logstash之Filter插件
1:grok正则表达式
grok**正则表达式是logstash非常重要的一个环节**;可以通过grok非常方便的将数据拆分和索引
语法格式:
(?<name>pattern)
?<name>表示要取出里面的值,pattern就是正则表达式
例子:收集控制台输入,然后将时间采集出来
input {stdin{}}
filter {
grok {
match => {
"message" => "(?<date>\d+\.\d+)\s+"
}
}
}
output {stdout{codec => rubydebug}}

还是按照上面的例子:4.19 is luck day 然后取出每一个字段
input {stdin{}}
filter {
grok {
match => {
"message" => "(?<date>\d+\.\d+)\s+(?<is>\w+)\s+(?<luck>\w+)\s+(?<day>\w+)"
}
}
}
output {stdout{codec => rubydebug}}
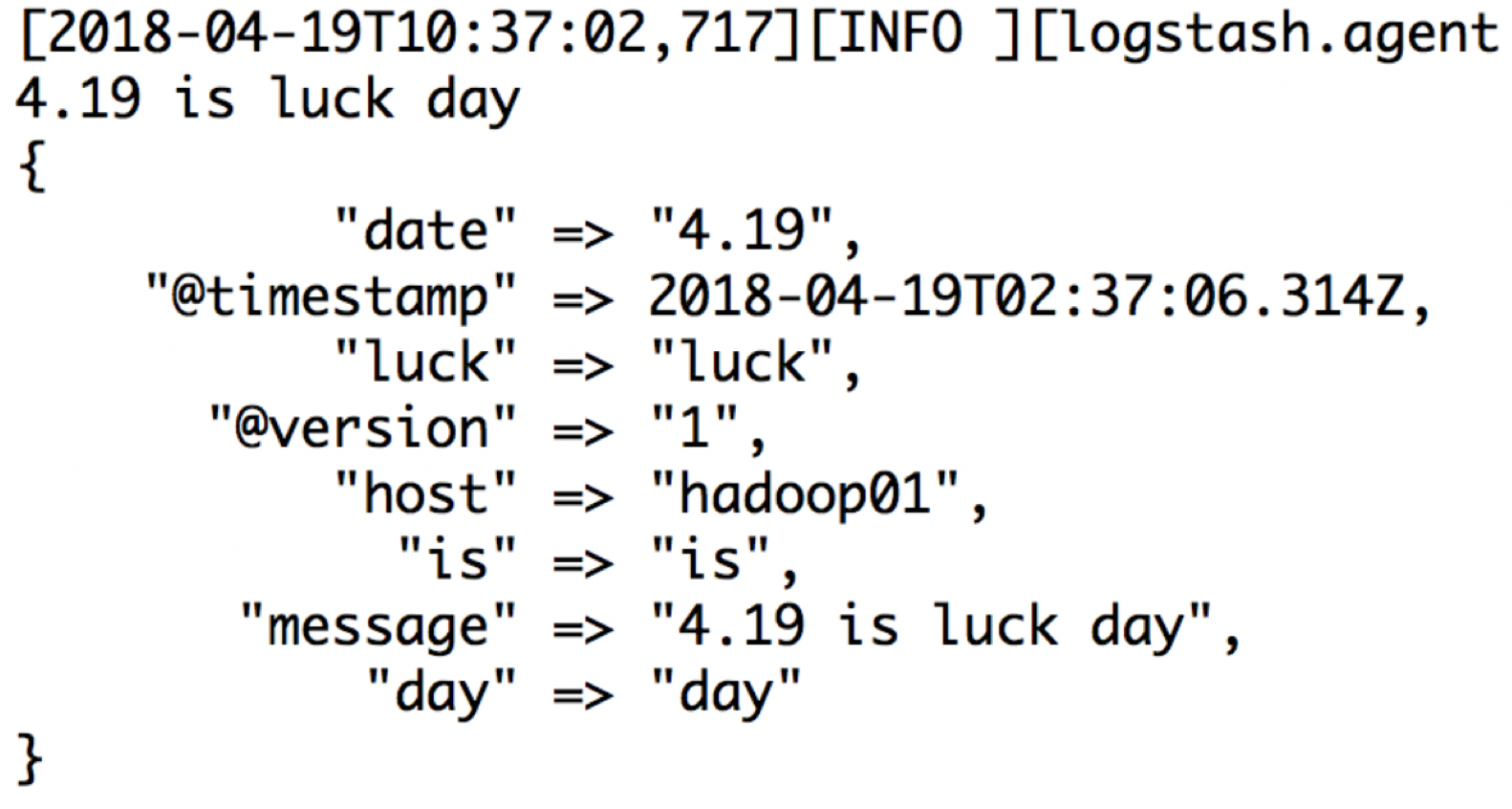
默认grok调用的是:/logstash-5.5.2/vendor/bundle/jruby/1.9/gems/logstash-patterns-core-4.1.1/patterns 这个目录下的正则
上面的例子,可以这样写:
input {stdin{}}
filter {
grok {
match => {
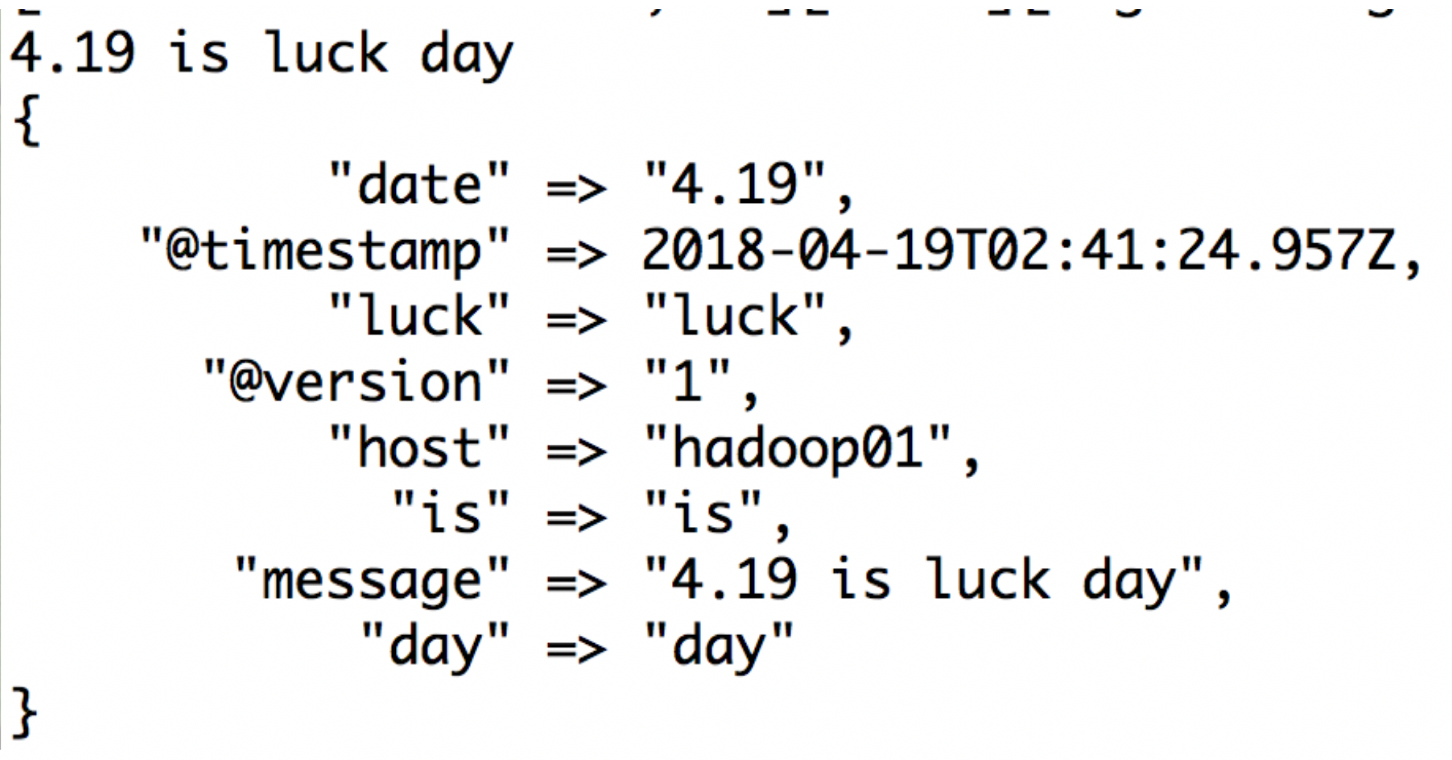
"message" => "%{NUMBER:date:float} %{WORD:is} %{WORD:luck} %{WORD:day}"
}
}
}
output {stdout{codec => rubydebug}}
结果截图:
Nginx打印出的日志一般格式是:
192.168.77.1 - - [10/May/2018:12:12:40 +0800] "GET /plugins/ml/ml.svg HTTP/1.1" 304 0 "http://hadoop01/app/kibana" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36" "-"
