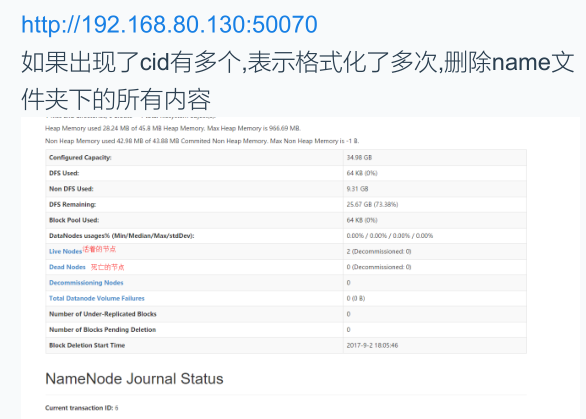
Hadoop集群搭建
1. 规范(配置三台虚拟机)
虚拟机命名规范是 master , slave1 , slave2
网络模式,NAT转换模式
2. 网络配置
所有的虚拟机设置为ipv4 手动设置,将子网掩码设置为

如果出现了后缀名是swp 的文件,表示正在编辑的文件没有正常退出,需要按照指定的目录将这个临时文件进行删除即可
3. 修改主机名称 vi /etc/sysconfig/network , 改为master , slave1 , slave2
source /etc/sysconfig/network 让刚才的设置生效
如果不行需要reboot
4. 设置host
在master主机的终端输入命令:vi /etc/hosts 然后添加
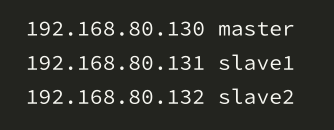
将修改后的hosts 文件发送到其他主机,进行远程拷贝scp /etc/hosts root@192.168.175.131:/etc/
5. 安装SSH
因为在每个主机中需要生成ssh目录,只要使用ssh登录过相应的主机,就会生成ssh目录在master节点通过ssh命令登录到相应的子节点中 ssh 192.168.80.131
输入exit进行退出,返回在master节点
每台机器首先在终端中输入命令: cd ~/.ssh
每台机器然后再终端中输入命令生成公钥和私钥文件: ssh-keygen -t rsa -P ''
每台机器然后在终端中输入命令将公钥文件拷贝到 authorized_keys 文件中: cp id_rsa.pub authorized_keys
在所有slaves节点上都执行命令,将每个slave中的authorized_keys内容追加到master中的相应的文件内容后:
cat ~/.ssh/authorized_keys | ssh root@192.168.80.130 'cat >> ~/.ssh/authorized_keys'
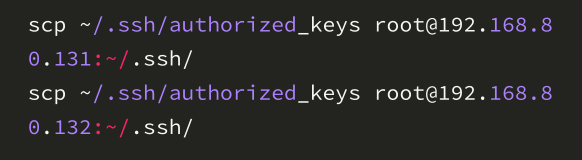
使用远程复制,将master中的 authorized_keys 拷贝到对应的 slave1 和 slave2
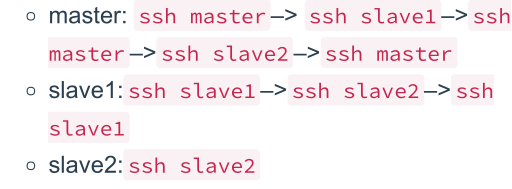
使用ssh命令,互相进行登录,出现提示的时候输入yes,以后每次登录就不需要再去输入密码对于
6. 安装jdk
利用filezilla将jdk上传到 /opt/SoftWare/java ,解压tar -xvf jdk-8u141-linux-x64.tar.gz
配置jdk环境变量,打开/etc/profile配置文件,将下面配置拷贝进去
export JAVA_HOME=/opt/SoftWare/Java/jdk1.8.0_141 export JRE_HOME=/opt/SoftWare/Java/jdk1.8.0_141/jre export CLASSPATH=.:$JRE_HOME/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
重新加载/etc/profile配置文件 source /etc/profile
java -version 或者 javac 或者 java 是否都识别,识别就证明安装成功。
7. 安装Hadoop
利用filezilla将hadoop-2.7.4.tar.gz上传到 /opt/SoftWare/Hadoop, 进行解压tar zxvf hadoop-2.7.3.tar.gz
(1)配置环境变量:
vi /etc/profile
在末尾添加:
export HADOOP_HOME=/opt/SoftWare/Hadoop/hadoop-2.7.4
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
保存后使新编辑的profile生效:
source /etc/profile
(2)配置hadoop
需要配置的文件的位置为/hadoop-2.6.4/etc/hadoop,需要修改的有以下几个
hadoop-env.sh
yarn-env.sh
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
slaves
其中
hadoop-env.sh和yarn-env.sh里面都要添加jdk的环境变量:
7.2.1 hadoop-env.sh中
# The java implementation to use.
export JAVA_HOME=/opt/SoftWare/Java/jdk1.8.0_141
# The jsvc implementation to use. Jsvc is required to run secure datanodes
# that bind to privileged ports to provide authentication of data transfer
# protocol. Jsvc is not required if SASL is configured for authentication of
# data transfer protocol using non-privileged ports.
#export JSVC_HOME=${JSVC_HOME}
7.2.2 yarn-env.sh中
# User for YARN daemons
export HADOOP_YARN_USER=${HADOOP_YARN_USER:-yarn}
# resolve links - $0 may be a softlink
export YARN_CONF_DIR="${YARN_CONF_DIR:-$HADOOP_YARN_HOME/conf}"
# some Java parameters
export JAVA_HOME=/opt/SoftWare/Java/jdk1.8.0_141
7.2.3 core-site.xml中
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/temp</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>
7.2.4 hdfs-site.xml中
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.web.ugi</name>
<value>supergroup</value>
</property>
</configuration>
7.2.5 mapred-site.xml中
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
7.2.6 yarn-site.xml中
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>
7.2.7 slaves中
slave1 slave2 master
7.2.8 拷贝hadoop安装文件到子节点 , 主节点上执行:
scp -r /opt/SoftWare/Hadoop/hadoop-2.7.4 root@slave1:/opt/SoftWare/Hadoop scp -r /opt/SoftWare/Hadoop/hadoop-2.7.4 root@slave2:/opt/SoftWare/Hadoop
7.2.9 拷贝profile到子节点
scp /etc/profile root@slave1:/etc/ scp /etc/profile root@slave2:/etc/
在两个子节点上分别使新的profile生效:
source /etc/profile
2.10 关闭防火墙
CentOS6.x 关闭防火墙: service iptables stop
CentOS7.x 关闭防火墙 systemctl stop firewalld
CentOS6.x 查看防火墙当前状态: service iptables status
CentOS7.x 查看防火墙当前状态: systemctl status firewalld
7.2.10 格式化主节点的namenode
主节点上进入/hadoop-2.7.4目录 然后执行: ./bin/hadoop namenode –format 新版本用下面的语句不用hadoop命令了 ./bin/hdfs namenode –format 提示:successfully formatted表示格式化成功
7.2.11 启动hadoop集群
启动集群,输入 ./sbin/start-all.sh 因为已经配置过了环境变量所以可以直接输入 start-all.sh
可以进入logs文件夹查看日志,查看日志的命令是 tail -100 日志文件
7.2.12 关闭hadoop集群
关闭集群 stop-all.sh
8. 登录