通过clickhouse源码了解hive/spark的RoaringBitmap写入Clickhouse的bitmap

先说结论:要把hive上的bitmap数据同步到clickhouse的bitmap里面
参考连接:
https://blog.csdn.net/nazeniwaresakini/article/details/108166089
https://blog.csdn.net/qq_27639777/article/details/111005838
https://zhuanlan.zhihu.com/p/351365841
https://blog.csdn.net/yizishou/article/details/78342499
https://github.com/RoaringBitmap/CRoaring
1、Clickhouse的RoaringBitmap结构
目标是将Hive的Binary类型能顺利转成Clickhouse的Bitmap类型
Hive的Binary类型是二进制数组byte[]

Clickhouse的Bitmap类型是,一般是通过groupBitmap方式构建出来的,比如:
select series_id, groupBitmapState(toUInt32(dvid)) bitmap列 FROM dms_pds_flow_interest_dvid_city_day_all group by series_id
其中关键sql是:groupBitmapState,源码对应位置是:AggregateFunctionGroupBitmap.cpp注册的;
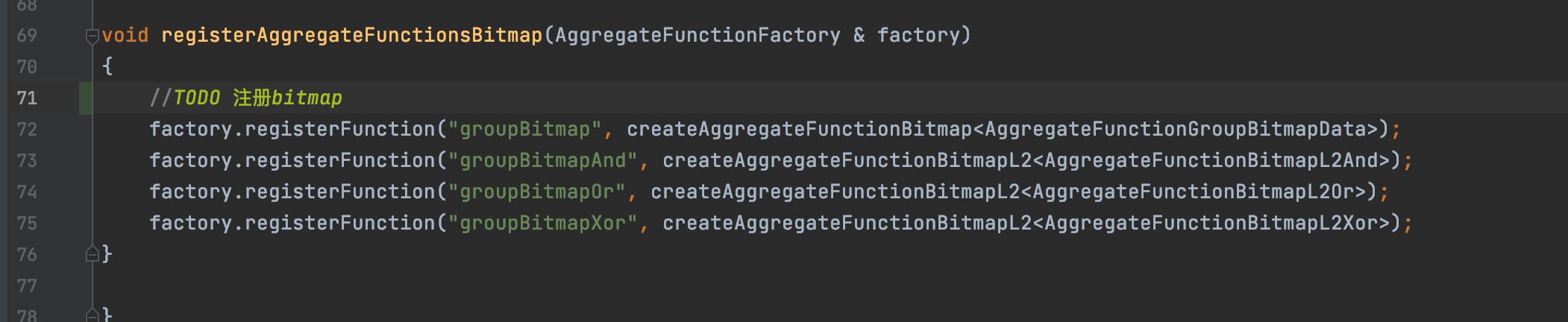
这个C++代码的关键点是:
createAggregateFunctionBitmap<AggregateFunctionGroupBitmapData>
代表通过函数:createAggregateFunctionBitmap来创建bitmap类型:AggregateFunctionGroupBitmapData
然后跟进这个AggregateFunctionGroupBitmapData类,文件(AggregateFunctionGroupBitmapData.h)
结构:

内部:
其中bitmap的一些计算函数逻辑,就是这个AggregateFunctionGroupBitmapData.h文件实现的;比如:
select bitmapOrCardinality(bitmap_a , bitmap_b) 是取两个bitmap的并集;
那么实现就是:

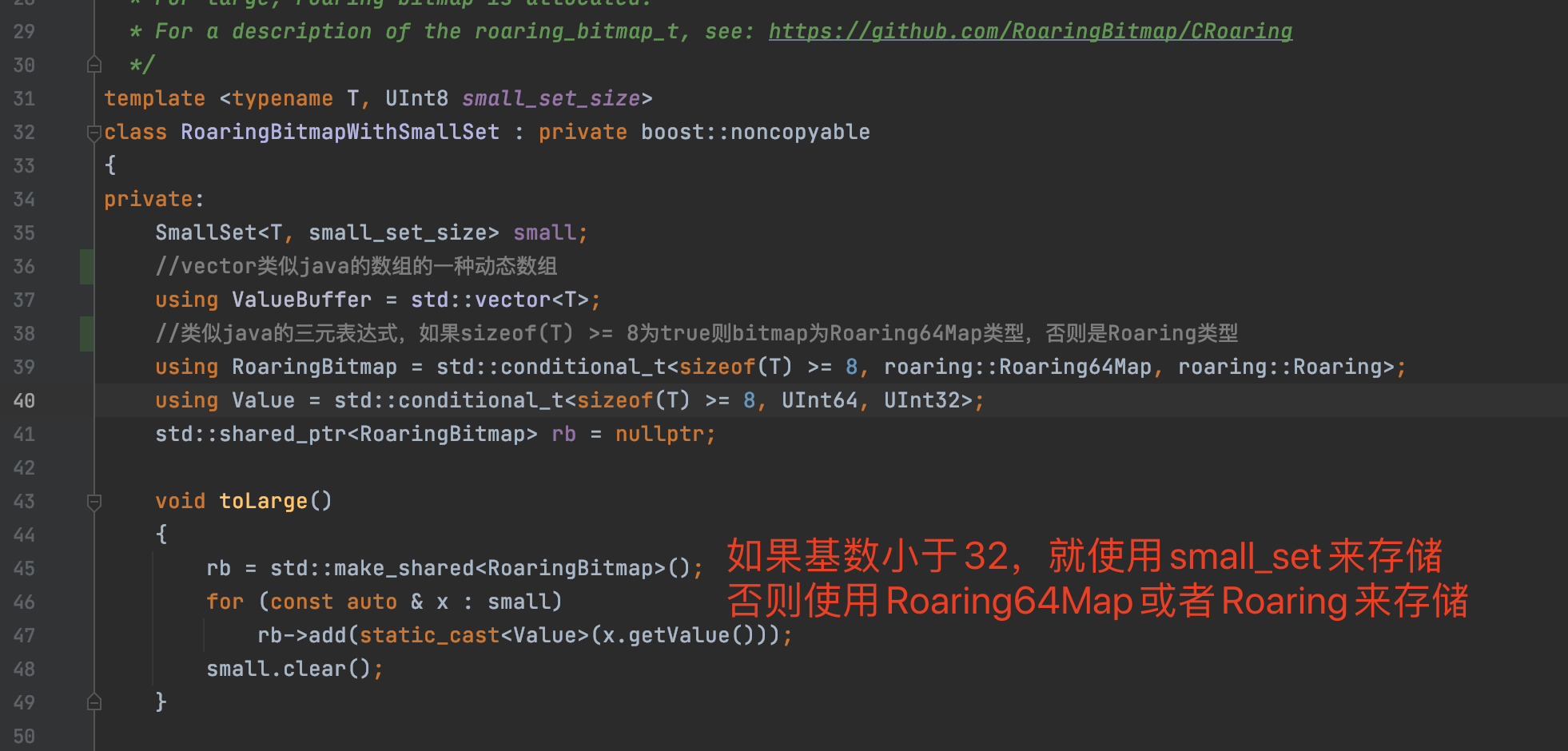
言归正传,根据Rbitmap的数据结构:
参考连接:https://zhuanlan.zhihu.com/p/351365841
