关于java中的伪共享的认识和解决

在并发编程过程中,我们大部分的焦点都放在如何控制共享变量的访问控制上(代码层面),但是很少人会关注系统硬件及 JVM 底层相关的影响因素;
CPU缓存
网页浏览器为了加快速度,会在本机存缓存以前浏览过的数据;
传统数据库或NoSQL数据库为了加速查询,常在内存设置一个缓存,减少对磁盘(慢)的IO。
随着CPU的频率不断提升,而内存的访问速度却没有质的突破,为了弥补访问内存的速度慢,充分发挥CPU的计算资源,提高CPU整体吞吐量,在CPU与内存之间引入了一级Cache。
随着热点数据体积越来越大,一级Cache L1已经不满足发展的要求,引入了二级Cache L2,三级Cache L3
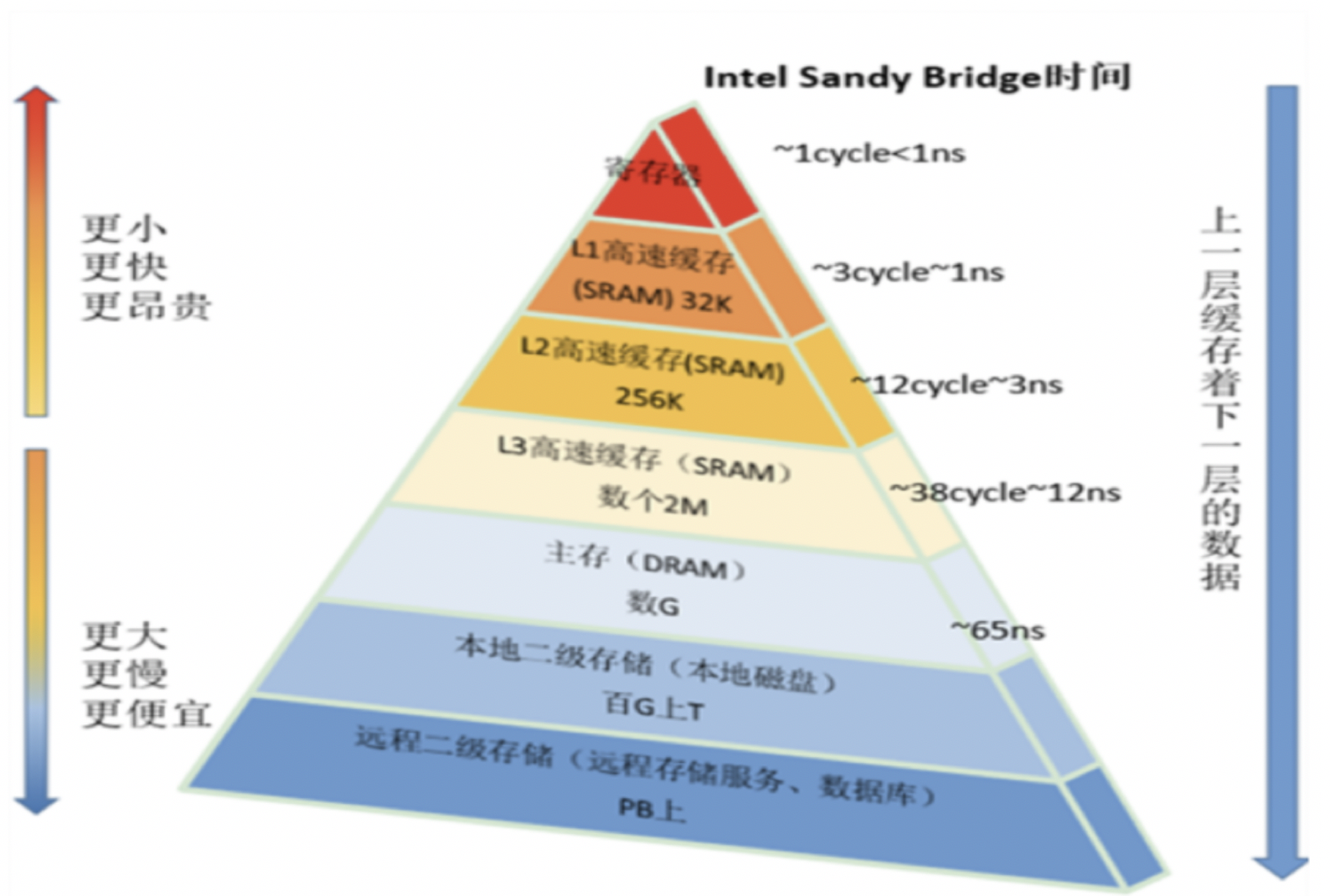
L1是最接近CPU的,它容量最小,例如32K,速度最快,每个核上都有一个L1 Cache(准确地说每个核上有两个L1 Cache,一个存数据 L1d Cache,一个存指令 L1i Cache)。
L2 Cache 更大一些,例如256K,速度要慢一些,一般情况下每个核上都有一个独立的L2 Cache;
L3 Cache 是三级缓存中最大的一级,例如12MB,同时也是最慢的一级,在同一个CPU插槽之间的核共享一个L3 Cache。
从图中的顺序可以看出来,寄存器 > L1 Cache速度 > L2 Cache速度 > L3 Cache > 主存
CPU 缓存的百度百科定义为:
CPU 缓存(Cache Memory)是位于 CPU 与内存之间的临时存储器,它的容量比内存小的多但是交换速度却比内存要快得多。
高速缓存的出现主要是为了解决 CPU 运算速度与内存读写速度不匹配的矛盾,因为 CPU 运算速度要比内存读写速度快很多,这样会使 CPU 花费很长时间等待数据到来或把数据写入内存。
缓存系统中是以缓存行(cache line)为单位存储的,程序的高效与否,关键就在于这个缓存行;
缓存行
有了上面对CPU的大概了解,我们来看看缓存行(Cache line)。缓存,是由缓存行组成的。一般一行缓存行有64字节。所以使用缓存时,并不是一个一个字节使用,而是一行缓存行、一行缓存行这样使用;换句话说,CPU存取缓存都是按照一行,为最小单位操作的。
这意味着,如果没有好好利用缓存行的话,程序可能会遇到性能的问题;
