基于calcite做傻瓜式的sql优化(二)

因为主要想借助hive的思路来实现对sql的优化,所以这一篇主要是梳理一条sql在hive内部大概是什么样的生命周期
首先通过一张图看下,内部sql大概执行流:
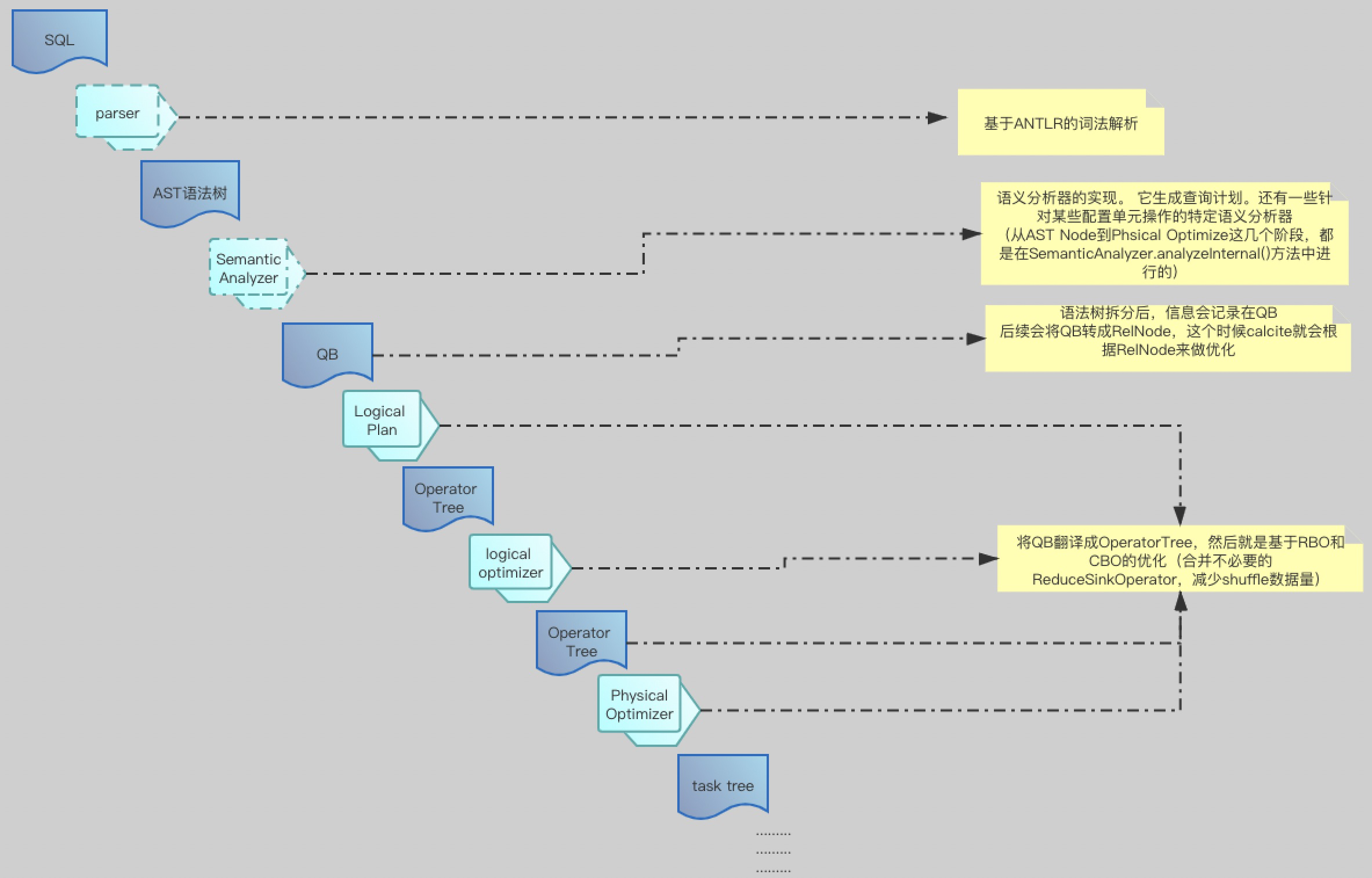
sql经过一系列的规则处理后,最后变成task tree,然后mapreduce通过task tree来执行job
接下来通过源码,看下是如何处理的!
另外我把编译好的hive(1.2.1版本)和hadoop(2.7.0版本)代码放在Git上,这样感兴趣的同学直接下载下来,就可以在本地debug跑
Hive编译后的源码:https://github.com/niutaofan/apache-hive-1.2.1-src.git
hadoop编译后的源码:链接:https://pan.baidu.com/s/1meF9MFHUAyY1Mk7mMOdqIg 密码:fwnh
1、大体流程
1)、Driver.compile 接收SQL , 然后通过:pd.parse(command)将SQL转换为ASTNode(这个过程包含了词法解析和语法解析)
1.1、ParseDriver.parse接收到sql语句,然后通过:r = parser.statement();解析了词法和语法
1.2、拿到解析后的HiveParser.statement_return,然后通过ASTNode tree = (ASTNode) r.getTree();获取到ASTNode
2)、通过sem.analyze(tree, ctx);从AST Node到Phsical Optimize这几个阶段,都是在SemanticAnalyzer.analyzeInternal()方法中进行的(语义解析、生成逻辑执行计划、优化逻辑执行计划等)
2.1、拿到ASTNode之后,通过SemanticAnalyzer.analyzeInternal()进行优化;
2.2、代码会调度到CalcitePlanner.analyzeInternal (这个方法内部会做 一个流程的判断:if (runCBO) 是否执行CBO优化),当然不管执行RBO还是CBO,最后调用的都是:SemanticAnalyzer.analyzeInternal()
2.3、在SemanticAnalyzer.analyzeInternal()方法中,首先基于ASTNode做了各种规则优化,根据需求包括了笼统的:RBO和CBO的优化,最终返回Operator
在Hive中,使用Calcite来进行核心优化,它将AST Node转换成QB,又将QB转换成Calcite的RelNode,在Calcite优化完成后,又会将RelNode转换成Operator Tree,说起来很简单,但这又是一条很长的调用链。
Calcite优化的主要类是CalcitePlanner,更加细节点,是在CalcitePlannerAction.apply()这个方法,CalcitePlannerAction是一个内部类,包括将QB转换成RelNode,优化具体操作都是在这个方法中进行的。
2、一条sql的源码之路
如果想debug的方式走读源码,那么需要如下几个步骤:
第一步:启动本地的hadoop源码(NameNode和DataNode)
第二步:启动hive的metastore服务

