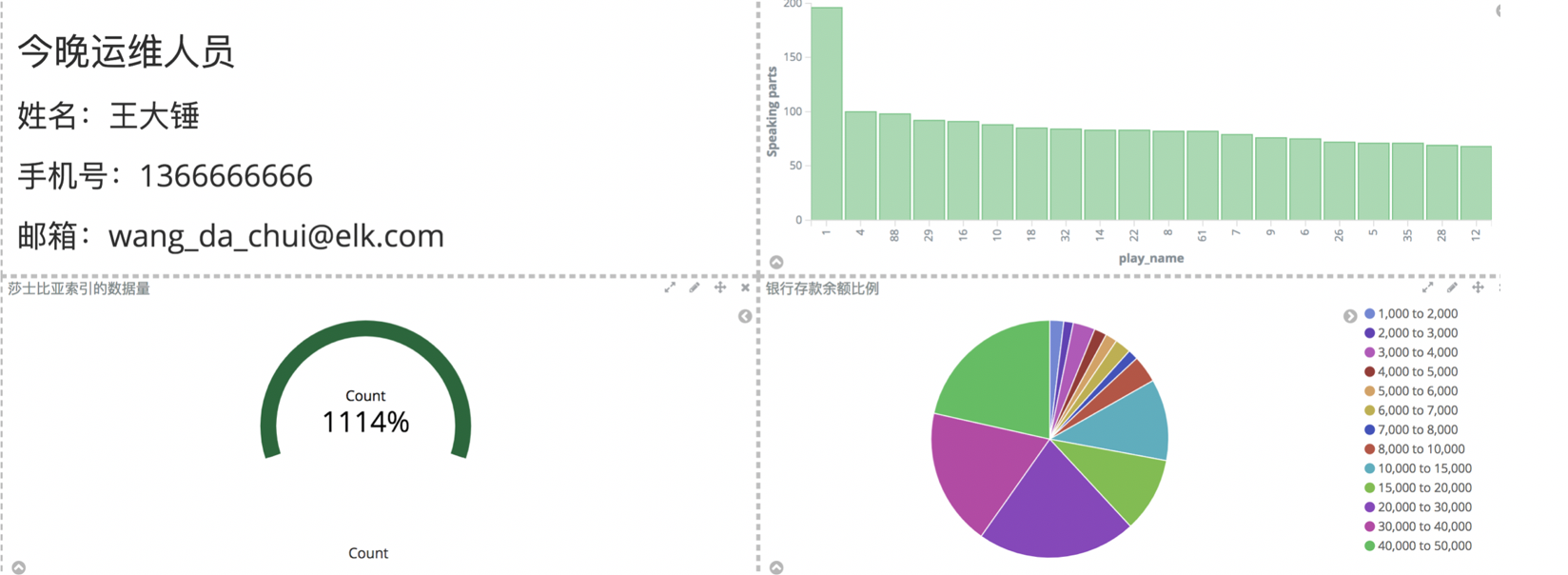
使用kibana构建各种图
以下命令来为莎士比亚数据集设置 mapping(映射):
curl -XPUT http://hadoop01:9200/shakespeare -d '
{
"mappings" : {
"_default_" : {
"properties" : {
"speaker" : {"type": "string", "index" : "not_analyzed" },
"play_name" : {"type": "string", "index" : "not_analyzed" },
"line_id" : { "type" : "integer" },
"speech_number" : { "type" : "integer" }
}
}
}
}
';
索引index
这个参数可以控制字段应该怎样建索引,怎样查询。它有以下三个可用值:
· no: 不把此字段添加到索引中,也就是不建索引,此字段不可查询
· not_analyzed:将字段的原始值放入索引中,作为一个独立的term,它是除string字段以外的所有字段的默认值。
· analyzed:string字段的默认值,会先进行分析后,再把分析的term结果存入索引中
该 mapping(映射)指定了数据集下列特质 :
字段解释:
1. speaker 字段是不分析的字符串。在这个 filed(字段)中的字符串被视为一个单独的单元,即使在这个 fileld(字段)中有多个单词。
2. 这同样适用于 play_name 字段。
3. line_id 和 speech_number 字段是整数。
日志数据集需要映射,通过将 **geo_point**``类型应用于这些字段,将日志中的 latitude(纬度)/longitude(纬度)对标记为地理位置。
使用以下命令建立日志 geo_point mappig(映射):
curl -XPUT http://hadoop01:9200/logstash-2015.05.18 -d '
{
"mappings": {
"log": {
"properties": {
"geo": {
"properties": {
"coordinates": {
"type": "geo_point"
}
}
}
}
}
}
}
';
curl -XPUT http://hadoop01:9200/logstash-2015.05.19 -d '
{
"mappings": {
"log": {
"properties": {
"geo": {
"properties": {
"coordinates": {
"type": "geo_point"
}
}
}
}
}
}
}
';
curl -XPUT http://hadoop01:9200/logstash-2015.05.20 -d '
{
"mappings": {
"log": {
"properties": {
