定期合并索引
Es是基于lucene构建的搜索引擎;lucene查询的快是因为倒排索引;
Es中经常会看到segments_q这样的文件,那么这个文件就是一个lucene的倒排索引;

倒排索引是由**词典 (Term Dictionary)和文档列表(Postings List)组成,lucene会在词典上做一层前缀索引(Term Index),然后把前缀索引全部存储在堆内存中(heap)**;
也可以使用restful查看当前的segment 大小:segment memory
查看一个索引所有segment的memory占用情况:
GET _cat/segments/.monitoring*?v&h=shard,segment,size,size.memory
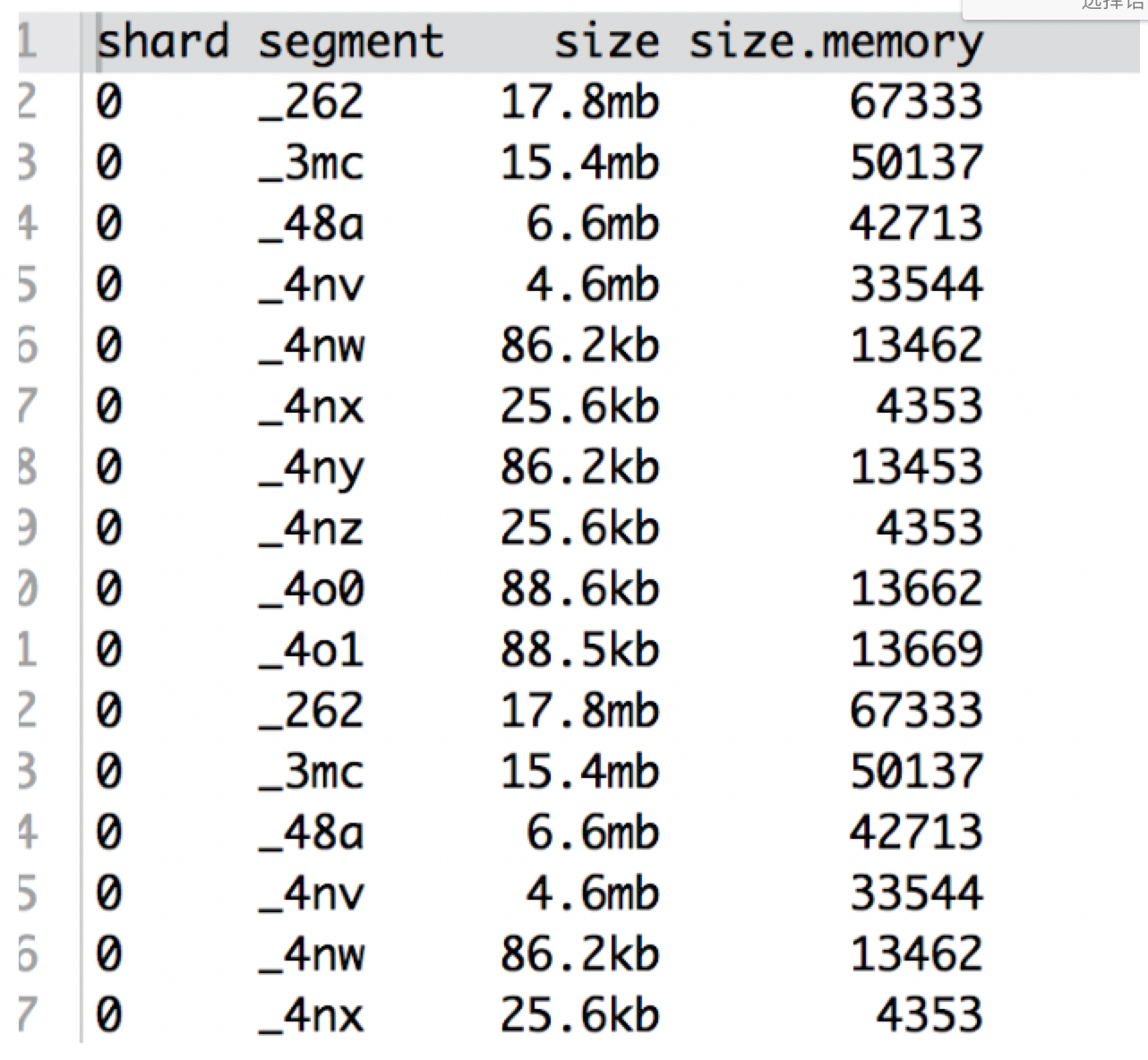
综上所述,segment越多,占用的内存(size.memory)也就越多;
所以要定期对索引进行合并优化;
合并的过程:
ES 会不断在后台运行任务,主动将这些零散的 segment 做数据归并,尽量让索引内只保有少量的,每个都比较大的,segment 文件。这个过程是有独立的线程来进行的,并不影响新 segment 的产生。
