的高度 src url 嵌入内容的 URL type type 定义嵌入内容的类型 width pixels 设置嵌入内容的宽度 支持HTML5的全局属性和事件属性。
<embed src=”someone.swf” /> <figure> 定义一组媒体内容(图像、图表、照片、代码等)以及它们的标题。如果被删除,则不应对文档流产生影响。 支持HTML5的全局属性和事件属性。 <figure> <p>The title of the image.</p>
<img src=”someimage.jpg” width=”100″ height=”50″ />
</figure>
<footer> 定义一个页面或一个区域的页脚。可包含文档的作者姓名、创作日期或者联系信息。 支持HTML5的全局属性和事件属性。 <header> 定义一个页面或一个区域的头部。 支持HTML5的全局属性和事件属性。 <hgroup> 定义文件中一个区块的相关信息,使用 <hgroup> 标签对网页或区段(section)的标题进行组合。 支持HTML5的全局属性和事件属性。 <hgroup> <h1>Welcome my world!</h1>
<h2>This is a title.</h2>
</hgroup>
<keygen> 定义表单里一个生成的键值。规定用于表单的密钥对生成器字段。当提交表单时,私钥存储在本地,公钥发送到服务器。 autofocus autofocus 使 keygen 字段在页面加载时获得焦点 challenge challenge 如果使用,则将 keygen 的值设置为在提交时询问 disabled disabled 禁用 keytag 字段 form formname 定义该 keygen 字段所属的一个或多个表单 keytype rsa 定义 keytype。rsa 生成 RSA 密钥 name fieldname 定义 keygen 元素的唯一名称,用于在提交表单时搜集字段的值。 支持HTML5的全局属性和事件属性。
<form action=”demo_keygen.asp” method=”get”> Username: <input type=”text” name=”usr_name” />
Encryption: <keygen name=”security” />
<input type=”submit” />
</form>
<mark> 定义有标记的文本。请在需要突出显示文本时使用此标签。 支持HTML5的全局属性和事件属性。 <p>I like <mark>apple</mark> most.</p> <meter> 定义度量衡。仅用于已知最大和最小值的度量。(注:必须定义度量的范围,既可以在元素的文本中,也可以在 min/max 属性中定义。) high number 定义度量的值位于哪个点,被界定为高的值 low number 定义度量的值位于哪个点,被界定为低的值 max number 定义最大值。默认值是 1 min number 定义最小值。默认值是 0 optimum number 定义什么样的度量值是最佳的值。如果该值高于 “high” 属性,则意味着值越高越好。如果该值低于 “low” 属性的值,则意味着值越低越好。 value number 定义度量的值 支持HTML5的全局属性和事件属性。
<meter min=”0″ max=”10″>2</meter> <meter>2 out of 5</meter>
<meter>10%</meter>
<nav> 定义导航链接。(注:如果文档中有“前后”按钮,则应该把它放到 <nav> 元素中。) 支持HTML5的全局属性和事件属性。 <nav> <a href=”index.asp”>Home</a>
<a href=”Previous.asp”>Previous</a>
<a href=”Next.asp”>Next</a>
</nav>
<output> 定义不同类型的输出,比如脚本的输出。 for id of another element 定义输出域相关的一个或多个元素 form formname 定义输入字段所属的一个或多个表单 name unique name 定义对象的唯一名称。(表单提交时使用) 支持HTML5的全局属性和事件属性。
<progress> 定义任务(如下载)的过程,可以使用此标签来显示 JavaScript 中耗费时间的函数的进度。 max number 定义完成的值 value number 定义进程的当前值 支持HTML5的全局属性和事件属性。
<progress> <span id=”progress”>15</span>%
</progress>
<ruby> 定义 ruby 注释(中文注音或字符)。在东亚使用,显示的是东亚字符的发音。ruby 元素由一个或多个字符(需要一个解释/发音)和一个提供该信息的 rt 元素组成,还包括可选的 rp 元素,定义当浏览器不支持 “ruby” 元素时显示的内容。 支持HTML5的全局属性和事件属性。 <section> 定义文档中的节(section、区段)。比如章节、页眉、页脚或文档中的其他部分。 cite URL 当 section 摘自 web 的时候使用 支持HTML5的全局属性和事件属性。
<source> 为媒介元素(比如 <video> 和 <audio>)定义媒介资源。 media media query 定义媒介资源的类型,供浏览器决定是否下载 src url 媒介的 URL type numeric value 定义播放器在音频流中播放起始位置。默认是从开头播放。 支持HTML5的全局属性和事件属性。
<time> 定义一个日期/时间,该元素能够以机器可读的方式对日期和时间进行编码,举例说,用户代理能够把生日提醒或排定的事件添加到用户日程表中,搜索引擎也能够生成更智能的搜索结果。 datetime datetime 规定日期或时间。否则,由元素的内容给定日期或时间 pubdate pubdate 指示 <time> 元素中的日期或时间是文档的发布日期 支持HTML5的全局属性和事件属性。
<p>大家都是早上 <time>9:00</time> 上班。</p> <p><time datetime=”2012-01-01″>元旦</time>晚会。</p>
<video> 定义视频,比如电影片段或其他视频流。 autoplay autoplay 自动播放。 controls controls 显示控件。 height pixels 设置视频播放器的高度 loop loop 自动重播。 preload preload 预备播放。如果使用 “autoplay”,则忽略该属性。 src url 视频的URL。 width pixels 设置视频播放器的宽度 支持HTML5的全局属性和事件属性。
<video src=”movie.ogg” controls=”controls”> 您的浏览器不支持 video 标签。(注:可以在开始标签和结束标签之间加上此文本内容,这样若浏览器不支持此元素,就可以显示出这个信息。)
</video>
-
-
input和textarea的区别
- <input>元素:
1.一定要指定type的值为text;
2.通过size属性指定显示字符的长度,value属性指定初始值,Maxlength属性指定文本框可以输入的最长长度;
1 <input type="text" value="入门狗" size="10" Maxlength="15">
<textarea>元素
1.使用<textarea></textarea>标签对
2.内容放在<textarea></textarea>标签对中
3.使用row、col指定大小
1 <textarea row="3" col="4">入门狗的博客园</textarea>
区别:一个是单行文本框,一个是多行文本框。
- <input>元素:
-
用一个div模拟textarea的实现
-
div模拟textarea
有些Weber可能没有用过contenteditable这个属性,如果想编辑一个DIV里面的内容,这个属性是一个非常不错的选择
<div contenteditable="true">可以编辑里面的内容</div>
如果你在BODY里面加上contenteditable="true",可以发现该属性是多么的神奇。因此我们可以给HTML标签设置contenteditable="true"属性则可以对该标签进行编辑。contenteditable属性兼容所有浏览器(IE6之前的版本是否兼容未测试)
在有些时候我们完全可以用DIV去替代input或者textarea来达到同样的效果,例如,在使用ajax的时候,在提交表单时我们可以获取DIV的内容。
细心的人会发现,QQ空间中的发表说说的文本框其实就是一个DIV,而非textarea文本框。
Div+CSS如何模拟textarea文本域高度自适应以达到html5标准的contenteditable属性
主要通过为标签添加HTML5中的contenteditable属性达到此效果(contenteditable:规定是否允许用户编辑内容),很棒的是,此属性IE也会支持,所以不用再为兼容问题太去纠结了。
代码如下:
<style type="text/css">
.demoEdit{border:1px solid #dddddd;width:450px;min- height:20px;_height:20px;outline:0px;padding:2px;} // outline:0px;样式解决容器获取焦点时,在FF浏览器下容器会显示虚线框的效果.
.demoEdit p{margin:0px;padding:0px;}
</style>
<div contenteditable="true" style="border:1px solid #dddddd;width:360px;min-height:20px;_height:20px;outline:0px;"></div>
<div contenteditable="true" class="demoEdit"></div>附:
在FF浏览器下,容器获取焦点时,光标的高度会与容器的高度一样高或者不显示光标. 此时若为容器默认加个占位符,比如<br/>或 可以解决这一问题.
现在煜子给大家介绍另一种可编辑可自动适应高度,但又不用加js代码的好方法。让大家开开眼界,煜子直接使用DIV也可以当文本框用,类似于TextArea文本框,更重要的是DIV的用户体验更完美更帅。Html中的contentEditable属性可以打开某些元素的可编辑状态。也许你没用过contentEditable属性,甚至从未听说过,contentEditable的作用相当神奇。可以让div或整个网页,以及span等等元素设置为可写.我们最常用的输入文本内容便是input与textarea 使用contentEditable属性后,可以在div,table,p,span,body,等等很多元素中输入内容.特别是contentEditable已在html5标准中得到有效的支持。大家来见证一下吧。
设置contentEditable=”true”属性后,是不是相当的神奇。哈哈…
DEMO页面: http://demo.jb51.net/js/2014/ContentEditable/我们来个特效吧,通过开启div元素编辑,是否能插入图片,这是需要用到js了。
代码如下:
<script>
function img(){
var location1 = prompt("请输入图片的地址:","http://");
if(location1){
selImg(location1);
}
}
function selImg(s){
if(!s){return false;}
var h=s.substr(s.lastIndexOf(".")+1,3);
if(h=="gif"||h=="jpg" || h=="GIF" || h=="JPG"){
Edit=document.getElementById("idEdit")
Edit.innerHTML+='<img src='+s+'>'
}
else{
}
}
</script>
<div NAME=EditCtrl id=idEdit contentEditable=true style="width:100%;height:200px;border:1px solid #666666"> <b>Yuzi.me</b></div>
<input type="button" name="Submit" value="插入图片" onclick="img()">
-







