es之分词器和分析器
对于es来说,有内置的分析器(Analyzer)和分词器(Tokenizer)
1:分析器
ES内置分析器
| standard | 分析器划分文本是通过词语来界定的,由Unicode文本分割算法定义。它删除大多数标点符号,将词语转换为小写(就是按照空格进行分词) |
|---|---|
| simple | 分析器每当遇到不是字母的字符时,将文本分割为词语。它将所有词语转换为小写。 |
| keyword | 可以接受任何给定的文本,并输出与单个词语相同的文本 |
| pattern | 分析器使用正则表达式将文本拆分为词语,它支持小写和停止字 |
| language | 语言分析器 |
| whitespace | (空白)分析器每当遇到任何空白字符时,都将文本划分为词语。它不会将词语转换为小写 |
| custom | 自定义分析器 |
测试simple Analyzer:
POST _analyze
{
"analyzer": "simple",
"text": "today is 2018year 5month 1day."
}
custom(自定义)分析器接受以下的参数:
tokenizer | 内置或定制的标记器(也就是需要使用哪种分析器)。<br/>(需要) |
|---|---|
char_filter |
内置或自定义字符过滤器的可选阵列。 |
filter |
可选的内置或定制token过滤器阵列。 |
position_increment_gap |
在索引文本值数组时,Elasticsearch会在一个词的最后一个位置和下一个词的第一个位置之间插入“间隙”,以确保短语查询与不同数组元素的两个术语不匹配。 默认为100.有关更多信息 |
测试:
PUT /my_index/groups/1
{
"names": [ "John Abraham", "Lincoln Smith"]
}
做一下普通查询:
GET /my_index/groups/_search
{
"query": {
"match_phrase": {
"names": "Abraham Lincoln"
}
}
}
然后删除索引,重新添加:
PUT my_index
{
"mappings": {
"my_type": {
"properties": {
"names": {
"type": "text",
"position_increment_gap": 0
}
}
}
}
}
然后倒入数据:
PUT /my_index/groups/1
{
"names": [ "John Abraham", "Lincoln Smith"]
}
在做查询操作:
GET /my_index/groups/_search
{
"query": {
"match_phrase": {
"names": "Abraham Lincoln"
}
}
}
2:更新分析器
1:要先关闭索引
2:添加分析器
3:打开索引
1、 关闭索引
POST my_index/_close
2、 添加分析器
PUT my_index/_settings
{
"analysis": {
"analyzer": {
"my_custom_analyzer3": {
"type": "custom",
"tokenizer": "standard",
"char_filter": [
"html_strip"
],
"filter": [
"lowercase",
"asciifolding"
]
}
}
}
}
3、打开索引
POST my_index/_open
4、测试:
POST my_index/_analyze
{
"analyzer": "my_custom_analyzer",
"text": "Is this <b>网页 </b>?"
}
3:分词器
Es中也支持非常多的分词器
| Standard | 默认的分词器根据 Unicode 文本分割算法,以单词边界分割文本。它删除大多数标点符号。<br/>它是大多数语言的最佳选择 |
|---|---|
| Letter | 遇到非字母时分割文本 |
| Lowercase | 类似 letter ,遇到非字母时分割文本,同时会将所有分割后的词元转为小写 |
| Whitespace | 遇到空白字符时分割位文本 |
Standard例子:
POST _analyze
{
"tokenizer": "standard",
"text": "this is standard tokenizer!!!!."
}
Letter例子:
POST _analyze
{
"tokenizer": "letter",
"text": "today is 2018year-05month"
}
Whitespace例子:
POST _analyze
{
"tokenizer": "whitespace",
"text": "this is t es t."