1、首先,将 32bit int(无符号的)类型数据 划分为 2^16 个桶(即使用数据的前16位二进制作为桶的编号), 每个桶有一个Container(可以理解为容器也可以理解为这个桶,容器和桶在这里可以理解为一个东西,只是说法不一样而已) 来存放一个数值的低16位。 2、在存储和查询数值时,将数值 k 划分为高 16 位和低 16 位,取高 16 位值找到对应的桶, 然后在将低 16 位值存放在相应的 Container 中。这样说可能比较抽象不易理解,下面以一个例子来帮助大家理解。

大概意思是,在clickhouse的Rbitmap里面,为了优化存储空间,会将一个32位的数据,分成高16位和低16位;
高16位会被作为key存储到short[] keys中,低16位则被看做value
比如我要存储666这个数字,需要将666划分成高16位和低16位,通过高16位定位到当前桶是5,定位到竖着排列的桶未知后,在将低16位的值存储到横着排列的数组中;
之前看clickhouse源码中C++里面返回的roaring和roaring64map到底是啥,在看CRoaring源码,创建Rbitmap的地方:
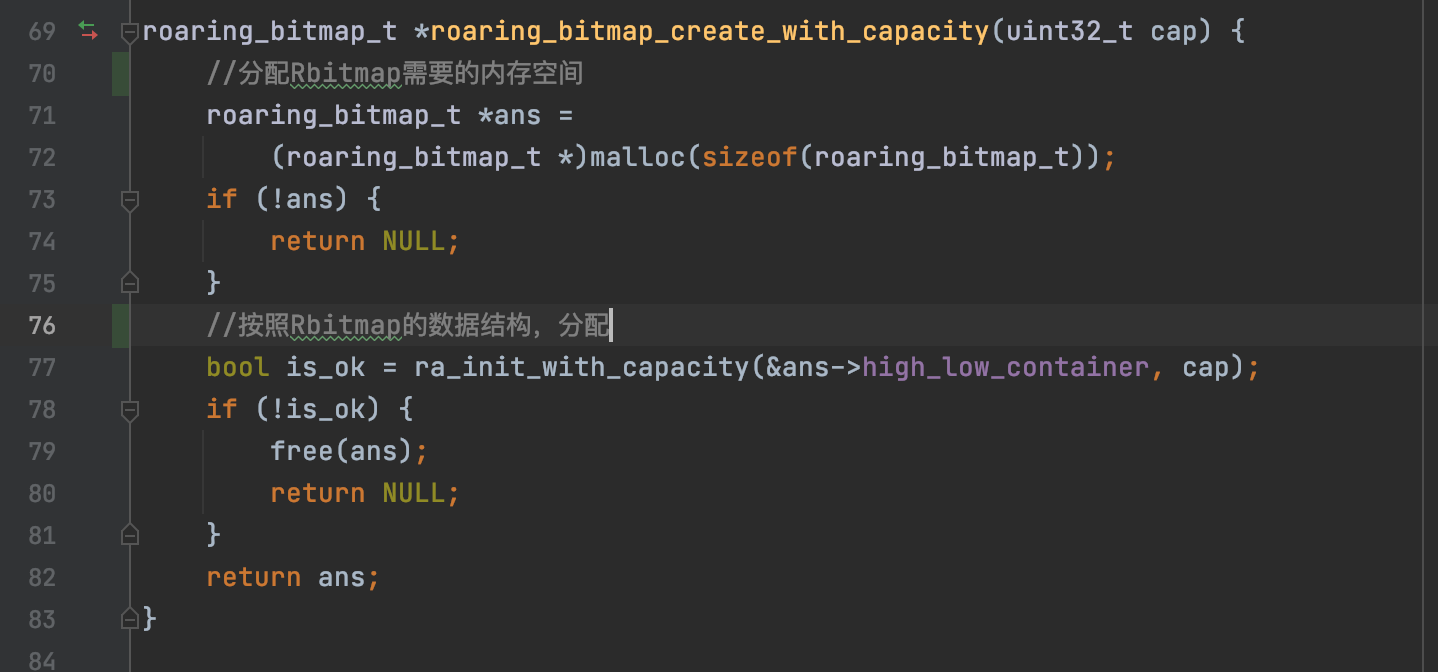
其中的关键点是:
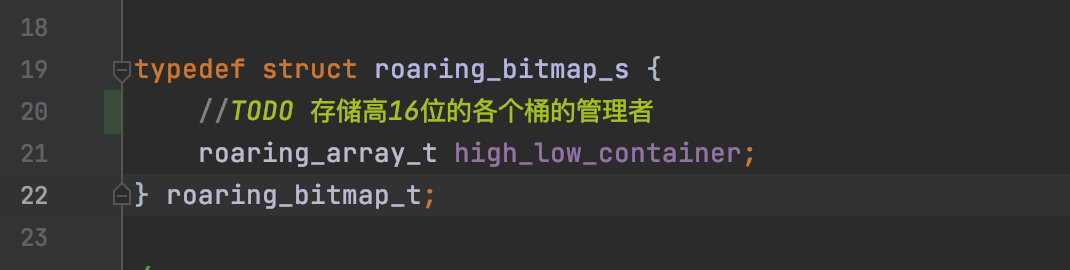
上面意思是定义一个结构体,类型是roaring_array_t , 变量名是:high_low_container
这个就是图片里面说的高16位和低16位的存储模型,然后查看roaring_array_t的结构:
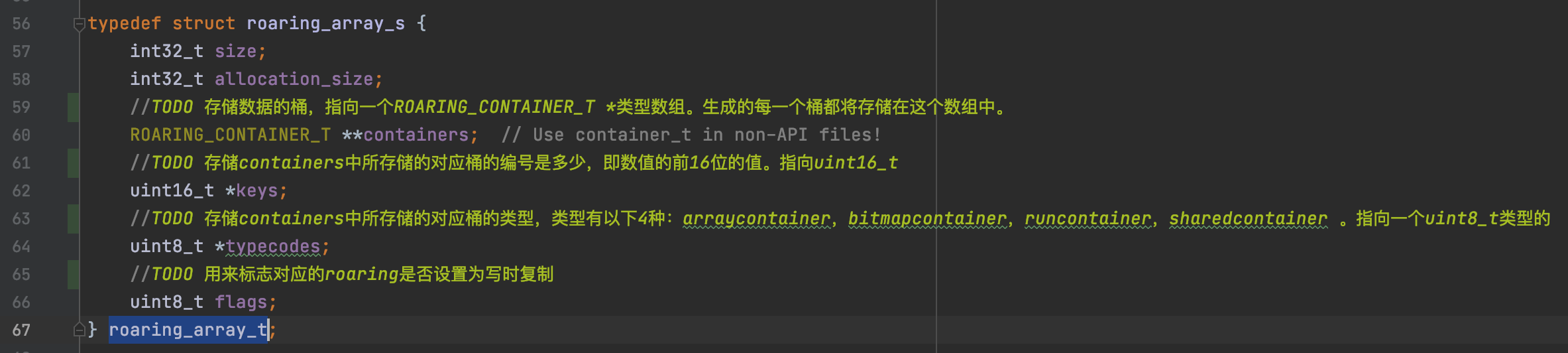
然后查看ROARING_CONTAINER_T,也就是低16位类型是,因为clickhouse是C++编写的,因此构建的数组其实是:struct container_s {}指向的各个子类
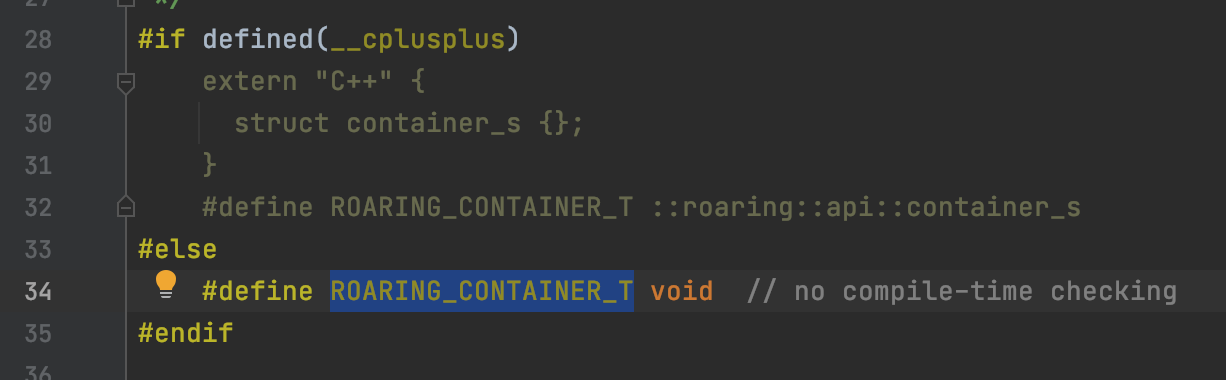
返回Clickhouse的源码,要开辟的子类就是:
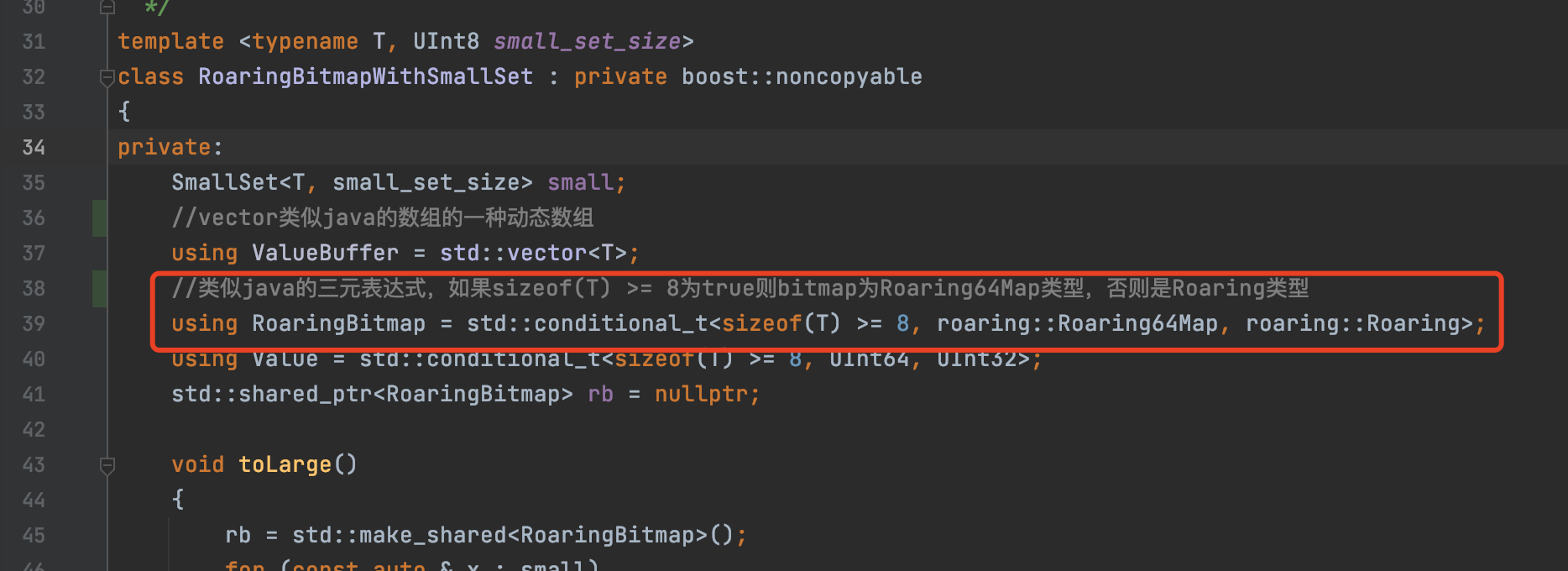
这样就又回到了Clickhouse的Rbitmap。虽然转了一圈,但是已经知道这个Rbitmap底层存储的其实是数组
2、hive或者sparksql里面的RoaringBitmap
参考hive制作bitmap的连接:https://github.com/sunyaf/bitmapudf
关键就是了解UDAF里面的函数:
// 输入输出都是Object inspectors public ObjectInspector init(Mode m, ObjectInspector[] parameters) throws HiveException; // AggregationBuffer保存数据处理的临时结果 abstract AggregationBuffer getNewAggregationBuffer() throws HiveException; // 重新设置AggregationBuffer public void reset(AggregationBuffer agg) throws HiveException; // 处理输入记录 public void iterate(AggregationBuffer agg, Object[] parameters) throws HiveException; // 处理全部输出数据中的部分数据 public Object terminatePartial(AggregationBuffer agg) throws HiveException; // 把两个部分数据聚合起来 public void merge(AggregationBuffer agg, Object partial) throws HiveException; // 输出最终结果 public Object terminate(AggregationBuffer agg) throws HiveException;
我们要兼容hive的Rbitmap和Clickhouse的Rbitmap,只需要关键方法:terminate到底返回了什么
查看代码:
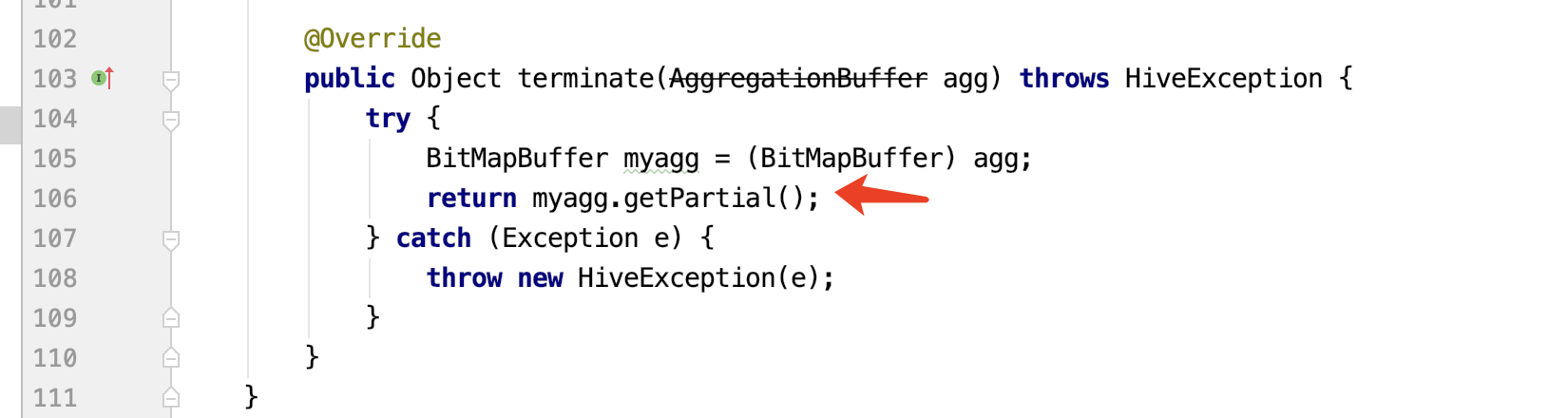
所以关键代码就是:myagg.getPartial()

hive里面返回的Rbitmap其实最终是java的二进制数组;
所以要想Hive的Rbitmap和Clickhouse的Rbitmap能够兼容,就是演变成:Hive的二进制数组如何有效的存储到Clickhouse里面
3、Clickhouse的Roaringbitmap是如何存储的
在回看Clickhouse的Rbitmap,比如看添加像Rbitmap里面添加内容。它的api是:
RoaringBitmap.add(1);
RoaringBitmap.add(2);
其源码是:
//如果基数超过32个,则会将数据存储到Rbitmap void toLarge() { //通过智能指针建立对象 rb = std::make_shared<RoaringBitmap>(); //C++ 里面的for循环,翻译成java就是:for (A x:small) for (const auto & x : small) //将smallSet的数据存储到Rbitmap里面 rb->add(static_cast<Value>(x.getValue())); //清空smallSet small.clear(); }