归并过程中(尚未完成的较大的 segment 是被排除在检索可见范围之外的)
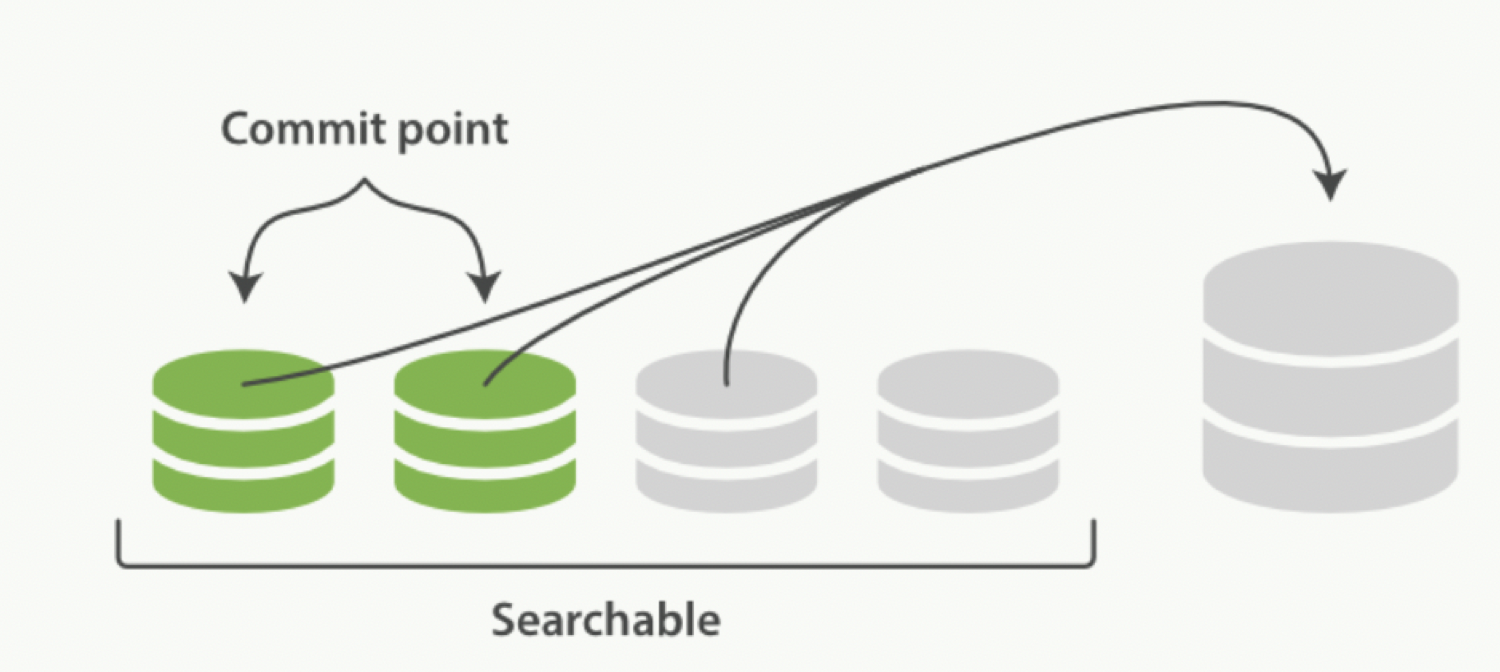
当归并完成,较大的这个 segment 刷到磁盘后,commit 文件做出相应变更,删除之前几个小 segment,改成新的大 segment。等检索请求都从小 segment 转到大 segment 上以后,删除没用的小 segment。这时候,索引里 segment 数量就下降了

索引的合并策略
通过命令进行索引的合并:
curl -XPOST http://hadoop01:9200/logstash/_forcemerge?max_num_segments=1
【注意】当索引的数量不是很大的情况下,max_num_segment可以1;
数据量很大,如果max_num_segments很小,会导致segment很大,合并segment会非常的耗时,如果用户这期间来检索数据,是检索不到这个合并期间的segment的,有可能会造成数据检索不到的现象;