}
4:更新分词器
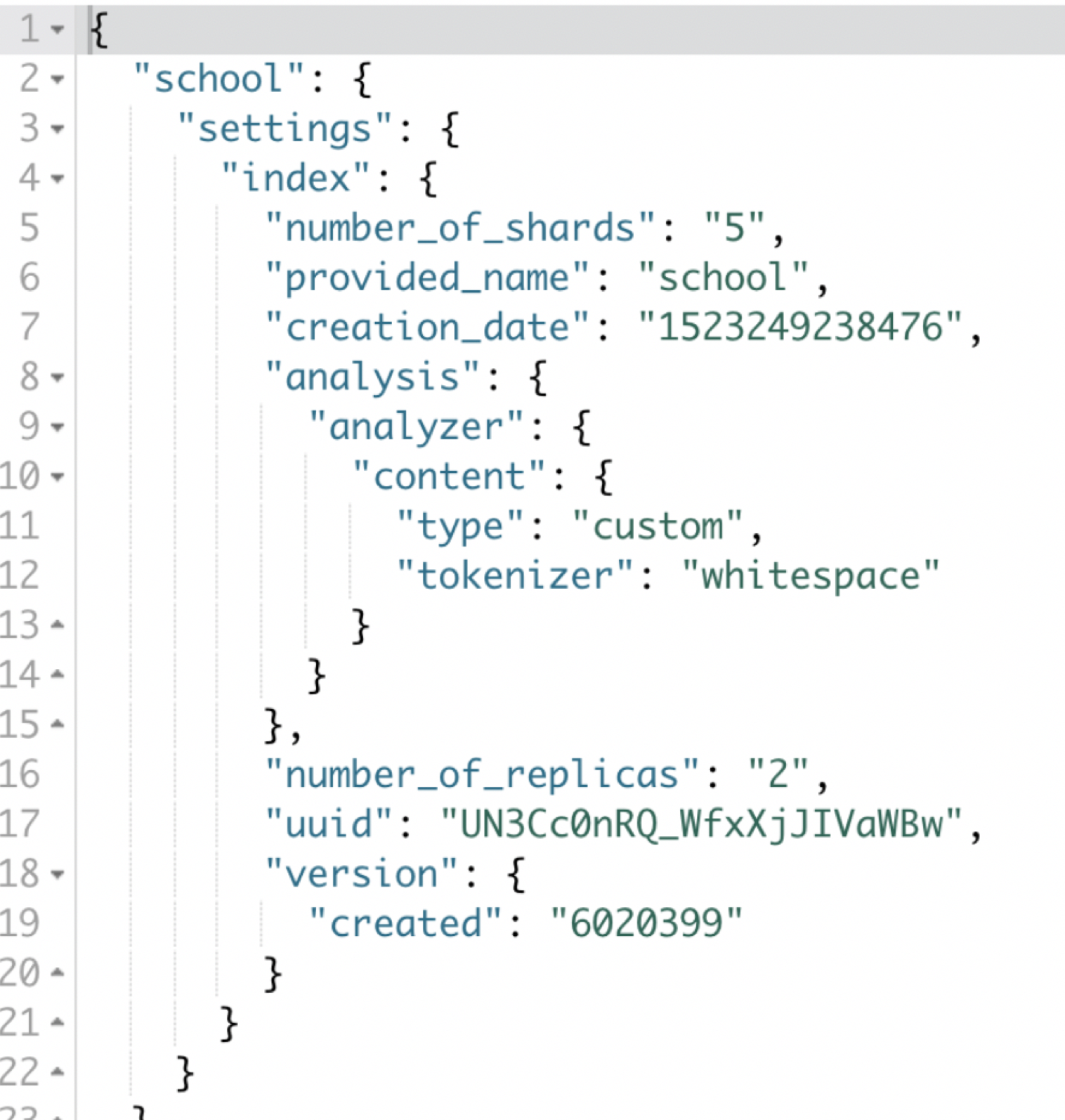
我们在创建索引之后可以添加分词器,比如想要按照空格的方式进行分词
【注意】
添加分词器步骤:
1:要先关闭索引
2:添加分词器
3:打开索引
POST school/_close
PUT school/_settings
{
"analysis" :
{
"analyzer" :
{
"content" : {"type" : "custom" , "tokenizer" : "whitespace"}
}
}
}
POST school/_open
获取索引的配置:
索引中包含了非常多的配置参数,我们可以通过命令进行查询
GET school/_settings