CSS
-
左右布局:左边定宽、右边自适应,不少于3种方法
- (兼容所有浏览器)
左侧固定宽,右侧自适应屏幕宽;
左右两列,等高布局;
左右两列要求有最小高度,例如:200px;(当内容超出200时,会自动以等高的方式增高)
要求不用JS或CSS行为实现;
仔细分析试题要求,要达到效果其实也并不是太难,只是给人感觉像有点蛋疼的问题一样。但是你仔细看后你会觉得不是那么回事:
左边固定,右边自适应布局,这个第一点应该来说是非常的容易,实现的方法也是相当的多,那么就可以说第一条要求已不是什么要求了;
左右两列等高布局,这一点相对来说要复杂一些,不过你要是了解了怎么实现等高布局,那么也是不难。我个人认为这个考题关键之处就在考这里,考你如何实现等高布局;所以这一点你需要整明白如何实现;
至于第三条要求,应该来说是很方面的,我们随处都可以看到实现最小高度的代码;
第四条这个要求我想是考官想让我们面试的人不能使用js来实现等高布局和最小高度的功能。
上面简单的分析了一下实现过程,那么最终关键之处应该是就是“让你的代码要能同时实现两点,其一就是左边固定,右边自适应的布局;其二就是实现两列等高的布局”,如果这两个功能完成,那么你也就可以交作业了。那么下面我们就先来看看这两 点是如合实现:
一、两列布局:左边固定宽度,右边自适应宽度
这样的布局,其实不是难点,我想很多同学都有实现过,那么我就在此稍微介绍两种常用的方法:
方法一:浮动布局
这种方法我采用的是左边浮动,右边加上一个margin-left值,让他实现左边固定,右边自适应的布局效果
HTML Markup
<div id="left">Left sidebar</div>
<div id="content">Main Content</div>
CSS Code
<style type="text/css">
*{
margin: 0;
padding: 0;
}
#left {
float: left;
width: 220px;
green;
}
#content {
orange;
margin-left: 220px;/*==等于左边栏宽度==*/
}
</style>
上面这种实现方法最关键之处就是自适应宽度一栏“div#content”的“margin-left”值要等于固定宽度一栏的宽度值,大家可以点击查看上面代码的DEMO
方法二:浮动和负边距实现
这个方法采用的是浮动和负边距来实现左边固定宽度右边自适应宽度的布局效果,大家可以仔细对比一下上面那种实现方法,看看两者有什么区别:
HTML Markup
<div id="left">
Left Sidebar
</div>
<div id="content">
<div id="contentInner">
Main Content
</div>
</div>
CSS Code
*{
margin: 0;
padding: 0;
}
#left {
green;
float: left;
width: 220px;
margin-right: -100%;
}
#content {
float: left;
width: 100%;
}
#contentInner {
margin-left: 220px;/*==等于左边栏宽度值==*/
orange;
}
这种方法看上去要稍微麻烦一点,不过也是非常常见的一种方法,大家可以看看他的DEMO效果。感觉一下,和前面的DEMO有什么不同之处。
我 在这里就只展示这两种方法,大家肯定还有别的实现方法,我就不在多说了,因为我们今天要说的不是这个问题。上面完成了试题的第一种效果,那么大家就要想办 法来实现第二条要求——两列等高布局。这一点也是本次面试题至关重要的一点,如果你要是不清楚如何实现等高布局的话,我建议您先阅读本站的《八种创建等高 列布局》,里面详细介绍了八种等高布局的方法,并附有相关代码,而且我们后面的运用中也使用了其中的方法。
现在关键的两点都完成了,那么我们就需要实现第三条要求,实现最小高度的设置,这个方法很简单:
min-height: 200px;
height: auto !important;
height: 200px;
上面的代码就轻松的帮我们实现了跨浏览器的最小高度设置问题。这样一来,我们可以交作业了,也完面了这个面试题的考试。为了让大家更能形象的了解,我在这里为大家准备了五种不同的实现方法:
方法一:
别的不多说,直接上代码,或者参考在线DEMO,下面所有的DEMO都有HTML和CSS代码,感兴趣的同学自己慢慢看吧。
HTML Markup
<div id="container">
<div id="wrapper">
<div id="sidebar">Left Sidebar</div>
<div id="main">Main Content</div>
</div>
</div>
CSS Code
<style type="text/css">
* {
margin: 0;
padding: 0;
}
html {
height: auto;
}
body {
margin: 0;
padding: 0;
}
#container {
background: #ffe3a6;
}
#wrapper {
display: inline-block;
border-left: 200px solid #d4c376;/*==此值等于左边栏的宽度值==*/
position: relative;
vertical-align: bottom;
}
#sidebar {
float: left;
width: 200px;
margin-left: -200px;/*==此值等于左边栏的宽度值==*/
position: relative;
}
#main {
float: left;
}
#maing,
#sidebar{
min-height: 200px;
height: auto !important;
height: 200px;
}
</style>
查看在线DEMO。
方法二
HTML Markup
<div id="container">
<div id="left" class="aside">Left Sidebar</div>
<div id="content" class="section">Main Content</div>
</div>
CSS Code
<style type="text/css">
*{margin: 0;padding: 0;}
#container {
overflow: hidden;
}
#left {
background: #ccc;
float: left;
width: 200px;
margin-bottom: -99999px;
padding-bottom: 99999px;
}
#content {
background: #eee;
margin-left: 200px;/*==此值等于左边栏的宽度值==*/
margin-bottom: -99999px;
padding-bottom: 99999px;
}
#left,
#content {
min-height: 200px;
height: auto !important;
height: 200px;
}
</style>
查看在线的DEMO。
方法三:
HTML Markup
<div id="container">
<div id="content">Main Content</div>
<div id="sidebar">Left Sidebar</div>
</div>
CSS Code
*{margin: 0;padding: 0;}
#container{
overflow:hidden;
padding-left:220px; /* 宽度大小等与边栏宽度大小*/
}
* html #container{
height:1%; /* So IE plays nice */
}
#content{
width:100%;
border-left:220px solid #f00;/* 宽度大小等与边栏宽度大小*/
margin-left:-220px;/* 宽度大小等与边栏宽度大小*/
float:right;
}
#sidebar{
width:220px;
float:right;
margin-left:-220px;/* 宽度大小等与边栏宽度大小*/
}
#content,
#sidebar {
min-height: 200px;
height: auto !important;
height: 200px;
}
查看在线DEMO效果。
方法四:
HTML Markup
<div id="container2">
<div id="container1">
<div id="col1">Left Sidebar</div>
<div id="col2">Main Content</div>
</div>
</div>
CSS Code
*{padding: 0;margin:0;}
#container2 {
float: left;
width: 100%;
background: orange;
position: relative;
overflow: hidden;
}
#container1 {
float: left;
width: 100%;
background: green;
position: relative;
left: 220px;/* 宽度大小等与边栏宽度大小*/
}
#col2 {
position: relative;
margin-right: 220px;/* 宽度大小等与边栏宽度大小*/
}
#col1 {
width: 220px;
float: left;
position: relative;
margin-left: -220px;/* 宽度大小等与边栏宽度大小*/
}
#col1,#col2 {
min-height: 200px;
height: auto !important;
height: 200px;
}
查看在线DEMO。
方法五:
HTML Markup
<div id="container1">
<div id="container">
<div id="left">Left Sidebar</div>
<div id="content">
<div id="contentInner">Main Content</div>
</div>
</div>
</div>
CSS Code
*{padding: 0;margin: 0;}
#container1 {
float: left;
width: 100%;
overflow: hidden;
position: relative;
#dbddbb;
}
#container {
orange;
width: 100%;
float: left;
position: relative;
left: 220px;/* 宽度大小等与边栏宽度大小*/
}
#left {
float: left;
margin-right: -100%;
margin-left: -220px;/* 宽度大小等与边栏宽度大小*/
width: 220px;
}
#content {
float: left;
width: 100%;
margin-left: -220px;/* 宽度大小等与边栏宽度大小*/
}
#contentInner {
margin-left: 220px;/* 宽度大小等与边栏宽度大小*/
overflow: hidden;
}
#left,
#content {
min-height: 200px;
height: auto !important;
height: 200px;
}
查看在线DEMO。
针对上面的面试题要求,我一共使用了五种不同的方法来实现,经过测试都能在各浏览器中运行,最后我有几点需要特别提出:
上面所有DEMO中,要注意其方向性的配合,并且值要统一,如果您想尝试使用自己布局需要的宽度值,请对照相关代码环节进行修改;
上面所有DEMO中,没有设置他们之间的间距,如果您想让他们之间有一定的间距,有两种方法可能实现,其一在上面的DEMO基础上修改相关参数,其二,在相应的里面加上"div"标签,并设置其“padding”值,这样更安全,不至于打破你的布局
因为我们这里有一列使用了自适应宽度,在部分浏览器下,当浏览器屏幕拉至到一定的大小时,给我们带来的感觉是自适应宽度那栏内容像是被隐藏,在你的实际项目中最好能在“body”中加上一个“min-width”的设置。
- (兼容所有浏览器)
-
CSS3用过哪些新特性
-
写过 CSS 的人应该对 CSS 选择器不陌生,我们所定义的 CSS 属性之所以能应用到相应的节点上,就是因为 CSS 选择器模式。参考下述代码:
清单 1. CSS 选择器案例
12345Body > .mainTabContainer div > span[5]{Border: 1px solod red;Background-color: white;Cursor: pointer;}此处的 CSS 选择器即:“body > .mainTabContainer div span[5]” 代表这这样一条路径:
1. “body”标签直接子元素里 class 属性值为“mainTabContainer”的所有元素 A
2. A 的后代元素(descendant)里标签为 div 的所有元素 B
3. B 的直接子元素中的第 5 个标签为 span 的元素 C
这个 C 元素(可能为多个)即为选择器定位到的元素,如上的 CSS 属性也会全部应用到 C 元素上。
以上为 CSS2 及之前版本所提供的主要定位方式。现在,CSS3 提供了更多更加方便快捷的选择器:
清单 2. CSS3 选择器案例
12345678910111213141516Body > .mainTabContainer tbody:nth-child(even){Background-color: white;}Body > .mainTabContainer tr:nth-child(odd){Background-color: black;}:not(.textinput){Font-size: 12px;}Div:first-child{Border-color: red;}如上所示,我们列举了一些 CSS3 的选择器,在我们日常的开发中可能会经常用到,这些新的 CSS3 特性解决了很多我们之前需要用 JavaScript 脚本才能解决的问题。
tbody: nth-child(even), nth-child(odd):此处他们分别代表了表格(tbody)下面的偶数行和奇数行(tr),这种样式非常适用于表格,让人能非常清楚的看到表格的行与行之间的差别,让用户易于浏览。
: not(.textinput):这里即表示所有 class 不是“textinput”的节点。
div:first-child:这里表示所有 div 节点下面的第一个直接子节点。
除此之外,还有很多新添加的选择器:
12345678910111213E:nth-last-child(n)E:nth-of-type(n)E:nth-last-of-type(n)E:last-childE:first-of-typeE:only-childE:only-of-typeE:emptyE:checkedE:enabledE:disabledE::selectionE:not(s)这里不一一介绍。学会利用这些新特性可以极大程度的减少我们的无畏代码,并且大幅度的提高程序的性能。
@Font-face 特性
Font-face 可以用来加载字体样式,而且它还能够加载服务器端的字体文件,让客户端显示客户端所没有安装的字体。
先来看一个客户端字体简单的案例:
清单 3. Font-face 客户端字体案例
1<p><fontface="arial">arial courier verdana</font></p>我们可以通过这种方式直接加载字体样式,因为这些字体(arial)已经安装在客户端了。清单 3 这种写法的作用等同于清单 4:
清单 4. 字体基本写法
1<p><fontstyle="font-family: arial">arial courier verdana</font></p>相信这种写法大家应该再熟悉不过了。
接下来我们看看如何使用服务端字体,即:未在客户端安装的字体样式。
参看如下代码:
清单 5. Font-face 服务端字体案例
1234567891011@font-face {font-family: BorderWeb;src:url(BORDERW0.eot);}@font-face {font-family: Runic;src:url(RUNICMT0.eot);}.border { FONT-SIZE: 35px; COLOR: black; FONT-FAMILY: "BorderWeb" }.event { FONT-SIZE: 110px; COLOR: black; FONT-FAMILY: "Runic" }清单 5 中声明的两个服务端字体,其字体源指向“BORDERW0.eot”和“RUNICMT0.eot”文件,并分别冠以“BorderWeb”和“Runic”的字体名称。声明之后,我们就可以在页面中使用了:“ FONT-FAMILY: "BorderWeb" ” 和 “ FONT-FAMILY: "Runic" ”。
这种做法使得我们在开发中如果需要使用一些特殊字体,而又不确定客户端是否已安装时,便可以使用这种方式。
Word-wrap & Text-overflow 样式
Word-wrap
先来看看 word-wrap 属性,参考下述代码:
清单 6. word-wrap 案例
12345678<divstyle="width:300px; border:1px solid #999999; overflow: hidden">wordwrapbreakwordwordwrapbreakwordwordwrapbreakwordwordwrapbreakword</div><divstyle="width:300px; border:1px solid #999999; word-wrap:break-word;">wordwrapbreakwordwordwrapbreakwordwordwrapbreakwordwordwrapbreakword</div>比较上述两段代码,加入了“word-wrap: break-word”,设置或检索当当前行超过指定容器的边界时是否断开转行,文字此时已被打散。所以可见如下的差别:
图 1. 没有 break-word
![图 1. 没有 break-word]()
图 2. 有 break-word
![图 2. 有 break-word]()
Text-overflow
知道了 word-wrap 的原理,我们再来看看 text-overflow,其实它与 word-wrap 是协同工作的,word-wrap 设置或检索当当前行超过指定容器的边界时是否断开转行,而 text-overflow 则设置或检索当当前行超过指定容器的边界时如何显示,见如下示例:
清单 7. Text-overflow 案例
123456789101112.clip{text-overflow:clip; overflow:hidden; white-space:nowrap;width:200px;background:#ccc;}.ellipsis{text-overflow:ellipsis; overflow:hidden; white-space:nowrap;width:200px; background:#ccc;}<divclass="clip">不显示省略标记,而是简单的裁切条</div><divclass="ellipsis">当对象内文本溢出时显示省略标记</div>如清单 7 所示,这里我们均使用“overflow: hidden”,对于“text-overflow”属性,有“clip”和“ellipsis”两种可供选择。见图 3 的效果图。
图 3. Text-overflow 效果图
![图 3. Text-overflow 效果图]()
这里我们可以看到,ellipsis 的显示方式比较人性化,clip 方式比较传统,我们可以依据需求进行选择。
文字渲染(Text-decoration)
CSS3 里面开始支持对文字的更深层次的渲染,我们来看看下面的例子:
清单 8. Text-decoration 案例
12345div {-webkit-text-fill-color: black;-webkit-text-stroke-color: red;-webkit-text-stroke-width: 2.75px;}这里我们主要以 webkit 内核浏览器为例,清单 8 的代码效果如图 4:
图 4. Text-decoration 效果图
![图 4. Text-decoration 效果图]()
Text-fill-color: 文字内部填充颜色
Text-stroke-color: 文字边界填充颜色
Text-stroke-width: 文字边界宽度
CSS3 的多列布局(multi-column layout)
CSS3 现在已经可以做简单的布局处理了,这个 CSS3 新特性又一次的减少了我们的 JavaScript 代码量,参考如下代码:
清单 9. CSS3 多列布局
12345678910.multi_column_style{-webkit-column-count: 3;-webkit-column-rule: 1px solid #bbb;-webkit-column-gap: 2em;}<divclass="multi_column_style">..................................</div>这里我们还是以 webkit 内核浏览器为例:
Column-count:表示布局几列。
Column-rule:表示列与列之间的间隔条的样式
Column-gap:表示列于列之间的间隔
清单 9 的代码效果图如图 5:
图 5. 多列布局效果图
![图 5. 多列布局效果图]()
边框和颜色(color, border)
关于颜色,CSS3 已经提供透明度的支持了:
清单 10. 颜色的透明度
12color: rgba(255, 0, 0, 0.75);background: rgba(0, 0, 255, 0.75);这里的“rgba”属性中的“a”代表透明度,也就是这里的“0.75”,同时 CSS3 还支持 HSL 颜色声明方式及其透明度:
清单 11. HSL 的透明度
1color: hsla( 112, 72%, 33%, 0.68);对于 border,CSS3 提供了圆角的支持:
清单 12. 圆角案例
1border-radius: 15px;参见下面圆角效果:
Figure xxx. Requires a heading
![Figure xxx. Requires a heading]()
CSS3 的渐变效果(Gradient)
线性渐变
左上(0% 0%)到右上(0% 100%)即从左到右水平渐变:
清单 13. 左到右的渐变
1background-image:-webkit-gradient(linear,0% 0%,100% 0%,from(#2A8BBE),to(#FE280E));这里 linear 表示线性渐变,从左到右,由蓝色(#2A8BBE)到红色(#FE280E)的渐变。效果图如下:
图 6. 简单线性渐变效果图
![图 6. 简单线性渐变效果图]()
同理,也可以有从上到下,任何颜色间的渐变转换:
图 7. 各种不同线性渐变效果图
![图 7. 各种不同线性渐变效果图]()
还有复杂一点的渐变,如:水平渐变,33% 处为绿色,66% 处为橙色:
清单 14. 复杂线性渐变
12background-image:-webkit-gradient(linear,0% 0%,100% 0%,from(#2A8BBE),color-stop(0.33,#AAD010),color-stop(0.33,#FF7F00),to(#FE280E));这里的“color-stop”为拐点,可见效果图:
图 8. 复杂线性渐变效果图
![图 8. 复杂线性渐变效果图]()
径向渐变
接下来我们要介绍径向渐变(radial),这不是从一个点到一个点的渐变,而从一个圆到一个圆的渐变。不是放射渐变而是径向渐变。来看一个例子:
清单 15. 径向渐变(目标圆半径为 0)
12backgroud:-webkit-gradient(radial,50 50,50,50 50,0,from(black),color-stop(0.5,red),to(blue));前面“50,50,50”是起始圆的圆心坐标和半径,“50,50,0”蓝色是目标圆的圆心坐标和半径,“color-stop(0.5,red)”是断点的位置和色彩。这里需要说明一下,和放射由内至外不一样,径向渐变刚好相反,是由外到内的渐变。清单 15 标识的是两个同心圆,外圆半径为 50px,内圆半径为 0,那么就是从黑色到红色再到蓝色的正圆形渐变。下面就是这段代码的效果:
图 9. 径向渐变(目标圆半径为 0)效果图
![图 9. 径向渐变(目标圆半径为 0)效果图]()
如果我们给目标源一个大于 0 半径,您会看到另外一个效果:
清单 16. 径向渐变(目标圆半径非 0)
12backgroud:-webkit-gradient(radial,50 50,50,50 50,10,from(black),color-stop(0.5,red),to(blue));这里我们给目标圆半径为 10,效果图如下:
图 10. 径向渐变(目标圆半径非 0)
![图 10. 径向渐变(目标圆半径非 0)]()
您可以看到,会有一个半径为 10 的纯蓝的圆在最中间,这就是设置目标圆半径的效果。
现在我再改变一下,不再是同心圆了,内圆圆心向右 20px 偏移。
清单 17. 径向渐变(目标圆圆心偏移)
12backgroud:-webkit-gradient(radial,50 50,50,70 50,10,from(black),color-stop(0.5,red),to(blue));这里我们给目标圆半径还是 10,但是圆心偏移为“70,50”(起始圆圆心为“50,50”)效果图如下:
图 11. 径向渐变(目标圆圆心偏移)
![图 11. 径向渐变(目标圆圆心偏移)]()
想必您明白原理了,我们可以做一个来自顶部的漫射光,类似于开了盏灯:
清单 18. 径向渐变(漫射光)
1backgroud:-webkit-gradient(radial,50 50,50,50 1,0,from(black),to(white));其效果如下:
图 12. 径向渐变(漫射光)
![图 12. 径向渐变(漫射光)]()
CSS3 的阴影(Shadow)和反射(Reflect)效果
首先来说说阴影效果,阴影效果既可用于普通元素,也可用于文字,参考如下代码:
清单 19. 元素和文字的阴影
1234567.class1{text-shadow:5px 2px 6px rgba(64, 64, 64, 0.5);}.class2{box-shadow:3px 3px 3px rgba(0, 64, 128, 0.3);}设置很简单,对于文字阴影:表示 X 轴方向阴影向右 5px,Y 轴方向阴影向下 2px, 而阴影模糊半径 6px,颜色为 rgba(64, 64, 64, 0.5)。其中偏移量可以为负值,负值则反方向。元素阴影也类似。参考一下效果图:
图 13. 元素和文字的阴影效果图
![元素和文字的阴影效果图]()
![图 13. 元素和文字的阴影效果图]()
接下来我们再来谈谈反射,他看起来像水中的倒影,其设置也很简单,参考如下代码:
清单 20. 反射
12345.classReflect{-webkit-box-reflect: below 10px-webkit-gradient(linear, left top, left bottom, from(transparent),to(rgba(255, 255, 255, 0.51)));}设置也很简单,大家主要关注“-webkit-box-reflect: below 10px”,他表示反射在元素下方 10px 的地方,再配上渐变效果,可见效果图如下:
图 14. 反射效果图
![图 14. 反射效果图]()
CSS3 的背景效果
CSS3 多出了几种关于背景(background)的属性,我们这里会简单介绍一下:
首先:“Background Clip”,该属确定背景画区,有以下几种可能的属性:
* background-clip: border-box; 背景从 border 开始显示 ;
* background-clip: padding-box; 背景从 padding 开始显示 ;
* background-clip: content-box; 背景显 content 区域开始显示 ;
* background-clip: no-clip; 默认属性,等同于 border-box;
通常情况,我们的背景都是覆盖整个元素的,现在 CSS3 让您可以设置是否一定要这样做。这里您可以设定背景颜色或图片的覆盖范围。
其次:“Background Origin”,用于确定背景的位置,它通常与 background-position 联合使用,您可以从 border、padding、content 来计算 background-position(就像 background-clip)。
* background-origin: border-box; 从 border. 开始计算 background-position;
* background-origin: padding-box; 从 padding. 开始计算 background-position;
* background-origin: content-box; 从 content. 开始计算 background-position;
还有,“Background Size”,常用来调整背景图片的大小,注意别和 clip 弄混,这个主要用于设定图片本身。有以下可能的属性:
* background-size: contain; 缩小图片以适合元素(维持像素长宽比)
* background-size: cover; 扩展元素以填补元素(维持像素长宽比)
* background-size: 100px 100px; 缩小图片至指定的大小 .
* background-size: 50% 100%; 缩小图片至指定的大小,百分比是相对包 含元素的尺寸 .
最后,“Background Break”属性,CSS3 中,元素可以被分成几个独立的盒子(如使内联元素 span 跨越多行),background-break 属性用来控制背景怎样在这些不同的盒子中显示。
* background-break: continuous; 默认值。忽略盒之间的距离(也就是像元 素没有分成多个盒子,依然是一个整体一 样)
* background-break: bounding-box; 把盒之间的距离计算在内;
* background-break: each-box; 为每个盒子单独重绘背景。
这种属性让您可以设定复杂元素的背景属性。
最为重要的一点,CSS3 中支持多背景图片,参考如下代码:
清单 21. 多背景图片
1234div {background: url(src/zippy-plus.png) 10px center no-repeat,url(src/gray_lines_bg.png) 10px center repeat-x;}此为同一元素两个背景的案例,其中一个重复显示,一个不重复。参考一下效果图:
图 15. 多背景图片
![图 15. 多背景图片]()
CSS3 的盒子模型
盒子模型为开发者提供了一种非常灵活的布局方式,但是支持这一特性的浏览器并不多,目前只有 webkit 内核的新版本 safari 和 chrome 以及 gecko 内核的新版本 firefox。
下面我们来介绍一下他是如何工作的,参考如下代码:
清单 22. CSS3 盒子模型
1234567891011121314<divclass="boxcontainer"><divclass="item">1</div><divclass="item">2</div><divclass="item">3</div><divclass="item flex">4</div></div>默认情况下,如果“boxcontainer”和“item”两个 class 里面没有特殊属性的话,由于 div 是块状元素,所以他的排列应该是这样的:
图 16. CSS3 盒子模型效果图
![图 16. CSS3 盒子模型效果图]()
下面,我们加入相关 CSS3 盒子模型属性:
清单 23. CSS3 盒子模型(水平排列)
12345678910111213141516.boxcontainer {width: 1000px;display: -webkit-box;display: -moz-box;-webkit-box-orient: horizontal;-moz-box-orient: horizontal;}.item {background: #357c96;font-weight: bold;margin: 2px;padding: 20px;color: #fff;font-family: Arial, sans-serif;}注意这里的“display: -webkit-box; display: -moz-box;”,它针对 webkit 和 gecko 浏览器定义了该元素的盒子模型。注意这里的“-webkit-box-orient: horizontal;”,他表示水平排列的盒子模型。此时,我们会看到如下效果:
图 17. CSS3 盒子模型(水平排列)效果图
![图 17. CSS3 盒子模型(水平排列)效果图]()
细心的读者会看到,“盒子”的右侧多出来了很大一块,这是怎么回事呢?让我们再来看一个比较有特点的属性:“flex”, 参考如下代码:
清单 24. CSS3 盒子模型(flex)
12345678910111213141516171819<divclass="boxcontainer"><divclass="item">1</div><divclass="item">2</div><divclass="item">3</div><divclass="item flex">4</div></div>.flex {-webkit-box-flex: 1;-moz-box-flex: 1;}您看到什么区别了没?在第四个“item 元素”那里多了一个“flex”属性,直接来看看效果吧:
图 18. CSS3 盒子模型(flex)效果图
![图 18. CSS3 盒子模型(flex)效果图]()
第四个“item 元素”填满了整个区域,这就是“flex”属性的作用。如果我们调整一下“box-flex”的属性值,并加入更多的元素,见如下代码:
清单 25. CSS3 盒子模型(flex 进阶)
123456789101112131415161718192021222324<divclass="boxcontainer"><divclass="item">1</div><divclass="item">2</div><divclass="item flex2">3</div><divclass="item flex">4</div></div>.flex {-webkit-box-flex: 1;-moz-box-flex: 1;}.flex2 {-webkit-box-flex: 2;-moz-box-flex: 2;}我们把倒数第二个元素(元素 3)也加上“box-flex”属性,并将其值设为 2,可见其效果图如下:
图 19. CSS3 盒子模型(flex 进阶)效果图
![图 19. CSS3 盒子模型(flex 进阶)效果图]()
由此可见,元素 3 和元素 4 按比例“2:1”的方式填充外层“容器”的余下区域,这就是“box-flex”属性的进阶应用。
还有,“box-direction”可以用来翻转这四个盒子的排序,“box-ordinal-group”可以用来改变每个盒子的位置:一个盒子的 box-ordinal-group 属性值越高,就排在越后面。盒子的对方方式可以用“box-align”和“box-pack”来设定。
CSS3 的 Transitions, Transforms 和 Animation
Transitions
先说说 Transition,Transition 有下面些具体属性:
transition-property:用于指定过渡的性质,比如 transition-property:backgrond 就是指 backgound 参与这个过渡
transition-duration:用于指定这个过渡的持续时间
transition-delay:用于制定延迟过渡的时间
transition-timing-function:用于指定过渡类型,有 ease | linear | ease-in | ease-out | ease-in-out | cubic-bezier
可能您觉得摸不着头脑,其实很简单,我们用一个例子说明,参看一下如下代码:
清单 26. CSS3 的 Transition
123456789101112<divid="transDiv"class="transStart"> transition </div>.transStart {background-color: white;-webkit-transition: background-color 0.3s linear;-moz-transition: background-color 0.3s linear;-o-transition: background-color 0.3s linear;transition: background-color 0.3s linear;}.transEnd {background-color: red;}这里他说明的是,这里 id 为“transDiv”的 div,当它的初始“background-color”属性变化时(被 JavaScript 修改),会呈现出一种变化效果,持续时间为 0.3 秒,效果为均匀变换(linear)。如:该 div 的 class 属性由“transStart”改为“transEnd”,其背景会由白(white)渐变到红(red)。
Transform
再来看看 Transform,其实就是指拉伸,压缩,旋转,偏移等等一些图形学里面的基本变换。见如下代码:
清单 27. CSS3 的 Transform
12345678910111213141516171819.skew {-webkit-transform: skew(50deg);}.scale {-webkit-transform: scale(2, 0.5);}.rotate {-webkit-transform: rotate(30deg);}.translate {-webkit-transform: translate(50px, 50px);}.all_in_one_transform {-webkit-transform: skew(20deg) scale(1.1, 1.1) rotate(40deg) translate(10px, 15px);}“skew”是倾斜,“scale”是缩放,“rotate”是旋转,“translate”是平移。最后需要说明一点,transform 支持综合变换。可见其效果图如下:
图 20. CSS3 的 Transform 效果图
![图 20. CSS3 的 Transform 效果图]()
现在您应该明白 Transform 的作用了吧。结合我们之前谈到的 Transition,将它们两者结合起来,会产生类似旋转,缩放等等的效果,绝对能令人耳目一新。
Animation
最后,我们来说说 Animation 吧。它可以说开辟了 CSS 的新纪元,让 CSS 脱离了“静止”这一约定俗成的前提。以 webkit 为例,见如下代码:
清单 28. CSS3 的 Animation
1234567891011121314151617@-webkit-keyframes anim1 {0% {Opacity: 0;Font-size: 12px;}100% {Opacity: 1;Font-size: 24px;}}.anim1Div {-webkit-animation-name: anim1 ;-webkit-animation-duration: 1.5s;-webkit-animation-iteration-count: 4;-webkit-animation-direction: alternate;-webkit-animation-timing-function: ease-in-out;}首先,定义动画的内容,如清单 28 所示,定义动画“anim1”,变化方式为由“透明”(opacity: 0)变到“不透明”(opacity: 1),同时,内部字体大小由“12px”变到“24px”。然后,再来定义 animation 的变化参数,其中,“duration”表示动画持续时间,“iteration-count”表示动画重复次数,direction 表示动画执行完一次后方向的变化方式(如第一次从右向左,第二次则从左向右),最后,“timing-function”表示变化的模式。
其实,CSS3 动画几乎支持所有的 style 变化,可以定义各种各样的动画效果以满足我们用户体验的需要。
这里,我们介绍了 CSS3 的主要的新特性,这些特性在 Chrome 和 Safari 中基本都是支持的,Firefox 支持其中的一部分,IE 和 Opera 支持的较少。读者们可以根据集体情况有选择的使用。
-
-
BFC、IFC
- 先说说FC,FC的含义就是Fomatting Context。它是CSS2.1规范中的一个概念。它是页面中的一块渲染区域,并且有一套渲染规则,它决定了其子元素将如何定位,以及和其他元素的关系和相互作用。BFC和IFC都是常见的FC。分别叫做Block Fomatting Context 和Inline Formatting Context。
-
一、BFC是什么?
BFC(Block Formatting Context)直译为“块级格式化范围”。
是 W3C CSS 2.1 规范中的一个概念,它决定了元素如何对其内容进行定位,以及与其他元素的关系和相互作用。当涉及到可视化布局的时候,Block Formatting Context提供了一个环境,HTML元素在这个环境中按照一定规则进行布局。一个环境中的元素不会影响到其它环境中的布局。比如浮动元素会形成BFC,浮动元素内部子元素的主要受该浮动元素影响,两个浮动元素之间是互不影响的。这里有点类似一个BFC就是一个独立的行政单位的意思。也可以说BFC就是一个作用范围。可以把它理解成是一个独立的容器,并且这个容器的里box的布局,与这个容器外的毫不相干。
另一个通俗点的解释是:在普通流中的 Box(框) 属于一种 formatting context(格式化上下文) ,类型可以是 block ,或者是 inline ,但不能同时属于这两者。并且, Block boxes(块框) 在 block formatting context(块格式化上下文) 里格式化, Inline boxes(块内框) 则在 inline formatting context(行内格式化上下文) 里格式化。任何被渲染的元素都属于一个 box ,并且不是 block ,就是 inline 。即使是未被任何元素包裹的文本,根据不同的情况,也会属于匿名的 block boxes 或者 inline boxes。所以上面的描述,即是把所有的元素划分到对应的 formatting context 里。
其一般表现规则,我整理了以下这几个情况:
1、在创建了 Block Formatting Context 的元素中,其子元素按文档流一个接一个地放置。垂直方向上他们的起点是一个包含块的顶部,两个相邻的元素之间的垂直距离取决于 ‘margin’ 特性。
根据 CSS 2.1 8.3.1 Collapsing margins 第一条,两个相邻的普通流中的块框在垂直位置的空白边会发生折叠现象。也就是处于同一个BFC中的两个垂直窗口的margin会重叠。
根据 CSS 2.1 8.3.1 Collapsing margins 第三条,生成 block formatting context 的元素不会和在流中的子元素发生空白边折叠。所以解决这种问题的办法是要为两个容器添加具有BFC的包裹容器。
2、在 Block Formatting Context 中,每一个元素左外边与包含块的左边相接触(对于从右到左的格式化,右外边接触右边), 即使存在浮动也是如此(尽管一个元素的内容区域会由于浮动而压缩),除非这个元素也创建了一个新的 Block Formatting Context 。
3、Block Formatting Context就是页面上的一个隔离的独立容器,容器里面的子元素不会在布局上影响到外面的元素,反之也是如此。
4、根据 CSS 2.1 9.5 Floats 中的描述,创建了 Block Formatting Context 的元素不能与浮动元素重叠。
表格的 border-box、块级的替换元素、或是在普通流中创建了新的 block formatting context(如元素的 'overflow' 特性不为 'visible' 时)的元素不可以与位于相同的 block formatting context 中的浮动元素相重叠。
5 、当容器有足够的剩余空间容纳 BFC 的宽度时,所有浏览器都会将 BFC 放置在浮动元素所在行的剩余空间内。
6、 在 IE6 IE7 IE8 Chrome Opera 中,当 BFC 的宽度介于 "容器剩余宽度" 与 "容器宽度" 之间时,BFC 会显示在浮动元素的下一行;在 Safari 中,BFC 则仍然保持显示在浮动元素所在行,并且 BFC 溢出容器;在 Firefox 中,当容器本身也创建了 BFC 或者容器的 'padding-top'、'border-top-width' 这些特性不都为 0 时表现与 IE8(S)、Chrome 类似,否则表现与 Safari 类似。
经验证,最新版本的浏览中只有firefox会在同一行显示,其它浏览器均换行。
7、 在 IE6 IE7 IE8 Opera 中,当 BFC 的宽度大于 "容器宽度" 时,BFC 会显示在浮动元素的下一行;在 Chrome Safari 中,BFC 则仍然保持显示在浮动元素所在行,并且 BFC 溢出容器;在 Firefox 中,当容器本身也创建了 BFC 或者容器的 'padding- top'、'border-top-width' 这些特性不都为 0 时表现与 IE8(S) 类似,否则表现与 Chrome 类似。
经验证,最新版本的浏览中只有firefox会在同一行显示,其它浏览器均换行。
8、根据CSS2.1 规范第10.6.7部分的高度计算规则,在计算生成了 block formatting context 的元素的高度时,其浮动子元素应该参与计算。
如果还有其它情况,请各位回得中补充,我会及时更新!
下面先看一个比较典型的例子:

DOCTYPE HTML> <</span>html> <</span>head> <</span>meta http-equiv="Content-Type" content="text/html; charset=gb2312"> <</span>title>无标题文档</</span>title> <</span>style> * { padding:0; margin:0; } #red, #yellow, #orange, #green { width:100px; height:100px; float:left; } #red { background-color:red; } #yellow { background-color:yellow; } #orange { background-color:orange; } #green { background-color:green; } </</span>style> </</span>head> <</span>body> <</span>div id="c1"> <</span>div id="red"> </</span>div> <</span>div id="yellow"> </</span>div> </</span>div> <</span>div id="c2"> <</span>div id="orange"> </</span>div> <</span>div id="green"> </</span>div> </</span>div> <</span>p>Here is the text!</</span>p> </</span>body> </</span>html>
效果如下:

该段代码本意要形成两行两列的布局,但是由于#red,#yellow,#orange,#green四个div在同一个布局环境BFC中,因此虽然它们位于两个不同的div(#c1和#c2)中,但仍然不会换行,而是一行四列的排列。
若要使之形成两行两列的布局,就要创建两个不同的布局环境,也可以说要创建两个BFC。那到底怎么创建BFC呢?
二、如何产生BFC:当一个HTML元素满足下面条件的任何一点,都可以产生Block Formatting Context:
- float的值不为none。
- overflow的值不为visible。
- display的值为table-cell, table-caption, inline-block中的任何一个。
- position的值不为relative和static。
如果还其它方式,请在回复中给出,我会及时更新!!
上面的例子,我再加两行代码,创建两个BFC:
#c1{overflow:hidden;} #c2{overflow:hidden;}效果如下:

上面创建了两个布局环境BFC。内部子元素的左浮动不会影响到外部元素。所以#c1和#c2没有受浮动的影响,仍然各自占据一行!
三、BFC能用来做什么?
a、不和浮动元素重叠
如果一个浮动元素后面跟着一个非浮动的元素,那么就会产生一个覆盖的现象,很多自适应的两栏布局就是这么做的。
看下面一个例子

DOCTYPE HTML> <</span>html> <</span>head> <</span>meta http-equiv="Content-Type" content="text/html; charset=gb2312"> <</span>title>无标题文档</</span>title> <</span>style> html,body {height:100%; } * { padding:0; margin:0; color:#fff; text-decoration:none; list-style:none; font-family:"微软雅黑" } .aside{background:#f00;width:170px;float:left;height:300px;} .main{background:#090;height:100%;} </</span>style> </</span>head> <</span>body> <</span>div class="aside"> </</span>div> <</span>div class="main"> </</span>div> </</span>body> </</span>html>
效果图如下:

很明显,.aside和.mian重叠了。试分析一下,由于两个box都处在同一个BFC中,都是以BFC边界为起点,如果两个box本身都具备BFC的话,会按顺序一个一个排列布局,现在.main并不具备BFC,按照规则2,内部元素都会从左边界开始,除非它本身具备BFC,按上面规则4拥有BFC的元素是不可以跟浮动元素重叠的,所以只要为.mian再创建一个BFC,就可以解决这个重叠的问题。上面已经说过创建BFC的方法,可以根据具体情况选用不同的方法,这里我选用的是加overflow:hidden。
由于ie的原因需要再加一个解发haslayout的zoom:1,有关haslayout后面会讲到。
b、清除元素内部浮动
只要把父元素设为BFC就可以清理子元素的浮动了,最常见的用法就是在父元素上设置overflow: hidden样式,对于IE6加上zoom:1就可以了(IE Haslayout)。
看下面例子:

DOCTYPE HTML> <</span>html> <</span>head> <</span>meta http-equiv="Content-Type" content="text/html; charset=gb2312"> <</span>title>无标题文档</</span>title> <</span>style> html,body {height:100%; } * { padding:10px; margin:0; color:#000; text-decoration:none; list-style:none; font-family:"微软雅黑" } .outer{width:300px;border:1px solid #666;padding:10px;} .innerLeft{height:100px;width:100px;float:left;background:#f00;} .innerRight{height:100px;width:100px;float:right;background:#090;} </</span>style> </</span>head> <</span>body> <</span>div class="outer"> <</span>div class="innerLeft"></</span>div> <</span>div class="innerRight"></</span>div> </</span>div> </</span>div> </</span>body> </</span>html>
效果图如下:

根据 CSS2.1 规范第 10.6.3 部分的高度计算规则,在进行普通流中的块级非替换元素的高度计算时,浮动子元素不参与计算。
同时 CSS2.1 规范第10.6.7部分的高度计算规则,在计算生成了 block formatting context 的元素的高度时,其浮动子元素应该参与计算。
所以,触发外部容器BFC,高度将重新计算。比如给outer加上属性overflow:hidden触发其BFC。
c、解决上下相邻两个元素重叠
看下面例子:

DOCTYPE HTML> <</span>html> <</span>head> <</span>meta http-equiv="Content-Type" content="text/html; charset=gb2312"> <</span>title>无标题文档</</span>title> <</span>style> html,body {height:100%; } * { padding:0; margin:0; color:#fff; text-decoration:none; list-style:none; font-family:"微软雅黑" } .rowone{background:#f00;height:100px;margin-bottom:20px;overflow:hidden;} .rowtow{background:#090;height:100px;margin-top:20px;position:relative} </</span>style> </</span>head> <</span>body> <</span>div class="rowone"> </</span>div> <</span>div class="rowtow"> </</span>div> </</span>body> </</span>html>
效果如下:

根据 CSS 2.1 8.3.1 Collapsing margins 第一条,两个相邻的普通流中的块框在垂直位置的空白边会发生折叠现象。也就是处于同一个BFC中的两个垂直窗口的margin会重叠。
根据 CSS 2.1 8.3.1 Collapsing margins 第三条,生成 block formatting context 的元素不会和在流中的子元素发生空白边折叠。所以解决这种问题的办法是要为两个容器添加具有BFC的包裹容器。
所以解这个问题的办法就是,把两个容器分别放在两个据有BFC的包裹容器中,IE里就是触发layout的两个包裹容器中!