void add(T value) { //判断存储个数是否小于32 if (isSmall()) { if (small.find(value) == small.end()) { //如果插入的元素没有超过smallSet的容量,则添加到smallSet if (!small.full()) small.insert(value); //如果插入的元素个数超过了smallSet容量,则插入RoaringBitmap else { toLarge(); rb->add(static_cast<Value>(value)); } } } //如果超过32则按照 else { rb->add(static_cast<Value>(value)); } }
其中内部的写入是:
void write(DB::WriteBuffer & out) const { //判断基数,是否超过32来判断底层的存储 UInt8 kind = isLarge() ? BitmapKind::Bitmap : BitmapKind::Small; //写入一个UInt8的标识到buf中,0代表使用smallset 1代表使用RoaringBitmap writeBinary(kind, out); //smallSet的写入 if (BitmapKind::Small == kind) { small.write(out); } //Rbitmap的写入 else if (BitmapKind::Bitmap == kind) { //得到要写入内存的Rbitmap字节大小 auto size = rb->getSizeInBytes(); writeVarUInt(size, out);
//通过指针占有并管理另一对象 std::unique_ptr<char[]> buf(new char[size]); rb->write(buf.get()); out.write(buf.get(), size); } }
其中getSizeInBytes() 这个方法要去CRoaring里面找:
/** * How many bytes are required to serialize this bitmap (meant to be * compatible with Java and Go versions) * * Setting the portable flag to false enable a custom format that * can save space compared to the portable format (e.g., for very * sparse bitmaps). */ size_t getSizeInBytes(bool portable = true) const { if (portable) return api::roaring_bitmap_portable_size_in_bytes(&roaring); else return api::roaring_bitmap_size_in_bytes(&roaring); }
