

Python正则表达式
python正则表达式(Regular Expression):
1、元字符的含义:
元字符是构造正则表达式的一种基本元素;以下为常用的元字符。
'.'表示任意字符:
作用:是匹配除“\n”以外的任何字符,也就是说,它是在一行中进行匹配。
“行”是以“\n”进行区分的。字符串有每行的末尾有一个“\n”,不过它不可见。
'abc'--->'a.'结果为:'ab'
'abc'--->'a.c'结果为:'abc'
注:匹配除换行符以外的任意字符;
\w含义:
匹配[a-zA-Z0-9_]-->1位字母,数字或_或汉字;
\W含义:
\W:匹配任意非数字和字母的字符,相当于[^a-zA-Z0-9_]
\s含义:
匹配任意的空白符;
\d的含义:
匹配任意十进制数,相当于[0-9]-->0123456789任意之一;
\D的含义:
\D:匹配任意非数字字符,相当于[^0-9];
\b的含义:
匹配单词的开始或结束;
'^'表示字符串开头:
'abc'--->'^abc'结果为:'abc';
'$'表示字符串结尾:
'abc'--->'abc$'结果为:'abc'
2、重复限定符
为了处理这些重复问题,正则表达式中一些重复限定符,把重复部分用合适的限定符替代。
'*'表示匹配前一个字符重复0次到无限次;等价于{0,}
'zo*'可以匹配到z, zo, zoo等
'+'表示匹配前一个字符重复1次到无限次;等价于{1,}
'zo+'可以匹配到zo, zoo等
注:'zo+'不能匹配'z'
'?'表示匹配前一个字符重复0次到1次
'zo?'可以匹配到z, zo
'*?','+?','??'前面的*,+,?等都是贪婪匹配,也就是尽可能多匹配;
后面加?号表示使其变成惰性匹配,非贪婪匹配;
abcccd--->abc*?--->ab
abcccd--->abc+?--->abc
abcccd--->abc??--->ab
{m}匹配前一个字符m次:
abcccd--->abc{3}d--->abcccd
例 1:匹配8位数字的QQ号码:
^\d{8}$
例 2:匹配1开头11位数字的手机号码:
^1\d{10}$
{m,}重复m次或更多次:
{m,n}匹配前一个字符m到n次
abcccd--->abc{2,3}d--->abcccd
例 1 匹配银行卡号码是14~18位的数字:
^\d{14, 18}$
{m,n}?匹配前一个字符m到n次,并且取尽可能少的情况
abcccd--->abc{2,3}?--->abc
3、转义
\对特殊字符进行转义,或者是指定特殊序列
a.c--->'a\.c'--->a.c
4、分组:
正则表达式中用小括号()来做分组,也就是括号中的内容作为一个整体。
如:匹配字符串中包含0到多个ab开头:
^(ab)*
5、条件或
正则用符号|来表示或,也叫分支条件,当满足正则里的分支条件的任何一种条件时,都会当成是匹配成功。
^(13[0-2]|15[56]|18[5-6]|145|176)\d{8}$
6、区间
正则提供一个元字符中括号[]来表示区间条件;
限定0到9可以写成:[0-9]
限定A-Z写成:[A-Z]
限定某些数字:[165]
下面,我们来改写下面的正则表达式:
^(130|131|132|155|156|185|186|145|176)\d{8}$
--->
^(130|131|132|155|156|185|186|145|176)\d{8}$
7、实例:正则表达式:
字符串:tel:086-0666-88810009999
原始正则:"^tel:[0-9]{1,3}-[0][0-9]{2-3}-[0-9]{8-11}$"
速记理解:开始"tel:普通文本"[0-9数字]{1至3位}"-普通文本"[0数字][0-9数字]{2至3位}"-普通文本"[0-9数字]{8至11位}结束"
等价简写后正则写法:"^tel:\d{1,3}-[0]\d{2,3}-\d{8,11}$"
8、贪婪模式和惰性模式区别:
贪婪模式:.+
1、贪婪匹配是先看整个字符串是否匹配;
2、如果不匹配,它会去掉字符串的最后一个字符,并再次尝试;
3、如果还不匹配,那么再去掉当前最后一个,直到发现匹配或不剩任何字符。
var str = 'aaa<div style="font-color:red;">123456</div>bbb' undefined str.match(/<.+>/); ["<div style="font-color:red;">123456</div>", index: 3, input: "aaa<div style="font-color:red;">123456</div>bbb", groups: undefined]
var str='abcdabceba' undefined str.match(/.+b/) ["abcdabceb", index: 0, input: "abcdabceba", groups: undefined]
第一次:(先看整个字符串是否是一个匹配) abcdabceba不匹配,然后去掉最后一个字符a;
第二次:(去掉最后一个字符后再匹配) abcdabceb匹配,返回abcdabceb;
惰性模式:.+?