DOCTYPE HTML> <</span>html> <</span>head> <</span>meta http-equiv="Content-Type" content="text/html; charset=gb2312"> <</span>title>无标题文档</</span>title> <</span>style> html, body { height:100%; } * { padding:0; margin:0; color:#fff; text-decoration:none; list-style:none; font-family:"微软雅黑" } .mg {overflow:hidden; } .rowone { background:#f00; height:100px; margin-bottom:20px; } .rowtow { background:#090; height:100px; margin-top:20px; } </</span>style> </</span>head> <</span>body> <</span>div class="mg"> <</span>div class="rowone"> </</span>div> </</span>div> <</span>div class="mg"> <</span>div class="rowtow"> </</span>div> </</span>div> </</span>body> </</span>html>
效果如下:

四、什么是IE的haslayout
上面的例子中我们用到了IE的zoom:1;实际上是触发了IE的layout。Layout 是 IE 浏览器渲染引擎的一个内部组成部分。在 IE 浏览器中,一个元素要么自己对自身的内容进行组织和计算大小, 要么依赖于包含块来计算尺寸和组织内容。为了协调这两种方式的矛盾,渲染引擎采用了 ‘hasLayout’ 属性,属性值可以为 true 或 false。 当一个元素的 ‘hasLayout’ 属性值为 true 时,我们说这个元素有一个布局(layout),或拥有布局。可以通过 hasLayout 属性来判断一个元素是否拥有 layout ,
如 object.currentStyle.hasLayout 。
hasLayout 与 BFC 有很多相似之处,但 hasLayout 的概念会更容易理解。在 Internet Explorer 中,元素使用“布局”概念来控制尺寸和定位,分为拥有布局和没有布局两种情况,拥有布局的元素由它控制本身及其子元素的尺寸和定位,而没有布局的元素则通过父元素(最近的拥有布局的祖先元素)来控制尺寸和定位,而一个元素是否拥有布局则由 hasLayout 属性告知浏览器,它是个布尔型变量,true 代表元素拥有布局,false 代表元素没有布局。简而言之,hasLayout 只是一个 IE 下专有的属性,hasLayout 为 true 的元素浏览器会赋予它一系列的效果。
特别注意的是,hasLayout 在 IE 8 及之后的 IE 版本中已经被抛弃,所以在实际开发中只需针对 IE 8 以下的浏览器为某些元素触发 hasLayout。
五、怎样触发layout
一个元素触发 hasLayout 会影响一个元素的尺寸和定位,这样会消耗更多的系统资源,因此 IE 设计者默认只为一部分的元素触发 hasLayout (即默认有部分元素会触发 hasLayout ,这与 BFC 基本完全由开发者通过特定 CSS 触发并不一样),这部分元素如下:

<</span>html>, <</span>body> <</span>table>, <</span>tr>, <</span>th>, <</span>td> <</span>img> <</span>hr> <</span>input>, <</span>button>, <</span>select>, <</span>textarea>, <</span>fieldset>, <</span>legend> <</span>iframe>, <</span>embed>, <</span>object>, <</span>applet> <</span>marquee>

除了 IE 默认会触发 hasLayout 的元素外,Web 开发者还可以使用特定的 CSS 触发元素的 hasLayout 。
通过为元素设置以下任一 CSS ,可以触发 hasLayout (即把元素的 hasLayout 属性设置为 true)。

display: inline-block height: (除 auto 外任何值) width: (除 auto 外任何值) float: (left 或 right) position: absolute writing-mode: tb-rl zoom: (除 normal 外任意值) min-height: (任意值) min-width: (任意值) max-height: (除 none 外任意值) max-width: (除 none 外任意值) overflow: (除 visible 外任意值,仅用于块级元素) overflow-x: (除 visible 外任意值,仅用于块级元素) overflow-y: (除 visible 外任意值,仅用于块级元素) position: fixed

对于内联元素(可以是默认被浏览器认为是内联元素的 span 元素,也可以是设置了 display: inline 的元素),width 和 height 只在 IE5.x 下和 IE6 或更新版本的 quirks 模式下能触发元素的 hasLayout ,但是对于 IE6,如果浏览器运行于标准兼容模式下,内联元素会忽略 width 或 height 属性,所以设置 width 或 height 不能在此种情况下令该元素触发 hasLayout 。但 zoom 除了在 IE 5.0 中外,总是能触发 hasLayout 。zoom 用于设置或检索元素的缩放比例,为元素设置 zoom: 1 既可以触发元素的 hasLayout 同时不会对元素造成多余的影响。因此综合考虑浏览器之间的兼容和对元素的影响, 建议使用 zoom: 1 来触发元素的 hasLayout 。
六、能解决的问题
hasLayout表现出来的特性跟BFC很相似,所以可以认为是IE中的BFC。上面的规则几乎都遵循,所以上面的问题在IE里都可以通过触发hasLayout来解决。
虽然 hasLayout 也会像 BFC 那样影响着元素的尺寸和定位,但它却又不是一套完整的标准,并且由于它默认只为某些元素触发,这导致了 IE 下很多前端开发的 bugs ,触发 hasLayout 更大的意义在于解决一些 IE 下的 bugs ,而不是利用它的一些“副作用”来达到某些效果。另外由于触发 hasLayout 的元素会出现一些跟触发 BFC 的元素相似的效果,因此为了统一元素在 IE 与支持 BFC 的浏览器下的表现,Kayo 建议为触发了 BFC 的元素同时触发 hasLayout ,当然还需要考虑实际的情况,也有可能只需触发其中一个就可以达到表现统一,下面会举例介绍。
这里首先列出触发 hasLayout 元素的一些效果:
a、阻止外边距折叠
如上面例子:

DOCTYPE HTML> <</span>html> <</span>head> <</span>meta http-equiv="Content-Type" content="text/html; charset=gb2312"> <</span>title>无标题文档</</span>title> <</span>style> html, body { height:100%; } * { padding:0; margin:0; color:#fff; text-decoration:none; list-style:none; font-family:"微软雅黑" } .mg {zoom:1} .rowone { background:#f00; height:100px; margin-bottom:20px; } .rowtow { background:#090; height:100px; margin-top:20px; } </</span>style> </</span>head> <</span>body> <</span>div class="mg"> <</span>div class="rowone"> </</span>div> </</span>div> <</span>div class="mg"> <</span>div class="rowtow"> </</span>div> </</span>div> </</span>body> </</span>html>
需要触发.mg的layout才能解决margin重叠问题
运行效果如下:

-
对栅格的理解
- Bootstrap 栅格系统 学习总结
Bootstrap框架是如今最流行的前端框架之一,Bootstrap功能强大,简单易学,很符合实际应用场景。
只是Bootstrap的内容较多,新手往往不能很快的熟练运用Bootstrap。
这里,我就对Bootstrap中非常重要好用的栅格系统做一个以实例为向导的总结:
(1)第一步:创建栅格系统的容器
<div class="container-fluid"> <div class="row"> ... </div> </div>
解释:为了寄予栅格系统合适的排列和padding,要把每一行“row”包含在一个容器中,而这个容器我们用class名为“container”或者“container-fluid”,这两个class是Bootstrap为我们事先设计好的
.container是固定宽度,居中显示:下面是Bootstrap中.container类的代码![]()
.container-fluid是 100% 宽度:下面是Bootstrap中.container-fluid类的代码![]()
(2)第二步:创建合适的栅格系统<div class="row">
<div class="col-md-1">.col-md-1</div>
<div class="col-md-1">.col-md-1</div>
<div class="col-md-1">.col-md-1</div>
<div class="col-md-1">.col-md-1</div>
<div class="col-md-1">.col-md-1</div>
<div class="col-md-1">.col-md-1</div>
<div class="col-md-1">.col-md-1</div>
<div class="col-md-1">.col-md-1</div>
<div class="col-md-1">.col-md-1</div>
<div class="col-md-1">.col-md-1</div>
<div class="col-md-1">.col-md-1</div>
<div class="col-md-1">.col-md-1</div>
</div>
<div class="row">
<div class="col-md-8">.col-md-8</div>
<div class="col-md-4">.col-md-4</div>
</div>
<div class="row">
<div class="col-md-4">.col-md-4</div>
<div class="col-md-4">.col-md-4</div>
<div class="col-md-4">.col-md-4</div>
</div>
<div class="row">
<div class="col-md-6">.col-md-6</div>
<div class="col-md-6">.col-md-6</div>
</div>解释:上面这段是我从Bootstrap官网复制下来的,每一个“row”代表一行,而内部的“col-md-数字”代表一个单元格;
Bootstrap把每一行分成12等份,“col-md-数字”中的“数字”从1-12中取,数字等于几,就占几份;
合理的选择单元格的数字配置,再往单元格中添加我们想要的内容,这样一个栅格系统就完成了!
(3)进阶:单元格的类还有其他选择 ,一共有四种:
.c0l-xs- 无论屏幕宽度如何,单元格都在一行,宽度按照百分比设置;试用于手机;
.col-sm- 屏幕大于768px时,单元格在一行显示;屏幕小于768px时,独占一行;试用于平板;
.col-md- 屏幕大于992px时,单元格在一行显示;屏幕小于992px时,独占一行;试用于桌面显示器;
.col-lg- 屏幕大于1200px时,单元格在一行显示;屏幕小于1200px时,独占一行;适用于大型桌面显示器;
以上的情况可以通过下面的代码清晰的理解:
<div class="container">
<div class="row">
<div class="col-xs-12 col-sm-6 col-md-8">.col-xs-12 .col-sm-6 .col-md-8</div>
<div class="col-xs-6 col-md-4">.col-xs-6 .col-md-4</div>
</div>
<div class="row">
<div class="col-xs-6 col-sm-4">.col-xs-6 .col-sm-4</div>
<div class="col-xs-6 col-sm-4">.col-xs-6 .col-sm-4</div>
<div class="col-xs-6 col-sm-4">.col-xs-6 .col-sm-4</div>
</div>
</div>屏幕大于992px时:.col-md-8 和.col-md-4 还处于 作用范围内,如下
![]()
屏幕在769px-992px之间时:.col-md-已失效,而.col-sm- 还处在 作用范围内,如下
![]()
屏幕宽度小于768px时,.col-sm-已失效 只有.col-xs- 不受屏幕宽度影响,这时候就由.col-xs-起作用,如下
![]()
- Bootstrap 栅格系统 学习总结
-
(水平)居中有哪些实现方式
-
1.用inline-block和vertical-align来实现居中:这种方法适合于未知宽度高度的情况下。
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> <style> #container{ text-align: center; height: 400px; background: #4dc71f; } #container:before{ content: ""; height: 100%; display: inline-block; vertical-align: middle; margin-right: -0.25em; } #center-div{ display: inline-block; vertical-align: middle; background: #2aabd2; } </style> </head> <body> <div id="container"> <div id="center-div"> xxx </div> </div> </body> -
参考:https://css-tricks.com/centering-in-the-unknown/
2.用相对绝对定位和负边距实现上下左右居中:高度和宽度已知<!DOCTYPE html> <html lang="en"> <head> <meta charset="utf-8"> <title>test</title> <style> .div2{ height: 600px; width: 600px; position: relative; border: 2px solid #000; } .img2{ height: 200px; width: 200px; position: relative; top: 50%; left: 50%; margin: -100px 0 0 -100px; } </style> </head> <body> <div class="div2"> <img class="img2" src="images/hongbao.png"> </div> </body> </html> -
其实第二种要理解不能,首先相对父元素top,left定位在50%的位置,这时候只是图片左上角居中,而中心点还没居中,加上margin: -100px 0 0 -100px;利用负边距把图片的中心点位于父元素的中心点,从而实现垂直水平居中
3.利用绝对定位来实现居中:适合高度,宽度已知的情况。<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> <style> #container{ text-align: center; height: 400px; background: #4dc71f; position: relative; } #center-div{ position: absolute; margin: auto; top: 0; right: 0; left:0; bottom: 0; width: 200px; height: 200px; background: #2b669a; } </style> </head> <body> <div id="container"> <div id="center-div"> xxx </div> </div> </body> </html> -
4.使用table-cell,inline-block实现水平垂直居中:适合高度宽度未知的情况
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> <style> #container{ display: table-cell; text-align: center; vertical-align: middle; height: 300px; background: #ccc; } #center-div{ display: inline-block; } </style> </head> <body> <div id="container"> <div id="center-div"> xxx </div> </div> </body> </html> -
5.使用css3中的transform来时实现水平垂直居中:适合高度宽度未知的情况
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> <style> #container{ position: relative; height: 200px; background: #333; } #center-div{ position: absolute; top:50%; left: 50%; transform: translate(-50%,-50%); } </style> </head> <body> <div id="container"> <div id="center-div"> xxx </div> </div> </body> </html> -
还可以使用Flexbox来实现水平垂直居中;适合宽度高度未知情况,但是要注意兼容性
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> <style> #p_2{ display: flex; justify-content: center; align-items: center; width: 200px; height: 200px; background: #009f95; } </style> </head> <body> <div id="p_2"> <div id="c_2"> xxxxxxx </div> </div> </body> </html>
-
-
1像素边框问题




























JavaScript
-
图片懒加载
-
前端实现图片懒加载(lazyload)的两种方式
在实际的项目开发中,我们通常会遇见这样的场景:一个页面有很多图片,而首屏出现的图片大概就一两张,那么我们还要一次性把所有图片都加载出来吗?显然这是愚蠢的,不仅影响页面渲染速度,还浪费带宽。这也就是们通常所说的首屏加载,技术上现实其中要用的技术就是图片懒加载--到可视区域再加载。
思路:
将页面里所有img属性src属性用data-xx代替,当页面滚动直至此图片出现在可视区域时,用js取到该图片的data-xx的值赋给src。
关于各种宽高:
![复制代码]()
页可见区域宽: document.body.clientWidth; 网页可见区域高: document.body.clientHeight; 网页可见区域宽: document.body.offsetWidth (包括边线的宽); 网页可见区域高: document.body.offsetHeight (包括边线的宽); 网页正文全文宽: document.body.scrollWidth; 网页正文全文高: document.body.scrollHeight; 网页被卷去的高: document.body.scrollTop; 网页被卷去的左: document.body.scrollLeft; 网页正文部分上: window.screenTop; 网页正文部分左: window.screenLeft; 屏幕分辨率的高: window.screen.height; 屏幕分辨率的宽: window.screen.width; 屏幕可用工作区高度: window.screen.availHeight;
![复制代码]()
示例:
jqueryLazyload方式
下载地址:https://github.com/helijun/helijun/blob/master/plugin/lazyLoad/jquery.lazyload.js
<section class="module-section" id="container"> <img class="lazy-load" data-original="../static/img/loveLetter/teacher/teacher1.jpg" width="640" height="480" alt="测试懒加载图片"/> </section>![复制代码]()
require.config({ baseUrl : "/static", paths: { jquery:'component/jquery/jquery-3.1.0.min' jqueryLazyload: 'component/lazyLoad/jquery.lazyload',//图片懒加载 }, shim: { jqueryLazyload: { deps: ['jquery'], exports: '$' } } });![复制代码]()
![复制代码]()
require( [ 'jquery', 'jqueryLazyload' ], function($){ $(document).ready(function() { $("img.lazy-load").lazyload({
effect : "fadeIn", //渐现,show(直接显示),fadeIn(淡入),slideDown(下拉)
threshold : 180, //预加载,在图片距离屏幕180px时提前载入
event: 'click', // 事件触发时才加载,click(点击),mouseover(鼠标划过),sporty(运动的),默认为scroll(滑动)
container: $("#container"), // 指定对某容器中的图片实现效果
failure_limit:2 //加载2张可见区域外的图片,lazyload默认在找到第一张不在可见区域里的图片时则不再继续加载,但当HTML容器混乱的时候可能出现可见区域内图片并没加载出来的情况});
});});
![复制代码]()
为了代码可读性,属性值我都写好了注释。值得注意的是预制图片属性为data-original,并且最好是给予初始高宽占位,以免影响布局,当然这里为了演示我是写死的640x480,如果是响应式页面,高宽需要动态计算。
dome演示地址:http://h5.sztoda.cn/test/testLazyLoad
echo.js方式
在前面“前端知识的一些总结”的博文中,介绍了一款非常简单实用轻量级的图片延时加载插件echo.js,如果你的项目中没有依赖jquery,那么这将是个不错的选择,50行代码,压缩后才1k。当然你完全可以集成到自己项目中去!
下载地址:https://github.com/helijun/helijun/tree/master/plugin/echo
![复制代码]()
<style> .demo img {
width: 736px;
height: 490px;
background: url(images/loading.gif) 50% no-repeat;} </style>![复制代码]()
<div class="demo"> <img class="lazy" src="images/blank.gif" data-echo="images/big-1.jpg"> </div>![复制代码]()
<script src="js/echo.min.js"></script> <script> Echo.init({ offset: 0,//离可视区域多少像素的图片可以被加载
throttle: 0 //图片延时多少毫秒加载
});
</script>![复制代码]()
说明:blank.gif是一张背景图片,包含在插件里了。图片的宽高必须设定,当然,可以使用外部样式对多张图片统一控制大小。data-echo指向的是真正的图片地址。
总结:
两者都非常简单,实现思路是一样的,只是jquerylazyload多几个属性。其实常用的echo就足够了,并且完全可以集成到自己项目中的公共js中,图片懒加载是相当常见且简单实用的功能,如果你的项目中还是傻瓜式的一次性全部加载,那么请花20分钟优化下
一、什么是图片滚动加载?
通俗的讲就是:当访问一个页面的时候,先把img元素或是其他元素的背景图片路径替换成一张大小为1*1px图片的路径(这样就只需请求一次),只有当图片出现在浏览器的可视区域内时,才设置图片正真的路径,让图片显示出来。这就是图片懒加载。
二、为什要使用这个技术?
比如一个页面中有很多图片,如淘宝、京东首页等等,如果一上来就发送这么多请求,页面加载就会很漫长,如果js文件都放在了文档的底部,恰巧页面的头部又依赖这个js文件,那就不好办了。更为要命的是:一上来就发送百八十个请求,服务器可能就吃不消了(又不是只有一两个人在访问这个页面)。
因此优点就很明显了:不仅可以减轻服务器的压力,而且可以让加载好的页面更快地呈现在用户面前(用户体验好)。
三、怎么实现?
关键点如下:
1、页面中的img元素,如果没有src属性,浏览器就不会发出请求去下载图片(也就没有请求咯,也就提高性能咯),一旦通过javascript设置了图片路径,浏览器才会送请求。有点按需分配的意思,你不想看,就不给你看,你想看了就给你看~
2、如何获取正真的路径,这个简单,现在正真的路径存在元素的“data-url”(这个名字起个自己认识好记的就行)属性里,要用的时候就取出来,再设置;
3、开始比较之前,先了解一些基本的知识,比如说如何获取某个元素的尺寸大小、滚动条滚动距离及偏移位置距离;
![]()
1)屏幕可视窗口大小:对应于图中1、2位置处
原生方法:window.innerHeight 标准浏览器及IE9+ || document.documentElement.clientHeight 标准浏览器及低版本IE标准模式 ||
document.body.clientHeight 低版本混杂模式
jQuery方法: $(window).height()
2)浏览器窗口顶部与文档顶部之间的距离,也就是滚动条滚动的距离:也就是图中3、4处对应的位置;
原生方法:window.pagYoffset——IE9+及标准浏览器 || document.documentElement.scrollTop 兼容ie低版本的标准模式 ||
document.body.scrollTop 兼容混杂模式;
jQuery方法:$(document).scrollTop();
3)获取元素的尺寸:对应于图中5、6位置处;左边jquery方法,右边原生方法
$(o).width() = o.style.width;
$(o).innerWidth() = o.style.width+o.style.padding;
$(o).outerWidth() = o.offsetWidth = o.style.width+o.style.padding+o.style.border;
$(o).outerWidth(true) = o.style.width+o.style.padding+o.style.border+o.style.margin;
注意:要使用原生的style.xxx方法获取属性,这个元素必须已经有内嵌的样式,如<div style="...."></div>;
如果原先是通过外部或内部样式表定义css样式,必须使用o.currentStyle[xxx] || document.defaultView.getComputedStyle(0)[xxx]来获取样式值
4)获取元素的位置信息:对应与图中7、8位置处
1)返回元素相对于文档document顶部、左边的距离;
jQuery:$(o).offset().top元素距离文档顶的距离,$(o).offset().left元素距离文档左边缘的距离
原生:getoffsetTop(),高程上有具体说明,这边就忽略了;
顺便提一下返回元素相对于第一个以定位的父元素的偏移距离,注意与上面偏移距的区别;
jQuery:position()返回一个对象,$(o).position().left = style.left,$(o).position().top = style.top;
4、知道如何获取元素尺寸、偏移距离后,接下来一个问题就是:如何判断某个元素进入或者即将进入可视窗口区域?下面也通过一张图来说明问题。
![]()
1)外面最大的框为实际页面的大小,中间浅蓝色的框代表父元素的大小,对象1~8代表元素位于页面上的实际位置;以水平方向来做如下说明!
2)对象8左边界相对于页面左边界的偏移距离(offsetLeft)大于父元素右边界相对于页面左边界的距离,此时可判读元素位于父元素之外;
3)对象7左边界跨过了父元素右边界,此时:对象7左边界相对于页面左边界的偏移距离(offsetLeft)小于 父元素右边界相对于
页面左边界的距离,因此对象7就进入了父元素可视区;
4)在对象6的位置处,对象5的右边界与页面左边界的距离 大于 父元素左边界与页面左边界的距离;
5)在对象5位置处时,对象5的右边界与页面左边界的距离 小于 父元素左边界与页面左边界的距离;此时,可判断元素处于父元素可视区外;
6)因此水平方向必须买足两个条件,才能说明元素位于父元素的可视区内;同理垂直方向也必须满足两个条件;具体见下文的源码;
四、扩展为jquery插件
使用方法:$("selector").scrollLoad({ 参数在代码中有说明 })
(function($) { $.fn.scrollLoading = function(options) { var defaults = { // 在html标签中存放的属性名称; attr: "data-url", // 父元素默认为window container: window, callback: $.noop }; // 不管有没有传入参数,先合并再说; var params = $.extend({}, defaults, options || {}); // 把父元素转为jquery对象; var container = $(params.container); // 新建一个数组,然后调用each方法,用于存储每个dom对象相关的数据; params.cache = []; $(this).each(function() { // 取出jquery对象中每个dom对象的节点类型,取出每个dom对象上设置的图片路径 var node = this.nodeName.toLowerCase(), url = $(this).attr(params["attr"]); //重组,把每个dom对象上的属性存为一个对象; var data = { obj: $(this), tag: node, url: url }; // 把这个对象加到一个数组中; params.cache.push(data); }); var callback = function(call) { if ($.isFunction(params.callback)) { params.callback.call(call); } }; //每次触发滚动事件时,对每个dom元素与container元素进行位置判断,如果满足条件,就把路径赋予这个dom元素! var loading = function() { // 获取父元素的高度 var contHeight = container.outerHeight(); var contWidth = container.outerWidth(); // 获取父元素相对于文档页顶部的距离,这边要注意了,分为以下两种情况; if (container.get(0) === window) { // 第一种情况父元素为window,获取浏览器滚动条已滚动的距离;$(window)没有offset()方法; var contop = $(window).scrollTop(); var conleft = $(window).scrollLeft(); } else { // 第二种情况父元素为非window元素,获取它的滚动条滚动的距离; var contop = container.offset().top; var conleft = container.offset().left; } $.each(params.cache, function(i, data) { var o = data.obj, tag = data.tag, url = data.url, post, posb, posl, posr; if (o) { //对象顶部与文档顶部之间的距离,如果它小于父元素底部与文档顶部的距离,则说明垂直方向上已经进入可视区域了; post = o.offset().top - (contop + contHeight); //对象底部与文档顶部之间的距离,如果它大于父元素顶部与文档顶部的距离,则说明垂直方向上已经进入可视区域了; posb = o.offset().top + o.height() - contop; // 水平方向上同理; posl = o.offset().left - (conleft + contWidth); posr = o.offset().left + o.width() - conleft; // 只有当这个对象是可视的,并且这四个条件都满足时,才能给这个对象赋予图片路径; if ( o.is(':visible') && (post < 0 && posb > 0) && (posl < 0 && posr > 0) ) { if (url) { //在浏览器窗口内 if (tag === "img") { //设置图片src callback(o.attr("src", url)); } else { // 设置除img之外元素的背景url callback(o.css("background-image", "url("+ url +")")); } } else { // 无地址,直接触发回调 callback(o); } // 给对象设置完图片路径之后,把params.cache中的对象给清除掉;对象再进入可视区,就不再进行重复设置了; data.obj = null; } } }); }; //加载完毕即执行 loading(); //滚动执行 container.bind("scroll", loading); }; })(jQuery);
-
-
实现页面加载进度条
-
网页进度条能够更好的反应当前网页的加载进度情况,loading进度条可用动画的形式从开始0%到100%完成网页加载这一过程。但是目前的浏览器并没有提供页面加载进度方面的接口,也就是说页面还无法准确返回页面实际加载的进度,本文中我们使用jQuery来实现页面加载进度条效果。
HTML
首先我们要知道的是,目前没有任何浏览器可以直接获取正在加载对象的大小。所以我们无法通过数据大小来实现0-100%的加载显示过程。
因此我们需要通过html代码逐行加载的特性,在整页代码的若干个跳跃行数中设置节点,进行大概的模糊进度反馈来实现进度加载的效果。大致意思是:页面每加载到指定区域,则返回(n)%的进度结果,通过设置多个节点,来达到一步一步显示加载进度的目的。
假如有一个页面,按区块分为页头、左侧内容、右边侧栏、页脚四部分,我们把这四部分作为四个节点,当页面加载每一个节点后,设置大概加载百分比,页面结构如下:
123456789101112<divid="header">页头部分</div><divid="mainpage">左侧内容</div><divid="sider">右边侧栏</div><divid="footer">页脚部分</div>然后我们在<body>下的第一行加上进度条.loading。
1<divclass="loading"></div>CSS
我们要设置loading进度条的样式,设置背景色,高度,以及位置,优先级等。
1234567.loading{background:#FF6100; //设置进度条的颜色height:5px;//设置进度条的高度position:fixed;//设定进度条跟随屏幕滚动top:0;//将进度条固定在页面顶部z-index:99999//提高进度条的优先层级,避免被其他层遮挡}jQuery
接下来,我们要在每个节点后面加上进度动画,使用jQuery来实现。
123456789101112131415161718192021222324252627<div id="header">页头部分</div><script type="text/javascript">$('.loading').animate({'width':'33%'},50);//第一个进度节点</script><div id="mainpage">左侧内容</div><script type="text/javascript">$('.loading').animate({'width':'55%'},50);//第二个进度节点</script><div id="sider">右边侧栏</div><script type="text/javascript">$('.loading').animate({'width':'80%'},50);//第三个进度节点</script><div id="footer">页脚部分</div><script type="text/javascript">$('.loading').animate({'width':'100%'},50);//第四个进度节点</script>可以看出,没加载一个节点后,jQuery调用animate()动画方法实现进度条宽度的变化,每个节点变化以50毫秒时间让进度条看起来更流畅些,最终从0%变化到100%,完成了进度条的进度动画。
当进度条达到100%后,页面加载完成,最后还有一步要做的就是隐藏进度条。
123$(document).ready(function(){$('.loading').fadeOut();});
-
-
事件委托
-
如今的JavaScript技术界里最火热的一项技术应该是‘事件委托(event delegation)’了。使用事件委托技术能让你避免对特定的每个节点添加事件监听器;相反,事件监听器是被添加到它们的父元素上。事件监听器会分析从子元素冒泡上来的事件,找到是哪个子元素的事件。基本概念非常简单,但仍有很多人不理解事件委托的工作原理。这里我将要解释事件委托是如何工作的,并提供几个纯JavaScript的基本事件委托的例子。
假定我们有一个
UL元素,它有几个子元素:<ul id="parent-list"> <li id="post-1">Item 1</li> <li id="post-2">Item 2</li> <li id="post-3">Item 3</li> <li id="post-4">Item 4</li> <li id="post-5">Item 5</li> <li id="post-6">Item 6</li> </ul>我们还假设,当每个子元素被点击时,将会有各自不同的事件发生。你可以给每个独立的
li元素添加事件监听器,但有时这些li元素可能会被删除,可能会有新增,监听它们的新增或删除事件将会是一场噩梦,尤其是当你的监听事件的代码放在应用的另一个地方时。但是,如果你将监听器安放到它们的父元素上呢?你如何能知道是那个子元素被点击了?简单:当子元素的事件冒泡到父
ul元素时,你可以检查事件对象的target属性,捕获真正被点击的节点元素的引用。下面是一段很简单的JavaScript代码,演示了事件委托的过程:// 找到父元素,添加监听器... document.getElementById("parent-list").addEventListener("click",function(e) { // e.target是被点击的元素! // 如果被点击的是li元素 if(e.target && e.target.nodeName == "LI") { // 找到目标,输出ID! console.log("List item ",e.target.id.replace("post-")," was clicked!"); } });第一步是给父元素添加事件监听器。当有事件触发监听器时,检查事件的来源,排除非
li子元素事件。如果是一个li元素,我们就找到了目标!如果不是一个li元素,事件将被忽略。这个例子非常简单,UL和li是标准的父子搭配。让我们试验一些差异比较大的元素搭配。假设我们有一个父元素div,里面有很多子元素,但我们关心的是里面的一个带有”classA” CSS类的A标记:// 获得父元素DIV, 添加监听器... document.getElementById("myDiv").addEventListener("click",function(e) { // e.target是被点击的元素 if(e.target && e.target.nodeName == "A") { // 获得CSS类名 var classes = e.target.className.split(" "); // 搜索匹配! if(classes) { // For every CSS class the element has... for(var x = 0; x < classes.length; x++) { // If it has the CSS class we want... if(classes[x] == "classA") { // Bingo! console.log("Anchor element clicked!"); // Now do something here.... } } } } });上面这个例子中不仅比较了标签名,而且比较了CSS类名。虽然稍微复杂了一点,但还是很具代表性的。比如,如果某个A标记里有一个
span标记,则这个span将会成为target元素。这个时候,我们需要上溯DOM树结构,找到里面是否有一个 A.classA 的元素。因为大部分程序员都会使用jQuery等工具库来处理DOM元素和事件,我建议大家都使用里面的事件委托方法,因为这里工具库里都提供了高级的委托方法和元素甄别方法。
希望这篇文章能帮助你理解JavaScript事件委托的幕后原理,希望你也感受到了事件委托的强大用处!
-
1,什么是事件委托:通俗的讲,事件就是onclick,onmouseover,onmouseout,等就是事件,委托呢,就是让别人来做,这个事件本来是加在某些元素上的,然而你却加到别人身上来做,完成这个事件。
也就是:利用冒泡的原理,把事件加到父级上,触发执行效果。
好处呢:1,提高性能。
我们可以看一个例子:需要触发每个li来改变他们的背景颜色。
<ul id="ul"> <li>aaaaaaaa</li> <li>bbbbbbbb</li> <li>cccccccc</li> </ul>window.onload = function(){ var oUl = document.getElementById("ul"); var aLi = oUl.getElementsByTagName("li"); for(var i=0; i<aLi.length; i++){ aLi[i].onmouseover = function(){ this.style.background = "red"; } aLi[i].onmouseout = function(){ this.style.background = ""; } } }这样我们就可以做到li上面添加鼠标事件。
但是如果说我们可能有很多个li用for循环的话就比较影响性能。
下面我们可以用事件委托的方式来实现这样的效果。html不变
window.onload = function(){ var oUl = document.getElementById("ul"); var aLi = oUl.getElementsByTagName("li"); /* 这里要用到事件源:event 对象,事件源,不管在哪个事件中,只要你操作的那个元素就是事件源。 ie:window.event.srcElement 标准下:event.target nodeName:找到元素的标签名 */ oUl.onmouseover = function(ev){ var ev = ev || window.event; var target = ev.target || ev.srcElement; //alert(target.innerHTML); if(target.nodeName.toLowerCase() == "li"){ target.style.background = "red"; } } oUl.onmouseout = function(ev){ var ev = ev || window.event; var target = ev.target || ev.srcElement; //alert(target.innerHTML); if(target.nodeName.toLowerCase() == "li"){ target.style.background = ""; } } }好处2,新添加的元素还会有之前的事件。
我们还拿这个例子看,但是我们要做动态的添加li。点击button动态添加li
如:
<input type="button" id="btn" /> <ul id="ul"> <li>aaaaaaaa</li> <li>bbbbbbbb</li> <li>cccccccc</li> </ul>不用事件委托我们会这样做:
window.onload = function(){ var oUl = document.getElementById("ul"); var aLi = oUl.getElementsByTagName("li"); var oBtn = document.getElementById("btn"); var iNow = 4; for(var i=0; i<aLi.length; i++){ aLi[i].onmouseover = function(){ this.style.background = "red"; } aLi[i].onmouseout = function(){ this.style.background = ""; } } oBtn.onclick = function(){ iNow ++; var oLi = document.createElement("li"); oLi.innerHTML = 1111 *iNow; oUl.appendChild(oLi); } }这样做我们可以看到点击按钮新加的li上面没有鼠标移入事件来改变他们的背景颜色。
因为点击添加的时候for循环已经执行完毕。
那么我们用事件委托的方式来做。就是html不变
window.onload = function(){ var oUl = document.getElementById("ul"); var aLi = oUl.getElementsByTagName("li"); var oBtn = document.getElementById("btn"); var iNow = 4; oUl.onmouseover = function(ev){ var ev = ev || window.event; var target = ev.target || ev.srcElement; //alert(target.innerHTML); if(target.nodeName.toLowerCase() == "li"){ target.style.background = "red"; } } oUl.onmouseout = function(ev){ var ev = ev || window.event; var target = ev.target || ev.srcElement; //alert(target.innerHTML); if(target.nodeName.toLowerCase() == "li"){ target.style.background = ""; } } oBtn.onclick = function(){ iNow ++; var oLi = document.createElement("li"); oLi.innerHTML = 1111 *iNow; oUl.appendChild(oLi); } }
-
-
实现extend函数
-
1.实现
- /**
- * 有一个函数为extend,该函数有两个参数
- * arg1
- * arg2
- * 当第一次调用该函数的时候,创建一个类,
- * 当第二次调用该函数的时候,为这个类提供扩展
- */
- function extend(json,prop){
- function F(){
- }
- /**
- * 如果json为函数
- */
- if(typeof json == "function"){
- /**
- * 如果json为一个函数,把json的原型赋值给了F的原型,相当于F继承了json
- */
- F.prototype = json.prototype;
- /**
- * prop为扩展,把prop的每一个key,value键值对赋值给了F的prototype
- */
- for(var i in prop){
- F.prototype[i] = prop[i];
- }
- }
- /**
- * 如果json为json对象
- * 当第一次调用extend方法的时候,执行该if语句
- */
- if(typeof json == "object"){
- /**
- * 遍历json对象,把json对象的每一个key值添加了F的prototype属性的属性上
- * 把json对象的每一个value值赋值给prototype的属性的值
- */
- for(var i in json){
- F.prototype[i] = json[i];
- }
- }
- return new F();
- }
2.调用
- /**
- * 该Person为一个对象
- */
- var Person = extend({
- a:'a',
- b:'b'
- });
- var p = new Person();//不能使用new关键字进行创建了
- alert(p.a);
- var Student = extend(Person,{
- c:'c',
- d:'d'
- });
- var s = new Student();
- alert(s.c);
-
-
为什么会有跨域的问题以及解决方式
- 前端解决跨域问题的8种方案(最新最全)
1.同源策略如下:
URL 说明 是否允许通信 http://www.a.com/a.js
http://www.a.com/b.js同一域名下 允许 http://www.a.com/lab/a.js
http://www.a.com/script/b.js同一域名下不同文件夹 允许 http://www.a.com:8000/a.js
http://www.a.com/b.js同一域名,不同端口 不允许 http://www.a.com/a.js
https://www.a.com/b.js同一域名,不同协议 不允许 http://www.a.com/a.js
http://70.32.92.74/b.js域名和域名对应ip 不允许 http://www.a.com/a.js
http://script.a.com/b.js主域相同,子域不同 不允许 http://www.a.com/a.js
http://a.com/b.js同一域名,不同二级域名(同上) 不允许(cookie这种情况下也不允许访问) http://www.cnblogs.com/a.js
http://www.a.com/b.js不同域名 不允许 - 特别注意两点:
- 第一,如果是协议和端口造成的跨域问题“前台”是无能为力的,
- 第二:在跨域问题上,域仅仅是通过“URL的首部”来识别而不会去尝试判断相同的ip地址对应着两个域或两个域是否在同一个ip上。
- “URL的首部”指window.location.protocol +window.location.host,也可以理解为“Domains, protocols and ports must match”。
2. 前端解决跨域问题
1> document.domain + iframe (只有在主域相同的时候才能使用该方法)
1) 在www.a.com/a.html中:
![复制代码]()
document.domain = 'a.com'; var ifr = document.createElement('iframe'); ifr.src = 'http://www.script.a.com/b.html'; ifr.display = none; document.body.appendChild(ifr); ifr.onload = function(){ var doc = ifr.contentDocument || ifr.contentWindow.document; //在这里操作doc,也就是b.html ifr.onload = null; };![复制代码]()
2) 在www.script.a.com/b.html中:
document.domain = 'a.com';
2> 动态创建script
这个没什么好说的,因为script标签不受同源策略的限制。
![复制代码]()
function loadScript(url, func) { var head = document.head || document.getElementByTagName('head')[0]; var script = document.createElement('script'); script.src = url; script.onload = script.onreadystatechange = function(){ if(!this.readyState || this.readyState=='loaded' || this.readyState=='complete'){ func(); script.onload = script.onreadystatechange = null; } }; head.insertBefore(script, 0); } window.baidu = { sug: function(data){ console.log(data); } } loadScript('http://suggestion.baidu.com/su?wd=w',function(){console.log('loaded')}); //我们请求的内容在哪里? //我们可以在chorme调试面板的source中看到script引入的内容![复制代码]()
3> location.hash + iframe
原理是利用location.hash来进行传值。
假设域名a.com下的文件cs1.html要和cnblogs.com域名下的cs2.html传递信息。
1) cs1.html首先创建自动创建一个隐藏的iframe,iframe的src指向cnblogs.com域名下的cs2.html页面
2) cs2.html响应请求后再将通过修改cs1.html的hash值来传递数据
3) 同时在cs1.html上加一个定时器,隔一段时间来判断location.hash的值有没有变化,一旦有变化则获取获取hash值
注:由于两个页面不在同一个域下IE、Chrome不允许修改parent.location.hash的值,所以要借助于a.com域名下的一个代理iframe
代码如下:
先是a.com下的文件cs1.html文件:![复制代码]()
function startRequest(){ var ifr = document.createElement('iframe'); ifr.style.display = 'none'; ifr.src = 'http://www.cnblogs.com/lab/cscript/cs2.html#paramdo'; document.body.appendChild(ifr); } function checkHash() { try { var data = location.hash ? location.hash.substring(1) : ''; if (console.log) { console.log('Now the data is '+data); } } catch(e) {}; } setInterval(checkHash, 2000);![复制代码]()
cnblogs.com域名下的cs2.html:
![复制代码]()
//模拟一个简单的参数处理操作 switch(location.hash){ case '#paramdo': callBack(); break; case '#paramset': //do something…… break; } function callBack(){ try { parent.location.hash = 'somedata'; } catch (e) { // ie、chrome的安全机制无法修改parent.location.hash, // 所以要利用一个中间的cnblogs域下的代理iframe var ifrproxy = document.createElement('iframe'); ifrproxy.style.display = 'none'; ifrproxy.src = 'http://a.com/test/cscript/cs3.html#somedata'; // 注意该文件在"a.com"域下 document.body.appendChild(ifrproxy); } }![复制代码]()
a.com下的域名cs3.html
//因为parent.parent和自身属于同一个域,所以可以改变其location.hash的值 parent.parent.location.hash = self.location.hash.substring(1);
4> window.name + iframe
window.name 的美妙之处:name 值在不同的页面(甚至不同域名)加载后依旧存在,并且可以支持非常长的 name 值(2MB)。
1) 创建a.com/cs1.html
2) 创建a.com/proxy.html,并加入如下代码
![复制代码]()
<head> <script> function proxy(url, func){ var isFirst = true, ifr = document.createElement('iframe'), loadFunc = function(){ if(isFirst){ ifr.contentWindow.location = 'http://a.com/cs1.html'; isFirst = false; }else{ func(ifr.contentWindow.name); ifr.contentWindow.close(); document.body.removeChild(ifr); ifr.src = ''; ifr = null; } }; ifr.src = url; ifr.style.display = 'none'; if(ifr.attachEvent) ifr.attachEvent('onload', loadFunc); else ifr.onload = loadFunc; document.body.appendChild(iframe); } </script> </head> <body> <script> proxy('http://www.baidu.com/', function(data){ console.log(data); }); </script> </body>![复制代码]()
3 在b.com/cs1.html中包含:
<script> window.name = '要传送的内容'; </script>5> postMessage(HTML5中的XMLHttpRequest Level 2中的API)
1) a.com/index.html中的代码:
![复制代码]()
<iframe id="ifr" src="b.com/index.html"></iframe> <script type="text/javascript"> window.onload = function() { var ifr = document.getElementById('ifr'); var targetOrigin = 'http://b.com'; // 若写成'http://b.com/c/proxy.html'效果一样 // 若写成'http://c.com'就不会执行postMessage了 ifr.contentWindow.postMessage('I was there!', targetOrigin); }; </script>![复制代码]()
2) b.com/index.html中的代码:
![复制代码]()
<script type="text/javascript"> window.addEventListener('message', function(event){ // 通过origin属性判断消息来源地址 if (event.origin == 'http://a.com') { alert(event.data); // 弹出"I was there!" alert(event.source); // 对a.com、index.html中window对象的引用 // 但由于同源策略,这里event.source不可以访问window对象 } }, false); </script>![复制代码]()
6> CORS
CORS背后的思想,就是使用自定义的HTTP头部让浏览器与服务器进行沟通,从而决定请求或响应是应该成功,还是应该失败。
IE中对CORS的实现是xdr
![复制代码]()
var xdr = new XDomainRequest(); xdr.onload = function(){ console.log(xdr.responseText); } xdr.open('get', 'http://www.baidu.com'); ...... xdr.send(null);![复制代码]()
其它浏览器中的实现就在xhr中
![复制代码]()
var xhr = new XMLHttpRequest(); xhr.onreadystatechange = function () { if(xhr.readyState == 4){ if(xhr.status >= 200 && xhr.status < 304 || xhr.status == 304){ console.log(xhr.responseText); } } } xhr.open('get', 'http://www.baidu.com'); ...... xhr.send(null);![复制代码]()
实现跨浏览器的CORS
![复制代码]()