nginx这种日志是非格式化的,通常,我们获取到日志后,还要使用mapreduce或者spark做一下清洗操作,就是将非格式化日志编程格式化日志;
在清洗的时候,如果日志的数据量比较大,那么也是需要花费一定的时间的;
所以可以使用logstash的grok功能,将nginx的非格式化数据采集成格式化数据:
安装grok插件: bin/logstash-plugin install logstash-filter-grok
input {stdin{}}
filter {
grok {
match => {
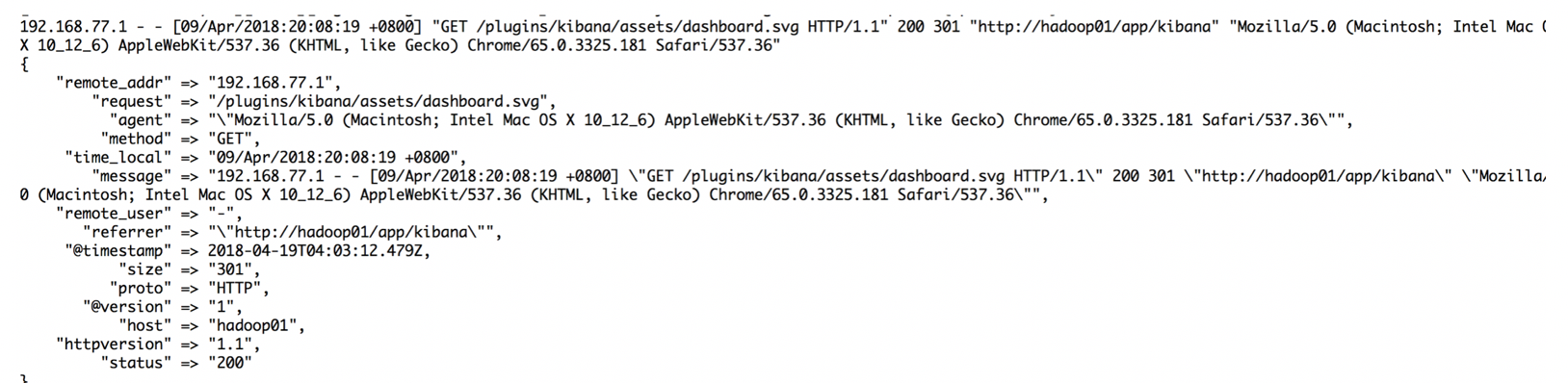
"message" => "%{IPORHOST:clientip} - - \[%{HTTPDATE:time_local}\] \"(?:%{WORD:request} %{NOTSPACE:request}(?:HTTP/%{NUMBER:httpversion})?|%{DATA:rawrequest})\" %{NUMBER:status} %{NUMBER:body_bytes_sent} %{QS:http_referer} %{QS:agent} %{NOTSPACE:http_x_forwarded_for}"
}
}
}
output {stdout{codec => rubydebug}}
【注意:】不同的nginx日志格式,应该对应不同的正则
启动:
bin/logstash -f /home/angel/logstash-5.5.2/logstash_conf/filter_4.conf
在控制台输入日志:
192.168.77.1 - - [10/May/2018:12:12:40 +0800] "GET /plugins/ml/ml.svg HTTP/1.1" 304 0 "http://hadoop01/app/kibana" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36" "-"
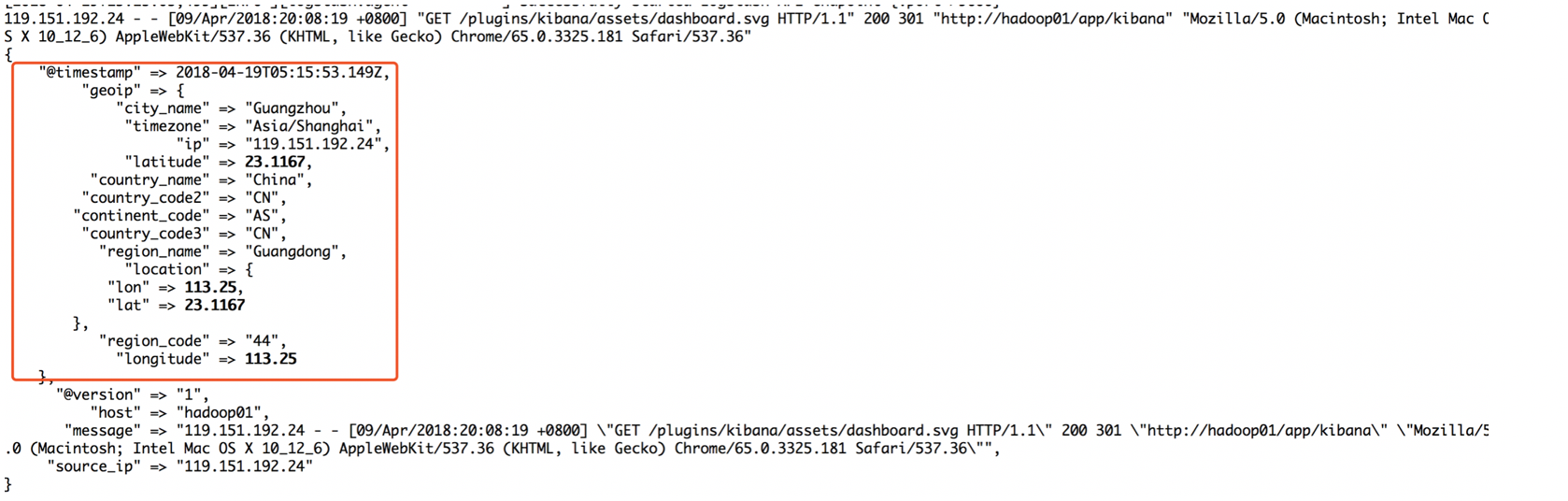
上面了解到logstash可以将nginx的非格式化日志进行格式化,那么在nginx的日志中有IP;往往会根据ip定位当前的地理位置,Logstash默认是安装了logstash-filter-geoip插件的
然后在kibana上以高德地图做展示
vim /conf/template/geoip.conf