public class L1CacheMiss { private static final int RUNS = 10; private static final int DIMENSION_1 = 1024 * 1024; private static final int DIMENSION_2 = 62; private static long[][] longs; public static void main(String[] args) throws Exception { // Thread.sleep(10000); longs = new long[DIMENSION_1][]; for (int i = 0; i < DIMENSION_1; i++) { longs[i] = new long[DIMENSION_2]; for (int j = 0; j < DIMENSION_2; j++) { longs[i][j] = 0L; } } System.out.println("starting...."); final long start = System.currentTimeMillis(); long sum = 0L; for (int r = 0; r < RUNS; r++) { // 1---------------------------- // for (int j = 0; j < DIMENSION_2; j++) { // for (int i = 0; i < DIMENSION_1; i++) { // sum += longs[i][j]; // } // } // 2---------------------------- // 3---------------------------- for (int i = 0; i < DIMENSION_1; i++) { for (int j = 0; j < DIMENSION_2; j++) { sum += longs[i][j]; } } // 4---------------------------- } System.out.println("duration = " + (System.currentTimeMillis() - start)); } }
上面1-2代码和3-4代码几乎没什么不同,但是运行的速度却是千差万别,这就是有缓存行和没有缓存行的一个区别:
doubles (8) 和 longs (8) ints (4) 和 floats (4) shorts (2) 和 chars (2) booleans (1) 和 bytes (1) references (4/8) <子类字段重复上述顺序>
64位系统,Java数组对象头固定占16字节,而long类型占8个字节。所以16+8*6=64字节,刚好等于一条缓存行的长度(一个缓存行可以装填6个long类型的数据)
3-4行快得到原因:
3-4行运算,每次开始内循环时,从内存抓取的数据块实际上覆盖了longs[i][0]到longs[i][5]的全部数据(刚好64字节)。因此,内循环时所有的数据都在L1缓存可以命中,遍历将非常快。
1-2行慢的原因:
1-2行运算,每次从内存抓取的都是同行不同列的数据块(如longs[i][0]到longs[i][5]的全部数据),但循环下一个的目标,却是同列不同行(如longs[0][0]下一个是longs[1][0],造成了longs[0][1]-longs[0][5]无法重复利用
伪共享
伪共享的非标准定义为:缓存系统中是以缓存行(cache line)为单位存储的,当多线程修改互相独立的变量时,如果这些变量共享同一个缓存行,就会无意中影响彼此的性能,这就是伪共享。
很多人甚至认为,伪共享是并发编程无声的性能杀手,因为从代码中很难看清楚是否会出现伪共享。
伪共享示意图:
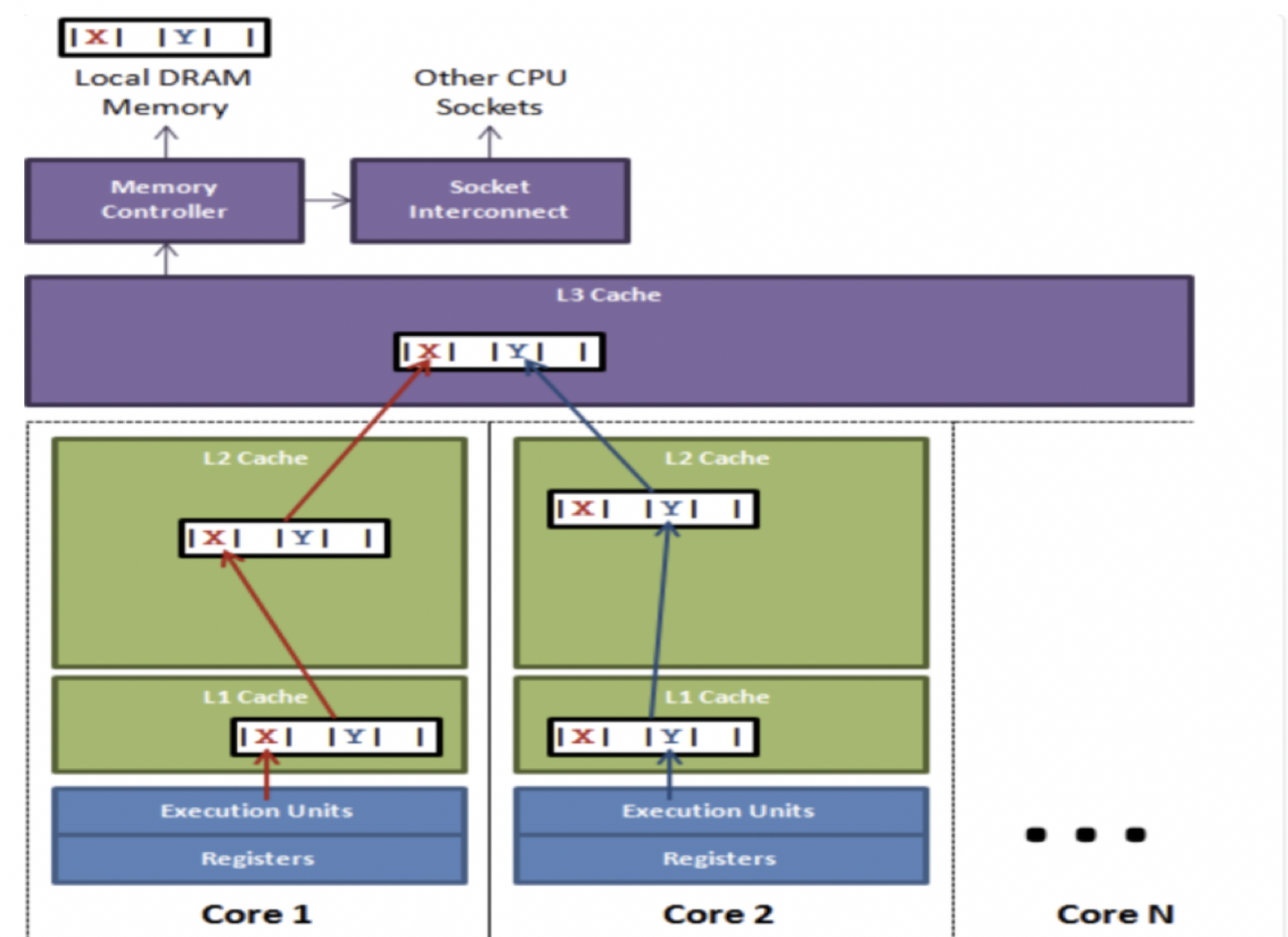
上图说明了伪共享的问题。
在核心1上运行的线程想更新变量X,同时核心2上的线程想要更新变量Y,不幸的是,这两个变量在同一个缓存行中。
每个线程都要去竞争缓存行的所有权来更新变量。
如果核心1获得了所有权,缓存子系统将会使核心2中对应的缓存行失效。
当核心2获得了所有权然后执行更新操作,核心1就要使自己对应的缓存行失效。
这会来来回回的经过L3缓存,大大影响了性能。如果互相竞争的核心位于不同的插槽,就要额外横跨插槽连接,问题可能更加严重。
在Java类中,最优化的设计是考虑清楚哪些变量是不变的,哪些是经常变化的,哪些变化是完全相互独立的,哪些属性一起变化。
举个例子:
public class Data{ long modifyTime; //value的修改时间 boolean flag;//标记 long createTime;//创建时间 char key ;//第一次创建就存在 int value; }
假如业务场景中,上述的类满足以下几个特点:
1. 当value变量改变时,modifyTime肯定会改变 2. createTime变量和key变量在创建后,就不会再变化。 3. flag也经常会变化,不过与modifyTime和value变量毫无关联。
在JDK1.8以前,我们一般是在属性间增加长整型变量来分隔每一组属性。
被操作的每一组属性占的字节数加上前后填充属性所占的字节数,不小于一个cache line的字节数就可以达到要求:(通过填充变量,使不相关的变量分开)
public class DataPadding{ long a1,a2,a3,a4,a5,a6,a7,a8;//防止与前一个对象产生伪共享 int value; long modifyTime; long b1,b2,b3,b4,b5,b6,b7,b8;//防止不相关变量伪共享; boolean flag; long c1,c2,c3,c4,c5,c6,c7,c8;// long createTime; char key; long d1,d2,d3,d4,d5,d6,d7,d8;//防止与下一个对象产生伪共享 }
在JDK1.8中,新增了一种注解@sun.misc.Contended,来使各个变量在Cache line中分隔开。 注意,jvm需要添加参数-XX:-RestrictContended才能开启此功能 用时,可以在类前或属性前加上此注释:
// 类前加上代表整个类的每个变量都会在单独的cache line中 @sun.misc.Contended @SuppressWarnings("restriction") public class ContendedData { int value; long modifyTime; boolean flag; long createTime; char key; } 或者这种: // 属性前加上时需要加上组标签 @SuppressWarnings("restriction") public class ContendedGroupData { @sun.misc.Contended("group1") int value; @sun.misc.Contended("group1") long modifyTime; @sun.misc.Contended("group2") boolean flag; @sun.misc.Contended("group3") long createTime; @sun.misc.Contended("group3") char key; }