function createCORS(method, url){ var xhr = new XMLHttpRequest(); if('withCredentials' in xhr){ xhr.open(method, url, true); }else if(typeof XDomainRequest != 'undefined'){ var xhr = new XDomainRequest(); xhr.open(method, url); }else{ xhr = null; } return xhr; } var request = createCORS('get', 'http://www.baidu.com'); if(request){ request.onload = function(){ ...... }; request.send(); }![复制代码]()
7> JSONP
JSONP包含两部分:回调函数和数据。
回调函数是当响应到来时要放在当前页面被调用的函数。
数据就是传入回调函数中的json数据,也就是回调函数的参数了。
![复制代码]()
function handleResponse(response){ console.log('The responsed data is: '+response.data); } var script = document.createElement('script'); script.src = 'http://www.baidu.com/json/?callback=handleResponse'; document.body.insertBefore(script, document.body.firstChild); /*handleResonse({"data": "zhe"})*/ //原理如下: //当我们通过script标签请求时 //后台就会根据相应的参数(json,handleResponse) //来生成相应的json数据(handleResponse({"data": "zhe"})) //最后这个返回的json数据(代码)就会被放在当前js文件中被执行 //至此跨域通信完成![复制代码]()
jsonp虽然很简单,但是有如下缺点:
1)安全问题(请求代码中可能存在安全隐患)
2)要确定jsonp请求是否失败并不容易
8> web sockets
web sockets是一种浏览器的API,它的目标是在一个单独的持久连接上提供全双工、双向通信。(同源策略对web sockets不适用)
web sockets原理:在js创建了web socket之后,会有一个HTTP请求发送到浏览器以发起连接。取得服务器响应后,建立的连接会使用HTTP升级从HTTP协议交换为web sockt协议。
只有在支持web socket协议的服务器上才能正常工作。
var socket = new WebSockt('ws://www.baidu.com');//http->ws; https->wss socket.send('hello WebSockt'); socket.onmessage = function(event){ var data = event.data; }
- 前端解决跨域问题的8种方案(最新最全)
-
jsonp原理、postMessage原理
- 简单透彻理解JSONP原理及使用
什么是JSONP
首先提一下JSON这个概念,JSON是一种轻量级的数据传输格式,被广泛应用于当前Web应用中。JSON格式数据的编码和解析基本在所有主流语言中都被实现,所以现在大部分前后端分离的架构都以JSON格式进行数据的传输。
那么JSONP是什么呢?
首先抛出浏览器同源策略这个概念,为了保证用户访问的安全,现代浏览器使用了同源策略,即不允许访问非同源的页面,详细的概念大家可以自行百度。这里大家只要知道,在ajax中,不允许请求非同源的URL就可以了,比如www.a.com下的一个页面,其中的ajax请求是不允许访问www.b.com/c.php这样一个页面的。JSONP就是用来解决跨域请求问题的,那么具体是怎么实现的呢?
JSONP原理
ajax请求受同源策略影响,不允许进行跨域请求,而script标签src属性中的链接却可以访问跨域的js脚本,利用这个特性,服务端不再返回JSON格式的数据,而是返回一段调用某个函数的js代码,在src中进行了调用,这样实现了跨域。
JSONP具体实现
1.首先看下ajax中如果进行跨域请求会如何。
前端代码在域www.practice.com下面,使用ajax发送了一个跨域的get请求<!DOCTYPE html> <html> <head> <title>GoJSONP</title> </head> <body> <script type="text/javascript"> function jsonhandle(data){ alert("age:" + data.age + "name:" + data.name); } </script> <script type="text/javascript" src="jquery-1.8.3.min.js"> </script> <script type="text/javascript"> $(document).ready(function(){ $.ajax({ type : "get", async: false, url : "http://www.practice-zhao.com/student.php?id=1", type: "json", success : function(data) { jsonhandle(data); } }); }); </script> </body> </html> -
后端PHP代码放在域www.practice-zhao.com下,简单的输出一段json格式的数据
jsonhandle({ "age" : 15, "name": "John", }) -
当访问前端代码http://www.practice.com/gojsonp/index.html 时 chrome报以下错误
提示了不同源的URL禁止访问2.下面使用JSONP,将前端代码中的ajax请求去掉,添加了一个script标签,标签的src指向了另一个域www.practice-zhao.com下的remote.js脚本
<!DOCTYPE html> <html> <head> <title>GoJSONP</title> </head> <body> <script type="text/javascript"> function jsonhandle(data){ alert("age:" + data.age + "name:" + data.name); } </script> <script type="text/javascript" src="jquery-1.8.3.min.js"> </script> <script type="text/javascript" src="http://www.practice-zhao.com/remote.js"></script> </body> </html> -
这里调用了跨域的remote.js脚本,remote.js代码如下:
jsonhandle({ "age" : 15, "name": "John", }) -
也就是这段远程的js代码执行了上面定义的函数,弹出了提示框
3.将前端代码再进行修改,代码如下:
<!DOCTYPE html> <html> <head> <title>GoJSONP</title> </head> <body> <script type="text/javascript"> function jsonhandle(data){ alert("age:" + data.age + "name:" + data.name); } </script> <script type="text/javascript" src="jquery-1.8.3.min.js"> </script> <script type="text/javascript"> $(document).ready(function(){ var url = "http://www.practice-zhao.com/student.php?id=1&callback=jsonhandle"; var obj = $('<script><\/script>'); obj.attr("src",url); $("body").append(obj); }); </script> </body> </html> -
这里动态的添加了一个script标签,src指向跨域的一个php脚本,并且将上面的js函数名作为callback参数传入,那么我们看下PHP代码怎么写的:
<?php $data = array( 'age' => 20, 'name' => '张三', ); $callback = $_GET['callback']; echo $callback."(".json_encode($data).")"; return; -
PHP代码返回了一段JS语句,即
jsonhandle({ "age" : 15, "name": "张三", }) -
此时访问页面时,动态添加了一个script标签,src指向PHP脚本,执行返回的JS代码,成功弹出提示框。
所以JSONP将访问跨域请求变成了执行远程JS代码,服务端不再返回JSON格式的数据,而是返回了一段将JSON数据作为传入参数的函数执行代码。4.最后jQuery提供了方便使用JSONP的方式,代码如下:
<!DOCTYPE html> <html> <head> <title>GoJSONP</title> </head> <body> <script type="text/javascript" src="jquery-1.8.3.min.js"> </script> <script type="text/javascript"> $(document).ready(function(){ $.ajax({ type : "get", async: false, url : "http://www.practice-zhao.com/student.php?id=1", dataType: "jsonp", jsonp:"callback", //请求php的参数名 jsonpCallback: "jsonhandle",//要执行的回调函数 success : function(data) { alert("age:" + data.age + "name:" + data.name); } }); }); </script> </body> </html> -
-
本文讲解SendMessage、PostMessage两个函数的实现原理,分为三个步骤进行讲解,分别适合初级、中级、高级程序员进行理解,三个步骤分别为:
1、SendMessage、PostMessage的运行机制。
2、SendMessage、PostMessage的运行内幕。
3、SendMessage、PostMessage的内部实现。
注:理解这篇文章之前,必须先了解Windows的消息循环机制。
1、SendMessage、PostMessage的运行机制
我们先来看最简单的。
SendMessage可以理解为,SendMessage函数发送消息,等待消息处理完成后,SendMessage才返回。稍微深入一点,是等待窗口处理函数返回后,SendMessage就返回了。
PostMessage可以理解为,PostMessage函数发送消息,不等待消息处理完成,立刻返回。稍微深入一点,PostMessage只管发送消息,消息有没有被送到则并不关心,只要发送了消息,便立刻返回。
对于写一般Windows程序的程序员来说,能够这样理解也就足够了。但SendMessage、PostMessage真的是一个发送消息等待、一个发送消息不等待吗?具体细节,下面第2点将会讲到。
2、SendMessage、PostMessage的运行内幕
在写一般Windows程序时,如上第1点讲到的足以应付,其实我们可以看看MSDN来确定SendMessage、PostMessage的运行内幕。
在MSDN中,SendMessage解释如为:The SendMessage function sends the specified message to a window or windows. It calls the window procedure for the specified window and does not return until the window procedure has processed the message.
翻译成中文为:SendMessage函数将指定的消息发到窗口。它调用特定窗口的窗口处理函数,并且不会立即返回,直到窗口处理函数处理了这个消息。
再看看PostMessage的解释:The PostMessage function places (posts) a message in the message queue associated with the thread that created the specified window and returns without waiting for the thread to process the message.
翻译成中文为:PostMessage函数将一个消息放入与创建这个窗口的消息队列相关的线程中,并立刻返回不等待线程处理消息。
仔细看完MSDN解释,我们了解到,SendMessage的确是发送消息,然后等待处理完成返回,但发送消息的方法为直接调用消息处理函数(即WndProc函数),按照函数调用规则,肯定会等消息处理函数返回之后,SendMessage才返回。而PostMessage却没有发送消息,PostMessage是将消息放入消息队列中,然后立刻返回,至于消息何时被处理,PostMessage完全不知道,此时只有消息循环知道被PostMessage的消息何时被处理了。
至此我们拨开了一层疑云,原来SendMessage只是调用我们的消息处理函数,PostMessage只是将消息放到消息队列中。下一节将会更深入这两个函数,看看Microsoft究竟是如何实现这两个函数的。
3、SendMessage、PostMessage的内部实现
Windows内部运行原理、机制往往是我们感兴趣的东西,而这些东西又没有被文档化,所以我们只能使用Microsoft提供的工具自己研究了。
首先,在基本Win32工程代码中,我们可以直接看到消息处理函数、消息循环,所以建立一个基本Win32工程(本篇文章使用VS2005),为了看到更多信息,我们需要进行设置,让VS2005载入Microsoft的Symbol(pdb)文件[1]。为了方便,去除了一些多余的代码,加入了两个菜单,ID分别为:IDM_SENDMESSAGE、IDM_POSTMESSAGE。如下列出经过简化后的必要的代码。
消息循环:
Ln000:while (GetMessage(&msg, NULL, 0, 0))
Ln001:{
Ln002: TranslateMessage(&msg);
Ln003: DispatchMessage(&msg);
Ln004:}
消息处理函数:
Ln100:LRESULT CALLBACK WndProc(HWND hWnd, UINT message, WPARAM wParam, LPARAM lParam)
Ln101:{
Ln102: int wmId, wmEvent;
Ln103: switch (message)
Ln104: {
Ln105: case WM_COMMAND:
Ln106: wmId = LOWORD(wParam);
Ln107: wmEvent = HIWORD(wParam);
Ln108: switch (wmId)
Ln109: {
Ln110: case IDM_EXIT:
Ln111: DestroyWindow(hWnd);
Ln112: break;
Ln113: case IDM_SENDMESSAGE:
Ln114: SendMessage(hWnd, WM_SENDMESSAGE, 0, 0);
Ln115: break;
Ln116: case IDM_POSTMESSAGE:
Ln117: PostMessage(hWnd, WM_POSTMESSAGE, 0, 0);
Ln118: break;
Ln119: default:
Ln120: return DefWindowProc(hWnd, message, wParam, lParam);
Ln121: }
Ln122: break;
Ln123:
Ln124: case WM_SENDMESSAGE:
Ln125: MessageBox(hWnd, L"SendMessage", L"Prompt", MB_OK);
Ln126: break;
Ln127:
Ln128: case WM_POSTMESSAGE:
Ln129: MessageBox(hWnd, L"PostMessage", L"Prompt", MB_OK);
Ln130: break;
Ln131:
Ln132: case WM_DESTROY:
Ln133: PostQuitMessage(0);
Ln134:
Ln135: default:
Ln136: return DefWindowProc(hWnd, message, wParam, lParam);
Ln137: }
Ln138: return 0;
Ln139:}
下面一步步分析这两个函数的内部情况,先讨论 SendMessage。
第一步,在DispatchMessage(Ln003)函数处下个断点,F5进行调试,当程序运行到断点后,查看 CallStack 窗口,可得如下结果:
#003:MyProj.exe!wWinMain(HINSTANCE__ * hInstance=0x00400000, HINSTANCE__ * hPrevInstance=0x00000000, wchar_t * lpCmdLine=0x000208e0, int nCmdShow=0x00000001) Line 49 C++
#002:MyProj.exe!__tmainCRTStartup() Line 589 + 0x35 bytes C
#001:MyProj.exe!wWinMainCRTStartup() Line 414 C
#000:kernel32.dll!_BaseProcessStart@4() + 0x23 bytes
我们可以看到,进程先调用 kernel32.dll 中的 BaseProcessStart 函数,然后调用的 Startup Code 的函数 wWinMainCRTStartup,然后调用 _tmainCRTStartup 函数,最终调用我们的 wWinMain函数,我们的程序就运行起来了。
第二步,去除第一步下的断点,在 WndProc(Ln101) 函数入口处下个断点,F5 继续运行,运行到新下的断点处,查看 CallStack 窗口,可得如下结果:
#008:MyProj.exe!WndProc(HWND__ * hWnd=0x00050860, unsigned int message=0x00000101, unsigned int wParam=0x00000074, long lParam=0xc03f0001) Line 122 C++
#007:user32.dll!_InternalCallWinProc@20() + 0x28 bytes
#006:user32.dll!_UserCallWinProcCheckWow@32() + 0xb7 bytes
#005:user32.dll!_DispatchMessageWorker@8() + 0xdc bytes
#004:user32.dll!_DispatchMessageW@4() + 0xf bytes
#003:MyProj.exe!wWinMain(HINSTANCE__ * hInstance=0x00400000, HINSTANCE__ * hPrevInstance=0x00000000, wchar_t * lpCmdLine=0x000208e0, #000:int nCmdShow=0x00000001) Line 49 + 0xc bytes C++
#002:MyProj.exe!__tmainCRTStartup() Line 589 + 0x35 bytes C
#001:MyProj.exe!wWinMainCRTStartup() Line 414 C
#000:kernel32.dll!_BaseProcessStart@4() + 0x23 bytes
#000~#003 跟第一步相同,不再解释。在 #004、#005,可以看到,函数运行到DispatchMessage 的内部了,DispatchMessageW、DispatchMessageWorker 是 user32.dll 中到处的函数,而且函数前部字符串相等,在此猜想应该是 DispatchMessage 的内部处理。#008 为我们消息处理函数,所以推想而知,#006、#007 是为了调用我们的消息处理函数而准备的代码。
第三步,去除第二步下的断点,在Ln003、Ln114、Ln115、Ln125 处分别下一个断点,在菜单中选择对应项,使程序运行至 Ln114,F10下一步,可以看到并没有运行到 break(Ln115),直接跳到了 Ln125 处,由此可知目前 SendMessage 已经在等待了,查看 CallStack 窗口,可得如下结果:
#013:MyProj.exe!WndProc(HWND__ * hWnd=0x00050860, unsigned int message=0x00000500, unsigned int wParam=0x00000000, long lParam=0x00000000) Line 147 C++
#012:user32.dll!_InternalCallWinProc@20() + 0x28 bytes
#011:user32.dll!_UserCallWinProcCheckWow@32() + 0xb7 bytes
#010:user32.dll!_SendMessageWorker@20() + 0xc8 bytes
#009:user32.dll!_SendMessageW@16() + 0x49 bytes
#008:MyProj.exe!WndProc(HWND__ * hWnd=0x00050860, unsigned int message=0x00000111, unsigned int wParam=0x00008003, long lParam=0x00000000) Line 136 + 0x15 bytes C++
#007:user32.dll!_InternalCallWinProc@20() + 0x28 bytes
#006:user32.dll!_UserCallWinProcCheckWow@32() + 0xb7 bytes
#005:user32.dll!_DispatchMessageWorker@8() + 0xdc bytes
#004:user32.dll!_DispatchMessageW@4() + 0xf bytes
#003:MyProj.exe!wWinMain(HINSTANCE__ * hInstance=0x00400000, HINSTANCE__ * hPrevInstance=0x00000000, wchar_t * lpCmdLine=0x000208e0, #000:int nCmdShow=0x00000001) Line 49 + 0xc bytes C++
#002:MyProj.exe!__tmainCRTStartup() Line 589 + 0x35 bytes C
#001:MyProj.exe!wWinMainCRTStartup() Line 414 C
#000:kernel32.dll!_BaseProcessStart@4() + 0x23 bytes
#000~#008 跟上面的相同,不再解释。在 #009、#010,可以看到,函数调用到 SendMessage 内部了,在此猜想应该是 SendMessage 的内部处理。#011、#012 跟第二步中的 #006、#007 一样,在第二部中,这两个函数是为了调用消息处理函数而准备的代码,#013 也是我们的消息处理函数,所以此两行代码的功能相等。
至此,我们证明了 SendMessage 的确是直接调用消息处理函数的,在消息处理函数返回前,SendMessage 等待。在所有的操作中,Ln003 断点没有去到,证明 SendMessage 不会将消息放入消息队列中(在 PostMessage 分析中,此断点将会跑到,接下来讲述)。
第四步,F5继续运行,此时弹出对话框,点击对话框中的确定后,运行到断点 Ln115 处。查看CallStack 窗口,可得如下结果:
#008:MyProj.exe!WndProc(HWND__ * hWnd=0x00050860, unsigned int message=0x00000111, unsigned int wParam=0x00008003, long lParam=0x00000000) Line 137 C++
#007:user32.dll!_InternalCallWinProc@20() + 0x28 bytes
#006:user32.dll!_UserCallWinProcCheckWow@32() + 0xb7 bytes
#005:user32.dll!_DispatchMessageWorker@8() + 0xdc bytes
#004:user32.dll!_DispatchMessageW@4() + 0xf bytes
#003:MyProj.exe!wWinMain(HINSTANCE__ * hInstance=0x00400000, HINSTANCE__ * hPrevInstance=0x00000000, wchar_t * lpCmdLine=0x000208e0, int nCmdShow=0x00000001) Line 49 + 0xc bytes C++
#002:MyProj.exe!__tmainCRTStartup() Line 589 + 0x35 bytes C
#001:MyProj.exe!wWinMainCRTStartup() Line 414 C
#000:kernel32.dll!_BaseProcessStart@4() + 0x23 bytes
#000~008 跟第二步的完全相同,此时 SendMessage 也已经返回,所调用的堆栈也清空了。
至此,我们彻底拨开了 SendMessage 的疑云,了解了 SendMessage 函数的运行机制,综述为,SendMessage 内部调用 SendMessageW、SendMessageWorker 函数做内部处理,然后调用UserCallWinProcCheckWow、InternalCallWinProc 来调用我们代码中的消息处理函数,消息处理函数完成之后,SendMessage 函数便返回了。
SendMessage 讨论完之后,现在讨论 PostMessage,将上面的所有断点删除,关闭调试。
第一步,在DispatchMessage(Ln003)函数处下个断点,F5进行调试,此处结果跟 SendMessage一样,不再说明。
第二步,去除第一步下的断点,在 WndProc(Ln101) 函数入口处下个断点,F5 继续运行,此处结果跟 SendMessage 一样,不再说明。
第三步,去除第二步下的断点,在 Ln003、Ln117、Ln118、Ln129 处分别下一个断点,在菜单中选择对应项,使程序运行至 Ln117,F10 下一步,可以看到已经运行到 break,PostMessage 函数返回了,此时 CallStack 没有变化。
第四步,F5 继续运行,此时程序运行到 Ln003,CallStack 跟第一步刚起来时一样。
第五步,F5 继续运行(由于有多个消息,可能要按多次),让程序运行到 Ln129,此时CallStack 跟第二步相同,为了方便说明,再次列举如下:
#008:MyProj.exe!WndProc(HWND__ * hWnd=0x00070874, unsigned int message=0x00000501, unsigned int wParam=0x00000000, long lParam=0x00000000) Line 151 C++
#007:user32.dll!_InternalCallWinProc@20() + 0x28 bytes
#006:user32.dll!_UserCallWinProcCheckWow@32() + 0xb7 bytes
#005:user32.dll!_DispatchMessageWorker@8() + 0xdc bytes
#004:user32.dll!_DispatchMessageW@4() + 0xf bytes
#003:MyProj.exe!wWinMain(HINSTANCE__ * hInstance=0x00400000, HINSTANCE__ * hPrevInstance=0x00000000, wchar_t * lpCmdLine=0x000208e0, int nCmdShow=0x00000001) Line 49 + 0xc bytes C++
#002:MyProj.exe!__tmainCRTStartup() Line 589 + 0x35 bytes C
#001:MyProj.exe!wWinMainCRTStartup() Line 414 C
#000:kernel32.dll!_BaseProcessStart@4() + 0x23 bytes
由此可以看到,此调用是从消息循环中调用而来,DispatchMessageW、DispatchMessageWorker是 DispatchMessage 的内部处理,UserCallWinProcCheckWow、InternalCallWinProc是为了调用我们的消息处理函数而准备的代码。
至此,我们再次彻底拨开了 PostMessage 的疑云,了解了 PostMessage 函数的运行机制,综述为,PostMessage 将消息放入消息队列中,自己立刻返回,消息循环中的 GetMessage(PeekMessage也可,本例中为演示)处理到我们发的消息之后,便按照普通消息处理方法进行处理。
-
-
实现拖拽功能,比如把5个兄弟节点中的最后一个节点拖拽到节点1和节点2之间
-
如果要设置物体拖拽,那么必须使用三个事件,并且这三个事件的使用顺序不能颠倒。
- onmousedown:鼠标按下事件
- onmousemove:鼠标移动事件
- onmouseup:鼠标抬起事件
拖拽的基本原理就是根据鼠标的移动来移动被拖拽的元素。鼠标的移动也就是x、y坐标的变化;元素的移动就是style.position的 top和left的改变。当然,并不是任何时候移动鼠标都要造成元素的移动,而应该判断鼠标左键的状态是否为按下状态,是否是在可拖拽的元素上按下的。
基本思路如下:- 拖拽状态 = 0鼠标在元素上按下的时候{
- 拖拽状态 = 1
- 记录下鼠标的x和y坐标
- 记录下元素的x和y坐标
- }
- 鼠标在元素上移动的时候{
- 如果拖拽状态是0就什么也不做。
- 如果拖拽状态是1,那么
- 元素y = 现在鼠标y - 原来鼠标y + 原来元素y
- 元素x = 现在鼠标x - 原来鼠标x + 原来元素x
- }
- 鼠标在任何时候放开的时候{
- 拖拽状态 = 0
- }
部分实例代码:
HTML部分- <div class="calculator" id="drag">**********</div>
CSS部分
- .calculator {
- position: absolute; /*设置绝对定位,脱离文档流,便于拖拽*/
- display: block;
- width: 218px;
- height: 280px;
- cursor: move; /*鼠标呈拖拽状*/
- }
js部分
- window.onload = function() {
- //拖拽功能(主要是触发三个事件:onmousedown\onmousemove\onmouseup)
- var drag = document.getElementById('drag');
- //点击某物体时,用drag对象即可,move和up是全局区域,也就是整个文档通用,应该使用document对象而不是drag对象(否则,采用drag对象时物体只能往右方或下方移动)
- drag.onmousedown = function(e) {
- var e = e || window.event; //兼容ie浏览器
- var diffX = e.clientX - drag.offsetLeft; //鼠标点击物体那一刻相对于物体左侧边框的距离=点击时的位置相对于浏览器最左边的距离-物体左边框相对于浏览器最左边的距离
- var diffY = e.clientY - drag.offsetTop;
- /*低版本ie bug:物体被拖出浏览器可是窗口外部时,还会出现滚动条,
- 解决方法是采用ie浏览器独有的2个方法setCapture()\releaseCapture(),这两个方法,
- 可以让鼠标滑动到浏览器外部也可以捕获到事件,而我们的bug就是当鼠标移出浏览器的时候,
- 限制超过的功能就失效了。用这个方法,即可解决这个问题。注:这两个方法用于onmousedown和onmouseup中*/
- if(typeof drag.setCapture!='undefined'){
- drag.setCapture();
- }
- document.onmousemove = function(e) {
- var e = e || window.event; //兼容ie浏览器
- var left=e.clientX-diffX;
- var top=e.clientY-diffY;
- //控制拖拽物体的范围只能在浏览器视窗内,不允许出现滚动条
- if(left<0){
- left=0;
- }else if(left >window.innerWidth-drag.offsetWidth){
- left = window.innerWidth-drag.offsetWidth;
- }
- if(top<0){
- top=0;
- }else if(top >window.innerHeight-drag.offsetHeight){
- top = window.innerHeight-drag.offsetHeight;
- }
- //移动时重新得到物体的距离,解决拖动时出现晃动的现象
- drag.style.left = left+ 'px';
- drag.style.top = top + 'px';
- };
- document.onmouseup = function(e) { //当鼠标弹起来的时候不再移动
- this.onmousemove = null;
- this.onmouseup = null; //预防鼠标弹起来后还会循环(即预防鼠标放上去的时候还会移动)
- //修复低版本ie bug
- if(typeof drag.releaseCapture!='undefined'){
- drag.releaseCapture();
- }
- };
- };
- };
-
-
动画:setTimeout何时执行,requestAnimationFrame的优点
-
setTimeout()和setInterval() 何时被调用执行
定义
setTimeout()和setInterval()经常被用来处理延时和定时任务。setTimeout() 方法用于在指定的毫秒数后调用函数或计算表达式,而setInterval()则可以在每隔指定的毫秒数循环调用函数或表达式,直到clearInterval把它清除。
从定义上我们可以看到两个函数十分类似,只不过前者执行一次,而后者可以执行多次,两个函数的参数也相同,第一个参数是要执行的code或句柄,第二个是延迟的毫秒数。
很简单的定义,使用起来也很简单,但有时候我们的代码并不是按照我们的想象精确时间被调用的,很让人困惑
简单示例
看个简单的例子,简单页面在加载完两秒后,写下Delayed alert!
setTimeout('document.write("Delayed alert!");', 2000);看起来很合理,我们再看个setInterVal()方法的例子
![复制代码]()
var num = 0; var i = setInterval(function() { num++; var date = new Date(); document.write(date.getMinutes() + ':' + date.getSeconds() + ':' + date.getMilliseconds() + '<br>'); if (num > 10) clearInterval(i); }, 1000);![复制代码]()
页面每隔1秒记录一次当前时间(分钟:秒:毫秒),记录十次后清除,不再记录。考虑到代码执行时间可能记录的不是执行时间,但时间间隔应该是一样的,看看结果
![复制代码]()
43:38:116 43:39:130 43:40:144 43:41:158 43:42:172 43:43:186 43:44:200 43:45:214 43:46:228 43:47:242 43:48:256
![复制代码]()
为什么
时间间隔几乎是1000毫秒,但不精确,这是为什么呢?原因在于我们对JavaScript定时器存在一个误解,JavaScript其实是运行在单线程的环境中的,这就意味着定时器仅仅是计划代码在未来的某个时间执行,而具体执行时机是不能保证的,因为页面的生命周期中,不同时间可能有其他代码在控制JavaScript进程。在页面下载完成后代码的运行、事件处理程序、Ajax回调函数都是使用同样的线程,实际上浏览器负责进行排序,指派某段程序在某个时间点运行的优先级。
我们把效果放大一下看看,添加一个耗时的任务
![复制代码]()
function test() { for (var i = 0; i < 500000; i++) { var div = document.createElement('div'); div.setAttribute('id', 'testDiv'); document.body.appendChild(div); document.body.removeChild(div); } } setInterval(test, 10); var num = 0; var i = setInterval(function() { num++; var date = new Date(); document.write(date.getMinutes() + ':' + date.getSeconds() + ':' + date.getMilliseconds() + '<br>'); if (num > 10) clearInterval(i); }, 1000);![复制代码]()
我们又加入了一个定时任务,看看结果
![复制代码]()
47:9:222 47:12:482 47:16:8 47:19:143 47:22:631 47:25:888 47:28:712 47:32:381 47:34:146 47:35:565 47:37:406
![复制代码]()
这下效果明显了,差距甚至都超过了3秒,而且差距很不一致。
我们可以可以把JavaScript想象成在时间线上运行。当页面载入的时候首先执行的是页面生命周期后面要用的方法和变量声明和数据处理,在这之后JavaScript进程将等待更多代码执行。当进程空闲的时候,下一段代码会被触发
除了主JavaScript进程外,还需要一个在进程下一次空闲时执行的代码队列。随着页面生命周期推移,代码会按照执行顺序添加入队列,例如当按钮被按下的时候他的事件处理程序会被添加到队列中,并在下一个可能时间内执行。在接到某个Ajax响应时,回调函数的代码会被添加到队列。JavaScript中没有任何代码是立即执行的,但一旦进程空闲则尽快执行。定时器对队列的工作方式是当特定时间过去后将代码插入,这并不意味着它会马上执行,只能表示它尽快执行。
知道了这些后,我们就能明白,如果想要精确的时间控制,是不能依赖于JavaScript的setTimeout函数的。
重复的定时器
使用 setInterval() 创建的定时器可以使代码循环执行,到有指定效果的时候,清除interval就可以,如下例
![复制代码]()
var my_interval = setInterval(function () { if (condition) { //.......... } else { clearInterval(my_interval); } }, 100);![复制代码]()
但这个方式的问题在于定时器的代码可能在代码再次被添加到队列之前还没有执行完成,结果导致循环内的判断条件不准确,代码多执行几次,之间没有停顿。不过JavaScript已经解决这个问题,当使用setInterval()时,仅当没有该定时器的其他代码实例时才将定时器代码插入队列。这样确保了定时器代码加入到队列的最小时间间隔为指定间隔。
这样的规则带来两个问题
- 1. 某些间隔会被跳过
- 2.多个定时器的代码执行之间的间隔可能比预期要小
为了避免这两个缺点,我们可以使用setTimeout()来实现重复的定时器
setTimeout(function () { //code setTimeout(arguments.callee, interval); }, interval)这样每次函数执行的时候都会创建一个新的定时器,第二个setTimeout()调用使用了agrument.callee 来获取当前实行函数的引用,并设置另外一个新定时器。这样做可以保证在代码执行完成前不会有新的定时器插入,并且下一次定时器代码执行之前至少要间隔指定时间,避免连续运行。
![复制代码]()
setTimeout(function () { var div = document.getElementById('moveDiv'); var left = parseInt(div.style.left) + 5; div.style.left = left + 'px'; if (left < 200) { setTimeout(arguments.callee, 50); } }, 50);![复制代码]()
这段定时器代码每次执行的时候,把一个div向右移动5px,当坐标大于200的时候停止。
requestAnimationFrame是什么?
在浏览器动画程序中,我们通常使用一个定时器来循环每隔几毫秒移动目标物体一次,来让它动起来。如今有一个好消息,浏览器开发商们决定:“嗨,为什么我们不在浏览器里提供这样一个API呢,这样一来我们可以为用户优化他们的动画。”所以,这个
requestAnimationFrame()函数就是针对动画效果的API,你可以把它用在DOM上的风格变化或画布动画或WebGL中。使用requestAnimationFrame有什么好处?
浏览器可以优化并行的动画动作,更合理的重新排列动作序列,并把能够合并的动作放在一个渲染周期内完成,从而呈现出更流畅的动画效果。比如,通过
requestAnimationFrame(),JS动画能够和CSS动画/变换或SVG SMIL动画同步发生。另外,如果在一个浏览器标签页里运行一个动画,当这个标签页不可见时,浏览器会暂停它,这会减少CPU,内存的压力,节省电池电量。requestAnimationFrame的用法
// shim layer with setTimeout fallback window.requestAnimFrame = (function(){ return window.requestAnimationFrame || window.webkitRequestAnimationFrame || window.mozRequestAnimationFrame || function( callback ){ window.setTimeout(callback, 1000 / 60); }; })(); // usage: // instead of setInterval(render, 16) .... (function animloop(){ requestAnimFrame(animloop); render(); })(); // place the rAF *before* the render() to assure as close to // 60fps with the setTimeout fallback.对requestAnimationFrame更牢靠的封装
Opera浏览器的技术师Erik Möller 把这个函数进行了封装,使得它能更好的兼容各种浏览器。你可以读一读这篇文章,但基本上他的代码就是判断使用