input {stdin{}}
filter {
grok {
match => {
"message" => "%{IPORHOST:clientip} - - \[%{HTTPDATE:time_local}\] \"(%{WORD:request} %{NOTSPACE:request}(?:HTTP/%{NUMBER:httpversion})?|%{DATA:rawrequest})\" %{NUMBER:status} %{NUMBER:body_bytes_sent} %{QS:http_referer} %{QS:agent} %{NOTSPACE:http_x_forwarded_for}"
}
}
geoip{
source => "clientip". #设置解析的ip字段
target => “geoip”. #将解析的geoip保存在一个字段内
}
}
output {stdout{codec => rubydebug}}
启动:bin/logstash -f /usr/local/elk/logstash-5.5.2/conf/template/geoip.conf
向控制台输入nginx日志:
119.151.192.24 - - [10/May/2018:12:12:40 +0800] "GET /plugins/ml/ml.svg HTTP/1.1" 304 0 "http://hadoop01/app/kibana" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36" "-"
截图展示:
下载地址:http://geolite.maxmind.com/download/geoip/database/GeoLite2-City.mmdb.gz(课程内提供)
然后在编写的时候,指定下载的ip-经纬度库,同时,我们会发现返回的信息太多了,有很多不是我们想要的,那么也可以指定哪些是自己想要的:
input {stdin{}}
filter {
grok {
match => {
"message" => "%{IPORHOST:clientip} - - \[%{HTTPDATE:time_local}\] \"(?:%{WORD:request} %{NOTSPACE:request}(?: HTTP/%{NUMBER:httpversion})?|%{DATA:rawrequest})\" %{NUMBER:status} %{NUMBER:body_bytes_sent} %{QS:http_referer} %{QS:agent} %{NOTSPACE:http_x_forwarded_for}"