追下去的大概意思就是:
一个header头部大小
一个Ritmao里面Container数组存储元素个数
然后header ++ Container数组元素的字节大小
writeVarInt(size , out)的参考连接:https://blog.csdn.net/B_e_a_u_tiful1205/article/details/106064778
所以要写入Rbitmap,需要存储结构是:
1、writeBinary(1, out) : java中的Byte(1) 2、 auto size = rb->getSizeInBytes(); writeVarUInt(size, out); 就是像buffer中写入需要序列化的的字节大小 3、将RoaringBitmap转化成字节数组
参考一位大神的的,对应java结果就是:https://blog.csdn.net/qq_27639777/article/details/111005838
Byte(1), VarInt(SerializedSizeInBytes), ByteArray(RoaringBitmap)
4、将java的Rbitmap转成Clickhouse的Rbitmap
在clickhouse中构建一个bitmap:
select bitmapToArray(bitmapBuild([toUInt32(3), toUInt32(4), toUInt32(100)]));
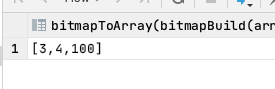
然后对bitmap做一个编码:
SELECT base64Encode(toString(bitmapBuild([toUInt32(3), toUInt32(4), toUInt32(100)])));
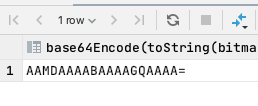
在反过来,将编码转回bitmap
1、构建表:
CREATE TABLE test_index.spark_bitmap_test( dt LowCardinality(String) COMMENT '日期', dim_type Int32 COMMENT '维度类型', dim_id Int32 COMMENT '纬度值', encode String COMMENT '编码', compare_encode AggregateFunction(groupBitmap, UInt32) MATERIALIZED base64Decode(encode) ) Engine = AggregatingMergeTree() PARTITION BY toYYYYMMDD(toDate(dt)) PRIMARY KEY (dim_type, dim_id) ORDER BY (dim_type, dim_id) SETTINGS index_granularity = 4;
2、将编码插入到bitmap
insert into test_index.spark_bitmap_test values ('2021-12-14' , 1 , 2370 , 'AAMDAAAABAAAAGQAAAA=');
3、查询:
select dt , dim_type , dim_id , encode , bitmapToArray(compare_encode) as arr , bitmapCardinality(compare_encode) as encode from test_index.spark_bitmap_test;

以上操作就是为了证明,如果在java中能够将bitmap进行编码,这样通过clickhouse的物化视图自动将编码字符串转成bitmap
结合之前分析的源码:
1、小于32的用smallSet存储 1):Byte(0) 2):Buffer(RoaringBitmap需要序列化的字节大小) 2、大于32的用RoaringBitmap存储 1):Byte(0) 2):VarInt(SerializedSizeInBytes) RoaringBitmap需要序列化的字节大小
3):RoaringBitmap的字节数组
综上转成java/scala代码:
import com.test.bitmap.VarInt import org.roaringbitmap.RoaringBitmap import org.roaringbitmap.buffer.{ImmutableRoaringBitmap, MutableRoaringBitmap} import java.io.{ByteArrayOutputStream, DataOutputStream} import java.nio.{ByteBuffer, ByteOrder} import java.util.Base64 object TestBitmapSeries { def main(args: Array[String]): Unit = { val rb = RoaringBitmap.bitmapOf(3, 4, 100) println("starting with bitmap " + rb) //当位图的基数少于32时,仅使用SmallSet存储 if (rb.getCardinality <= 32) { //分配缓冲区大小 val initBuffer = ByteBuffer.allocate(2 + 4 * rb.getCardinality) val bos = if (initBuffer.order eq ByteOrder.LITTLE_ENDIAN) initBuffer else initBuffer.slice.order(ByteOrder.LITTLE_ENDIAN) bos.put(new Integer(0).toByte) bos.put(rb.getCardinality.toByte) rb.toArray.foreach(i => bos.putInt(i)) val result = Base64.getEncoder.encodeToString(bos.array()) println("小于32的encode :"+result) } else { //rb.serializedSizeInBytes() 需要序列化的字节数 val seriesByteSize: Int = rb.serializedSizeInBytes() //VarInt.varIntSize返回编码需要的长度(二进制条件下:>>>) val varIntLen = VarInt.varIntSize(seriesByteSize) //初始化 val initBuffer: ByteBuffer = ByteBuffer.allocate(1 + varIntLen + rb.serializedSizeInBytes()) //字节高低序列,好像意思是在内存的存储方式 val bos = if (initBuffer.order eq ByteOrder.LITTLE_ENDIAN) initBuffer else initBuffer.slice.order(ByteOrder.LITTLE_ENDIAN) bos.put(new Integer(1).toByte) //TODO VarInt.putVarInt(rb.serializedSizeInBytes(), bos) val baos = new ByteArrayOutputStream() rb.serialize(new DataOutputStream(baos)) bos.put(baos.toByteArray()) val result: String = Base64.getEncoder.encodeToString(bos.array()) println("大于32的encode :"+result) } } }

结果和Clickhouse的编解码一致
5、利用sparkSql批量序列化RoaringBitmap,然后写入clickhouse
https://github.com/niutaofan/spark_bitmap.git

 浙公网安备 33010602011771号
浙公网安备 33010602011771号