4ms还是16ms的延迟,来最佳匹配60fps。下面就是这段代码,你可以使用它,但请注意,这段代码里使用的是标准函数,我给它加上了兼容各种浏览器引擎前缀。(function() { var lastTime = 0; var vendors = ['webkit', 'moz']; for(var x = 0; x < vendors.length && !window.requestAnimationFrame; ++x) { window.requestAnimationFrame = window[vendors[x]+'RequestAnimationFrame']; window.cancelAnimationFrame = window[vendors[x]+'CancelAnimationFrame'] || window[vendors[x]+'CancelRequestAnimationFrame']; } if (!window.requestAnimationFrame) window.requestAnimationFrame = function(callback, element) { var currTime = new Date().getTime(); var timeToCall = Math.max(0, 16 - (currTime - lastTime)); var id = window.setTimeout(function() { callback(currTime + timeToCall); }, timeToCall); lastTime = currTime + timeToCall; return id; }; if (!window.cancelAnimationFrame) window.cancelAnimationFrame = function(id) { clearTimeout(id); }; }());requestAnimationFrame API
window.requestAnimationFrame(function(/* time */ time){ // time ~= +new Date // the unix time });回调函数里的参数可以传入时间。
各种浏览器对requestAnimationFrame的支持情况
谷歌浏览器,火狐浏览器,IE10+都实现了这个函数,即使你的浏览器很古老,上面的对requestAnimationFrame封装也能让这个方法在IE8/9上不出错。
-
-
手写parseInt的实现:要求简单一些,把字符串型的数字转化为真正的数字即可,但不能使用JS原生的字符串转数字的API,比如Number()
-
编写分页器组件的时候,为了减少服务端查询次数,点击“下一页”怎样能确保还有数据可以加载(请求数据不会为空)?
-
ES6新增了哪些特性,使用过哪些,也有当场看代码说输出结果的
-
ES6是即将到来的新版本JavaScript语言的标准,他给我们带来了更“甜”的语法糖(一种语法,使得语言更容易理解和更具有可读性,也让我们编写代码更加简单快捷),如箭头函数(=>)、class等等。用一句话来说就是:
ES6给我们提供了许多的新语法和代码特性来提高javascript的体验
不过遗憾的是,现在还没有浏览器能够很好的支持es6语法,点这里查看浏览器支持情况,所以我们在开发中还需要用babel进行转换为CommonJS这种模块化标准的语法。
因为下面我会讲到一些es6新特性的例子,如果想要运行试试效果的话,可以点这里去测试es6的代码。
常用es6特性
然后我下面简单的介绍一些很常用的语法特性,如果想完整的了解ES6,我推荐大家 点这里
定义函数
我们先来看一个基本的新特性,在javascript中,定义函数需要关键字function,但是在es6中,还有更先进的写法,我们来看:
es6写法:
var human = { breathe(name) { //不需要function也能定义breathe函数。 console.log(name + ' is breathing...'); } }; human.breathe('jarson'); //输出 ‘jarson is breathing...’转成js代码:
var human = { breathe: function(name) { console.log(name + 'is breathing...'); } }; human.breathe('jarson');很神奇对不对?这样一对比,就可以看出es6的写法让人简单易懂。别着急,下面还有更神奇的。
创建类
我们知道,javascript不像java是面向对象编程的语言,而只可以说是基于对象编程的语言。所以在js中,我们通常都是用function和prototype来模拟 类 这个概念。
但是现在有了es6,我们可以像java那样‘明目张胆’的创建一个类了:
class Human { constructor(name) { this.name = name; } breathe() { console.log(this.name + " is breathing"); } } var man = new Human("jarson"); man.breathe(); //jarson is breathing上面代码转为js格式:
function Human(name) { this.name = name; this.breathe = function() { console.log(this.name + ' is breathing'); } } var man = new Human('jarson'); man.breathe(); //jarson is breathing所以我们看到,我们可以像java那样语义化的去创建一个类。另外,js中的继承父类,需要用prototype来实现。那么在es6中,又有什么新的方法来实现类的继承呢?继续看:
假如我们要创建一个Man类继承上面的Human类,es6代码:
class Man extends Human { constructor(name, sex) { super(name); this.sex = sex; } info(){ console.log(this.name + 'is ' + this.sex); } } var xx = new Man('jarson', 'boy'); xx.breathe(); //jarson is breathing xx.info(); //arsonis boy代码很简单,不作赘述,可以使用文章里提到的在线工具去试试效果就能明白了。需要注意的是: super() 是父类的构造函数。
模块
在ES6标准中,javascript原生支持module了。将不同功能的代码分别写在不同文件中,各模块只需 导出(export) 公共接口部分,然后在需要使用的地方通过模块的 导入(import) 就可以了。下面继续看例子:
内联导出
ES6模块里的对象可在创建它们的声明中直接导出,一个模块中可无数次使用export。
先看模块文件 app.js :
export class Human{ constructor(name) { this.name = name; } breathe() { console.log(this.name + " is breathing"); } } export function run(){ console.log('i am runing'); } function eat() { console.log('i am eating'); }例子中的模块导出了两个对象:Human类和run函数, eat函数没有导出,则仍为此模块私有,不能被其他文件使用。
导出一组对象
另外,其实如果需要导出的对象很多的时候,我们可以在最后统一导出一组对象。
更改 app.js 文件:
class Human{ constructor(name) { this.name = name; } breathe() { console.log(this.name + " is breathing"); } } function run(){ console.log('i am runing'); } function eat() { console.log('i am eating'); } export {Human, run};这样的写法功能和上面一样,而且也很明显,在最后可以清晰的看到导出了哪些对象。
Default导出
导出时使用关键字default,可将对象标注为default对象导出。default关键字在每一个模块中只能使用一次。它既可以用于内联导出,也可以用于一组对象导出声明中。
查看导出default对象的语法:
... //创建类、函数等等 export default { //把Human类和run函数标注为default对象导出。 Human, run };无对象导入
如果模块包含一些逻辑要执行,且不会导出任何对象,此类对象也可以被导入到另一模块中,导入之后只执行逻辑。如:
import './module1.js';导入默认对象
使用Default导出方式导出对象,该对象在import声明中将直接被分配给某个引用,如下例中的“app”。
import app from './module1.js';上面例子中,默认 ./module1.js 文件只导出了一个对象;若导出了一组对象,则应该在导入声明中一一列出这些对象,如:
import {Human, run} from './app.js'let与const
在我看来,在es6新特性中,在定义变量的时候统统使用 let 来代替 var 就好了, const 则很直观,用来定义常量,即无法被更改值的变量。
for (let i=0;i<2;i++) { console.log(i); //输出: 0,1 }箭头函数
ES6中新增的箭头操作符 => 简化了函数的书写。操作符左边为输入的参数,而右边则是进行的操作以及返回的值,这样的写法可以为我们减少大量的代码,看下面的实例:
let arr = [6, 8, 10, 20, 15, 9]; arr.forEach((item, i) => console.log(item, i)); let newArr = arr.filter((item) => (item<10)); console.log(newArr); //[6, 8, 9];上面的 (item, i) 就是参数,后面的 console.log(item, i) 就是回到函数要执行的操作逻辑。
上面代码转为js格式:
var arr = [6, 8, 10, 20, 15, 9]; arr.forEach(function(item, i) { return console.log(item, i); }); var newArr = arr.filter(function(item) { return (item < 10); }); console.log(newArr);字符串模版
ES6中允许使用反引号 ` 来创建字符串,此种方法创建的字符串里面可以包含由美元符号加花括号包裹的变量${vraible}。看一下实例就会明白了:
//产生一个随机数 let num = Math.random(); //将这个数字输出到console console.log(`your num is ${num}`);解构
若一个函数要返回多个值,常规的做法是返回一个对象,将每个值做为这个对象的属性返回。在ES6中,利用解构这一特性,可以直接返回一个数组,然后数组中的值会自动被解析到对应接收该值的变量中。我们来看例子:
function getVal() { return [1, 2]; } var [x,y] = getVal(); //函数返回值的解构 console.log('x:'+x+', y:'+y); //输出:x:1, y:2默认参数
现在可以在定义函数的时候指定参数的默认值了,而不用像以前那样通过逻辑或操作符来达到目的了。
function sayHello(name){ var name=name||'tom'; //传统的指定默认参数的方式 console.log('Hello '+name); } //运用ES6的默认参数 function sayHello2(name='tom'){ //如果没有传这个参数,才会有默认值, console.log(`Hello ${name}`); } sayHello();//输出:Hello tom sayHello('jarson');//输出:Hello jarson sayHello2();//输出:Hello tom sayHello2('jarson');//输出:Hello jarson注意: sayHello2(name='tom') 这里的等号,意思是没有传这个参数,则设置默认值,而不是给参数赋值的意思。
Proxy
Proxy可以监听对象身上发生了什么事情,并在这些事情发生后执行一些相应的操作。一下子让我们对一个对象有了很强的追踪能力,同时在数据绑定方面也很有用处。
//定义被监听的目标对象 let engineer = { name: 'Joe Sixpack', salary: 50 }; //定义处理程序 let interceptor = { set(receiver, property, value) { console.log(property, 'is changed to', value); receiver[property] = value; } }; //创建代理以进行侦听 engineer = new Proxy(engineer, interceptor); //做一些改动来触发代理 engineer.salary = 70;//控制台输出:salary is changed to 70对于处理程序,是在被监听的对象身上发生了相应事件之后,处理程序里面的方法就会被调用。
结语
总的来说,虽然支持es6的情况到目前还不是很乐观,但es6的新语法特性让前端和后端的差异越来越小了,这是一个新时代的开始,我们必须要了解这些新的前沿知识,才能跟上时代的步伐。
-
-
require.js的实现原理(如果使用过webpack,进一步会问,两者打包的异同及优缺点)
-
requireJS实现原理研究1
众所周知,Javascript有一个很棒的模块化库requireJS,这个基于AMD规范的js库受到越来越多的程序员喜爱,那么,下面就来谈谈我对requireJS的研究和理解。
1. 简单流程概括:
- 我们在使用requireJS时,都会把所有的js交给requireJS来管理,也就是我们的页面上只引入一个require.js,把data-main指向我们的main.js。
- 通过我们在main.js里面定义的require方法或者define方法,requireJS会把这些依赖和回调方法都用一个数据结构保存起来。
- 当页面加载时,requireJS会根据这些依赖预先把需要的js通过document.createElement的方法引入到dom中,这样,被引入dom中的script便会运行。
- 由于我们依赖的js也是要按照requireJS的规范来写的,所以他们也会有define或者require方法,同样类似第二步这样循环向上查找依赖,同样会把他们村起来。
- 当我们的js里需要用到依赖所返回的结果时(通常是一个key value类型的object),requireJS便会把之前那个保存回调方法的数据结构里面的方法拿出来并且运行,然后把结果给需要依赖的方法。
- 以上就是一个简单的流程。
2. 测试代码
下面我把一个requireJS小Demo写出来,是下面研究源码的基础:
main.js
12345678910require.config({paths: {"a": "a","b": "b"}});require(['a'], function (a){console.log('main');//console.log(a);});
a.js
123456define(['b'], function(b){console.log('a');return {'text' : 1}})
b.js
1234define(function(){console.log('b');//return 1;})
这些代码都很简单,下面开始正式的研究。
3. 开始研究
- 关于requireJS预加载。也就是说,我每个模块所依赖的其他模块都会比本模块预先加载,这点可以直接运行测试代码来证明。
123b b.js:2a a.js:2main main.js:8
这是控制台打印出的信息,可以看到,加载的顺序确实如上面所说。
- requireJS的上下文对象context。翻开requireJS的代码,看到通篇的function定义和其他变量的声明,这些暂时都还不重要,我们只用关心两行代码。
12//Create default context.req({});
根据注释可以知道,这段代码初始化了一个上下文对象context,调用的是req方法
1234567891011121314151617181920212223242526272829303132333435req = requirejs = function (deps, callback, errback, optional) {//Find the right context, use defaultvar context, config,contextName = defContextName;// Determine if have config object in the call.if (!isArray(deps) && typeof deps !== 'string') {// deps is a config objectconfig = deps;if (isArray(callback)) {// Adjust args if there are dependenciesdeps = callback;callback = errback;errback = optional;} else {deps = [];}}if (config && config.context) {contextName = config.context;}context = getOwn(contexts, contextName);if (!context) {context = contexts[contextName] = req.s.newContext(contextName);}if (config) {context.configure(config);}var fg = context.require(deps, callback, errback);return fg;};
这也方法也就是常用的require方法,可以看到这个context只会初始化一次,打印出来就是
12345678910111213141516171819202122Module: function (map) {completeLoad: function (moduleName) {config: Objectconfigure: function (cfg) {contextName: "_"defQueue: Array[0]defined: Objectenable: function (depMap) {execCb: function (name, callback, args, exports) {load: function (id, url) {makeModuleMap: function makeModuleMap(name, parentModuleMap, isNormalized, applyMap) {makeRequire: function (relMap, options) {makeShimExports: function (value) {nameToUrl: function (moduleName, ext, skipExt) {nextTick: function (fn) {onError: function onError(err, errback) {onScriptError: function (evt) {onScriptLoad: function (evt) {registry: Objectrequire: function localRequire(deps, callback, errback) {urlFetched: Object__proto__: Object
当然,这里面有很多东西,但是根据命名,不难理解,这里很多东西都是以后要用到的,例如defQueue,makeRequire等等,不用着急,这些都会在后面说道的。这个方法return了一个fg我是自己调试用的,这个fg是一个function(闭包),程序运行到这里由于我们传入的defs是空,这个function里的大多数逻辑都没有走,所以这个方法就结束了,程序会继续往下运行。
- requireJS的引入script。上一步我们得到的第一次初始化的context对象,看上去里面什么还没有,我们继续debug下,程序走到了这里:
12345678910if (isBrowser) {head = s.head = document.getElementsByTagName('head')[0];//If BASE tag is in play, using appendChild is a problem for IE6.//When that browser dies, this can be removed. Details in this jQuery bug://http://dev.jquery.com/ticket/2709baseElement = document.getElementsByTagName('base')[0];if (baseElement) {head = s.head = baseElement.parentNode;}}
这段代码不难理解,跟我上面说道的流程一样,开始寻找html里的head标签了,当然是为了引入script了!然后程序走到了这里:
12345678910111213141516171819202122232425262728293031323334if (isBrowser && !cfg.skipDataMain) {eachReverse(scripts(), function (script) {if (!head) {head = script.parentNode;}dataMain = script.getAttribute('data-main');if (dataMain) {mainScript = dataMain;if (!cfg.baseUrl) {src = mainScript.split('/');mainScript = src.pop();subPath = src.length ? src.join('/') + '/' : './';cfg.baseUrl = subPath;}mainScript = mainScript.replace(jsSuffixRegExp, '');if (req.jsExtRegExp.test(mainScript)) {mainScript = dataMain;}cfg.deps = cfg.deps ? cfg.deps.concat(mainScript) : [mainScript];return true;}});}
这段代码的主要功能就是找到我们之前绑定的data-main的,然后往全局的cfg对象里添加base路径和main,当然如果我们自己通过require的config设置打印出cfg:
1234567Object {baseUrl: "./", deps: Array[1]}baseUrl: "./"deps: Array[1]0: "main"length: 1__proto__: Array[0]__proto__: Object
这个cfg马上就会用到了。
- 第二次执行req方法。这时候程序来到了整个文件的倒数第二行
12//Set up with config info.req(cfg);
这个时候调用req方法,把刚才的cfg传了进去,然后便又回到了require方法里面,到此为止,html页面上还只有一个script标签和一个require.js,我们的main a b .js都还没有运行,里面的代码都还没有起作用。
再次进入req方法,这时deps不再是{},而是上面cfg,里面有一个main,这是在回头看看刚才return的fg,打印出来:
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354function localRequire(deps, callback, errback) {var id, map, requireMod;if (options.enableBuildCallback && callback && isFunction(callback)) {callback.__requireJsBuild = true;}if (typeof deps === 'string') {if (isFunction(callback)) {//Invalid callreturn onError(makeError('requireargs', 'Invalid require call'), errback);}if (relMap && hasProp(handlers, deps)) {return handlers[deps](registry[relMap.id]);}if (req.get) {return req.get(context, deps, relMap, localRequire);}//Normalize module name, if it contains . or ..map = makeModuleMap(deps, relMap, false, true);id = map.id;if (!hasProp(defined, id)) {return onError(makeError('notloaded', 'Module name "' +id +'" has not been loaded yet for context: ' +contextName +(relMap ? '' : '. Use require([])')));}return defined[id];}intakeDefines();context.nextTick(function () {intakeDefines();requireMod = getModule(makeModuleMap(null, relMap));requireMod.skipMap = options.skipMap;requireMod.init(deps, callback, errback, {enabled: true});checkLoaded();});return localRequire;}
原来程序走到了这里,于是我们继续debug。由于我们传入的defs不为空,所以这次和第一次执行req方法大不一样了,一路走下来,我们发现context.nextTick这个方法,很奇怪的是,找到nextTick定义的地方
123req.nextTick = typeof setTimeout !== 'undefined' ? function (fn) {setTimeout(fn, 4);} : function (fn) { fn(); };
没错,这里用到了setTimeout来延迟执行一个方法,这是为什么呢?还是4ms,至今没有搞明白!nextTick方法:
12345678910111213141516context.nextTick(function () {//Some defines could have been added since the//require call, collect them.intakeDefines();requireMod = getModule(makeModuleMap(null, relMap));//Store if map config should be applied to this require//call for dependencies.requireMod.skipMap = options.skipMap;requireMod.init(deps, callback, errback, {enabled: true});checkLoaded();});
这里说一下getModule方法,这个方法返回context里面的Module对象,这个对象是唯一标识的,也就说每个模块对应一个module,module里面存储这当前模块所依赖的模块和当前模块运行的结果。
123456789101112131415Module = function (map) {this.events = getOwn(undefEvents, map.id) || {};this.map = map;this.shim = getOwn(config.shim, map.id);this.depExports = [];this.depMaps = [];this.depMatched = [];this.pluginMaps = {};this.depCount = 0;/* this.exports this.factorythis.depMaps = [],this.enabled, this.fetched*/};
这个方法里的intakeDefines方法,可以理解为对上面context里面defQueue的初始化,通过getModule方法,最终会执行Module的init方法,这个defQueue数组里面存的是全局当前的依赖。由于此时defQueue还为空,所以不会初始化。
然后程序接着往下运行,由于我们的deps里面有main,所以我们得到了一个新的Module,是关于main的requireMod,然后执行init方法。
- 开始引入main.js。进入init()方法:
12345678910111213141516171819202122232425262728293031323334353637init: function (depMaps, factory, errback, options) {options = options || {};if (this.inited) {return;}this.factory = factory;if (errback) {this.on('error', errback);} else if (this.events.error) {errback = bind(this, function (err) {this.emit('error', err);});}this.depMaps = depMaps && depMaps.slice(0);this.errback = errback;this.inited = true;this.ignore = options.ignore;if (options.enabled || this.enabled) {//Enable this module and dependencies.//Will call this.check()this.enable();} else {this.check();}},
这段代码这么长,一开始我也看不懂的,但是我们可以抽取要点,看最后的this.enable()由于执行了这个方法,再往下debug,中间经过了check()方法,fetch()方法,load()方法,然后进入到了req.load(),在这里感叹一下requireJS确实比较复杂,中间的每个方法都对一些全局变量有修改或者设置,在这里不细致描述,继续我们主要的流程。在req.load()
1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950req.load = function (context, moduleName, url) {var config = (context && context.config) || {},node;if (isBrowser) {node = req.createNode(config, moduleName, url);node.setAttribute('data-requirecontext', context.contextName);node.setAttribute('data-requiremodule', moduleName);if (node.attachEvent &&!(node.attachEvent.toString && node.attachEvent.toString().indexOf('[native code') < 0) &&!isOpera) {useInteractive = true;node.attachEvent('onreadystatechange', context.onScriptLoad);} else {node.addEventListener('load', context.onScriptLoad, false);node.addEventListener('error', context.onScriptError, false);}node.src = url;currentlyAddingScript = node;if (baseElement) {head.insertBefore(node, baseElement);} else {head.appendChild(node);}currentlyAddingScript = null;return node;} else if (isWebWorker) {try {importScripts(url);context.completeLoad(moduleName);} catch (e) {context.onError(makeError('importscripts','importScripts failed for ' +moduleName + ' at ' + url,e,[moduleName]));}}};
终于,我们看到了证据,requireJS开始往dom里面插script了!打印出参数context, moduleName, url即
12345678910111213141516171819202122232425262728293031context:Module: function (map) {completeLoad: function (moduleName) {config: Objectconfigure: function (cfg) {contextName: "_"defQueue: Array[0]defined: Objectenable: function (depMap) {execCb: function (name, callback, args, exports) {load: function (id, url) {makeModuleMap: function makeModuleMap(name, parentModuleMap, isNormalized, applyMap) {makeRequire: function (relMap, options) {makeShimExports: function (value) {nameToUrl: function (moduleName, ext, skipExt) {nextTick: function (fn) {onError: function onError(err, errback) {onScriptError: function (evt) {onScriptLoad: function (evt) {registry: Objectrequire: function localRequire(deps, callback, errback) {startTime: 1407753904901urlFetched: ObjectmoduleName:mainurl:./main.js
然后,我们的main.js就引入进来了!
1<script type="text/javascript" charset="utf-8" async="" data-requirecontext="_" data-requiremodule="main" src="./main.js"></script>
当然,localRequire方法最后还有一个checkLoaded();方法,顾名思义就是用来检测是否引入成功,里面还有一个exprier时间,超出则报错。 -
区别不大,都是引用的写法,
require是common.js的写法,
import是ES6的写法,
主要功能都是引入模块,
写法上:var modal = require('...') import modal from '....'
不用这么麻烦,简单记住 require 是 webpack 1.x 的写法,webpack 2.x 用 import 就行了
-
-
promise的实现原理,进一步会问async、await是否使用过
-
这两天在熟悉 kissy 框架的时候,看到了
Promise模块。Promise对于一个Jser并不陌生,Promise类似于一个事务管理器,它的作用就是将各种内嵌回调的事务用流水形式表达。利用Promise可以让异步编程更符合人的直觉,让代码逻辑更加清晰,把开发人员从回调地狱中释放出来。这么“高大上”的东西,以前写nodejs代码的时候只是简单的用用,还没有理解其基本的实现原理,罪过!个人认为,理解编程思想最好的途径就是阅读一份简易的实现源码。很幸运,网上有不少Promise的简易实现,其中 这篇博文 介绍的实现方式非常赞,下面就来好好研究下吧!基础概念
目前,
Promise是ECMAScript 6规范的重要特性之一,各大浏览器也开始慢慢支持这一特性。当然,也有一些第三方内库实现了该功能,如: Q 、 when 、 WinJS 、 RSVP.js 等。Promise对象用来进行延迟(deferred)和异步(asynchronous)计算.。一个Promise处于以下四种状态之一:- pending: 还没有得到肯定或者失败结果,进行中
- fulfilled: 成功的操作
- rejected: 失败的操作
- settled: 已被
fulfilled或rejected
Promise对象有两个重要的方法,一个是then,另一个是resolve:- then:将事务添加到事务队列中
- resolve:开启流程,让整个操作从第一个事务开始执行
Promise常用方式如下:var p = new Promise(function(resolve, reject) { ... // 事务触发 resovle(xxx); ... }); p.then(function(value) { // 满足 }, function(reason) { // 拒绝 }).then().then()...示意图如下:
![]()
实现步骤
1.
Promise其实就是一个状态机。按照它的定义,我们可从如下基础代码开始:var PENDING = 0; // 进行中 var FULFILLED = 1; // 成功 var REJECTED = 2; // 失败 function Promise() { // 存储PENDING, FULFILLED或者REJECTED的状态 var state = PENDING; // 存储成功或失败的结果值 var value = null; // 存储成功或失败的处理程序,通过调用`.then`或者`.done`方法 var handlers = []; // 成功状态变化 function fulfill(result) { state = FULFILLED; value = result; } // 失败状态变化 function reject(error) { state = REJECTED; value = error; } }2.下面是
Promise的resolve方法实现:注意:
resolve方法可接收的参数有两种:一个普通的值/对象或者一个Promise对象。如果是普通的值/对象,则直接把结果传递到下一个对象;如果是一个Promise对象,则必须先等待这个子任务序列完成。function Promise() { ... function resolve(result) { try { var then = getThen(result); // 如果是一个promise对象 if (then) { doResolve(then.bind(result), resolve, reject); return; } // 修改状态,传递结果到下一个事务 fulfill(result); } catch (e) { reject(e); } } }两个辅助方法:
/** * Check if a value is a Promise and, if it is, * return the `then` method of that promise. * * @param {Promise|Any} value * @return {Function|Null} */ function getThen(value) { var t = typeof value; if (value && (t === 'object' || t === 'function')) { var then = value.then; if (typeof then === 'function') { return then; } } return null; } /** * Take a potentially misbehaving resolver function and make sure * onFulfilled and onRejected are only called once. * * Makes no guarantees about asynchrony. * * @param {Function} fn A resolver function that may not be trusted * @param {Function} onFulfilled * @param {Function} onRejected */ function doResolve(fn, onFulfilled, onRejected) { var done = false; try { fn(function(value) { if (done) return; done = true; onFulfilled(value); }, function(reason) { if (done) return; done = true; onRejected(reason); }); } catch(ex) { if (done) return; done = true; onRejected(ex); } }3.上面已经完成了一个完整的内部状态机,但我们并没有暴露一个方法去解析或则观察
Promise。现在让我们开始解析Promise:function Promise(fn) { ... doResolve(fn, resolve, reject); }如你所见,我们复用了
doResolve,因为对于初始化的fn也要对其进行控制。fn允许调用resolve或则reject多次,甚至抛出异常。这完全取决于我们去保证promise对象仅被resolved或则rejected一次,且状态不能随意改变。4.目前,我们已经有了一个完整的状态机,但我们仍然没有办法去观察它的任何变化。我们最终的目标是实现
then方法,但done方法似乎更简单,所以让我们先实现它。我们的目标是实现
promise.done(onFullfilled, onRejected):onFulfilled和onRejected两者只能有一个被执行,且执行次数为一- 该方法仅能被调用一次
- 一旦调用了该方法,则
promise链式调用结束 - 无论是否
promise已经被解析,都可以调用该方法
var PENDING = 0; // 进行中 var FULFILLED = 1; // 成功 var REJECTED = 2; // 失败 function Promise() { // 存储PENDING, FULFILLED或者REJECTED的状态 var state = PENDING; // 存储成功或失败的结果值 var value = null; // 存储成功或失败的处理程序,通过调用`.then`或者`.done`方法 var handlers = []; // 成功状态变化 function fulfill(result) { state = FULFILLED; value = result; handlers.forEach(handle); handlers = null; } // 失败状态变化 function reject(error) { state = REJECTED; value = error; handlers.forEach(handle); handlers = null; } function resolve(result) { try { var then = getThen(result); if (then) { doResolve(then.bind(result), resolve, reject) return } fulfill(result); } catch (e) { reject(e); } } // 不同状态,进行不同的处理 function handle(handler) { if (state === PENDING) { handlers.push(handler); } else { if (state === FULFILLED && typeof handler.onFulfilled === 'function') { handler.onFulfilled(value); } if (state === REJECTED && typeof handler.onRejected === 'function') { handler.onRejected(value); } } } this.done = function (onFulfilled, onRejected) { // 保证异步 setTimeout(function () { handle({ onFulfilled: onFulfilled, onRejected: onRejected }); }, 0); } doResolve(fn, resolve, reject); }当
Promise被resolved或者rejected时,我们保证handlers将被通知。5.现在我们已经实现了
done方法,下面实现then方法就很容易了。需要注意的是,我们要在处理程序中新建一个Promise。this.then = function (onFulfilled, onRejected) { var self = this; return new Promise(function (resolve, reject) { return self.done(function (result) { if (typeof onFulfilled === 'function') { try { // onFulfilled方法要有返回值! return resolve(onFulfilled(result)); } catch (ex) { return reject(ex); } } else { return resolve(result); } }, function (error) { if (typeof onRejected === 'function') { try { return resolve(onRejected(error)); } catch (ex) { return reject(ex); } } else { return reject(error); } }); }); }测试
完成了上面的代码,测试就很容易啦。偷个懒,测试实例来自MDN:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>promise test</title> <script src="./mypromise.js"></script> </head> <body> <button id="test">promise test</button> <div id="log"></div> <script> var promiseCount = 0; function testPromise() { var thisPromiseCount = ++promiseCount; var log = document.getElementById('log'); log.insertAdjacentHTML('beforeend', thisPromiseCount + ') 开始(同步代码开始)'); var p1 = new Promise( function(resolve, reject) { log.insertAdjacentHTML('beforeend', thisPromiseCount + ') Promise开始(异步代码开始)'); window.setTimeout(function() { resolve(thisPromiseCount); }, Math.random() * 2000 + 1000); } ); p1.then( function(val) { log.insertAdjacentHTML('beforeend', val + ') Promise被满足了(异步代码结束)'); } ); log.insertAdjacentHTML('beforeend', thisPromiseCount + ') 建立了Promise(同步代码结束)'); } document.querySelector('button').addEventListener('click', testPromise); </script> </body> </html> - async 和 await 实现原理
-
今天在stackOverflow网站看到一个很好的解释,摘抄并发挥一下,
It works similarly to the yield return keyword in C# 2.0.
An asynchronous method is not actually an ordinary sequential method. It is compiled into a state machine (an object) with some state (local variables are turned into fields of the object). Each block of code between two uses of await is one "step" of the state machine.
This means that when the method starts, it just runs the first step and then the state machine returns and schedules some work to be done - when the work is done, it will run the next step of the state machine. For example this code:- async Task Demo() {
- var v1 = foo();
- var v2 = await bar();
- more(v1, v2);
- }
- async Task Demo() {
- var v1 = foo();
- var v2 = await bar();
- more(v1, v2);
- }
- class _Demo {
- int _v1, _v2;
- int _state = 0;
- Task<int> _await1;
- public void Step() {
- switch(this._state) {
- case 0:
- foo();
- this._v1 = foo();
- this._await1 = bar();
- // When the async operation completes, it will call this method
- this._state = 1;
- op.SetContinuation(Step);
- case 1:
- this._v2 = this._await1.Result; // Get the result of the operation
- more(this._v1, this._v2);
- }
- }
- class _Demo {
- int _v1, _v2;
- int _state = 0;
- Task<int> _await1;
- public void Step() {
- switch(this._state) {
- case 0:
- foo();
- this._v1 = foo();
- this._await1 = bar();
- // When the async operation completes, it will call this method
- this._state = 1;
- op.SetContinuation(Step);
- case 1:
- this._v2 = this._await1.Result; // Get the result of the operation
- more(this._v1, this._v2);
- }
- }
- async Task Demo() {
- var v1 = 前序工作();
- var v2 = await 费时工作();
- 后续工作(v1, v2);
- }
- async Task Demo() {
- var v1 = 前序工作();
- var v2 = await 费时工作();
- 后续工作(v1, v2);
- }
- class 状态机{
- int _v1, _v2;
- int 状态变量 =起始态;
- Task<int> _await1;
- public void Step() {
- switch(this.状态变量) {
- case 起始态:
- this._v1 = 前序工作();
- this._await1 = 费时工作();
- // 当费时工作异步完成时, 异步工作将改变状态变量值
- this.状态变量= 顺利完成;
- 继续调用自身即 Step函数; //op.SetContinuation(Step);
- case 顺利完成:
- this._v2 = this._await1.Result; //费时工作结果
- 后续工作(this._v1, this._v2);
- }
- }
- class 状态机{
- int _v1, _v2;
- int 状态变量 =起始态;
- Task<int> _await1;
- public void Step() {
- switch(this.状态变量) {
- case 起始态:
- this._v1 = 前序工作();
- this._await1 = 费时工作();
- // 当费时工作异步完成时, 异步工作将改变状态变量值
- this.状态变量= 顺利完成;
- 继续调用自身即 Step函数; //op.SetContinuation(Step);
- case 顺利完成:
- this._v2 = this._await1.Result; //费时工作结果
- 后续工作(this._v1, this._v2);
- }
- }
-
-
实现gulp的功能
-
当一个大项目逐渐成型,或者一个框架又或者一个开发方式逐渐成型的时候,总会有一个所谓的“套路”,我们在工作中往往遵循着这个套路走。所以更换一家公司或者一个部门团队的时候,上手项目并不难,你只需要掌握这个团队管用的“套路”就ok了,关键是:要想办法优化这个“套路”。
之前一直在做内部框架的跨平台和自动化构建的事,加上开发业务逻辑的页面已经完成,就没去优化这个开发套路,什么套路呢?当项目中需要一个新的H5页面的时候,就需要手动去copy之前的一个页面代码,然后逐个修改,改成另外一个页面。去掉代码中的业务逻辑,会发现除了名称不同,其余的代码全部相同,秉承着“上级命令一定要完成”总宗旨,非也,是秉承着“我是一个程序员”的宗旨,就应该将一切需要手工完成的工作变成自动化的。所以……所以就不吹NB了,好好写……
一个古老的思路是,你应该有一套模板,当有新的页面需要开发的时候,只需一条命令或者一个按钮就可以自动帮你基于这套模板创建一个可直接用于开发的环境。为了达成这个目的,我是用到了:
1.gulp
gulp的教程这里就不写了,这里讲的很清楚 gulp教程
2.该功能主要使用到的gulp插件
gulp-load-plugins 加载gulp插件的插件
gulp-file-include 文件包含插件
gulp-data 提供数据,该数据可被其他gulp插件使用
gulp-rename 重命名文件
gulp-template 渲染模板
上面的插件连接,点击进去就是文档。
笔者认为最好的学习方式就是有一个能运行起来的项目,然后看着代码一步步走,所以我把模板化从公司的项目中抽离出来,并做了删减,提炼出一个完整的可运行的项目,并放在我的git仓库,可以运行一下命令查看效果,调试并学习:
git clone git@github.com:HcySunYang/modapp.git
npm install
gulp createapp --name=aaa下面是gulpfile.js文件和package.json文件
gulpfile.js
var gulp = require('gulp');
var gulpLoadPlugins = require("gulp-load-plugins");
var plugins = gulpLoadPlugins();
var util = require("gulp-util");
var devPath = './html';
var appData = {};
/*
* @desc 组装模板
* @src devPath
* @deps
* @dest devPath + '/tmod/app/dest'
*/
gulp.task('includeTpl',function () {
// 获取 gulp 命令的 --name参数的值 (gulp createapp --name=aaa)
var appName = util.env.name || 'special';
// 首字母大写
var appNameBig = appName.replace((/\w/), function(char){
return char.toUpperCase();
});
appData={
app: appName,
appapi: appNameBig,
appDo: appName + "Do",
title: appName
}
return gulp.src([
devPath + '/tmod/app/app.tpl',
devPath + '/tmod/app/appDo.tpl',
devPath + '/tmod/app/app.html',
devPath + '/tmod/app/appApi.tpl',
devPath + '/tmod/app/appapiInterFace.tpl'
])
.pipe(plugins.fileInclude({
prefix: '@@',
basepath: '@file'
}))
.pipe(gulp.dest(devPath + '/tmod/app/dest'));
});
/*
* @desc 解析模板
* @src devPath
* @deps includeTpl
* @dest devPath + '/tmod/app/dest'
*/
gulp.task('resolveTpl',["includeTpl"],function () {
return gulp.src([
devPath + '/tmod/app/dest/app.tpl',
devPath + '/tmod/app/dest/appDo.tpl',
devPath + '/tmod/app/dest/app.html',
devPath + '/tmod/app/dest/appApi.tpl',
devPath + '/tmod/app/dest/appapiInterFace.tpl'
])
.pipe(plugins.data(function () {
return {app: appData.app, appDo:appData.appDo,title:appData.title, appapi : appData.appapi};
}))
.pipe(plugins.template())
.pipe(gulp.dest(devPath + '/tmod/app/dest'));
});
/*
* @desc 创建部署
* @src devPath + '/tmod/app/dest
* @deps resolveTpl
* @dest devPath + '/modules/'
*/
gulp.task('createapp', ["resolveTpl"], function () {
// 创建部署入口js文件,如 index.js
gulp.src(devPath + '/tmod/app/dest/app.tpl')
.pipe(plugins.rename({
basename: appData.app,
extname: ".js"
}))
.pipe(gulp.dest(devPath + '/target/'+appData.app));
// 创建部署业务逻辑js文件,如 indexDo.js
gulp.src(devPath + '/tmod/app/dest/appDo.tpl')
.pipe(plugins.rename({
basename: appData.appDo,
extname: ".js"
}))
.pipe(gulp.dest(devPath + '/target/'+appData.app));
// 创建部署html页面文件,如 index.html
gulp.src([devPath + '/tmod/app/dest/*.html'])
.pipe(plugins.rename({
basename: appData.app,
extname: ".html"
}))
.pipe(gulp.dest(devPath + '/target/'+appData.app));
// 创建部署api接口js文件,如 indexApi.js
gulp.src(devPath + '/tmod/app/dest/appApi.tpl')
.pipe(plugins.rename({
basename: appData.app + 'Api',
extname: ".js"
}))
.pipe(gulp.dest(devPath + '/target/clientApi'));
// 创建部署跨平台接口js文件,如 indexapiInterFace.js
gulp.src(devPath + '/tmod/app/dest/appapiInterFace.tpl')
.pipe(plugins.rename({
basename: appData.app + 'apiInterFace',
extname: ".js"
}))
.pipe(gulp.dest(devPath + '/target/clientApi'));
});package.json
{
"name": "app",
"project": "app",
"version": "1.0.0",
"host": "http://10.0.69.79",
"path": "/home/huangjian/workstation/bridge/newssdk/bin",
"devDependencies": {
"gulp": "^3.9.0",
"gulp-data": "^1.2.0",
"gulp-file-include": "^0.13.7",
"gulp-load-plugins": "^0.10.0",
"gulp-rename": "^1.2.0",
"gulp-template": "^2.1.0",
"gulp-util": "^3.0.6"
}
}
-
-
使用前端框架(angular/vue/react)带来哪些好处,相对于使用jQuery
-
vue双向数据绑定的实现
-
本文能帮你做什么?
1、了解vue的双向数据绑定原理以及核心代码模块
2、缓解好奇心的同时了解如何实现双向绑定
为了便于说明原理与实现,本文相关代码主要摘自vue源码, 并进行了简化改造,相对较简陋,并未考虑到数组的处理、数据的循环依赖等,也难免存在一些问题,欢迎大家指正。不过这些并不会影响大家的阅读和理解,相信看完本文后对大家在阅读vue源码的时候会更有帮助<
本文所有相关代码均在github上面可找到 https://github.com/DMQ/mvvm相信大家对mvvm双向绑定应该都不陌生了,一言不合上代码,下面先看一个本文最终实现的效果吧,和vue一样的语法,如果还不了解双向绑定,猛戳Google
<div id="mvvm-app"> <input type="text" v-model="word"> <p>{{word}}</p> <button v-on:click="sayHi">change model</button> </div> <script src="./js/observer.js"></script> <script src="./js/watcher.js"></script> <script src="./js/compile.js"></script> <script src="./js/mvvm.js"></script> <script> var vm = new MVVM({ el: '#mvvm-app', data: { word: 'Hello World!' }, methods: { sayHi: function() { this.word = 'Hi, everybody!'; } } }); </script>效果:
几种实现双向绑定的做法
目前几种主流的mvc(vm)框架都实现了单向数据绑定,而我所理解的双向数据绑定无非就是在单向绑定的基础上给可输入元素(input、textare等)添加了change(input)事件,来动态修改model和 view,并没有多高深。所以无需太过介怀是实现的单向或双向绑定。
实现数据绑定的做法有大致如下几种:
发布者-订阅者模式(backbone.js)
脏值检查(angular.js)
数据劫持(vue.js)
发布者-订阅者模式: 一般通过sub, pub的方式实现数据和视图的绑定监听,更新数据方式通常做法是
vm.set('property', value),这里有篇文章讲的比较详细,有兴趣可点这里这种方式现在毕竟太low了,我们更希望通过
vm.property = value这种方式更新数据,同时自动更新视图,于是有了下面两种方式脏值检查: angular.js 是通过脏值检测的方式比对数据是否有变更,来决定是否更新视图,最简单的方式就是通过
setInterval()定时轮询检测数据变动,当然Google不会这么low,angular只有在指定的事件触发时进入脏值检测,大致如下:-
DOM事件,譬如用户输入文本,点击按钮等。( ng-click )
-
XHR响应事件 ( $http )
-
浏览器Location变更事件 ( $location )
-
Timer事件( $timeout , $interval )
-
执行 $digest() 或 $apply()
数据劫持: vue.js 则是采用数据劫持结合发布者-订阅者模式的方式,通过
Object.defineProperty()来劫持各个属性的setter,getter,在数据变动时发布消息给订阅者,触发相应的监听回调。思路整理
已经了解到vue是通过数据劫持的方式来做数据绑定的,其中最核心的方法便是通过
Object.defineProperty()来实现对属性的劫持,达到监听数据变动的目的,无疑这个方法是本文中最重要、最基础的内容之一,如果不熟悉defineProperty,猛戳这里
整理了一下,要实现mvvm的双向绑定,就必须要实现以下几点:
1、实现一个数据监听器Observer,能够对数据对象的所有属性进行监听,如有变动可拿到最新值并通知订阅者
2、实现一个指令解析器Compile,对每个元素节点的指令进行扫描和解析,根据指令模板替换数据,以及绑定相应的更新函数
3、实现一个Watcher,作为连接Observer和Compile的桥梁,能够订阅并收到每个属性变动的通知,执行指令绑定的相应回调函数,从而更新视图
4、mvvm入口函数,整合以上三者上述流程如图所示:
1、实现Observer
ok, 思路已经整理完毕,也已经比较明确相关逻辑和模块功能了,let's do it
我们知道可以利用Obeject.defineProperty()来监听属性变动
那么将需要observe的数据对象进行递归遍历,包括子属性对象的属性,都加上setter和getter
这样的话,给这个对象的某个值赋值,就会触发setter,那么就能监听到了数据变化。。相关代码可以是这样:var data = {name: 'kindeng'}; observe(data); data.name = 'dmq'; // 哈哈哈,监听到值变化了 kindeng --> dmq function observe(data) { if (!data || typeof data !== 'object') { return; } // 取出所有属性遍历 Object.keys(data).forEach(function(key) { defineReactive(data, key, data[key]); }); }; function defineReactive(data, key, val) { observe(val); // 监听子属性 Object.defineProperty(data, key, { enumerable: true, // 可枚举 configurable: false, // 不能再define get: function() { return val; }, set: function(newVal) { console.log('哈哈哈,监听到值变化了 ', val, ' --> ', newVal); val = newVal; } }); }这样我们已经可以监听每个数据的变化了,那么监听到变化之后就是怎么通知订阅者了,所以接下来我们需要实现一个消息订阅器,很简单,维护一个数组,用来收集订阅者,数据变动触发notify,再调用订阅者的update方法,代码改善之后是这样:
// ... 省略 function defineReactive(data, key, val) { var dep = new Dep(); observe(val); // 监听子属性 Object.defineProperty(data, key, { // ... 省略 set: function(newVal) { if (val === newVal) return; console.log('哈哈哈,监听到值变化了 ', val, ' --> ', newVal); val = newVal; dep.notify(); // 通知所有订阅者 } }); } function Dep() { this.subs = []; } Dep.prototype = { addSub: function(sub) { this.subs.push(sub); }, notify: function() { this.subs.forEach(function(sub) { sub.update(); }); } };那么问题来了,谁是订阅者?怎么往订阅器添加订阅者?
没错,上面的思路整理中我们已经明确订阅者应该是Watcher, 而且var dep = new Dep();是在defineReactive方法内部定义的,所以想通过dep添加订阅者,就必须要在闭包内操作,所以我们可以在getter里面动手脚:// Observer.js // ...省略 Object.defineProperty(data, key, { get: function() { // 由于需要在闭包内添加watcher,所以通过Dep定义一个全局target属性,暂存watcher, 添加完移除 Dep.target && dep.addDep(Dep.target); return val; } // ... 省略 }); // Watcher.js Watcher.prototype = { get: function(key) { Dep.target = this; this.value = data[key]; // 这里会触发属性的getter,从而添加订阅者 Dep.target = null; } }这里已经实现了一个Observer了,已经具备了监听数据和数据变化通知订阅者的功能,完整代码。那么接下来就是实现Compile了
2、实现Compile
compile主要做的事情是解析模板指令,将模板中的变量替换成数据,然后初始化渲染页面视图,并将每个指令对应的节点绑定更新函数,添加监听数据的订阅者,一旦数据有变动,收到通知,更新视图,如图所示:
因为遍历解析的过程有多次操作dom节点,为提高性能和效率,会先将跟节点
el转换成文档碎片fragment进行解析编译操作,解析完成,再将fragment添加回原来的真实dom节点中function Compile(el) { this.$el = this.isElementNode(el) ? el : document.querySelector(el); if (this.$el) { this.$fragment = this.node2Fragment(this.$el); this.init(); this.$el.appendChild(this.$fragment); } } Compile.prototype = { init: function() { this.compileElement(this.$fragment); }, node2Fragment: function(el) { var fragment = document.createDocumentFragment(), child; // 将原生节点拷贝到fragment while (child = el.firstChild) { fragment.appendChild(child); } return fragment; } };compileElement方法将遍历所有节点及其子节点,进行扫描解析编译,调用对应的指令渲染函数进行数据渲染,并调用对应的指令更新函数进行绑定,详看代码及注释说明:
Compile.prototype = { // ... 省略 compileElement: function(el) { var childNodes = el.childNodes, me = this; [].slice.call(childNodes).forEach(function(node) { var text = node.textContent; var reg = /\{\{(.*)\}\}/; // 表达式文本 // 按元素节点方式编译 if (me.isElementNode(node)) { me.compile(node); } else if (me.isTextNode(node) && reg.test(text)) { me.compileText(node, RegExp.$1); } // 遍历编译子节点 if (node.childNodes && node.childNodes.length) { me.compileElement(node); } }); }, compile: function(node) { var nodeAttrs = node.attributes, me = this; [].slice.call(nodeAttrs).forEach(function(attr) { // 规定:指令以 v-xxx 命名 // 如 <span v-text="content"></span> 中指令为 v-text var attrName = attr.name; // v-text if (me.isDirective(attrName)) { var exp = attr.value; // content var dir = attrName.substring(2); // text if (me.isEventDirective(dir)) { // 事件指令, 如 v-on:click compileUtil.eventHandler(node, me.$vm, exp, dir); } else { // 普通指令 compileUtil[dir] && compileUtil[dir](node, me.$vm, exp); } } }); } }; // 指令处理集合 var compileUtil = { text: function(node, vm, exp) { this.bind(node, vm, exp, 'text'); }, // ...省略 bind: function(node, vm, exp, dir) { var updaterFn = updater[dir + 'Updater']; // 第一次初始化视图 updaterFn && updaterFn(node, vm[exp]); // 实例化订阅者,此操作会在对应的属性消息订阅器中添加了该订阅者watcher new Watcher(vm, exp, function(value, oldValue) { // 一旦属性值有变化,会收到通知执行此更新函数,更新视图 updaterFn && updaterFn(node, value, oldValue); }); } }; // 更新函数 var updater = { textUpdater: function(node, value) { node.textContent = typeof value == 'undefined' ? '' : value; } // ...省略 };这里通过递归遍历保证了每个节点及子节点都会解析编译到,包括了{{}}表达式声明的文本节点。指令的声明规定是通过特定前缀的节点属性来标记,如
<span v-text="content" other-attr中v-text便是指令,而other-attr不是指令,只是普通的属性。
监听数据、绑定更新函数的处理是在compileUtil.bind()这个方法中,通过new Watcher()添加回调来接收数据变化的通知至此,一个简单的Compile就完成了,完整代码。接下来要看看Watcher这个订阅者的具体实现了
3、实现Watcher
Watcher订阅者作为Observer和Compile之间通信的桥梁,主要做的事情是:
1、在自身实例化时往属性订阅器(dep)里面添加自己
2、自身必须有一个update()方法
3、待属性变动dep.notice()通知时,能调用自身的update()方法,并触发Compile中绑定的回调,则功成身退。
如果有点乱,可以回顾下前面的思路整理function Watcher(vm, exp, cb) { this.cb = cb; this.vm = vm; this.exp = exp; // 此处为了触发属性的getter,从而在dep添加自己,结合Observer更易理解 this.value = this.get(); } Watcher.prototype = { update: function() { this.run(); // 属性值变化收到通知 }, run: function() { var value = this.get(); // 取到最新值 var oldVal = this.value; if (value !== oldVal) { this.value = value; this.cb.call(this.vm, value, oldVal); // 执行Compile中绑定的回调,更新视图 } }, get: function() { Dep.target = this; // 将当前订阅者指向自己 var value = this.vm[exp]; // 触发getter,添加自己到属性订阅器中 Dep.target = null; // 添加完毕,重置 return value; } }; // 这里再次列出Observer和Dep,方便理解 Object.defineProperty(data, key, { get: function() { // 由于需要在闭包内添加watcher,所以可以在Dep定义一个全局target属性,暂存watcher, 添加完移除 Dep.target && dep.addDep(Dep.target); return val; } // ... 省略 }); Dep.prototype = { notify: function() { this.subs.forEach(function(sub) { sub.update(); // 调用订阅者的update方法,通知变化 }); } };实例化
Watcher的时候,调用get()方法,通过Dep.target = watcherInstance标记订阅者是当前watcher实例,强行触发属性定义的getter方法,getter方法执行的时候,就会在属性的订阅器dep添加当前watcher实例,从而在属性值有变化的时候,watcherInstance就能收到更新通知。ok, Watcher也已经实现了,完整代码。
基本上vue中数据绑定相关比较核心的几个模块也是这几个,猛戳这里 , 在src目录可找到vue源码。最后来讲讲MVVM入口文件的相关逻辑和实现吧,相对就比较简单了~
4、实现MVVM
MVVM作为数据绑定的入口,整合Observer、Compile和Watcher三者,通过Observer来监听自己的model数据变化,通过Compile来解析编译模板指令,最终利用Watcher搭起Observer和Compile之间的通信桥梁,达到数据变化 -> 视图更新;视图交互变化(input) -> 数据model变更的双向绑定效果。
一个简单的MVVM构造器是这样子:
function MVVM(options) { this.$options = options; var data = this._data = this.$options.data; observe(data, this); this.$compile = new Compile(options.el || document.body, this) }但是这里有个问题,从代码中可看出监听的数据对象是options.data,每次需要更新视图,则必须通过
var vm = new MVVM({data:{name: 'kindeng'}}); vm._data.name = 'dmq';这样的方式来改变数据。显然不符合我们一开始的期望,我们所期望的调用方式应该是这样的:
var vm = new MVVM({data: {name: 'kindeng'}}); vm.name = 'dmq';所以这里需要给MVVM实例添加一个属性代理的方法,使访问vm的属性代理为访问vm._data的属性,改造后的代码如下:
function MVVM(options) { this.$options = options; var data = this._data = this.$options.data, me = this; // 属性代理,实现 vm.xxx -> vm._data.xxx Object.keys(data).forEach(function(key) { me._proxy(key); }); observe(data, this); this.$compile = new Compile(options.el || document.body, this) } MVVM.prototype = { _proxy: function(key) { var me = this; Object.defineProperty(me, key, { configurable: false, enumerable: true, get: function proxyGetter() { return me._data[key]; }, set: function proxySetter(newVal) { me._data[key] = newVal; } }); } };这里主要还是利用了
Object.defineProperty()这个方法来劫持了vm实例对象的属性的读写权,使读写vm实例的属性转成读写了vm._data的属性值,达到鱼目混珠的效果,哈哈总结
本文主要围绕“几种实现双向绑定的做法”、“实现Observer”、“实现Compile”、“实现Watcher”、“实现MVVM”这几个模块来阐述了双向绑定的原理和实现。并根据思路流程渐进梳理讲解了一些细节思路和比较关键的内容点,以及通过展示部分关键代码讲述了怎样一步步实现一个双向绑定MVVM。
-
-
-
单页应用,如何实现其路由功能
-
路由是每个单页面网站必须要有的,所以,理解一下原理,我觉得还是比较重要的。
本篇,基本不会贴代码,只讲原理,代码在页底会有githup地址,主意,一定要放在服务本地服务器里跑(因为有ajax),
希望能帮到你。
众所周知单页面网站的路径跳转全是通过js来控制的,下面咱们来讲讲
第一种:url完全不动型
这一种的情况是url完全不动,即你的页面怎么改变,怎么跳转url都不会改变
这种情况的原理 就是纯ajax拿到页面后替换原页面中的元素,
这种情况没什么好讲的,好的一言不和上代码 demo(地址在页底) 这里有全部的代码
第二种:带hash(#)型
这种类型的优点就是刷新页面,页面也不会丢。
实现原理:
小明说:如果window有一个事件能让我监听url的变化,那我就能实先路由,
那样我就可以根据url的变化,来通过ajax请求参数来渲染页面,
一个url对应一个页面,也不会重复,多好了。
我:还真有,但是只能监听 #后面参数的变化。
小明说:唉,那就凑合一下把。
通过监听 hash(#)的变化来执行js代码 从而实现 页面的改变
核心代码:
window.addEventListener(‘hashchange‘,function(){
self.urlChange()
})就是通过这个原理 只要#改变了 就能触发这个事件,这也是很多单页面网站的url中都也 (#)的原因
demo在下面
第三种:无hash(#)型
这种类型是通过html5的最新history api来实现的 能正常的回退前进 很好
url是这样的 www.ff.ff/jjkj/fdfd/fdf/fd 和普通的url一样,但是也有缺点 ,就是一刷新页面 页面就会丢,
因为 只要刷新 这个url(www.ff.ff/jjkj/fdfd/fdf/fd)就会请求服务器,然而服务器上根本没有这个资源,所以就会报404,解决方案就 配置一下服务器端(可以百度一下)
实现原理:
用了 这几个 api
history.pushState
history.replaceState
history.state
window.onpopstate事件第一步:history.pushState(null,null,"/abc"); 改变url
第二部:执行一个函数(这个函数里有改变页面的代码)
就这末简单。
下面讲一下这几个api怎么用
pushState是将指定的URL添加到浏览器历史里,存储当前历史记录点API:history.pushState(state, title, url)
// @state状态对象:记录历史记录点的额外对象,可以为空
// @title页面标题:目前所有浏览器都不支持
// @url可选的url:浏览器不会检查url是否存在,只改变url,url必须同域,不能跨域history.pushState的目的
SEO优化
更少的数据请求
更好的用户体验history.replaceState
replaceState是将指定的URL替换当前的URL,替换当前历史记录点
replaceState的api和pushState类似,不同之处在于replaceState不会在window.history里新增历史记录点,而pushState会在历史记录点里新增一个记录点的
history.state
当前URL下对应的状态信息。如果当前URL不是通过pushState或者replaceState产生的,那么history.state是null。
state对象虽然可以存储很多自定义的属性,但对于不可序列化的对象则不能存储
window.onpopstate事件
window.onpopstate事件主要是监听历史记录点,也就是说监听URL的变化,但会忽略URL的hash部分。
history.go和history.back(包括用户按浏览器历史前进后退按钮)触发,并且页面无刷的时候(由于使用pushState修改了history)会触发popstate事件,事件发生时浏览器会从history中取出URL和对应的state对象替换当前的URL和history.state。通过event.state也可以获取history.state。
注意点:
javascript脚本执行window.history.pushState和window.history.replaceState不会触发onpopstate事件。
谷歌浏览器和火狐浏览器在页面第一次打开的反应是不同的,谷歌浏览器奇怪的是回触发onpopstate事件,而火狐浏览器则不会。
-



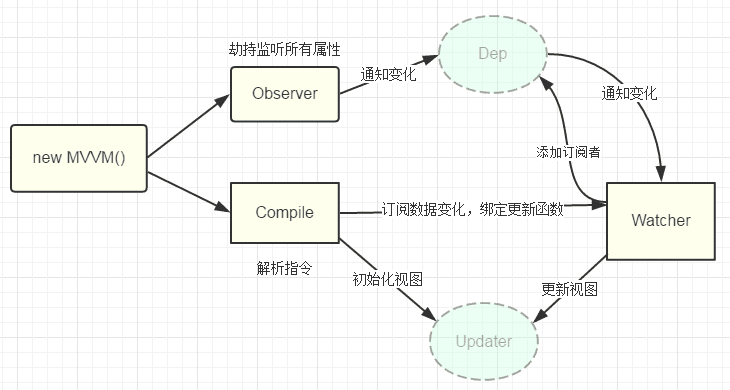

性能优化
-
项目中使用过哪些优化方法
-
输入一个URL,Enter之后发生了什么
-
原文:http://igoro.com/archive/what-really-happens-when-you-navigate-to-a-url/
作为一个软件开发者,你一定会对网络应用如何工作有一个完整的层次化的认知,同样这里也包括这些应用所用到的技术:像浏览器,HTTP,HTML,网络服务器,需求处理等等。
本文将更深入的研究当你输入一个网址的时候,后台到底发生了一件件什么样的事~
1. 首先嘛,你得在浏览器里输入要网址:

2. 浏览器查找域名的IP地址

导航的第一步是通过访问的域名找出其IP地址。DNS查找过程如下:
- 浏览器缓存 – 浏览器会缓存DNS记录一段时间。 有趣的是,操作系统没有告诉浏览器储存DNS记录的时间,这样不同浏览器会储存个自固定的一个时间(2分钟到30分钟不等)。
- 系统缓存 – 如果在浏览器缓存里没有找到需要的记录,浏览器会做一个系统调用(windows里是gethostbyname)。这样便可获得系统缓存中的记录。
- 路由器缓存 – 接着,前面的查询请求发向路由器,它一般会有自己的DNS缓存。
- ISP DNS 缓存 – 接下来要check的就是ISP缓存DNS的服务器。在这一般都能找到相应的缓存记录。
- 递归搜索 – 你的ISP的DNS服务器从跟域名服务器开始进行递归搜索,从.com顶级域名服务器到Facebook的域名服务器。一般DNS服务器的缓存中会有.com域名服务器中的域名,所以到顶级服务器的匹配过程不是那么必要了。
DNS递归查找如下图所示:

DNS有一点令人担忧,这就是像wikipedia.org 或者 facebook.com这样的整个域名看上去只是对应一个单独的IP地址。还好,有几种方法可以消除这个瓶颈:
大多数DNS服务器使用Anycast来获得高效低延迟的DNS查找。
3. 浏览器给web服务器发送一个HTTP请求

因为像Facebook主页这样的动态页面,打开后在浏览器缓存中很快甚至马上就会过期,毫无疑问他们不能从中读取。
所以,浏览器将把一下请求发送到Facebook所在的服务器:
GET http://facebook.com/ HTTP/1.1
Accept: application/x-ms-application, image/jpeg, application/xaml+xml, [...]
User-Agent: Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; [...]
Accept-Encoding: gzip, deflate
Connection: Keep-Alive
Host: facebook.com
Cookie: datr=1265876274-[...]; locale=en_US; lsd=WW[...]; c_user=2101[...]GET 这个请求定义了要读取的URL: “http://facebook.com/”。 浏览器自身定义 (User-Agent 头), 和它希望接受什么类型的相应 (Accept andAccept-Encoding 头). Connection头要求服务器为了后边的请求不要关闭TCP连接。
请求中也包含浏览器存储的该域名的cookies。可能你已经知道,在不同页面请求当中,cookies是与跟踪一个网站状态相匹配的键值。这样cookies会存储登录用户名,服务器分配的密码和一些用户设置等。Cookies会以文本文档形式存储在客户机里,每次请求时发送给服务器。
用来看原始HTTP请求及其相应的工具很多。作者比较喜欢使用fiddler,当然也有像FireBug这样其他的工具。这些软件在网站优化时会帮上很大忙。
除了获取请求,还有一种是发送请求,它常在提交表单用到。发送请求通过URL传递其参数(e.g.: http://robozzle.com/puzzle.aspx?id=85)。发送请求在请求正文头之后发送其参数。
像“http://facebook.com/”中的斜杠是至关重要的。这种情况下,浏览器能安全的添加斜杠。而像“http: //example.com/folderOrFile”这样的地址,因为浏览器不清楚folderOrFile到底是文件夹还是文件,所以不能自动添加 斜杠。这时,浏览器就不加斜杠直接访问地址,服务器会响应一个重定向,结果造成一次不必要的握手。4. facebook服务的永久重定向响应

图中所示为Facebook服务器发回给浏览器的响应:
HTTP/1.1 301 Moved Permanently
Cache-Control: private, no-store, no-cache, must-revalidate, post-check=0,
pre-check=0
Expires: Sat, 01 Jan 2000 00:00:00 GMT
Location: http://www.facebook.com/
P3P: CP="DSP LAW"
Pragma: no-cache
Set-Cookie: made_write_conn=deleted; expires=Thu, 12-Feb-2009 05:09:50 GMT;
path=/; domain=.facebook.com; httponly
Content-Type: text/html; charset=utf-8
X-Cnection: close
Date: Fri, 12 Feb 2010 05:09:51 GMT
Content-Length: 0服务器给浏览器响应一个301永久重定向响应,这样浏览器就会访问“http://www.facebook.com/” 而非“http://facebook.com/”。
为什么服务器一定要重定向而不是直接发会用户想看的网页内容呢?这个问题有好多有意思的答案。
其中一个原因跟搜索引擎排名有 关。你看,如果一个页面有两个地址,就像http://www.igoro.com/ 和http://igoro.com/,搜索引擎会认为它们是两个网站,结果造成每一个的搜索链接都减少从而降低排名。而搜索引擎知道301永久重定向是 什么意思,这样就会把访问带www的和不带www的地址归到同一个网站排名下。
还有一个是用不同的地址会造成缓存友好性变差。当一个页面有好几个名字时,它可能会在缓存里出现好几次。
5. 浏览器跟踪重定向地址

现在,浏览器知道了“http://www.facebook.com/”才是要访问的正确地址,所以它会发送另一个获取请求:
GET http://www.facebook.com/ HTTP/1.1
Accept: application/x-ms-application, image/jpeg, application/xaml+xml, [...]
Accept-Language: en-US
User-Agent: Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; [...]
Accept-Encoding: gzip, deflate
Connection: Keep-Alive
Cookie: lsd=XW[...]; c_user=21[...]; x-referer=[...]
Host: www.facebook.com头信息以之前请求中的意义相同。
6. 服务器“处理”请求

服务器接收到获取请求,然后处理并返回一个响应。
这表面上看起来是一个顺向的任务,但其实这中间发生了很多有意思的东西- 就像作者博客这样简单的网站,何况像facebook那样访问量大的网站呢!
- Web 服务器软件
web服务器软件(像IIS和阿帕奇)接收到HTTP请求,然后确定执行什么请求处理来处理它。请求处理就是一个能够读懂请求并且能生成HTML来进行响应的程序(像ASP.NET,PHP,RUBY...)。举 个最简单的例子,需求处理可以以映射网站地址结构的文件层次存储。像http://example.com/folder1/page1.aspx这个地 址会映射/httpdocs/folder1/page1.aspx这个文件。web服务器软件可以设置成为地址人工的对应请求处理,这样 page1.aspx的发布地址就可以是http://example.com/folder1/page1。
- 请求处理
请求处理阅读请求及它的参数和cookies。它会读取也可能更新一些数据,并讲数据存储在服务器上。然后,需求处理会生成一个HTML响应。
所 有动态网站都面临一个有意思的难点 -如何存储数据。小网站一半都会有一个SQL数据库来存储数据,存储大量数据和/或访问量大的网站不得不找一些办法把数据库分配到多台机器上。解决方案 有:sharding (基于主键值讲数据表分散到多个数据库中),复制,利用弱语义一致性的简化数据库。
委 托工作给批处理是一个廉价保持数据更新的技术。举例来讲,Fackbook得及时更新新闻feed,但数据支持下的“你可能认识的人”功能只需要每晚更新 (作者猜测是这样的,改功能如何完善不得而知)。批处理作业更新会导致一些不太重要的数据陈旧,但能使数据更新耕作更快更简洁。
7. 服务器发回一个HTML响应

图中为服务器生成并返回的响应:
HTTP/1.1 200 OK
Cache-Control: private, no-store, no-cache, must-revalidate, post-check=0,
pre-check=0
Expires: Sat, 01 Jan 2000 00:00:00 GMT
P3P: CP="DSP LAW"
Pragma: no-cache
Content-Encoding: gzip
Content-Type: text/html; charset=utf-8
X-Cnection: close
Transfer-Encoding: chunked
Date: Fri, 12 Feb 2010 09:05:55 GMT
2b3Tn@[...]整个响应大小为35kB,其中大部分在整理后以blob类型传输。
内容编码头告诉浏览器整个响应体用gzip算法进行压缩。解压blob块后,你可以看到如下期望的HTML:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en"
lang="en" id="facebook" class=" no_js">
<head>
<meta http-equiv="Content-type" content="text/html; charset=utf-8" />
<meta http-equiv="Content-language" content="en" />
...关于压缩,头信息说明了是否缓存这个页面,如果缓存的话如何去做,有什么cookies要去设置(前面这个响应里没有这点)和隐私信息等等。
请注意报头中把Content-type设置为“text/html”。报头让浏览器将该响应内容以HTML形式呈现,而不是以文件形式下载它。浏览器会根据报头信息决定如何解释该响应,不过同时也会考虑像URL扩展内容等其他因素。
8. 浏览器开始显示HTML
在浏览器没有完整接受全部HTML文档时,它就已经开始显示这个页面了:

9. 浏览器发送获取嵌入在HTML中的对象

在浏览器显示HTML时,它会注意到需要获取其他地址内容的标签。这时,浏览器会发送一个获取请求来重新获得这些文件。
下面是几个我们访问facebook.com时需要重获取的几个URL:
- 图片
http://static.ak.fbcdn.net/rsrc.php/z12E0/hash/8q2anwu7.gif
http://static.ak.fbcdn.net/rsrc.php/zBS5C/hash/7hwy7at6.gif
… - CSS 式样表
http://static.ak.fbcdn.net/rsrc.php/z448Z/hash/2plh8s4n.css
http://static.ak.fbcdn.net/rsrc.php/zANE1/hash/cvtutcee.css
… - JavaScript 文件
http://static.ak.fbcdn.net/rsrc.php/zEMOA/hash/c8yzb6ub.js
http://static.ak.fbcdn.net/rsrc.php/z6R9L/hash/cq2lgbs8.js
…
这些地址都要经历一个和HTML读取类似的过程。所以浏览器会在DNS中查找这些域名,发送请求,重定向等等...
但 不像动态页面那样,静态文件会允许浏览器对其进行缓存。有的文件可能会不需要与服务器通讯,而从缓存中直接读取。服务器的响应中包含了静态文件保存的期限 信息,所以浏览器知道要把它们缓存多长时间。还有,每个响应都可能包含像版本号一样工作的ETag头(被请求变量的实体值),如果浏览器观察到文件的版本 ETag信息已经存在,就马上停止这个文件的传输。
试着猜猜看“fbcdn.NET”在地址中代表什么?聪明的答案是"Facebook内容分发网络"。Facebook利用内容分发网络(CDN)分发像图片,CSS表和JavaScript文件这些静态文件。所以,这些文件会在全球很多CDN的数据中心中留下备份。
静态内容往往代表站点的带宽大小,也能通过CDN轻松的复制。通常网站会使用第三方的CDN。例如,Facebook的静态文件由最大的CDN提供商Akamai来托管。
举例来讲,当你试着ping static.ak.fbcdn.net的时候,可能会从某个akamai.Net服务器上获得响应。有意思的是,当你同样再ping一次的时候,响应的服务器可能就不一样,这说明幕后的负载平衡开始起作用了。
10. 浏览器发送异步(AJAX)请求

在Web 2.0伟大精神的指引下,页面显示完成后客户端仍与服务器端保持着联系。
以 Facebook聊天功能为例,它会持续与服务器保持联系来及时更新你那些亮亮灰灰的好友状态。为了更新这些头像亮着的好友状态,在浏览器中执行的 javascript代码会给服务器发送异步请求。这个异步请求发送给特定的地址,它是一个按照程式构造的获取或发送请求。还是在Facebook这个例 子中,客户端发送给http://www.facebook.com/ajax/chat/buddy_list.PHP一个发布请求来获取你好友里哪个 在线的状态信息。
提起这个模式,就必须要讲讲"AJAX"-- “异步JavaScript 和 XML”,虽然服务器为什么用XML格式来进行响应也没有个一清二白的原因。再举个例子吧,对于异步请求,Facebook会返回一些JavaScript的代码片段。
除了其他,fiddler这个工具能够让你看到浏览器发送的异步请求。事实上,你不仅可以被动的做为这些请求的看客,还能主动出击修改和重新发送它们。AJAX请求这么容易被蒙,可着实让那些计分的在线游戏开发者们郁闷的了。(当然,可别那样骗人家~)
Facebook聊天功能提供了关于AJAX一个有意思的问题案例:把数据从服务器端推送到客户端。因为HTTP是一个请求-响应协议,所以聊天服务器不能把新消息发给客户。取而代之的是客户端不得不隔几秒就轮询下服务器端看自己有没有新消息。
这些情况发生时长轮询是个减轻服务器负载挺有趣的技术。如果当被轮询时服务器没有新消息,它就不理这个客户端。而当尚未超时的情况下收到了该客户的新消息,服务器就会找到未完成的请求,把新消息做为响应返回给客户端。
总结一下
希望看了本文,你能明白不同的网络模块是如何协同工作的
-
-
(承上)页面的渲染过程
-
详解浏览器渲染页面过程
1.解析HTML文件,创建DOM树
自上而下,遇到任何样式(link、style)与脚本(script)都会阻塞(外部样式不阻塞后续外部脚本的加载)。
2.解析CSS
优先级:浏览器默认设置<用户设置<外部样式<内联样式<HTML中的style样式;
特定级:id数*100+类或伪类数*10+tag名称*13.将CSS与DOM合并,构建渲染树(renderingtree)
DOM树与HTML一一对应,渲染树会忽略诸如head、display:none的元素
4.布局和绘制,重绘(repaint)和重排(reflow)
重排:若渲染树的一部分更新,且尺寸变化,就会发生重排;
重绘:部分节点需要更新,但不改变其他集合形状。如改变某个元素的颜色,就会发生重绘。附:
1.重绘和重排何时会发生:
(1)增加或删除DOM节点;
(2)display:none(重排并重绘);visibility:hidden(重排);
(3)移动页面中的元素;
(4)增加或修改样式;
(5)用户改变窗口大小,滚动页面等。2.如何减少重绘和重排以提升页面性能:
(1)不要一个个修改属性,应通过一个class来修改
错误写法:div.style.width="50px";div.style.top="60px";
正确写法:div.className+=" modify";(2)clone节点,在副本中修改,然后直接替换当前的节点;
(3)若要频繁获取计算后的样式,请暂存起来;
(4)降低受影响的节点:在页面顶部插入节点将影响后续所有节点。而绝对定位的元素改变会影响较少的元素;
(5)批量添加DOM:多个DOM插入或修改,应组成一个长的字符串后一次性放入DOM。使用innerHTML永远比DOM操作快。(特别注意:innerHTML不会执行字符串中的嵌入脚本,因此不会产生XSS漏洞)。
-
-
优化中会提到缓存的问题,问:静态资源或者接口等如何做缓存优化
-
最近遇到项目优化的问题,由于项目用到的框架,函数库比较多,导致首次需要加载3.6M的文件,那么问题来了,当网络很差的时候,很多文件就会timeout.然后就挂了。所以就开始用到离线缓存,一些文件静态的函数库开始缓存起来,一些经常更新的文件每次上线加版本号更新。
下面说说离线缓存,长话短说,很简单,只要完成简单的几个步骤
1,创建一个后缀名为.appcache的文件(如:list.appcache),里面配置项也很简单,同上
CACHE MANIFEST:这里面把你需要缓存的文件列出来,注意路径哈。
NETWORK:指定只有通过联网才能浏览的文件.一般写通配符 * 号(*代表除了在CACHE中的文件)
FALLBACK: 当上面文件尝试加载失败时,转换成下面列出的备用条目。
2.把list.appcache添加到页面中得HTML中
1<htmllang="zh-cn" manifest="/list.appcache" type="text/cache-manifest">3.我们可以通过调试器看 或者 chrome://appcache-internals/ 可以访问
![]()
小结:
离线访问对基于网络的应用而言越来越重要。虽然所有浏览器都有缓存机制,但它们并不可靠,也不一定总能起到预期的作用。HTML5 使用ApplicationCache 接口解决了由离线带来的部分难题。前提是你需要访问的web页面至少被在线访问过一次。
使用离线加载有几大优势,首先可以在没有网络的情况下访问缓存的资源,第二,可以加快网页加载速度。
此外, 如果报错,首先检测访问文件地址是否正确(大部分是这个原因导致),还有就是需要服务器支持,比如tomcat需要修改config文件(nginx我试过,是可以识别,不用额外修改)
1234<mime-mapping><extension>manifest</extension><mime-type>text/cache-manifest</mime-type></mime-mapping>
-
-
页面DOM节点太多,会出现什么问题?如何优化?












项目经历
这些大公司招聘都是高级工程师起步,所以对简历上的项目会刨根问底。很多很多问题都是由项目中拓展开的,像优化相关的东西,还有前面提到的require.js、promise、gulp,项目中用到了某项技术,高级工程师的要求是:不仅会用,更要知道其原理。对自己的提醒:项目中用到的技术,不能说完全掌握其原理吧,但大致的实现还是有必要了解一下的。
-
介绍一下你做的这个项目,进一步细问:整个项目有哪些模块,你主要负责哪些
-
你在项目中的角色
-
你在项目中做的最出彩的一个地方
-
碰到过什么样的困难,怎么解决的
-
(如果你是这个项目的负责人),任务怎么分配的,有没有关注过团队成员的成长问题
-
前端安全问题:CSRF和XSS
-
xss:跨站点攻击。xss攻击的主要目的是想办法获取目标攻击网站的cookie,因为有了cookie相当于有了session,有了这些信息就可以在任意能接进互联网的PC登陆该网站,并以其他人的身份登陆做破坏。预防措施防止下发界面显示html标签,把</>等符号转义。
csrf:跨站点伪装请求。csrf攻击的主要目的是让用户在不知情的情况下攻击自己已登录的一个系统,类似于钓鱼。如用户当前已经登陆了邮箱或bbs,同时用户又在使用另外一个,已经被你控制的网站,我们姑且叫它钓鱼网站。这个网站上面可能因为某个图片吸引你,你去点击一下,此时可能就会触发一个js的点击事件,构造一个bbs发帖的请求,去往你的bbs发帖,由于当前你的浏览器状态已经是登陆状态,所以session登陆cookie信息都会跟正常的请求一样,纯天然的利用当前的登陆状态,让用户在不知情的情况下,帮你发帖或干其他事情。预防措施,请求加入随机数,让钓鱼网站无法正常伪造请求。
-
其他
-
为什么选择做前端(我靠,我都快转前端两年了,还在问这个问题啊…)
-
你希望进入一个什么样的团队
-
你有什么问题想问我(面试官)的吗?
前前后后有两个月时间,暂时只回忆起这么多了,如果还有其他的,后期我会补上。
webpack其实也是必问的,由于我说还没使用过webpack,只是了解,写过demo,面试官就没问太深。如果你的简历中有提到webpack,请提前准备好,比如webpack打包原理、如何写webpack插件等。
面试阿里云那个岗位的时候,有要求算法和数据结构,有能力者多多准备吧。
阿里、网易的面试几乎都是围绕项目展开的,所以提醒自己搬砖的时候多想想、多看看,多站在一个高度去看整个项目:用到什么技术,技术实现原理是什么,项目框架怎么搭建的,采取安全措施了吗…
后记
有几个岗位感觉就是挂在了项目上。自己做过一个前后端分离项目,但是经过几次面试,发现这个项目还存在某些问题,比如:整个登录注册系统是不完善的,关于权限的处理上甚至是有很大缺陷的;这个项目的node层只是起到构建前端项目(gulp)、渲染index.ejs、代理转发api接口等作用,但是面试官指出说你这个node也太简单了,导致我都在怀疑这是个假的前后端分离…还是需要大神带多见见世面啊,求带…
虽然五次面试都没成功,但自己也收获了很多很多:认识了大牛hb,一个超有文艺气息的资深前端;多谢fw大大帮我内推阿里,十分感谢您对我的认可;也见到了平时只能在视频上看到的cjf老师,谢谢您的指点;对高级前端工程师所具备的技能有了更清晰的认识;肯定也增加了很多面试经验…
再好好提升一下,打算过段时间重新上阵,也祝自己多点好运气,早日进入心仪的企业,毕竟,当初来杭州的时候就是以网易、阿里为目标的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号