"geo": {
"properties": {
"coordinates": {
"type": "geo_point"
}
}
}
}
}
}
}
';
1.3.2:导入数据
accounts(账目)数据集不需要任何 mapping(映射),所以在这一点上,我们已经准备好使用 Elasticsearch 的 bulk API 加载数据集,使用以下命令 :
curl -XPOST 'hadoop01:9200/bank/account/_bulk?pretty' --data-binary @accounts.json
curl -XPOST 'hadoop01:9200/shakespeare/_bulk?pretty' --data-binary @shakespeare.json
curl -XPOST 'hadoop01:9200/_bulk?pretty' --data-binary @logs.jsonl
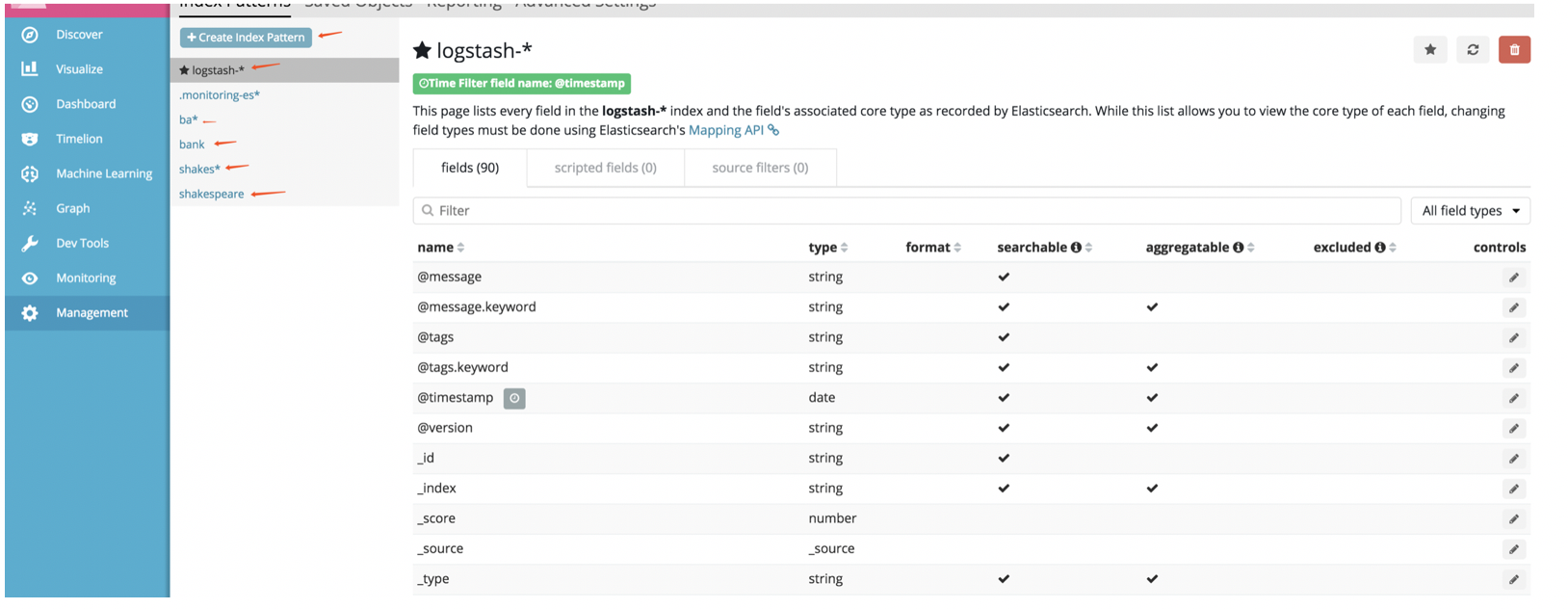
1.3.3:定义索引模式

使用create index Pattern创建一下索引:
Lostash-、ba、bank、shakes*、shakespeare
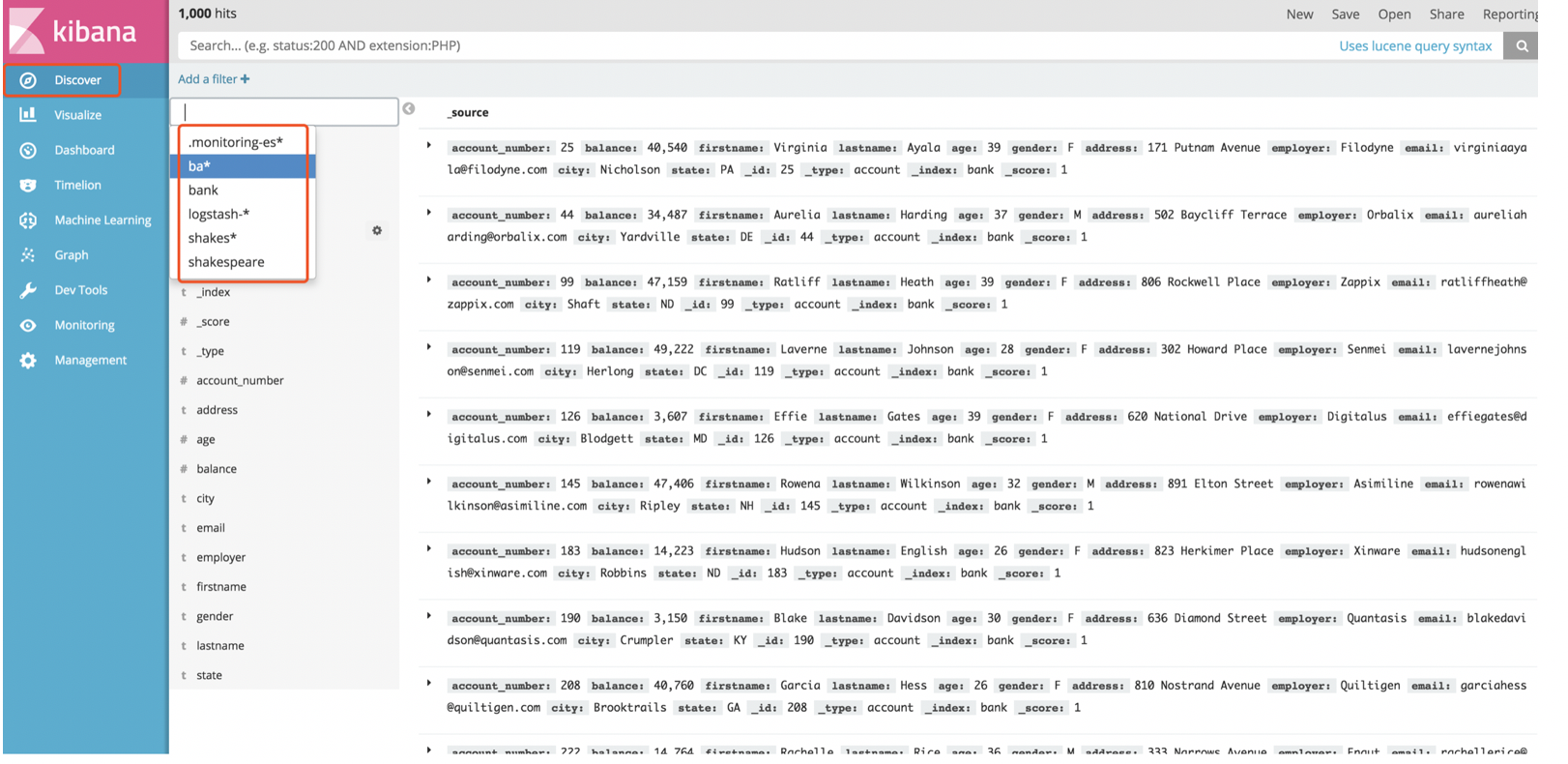
1.3.4:发现数据discover
1.3.5:可视化操作
1.3.5.1:创建饼图
1):步骤:Visualize--》create a visualization

2):选择饼图

选择bank:
按照账户余额balance进行饼图的划分

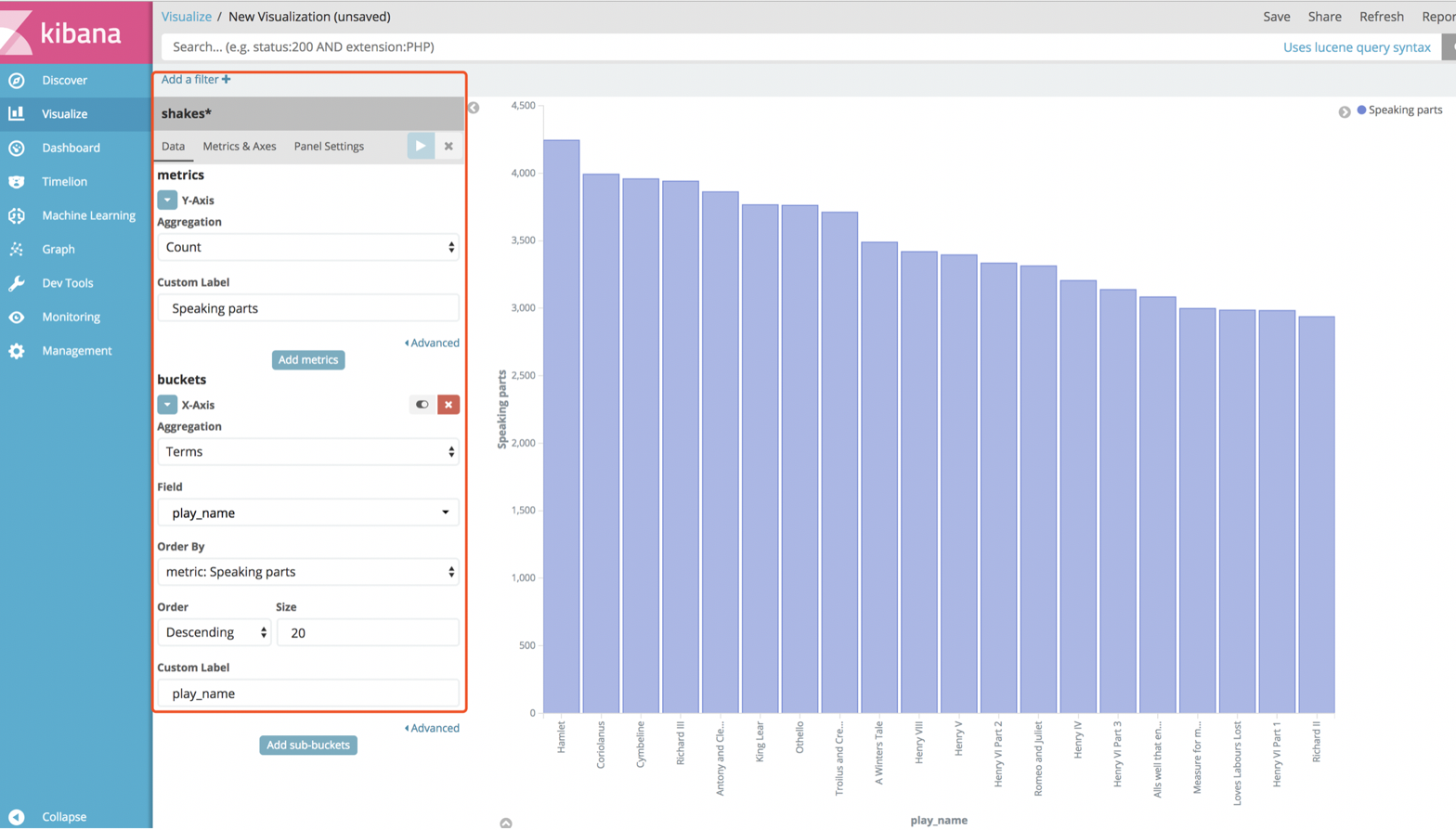
1.3.5.2:构建条形图
1):选择sharks*索引
2):展示每个演员的口语数量
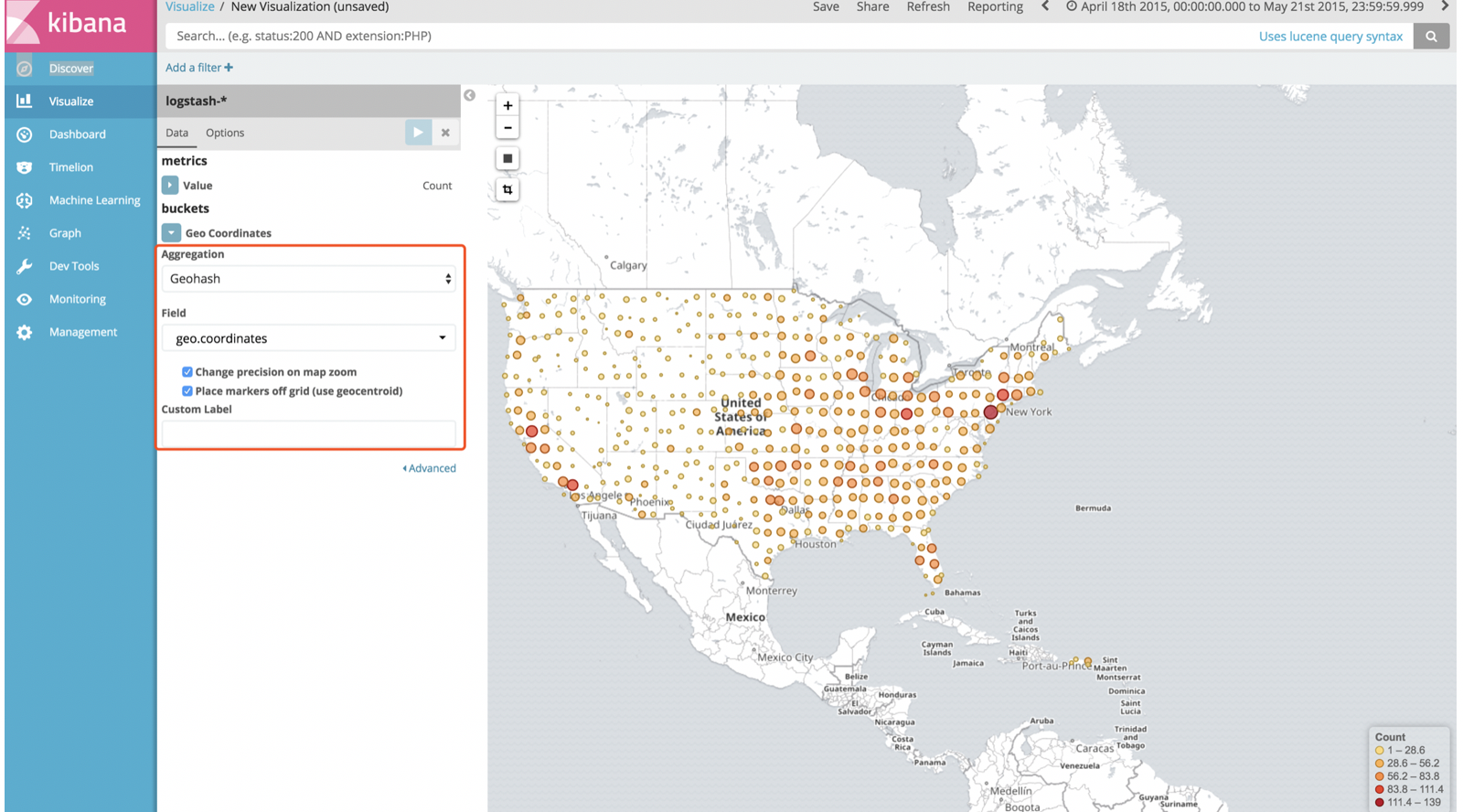
1.3.5.3:构建地图
展示采集的数据中logstash日志文件中,用户的地理位置