var str = 'aaa<div style="font-color:red;">123456</div>bbb' undefined str.match(/<.+?>/); ["<div style="font-color:red;">", index: 3, input: "aaa<div style="font-color:red;">123456</div>bbb", groups: undefined]
str.match(/.+?b/)
["ab", index: 0, input: "abcdabceba", groups: undefined]
1、惰性匹配是从左侧第一个字符开始向右匹配, 先看第一个字符是不是一个匹配;
2、如果不匹配就加入下一个字符再尝式匹配, 直到发现匹配。
执行str.match(/.+?b/)
第一次:(读入左侧第一个字符)a,不匹配加一个再试;
第二次:ab匹配,返回ab。
9、零宽断言:
断言:正则断言,指明在指定内容的前面或是后面,会出现满足指定规则的内容。
零宽:就是没有宽度,断言只是匹配位置,不占字符,不会返回断言本身。
正则表达式的匹配有两种概念:一种是匹配字符,一种是匹配位置;
\b:匹配一个单词的边界,也就是单词和空格间的位置;
例:"er\b"可以匹配"never"中的"er";但是不能匹配"verb"中的"er"。
正则表达式的一种方法,用来查找在某些内容(但并不包括这些内容)之前或之后的东西;
^(匹配输入字行首),$(匹配输入字行尾),用于指定一个位置,这个位置应该满足一定的条件(即断言)
断言用来声明一个应该为真的事实,正则表达式中只有当断言为真时,才会继续进行匹配;
9.1、正向先行断言(正前瞻)
语法:(?=exp)
作用:匹配exp表达式前面的内容,不返回本身。
例1 "I'm singing while you're dancing."获取字符串中的sing和danc字符;
import re # 匹配的源文本
key = r"I'm singing while you're dancing." # 匹配的正则表达式 # ?=exp:零宽度正预测先行断言,匹配exp前面的位置 # ?=ing:匹配以ing结尾的单词的前面部分(除了ing以外的部分) p1 = r"\b\w+(?=ing\b)" # 编译正则表达式 pattern1 = re.compile(p1) # findall:返回的是所有符合要求的元素列表 # 打印结果:['sing', 'danc'] print(pattern1.findall(key))
import re # 匹配的源文本 key = "<span class=\"read-count\">阅读数:641</span>" # 匹配的正则表达式 p1 = r"\d+(?=</span>)" # 编译正则表达式 pattern1 = re.compile(p1) # ['641'] print(pattern1.findall(key))
9.2、正向后行断言(正后顾)
语法:(?<=exp)
作用:匹配exp表达式后面的内容,不返回本身。
import re # 匹配的源文本 key = r"reading a book" # 匹配的正则表达式 # ?<=exp 匹配exp后面的位置 # ?<=re 会匹配以re开头的单词的后半部分(除了re以外的部分) p1 = r"(?<=\bre)\w+\b" # 编译正则表达式 pattern1 = re.compile(p1) # 打印匹配的结果,findall查找结果返回的是列表 # ['ading'] print(pattern1.findall(key))
import re # 匹配的源文本 key = "<span class=\"read-count\">阅读数:641</span>" # 匹配的正则表达式 p1 = r"(?<=<span class=\"read-count\">阅读数:)\d+" # 编译正则表达式 pattern1 = re.compile(p1) # ['641'] print(pattern1.findall(key))
9.3、负向先行断言(负前瞻)
语法:(?!exp)
作用:匹配非exp表达式的前面的内容,不返回本身;
import re # 匹配的源文本 key = r"128e12x8654w856d45y99" # 匹配的正则表达式 # ?!exp 匹配后面跟的不是exp的位置 # 表示匹配三位数字,而且这三位数字的后面不能是数字; p1 = r"\d{3}(?!\d)" # 编译正则表达式 pattern1 = re.compile(p1) # 打印匹配的结果,findall查找结果返回的是列表 # ['128', '654', '856'] print(pattern1.findall(key))
import re # 匹配的源文本 key = r"abcd ef cabce ag abc" # 匹配的正则表达式 # ?!exp 匹配后面跟的不是exp的位置 # 匹配不能以abc开头的单词; p1 = r"\b((?!abc)\w+)\b" # 编译正则表达式 pattern1 = re.compile(p1) # 打印匹配的结果,findall查找结果返回的是列表 # ['ef', 'cabce', 'ag'] print(pattern1.findall(key))
import re # 匹配的源文本 key = "I love China, I love China very much" # 匹配的正则表达式 # 匹配不是very much前面的China p1 = r"China(?!\s\bvery\smuch\b)" # 编译正则表达式 pattern1 = re.compile(p1) # ['China'] print(pattern1.findall(key))
9.4、负后后行断言(负后顾)
语法:(?<!exp)
作用:匹配非exp表达式的后面内容,不返回本身。
例:(?<![a-z])\d{7},匹配不是小写字母开头的七位数字。
10、捕获和非捕获
捕获组:匹配子表达式的内容,把匹配结果保存到内存中,以数字编号或显示命名的组里。
10.1、数字编号捕获组:
语法:(exp)
解释:从表达式左侧开始,每出现一个左括号和它对应的右括号之间的内容为一个分组。
在分组中,第0组为整个表达式,第一组开始为分组。
固定电话:020-85653333
正则表达式为:(0\d{2})-(\d{8})
按照左括号的顺序,这个表达式有如下分组:

用Python来验证一下:
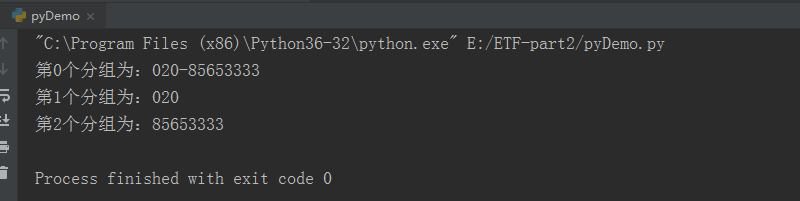
import re
# 匹配的源文本
str = "020-85653333"
# 定义正则表达式,匹配源文本
res = re.match(r"(0\d{2})-(\d{8})", str)
# 获取分组的长度,并循环
for i in range(len(res.groups())+1):
# 打印分组
print("第%d个分组为:"%i + res.group(i))
输出结果:
10.2、命名编号捕获组:
语法:(?P<name>exp)
解释:分组的命名由表达式中的name指定。
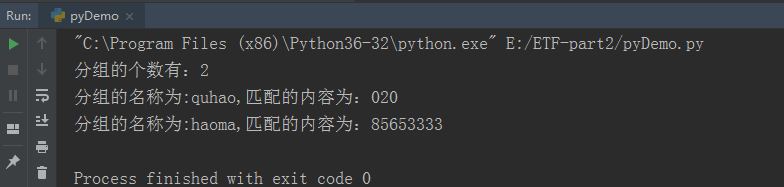
import re
# 匹配的源文本
str = "020-85653333"
# 定义正则表达式,匹配源文本
# 按名字分组,格式:?P<name>exp,定义正则表达式
res = re.match(r'(?P<quhao>0\d{2})-(?P<haoma>\d{8})', str)
print("分组的个数有:%d"%len(res.groups()))
# 打印分组quhao
print("分组的名称为:quhao,匹配的内容为:%s"%res.group('quhao'))
# 打印分组haoma
print("分组的名称为:haoma,匹配的内容为:%s"%res.group('haoma'))
10.3、非捕获组
语法:(?:exp)
解释:和捕获组刚好相反,用它来标识不需要捕获的分组;可以根据需要去保存你想要的分组。
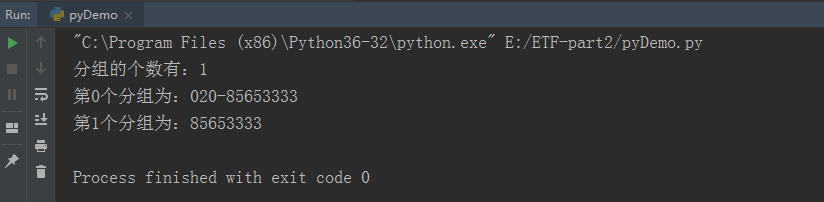
import re
# 匹配的源文本
str = "020-85653333"
# ?:exp不需要匹配的分组
res = re.match(r"(?:0\d{2})-(\d{8})",str)
# 打印分组的个数
print("分组的个数有:%d"%len(res.groups()))
# 循环分组的内容
for i in range(len(res.groups())+1):
# 打印分组的内容
print("第%d个分组为:"%i + res.group(i))
11、反向引用
根据捕获组的命名规则,反向引用可分为:
数字编号组反向引用:\k或\number
命名编号组反向引用:\k或\'name'
通常:捕获组和反向引用是一起使用的。
12、实例:获取a标签属性href里面的文本内容:
import re # 匹配的源文本 key = r"""<br/>您好,非常好,很开心认识你 <br/><a target=_blank href="www.baidu.com">百度一下</a>百度才知道 <br/><a target=_blank href="/view/fafa.htm">发发</a>最佳帅哥 <br/><a target=_blank href="/view/lili.htm">丽丽</a>最佳美女 <br/>""" # 匹配的正则表达式 # ?<=exp 匹配exp后面的位置 # ?=exp 匹配exp前面的位置 # .*? 惰性匹配,从前往后 p1 = r'(?<=href=").*?(?=">)' # 编译正则表达式 pattern1 = re.compile(p1) # 打印匹配的结果,findall查找结果返回的是列表 # ['www.baidu.com', '/view/fafa.htm', '/view/lili.htm'] print(pattern1.findall(key))