}
}
geoip{
source => "clientip"
database => "/home/angel/logstash-5.5.2/conf/GeoLite2-City.mmdb"
target => "geoip"
add_field => [ "[geoip][coordinates]", "%{[geoip][longitude]}" ]
add_field => [ "[geoip][coordinates]", "%{[geoip][latitude]}" ]
fields => ["country_name", "region_name", "city_name", "latitude", "longitude"]
# remove_field => [ "[geoip][longitude]", "[geoip][latitude]" ]
}
}
output {stdout{codec => rubydebug}}
6:Key-value拆分
在采集的日志中,往往出现类似于这样的URL:
https://mbd.baidu.com/newspage/data/landingsuper?context=%7B%22nid%22%3A%22news_6858188417104403771%22%7D&n_type=0&p_from=1
类似这种url,字段的信息是按照&拼接而成的,所以需要把这些url进行拆分
vim k_v_split.conf
input {
stdin {
}
}
filter {
kv {
prefix => "key_"
source => "message"
field_split => "&"
value_split => "="
}
}
output {
stdout{codec=>rubydebug}
}
启动:bin/logstash -f /usr/local/elk/logstash-5.5.2/conf/template/k_v_split.conf
向控制台输入:
https://www.baidu.com/s?wd=哈哈,这就是测试&a=1&b=2&c=3&d=4&e=5
结果截图:


