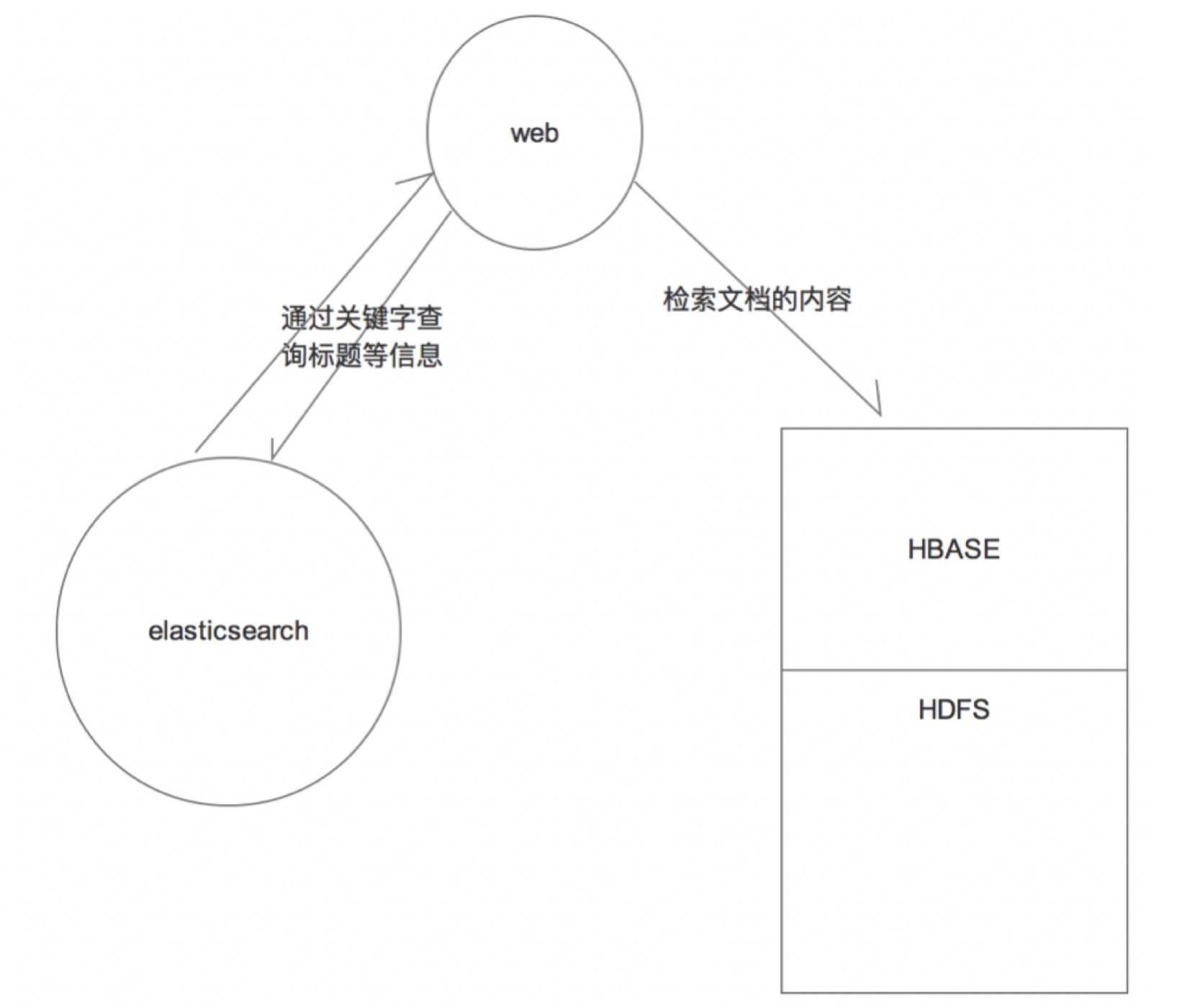
企业级技术解决方案:hbase+es
解决海量数据的存储,并且能够实现海量数据的秒级查询
Hbase是典型的nosql,是一种构建在HDFS之上的分布式、面向列的存储系统,在需要的时候可以进行实时的大规模数据集的读写操作;但是hbase的语法非常固话,即便在hbase之上嫁接了phoneix在应对复杂查询的时候,仍然力不从心;
所以说很多公司在历史遗留问题,最开始数据存储在hbase上,当业务越来越复杂,数据量越来越大的时候,使用hbase构建复杂的查询就很吃力了,甚至很多指标无法完成;
这个时候,我们就是用elasticsearch架构在hbase之上;
海量的数据存储使用hbase,数据的即席查询(快速检索)使用elasticsearch
通过elasticsearch+hbase就可以做到海量数据的复杂查询;
在操作之前,我们还要考虑:一批数据在elasticsearch中构建索引的时候,针对每一个字段要分析是否存储和是否构建索引;
实际生产中,一遍文章要分成标题和正文;但是正文的量是比较大的,那么我们一般会在,在hbase中存储正文(hbase本身就是做海量数据的存储);这样通过es的倒排索引列表检索到关键词的文档id,然后根据文档id在hbase中查询出具体的正文
(当然具体情况看具体需求)
分析,数据哪些字段需要构建索引:
文章数据(id、title、author、describe、conent)
| 字段名称 | 是否需要索引 | 是否需要存储 |
|---|---|---|
| Id | 默认索引 | 默认存储 |
| Title | 需要 | 需要 |
| Author | 看需求 | 看需求 |
| Dscribe | 需要 | 存储 |
| Content | 看需求(高精度查询,是需要的 ) | 看需求 |
| Time | 需要 | 需要 |
curl -XPUT http://hadoop01:9200/articles -d '
{
"settings":{
"number_of_shards":3,
"number_of_replicas":1
},
"mappings":{
"article":{
"dynamic":"strict",
"properties":{
"id":{"type": "string", "store": true},
"title":{"type": "string","store": true,"index" : "analyzed","analyzer": "ik_max_word"},
"from":{"type": "string","store": true},
"readCounts":{"type": "integer","store": true},
"content":{"type": "string","store": false,"index": "no"},
"times": {"type": "string", "index": "not_analyzed"}
}
}
}
} '
3: 架构设计