第三步:启动(Debug方式)CliDriver类
根据上文提示, sql在客户端执行后,会在Driver.compile 接收SQL , 然后通过:pd.parse(command)将SQL转换为ASTNode(这个过程包含了词法解析和语法解析)
eg. 执行一段sql(sql的数据,提前放入hive了) , 看下hive是如何解析和优化的
select * from ( select Sname, Sex, Sage, Sdept, count(1) as num from student_ext group by Sname, Sex, Sage, Sdept ) t1 where Sage > 10;
Driver.compile代码:

上图比较重要的点:
ParseDriver
Hive使用的是antlr来做词法、语法的解析工作,最终生成一棵有语义的ast树
而在Hive中调用antlr类的代码org.apache.hadoop.hive.ql.parse.ParseDriver类,通过ParseDriver.parse 可以返回HiveParser.statement_return
而这个HiveParser.statement_return通过强转,即可拿到ASTNode,如下图:

ps:这块儿存在极大的性能问题,后续会提到并改进
######################################################思考############################################################################################
如果需求是快速实现对用户输入的sql进行词法和语法解析,以便达到自定义或者sql优化的需求,那么可不可以利用上述内容进行重构???
答案是肯定可以的,而且非常简单,只需要知道,hive在做sql的词法和语法解析,使用的是哪个包(org.apache.hadoop.hive.ql.parse)
然后开启一个新的工程,导入hive-exec包即可
第一步:maven导入依赖
<dependency> <groupId>org.apache.hive</groupId> <artifactId>hive-exec-nt</artifactId> <version>1.2.1</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.7.1</version> </dependency>
第二步:代码编写
import org.apache.hadoop.hive.ql.parse.ASTNode; import org.apache.hadoop.hive.ql.parse.ParseDriver; import org.apache.hadoop.hive.ql.parse.ParseException; /** * Created by niutao */ public class Tests { public static void main(String[] args) { String sql = "SELECT `object_id`, `column1_id`, COUNT(DISTINCT `cookie`) AS `COOKIE`\n" + "FROM `D_DSJ_INDEX_PDS`.`INDEX2_FLW_COOKIE_INTEREST_OBJECT_D_FACT`\n" + "WHERE `dim_day` >= '2020-03-03' AND `dim_day` <= '2020-03-16' AND `series_id` = '692'\n" + "GROUP BY `object_id`, `column1_id`\n" + "ORDER BY COUNT(DISTINCT `cookie`) IS NULL DESC, COUNT(DISTINCT `cookie`) DESC\n" + "LIMIT 200"; //1、导入模仿hive,导入ParseDriver ParseDriver pd = new ParseDriver(); //2、解析sql try { ASTNode ast = pd.parse(sql); //3、测试,打印解析树 System.out.println(ast.dump()); } catch (ParseException e) { e.printStackTrace(); } } }
打印 结果:
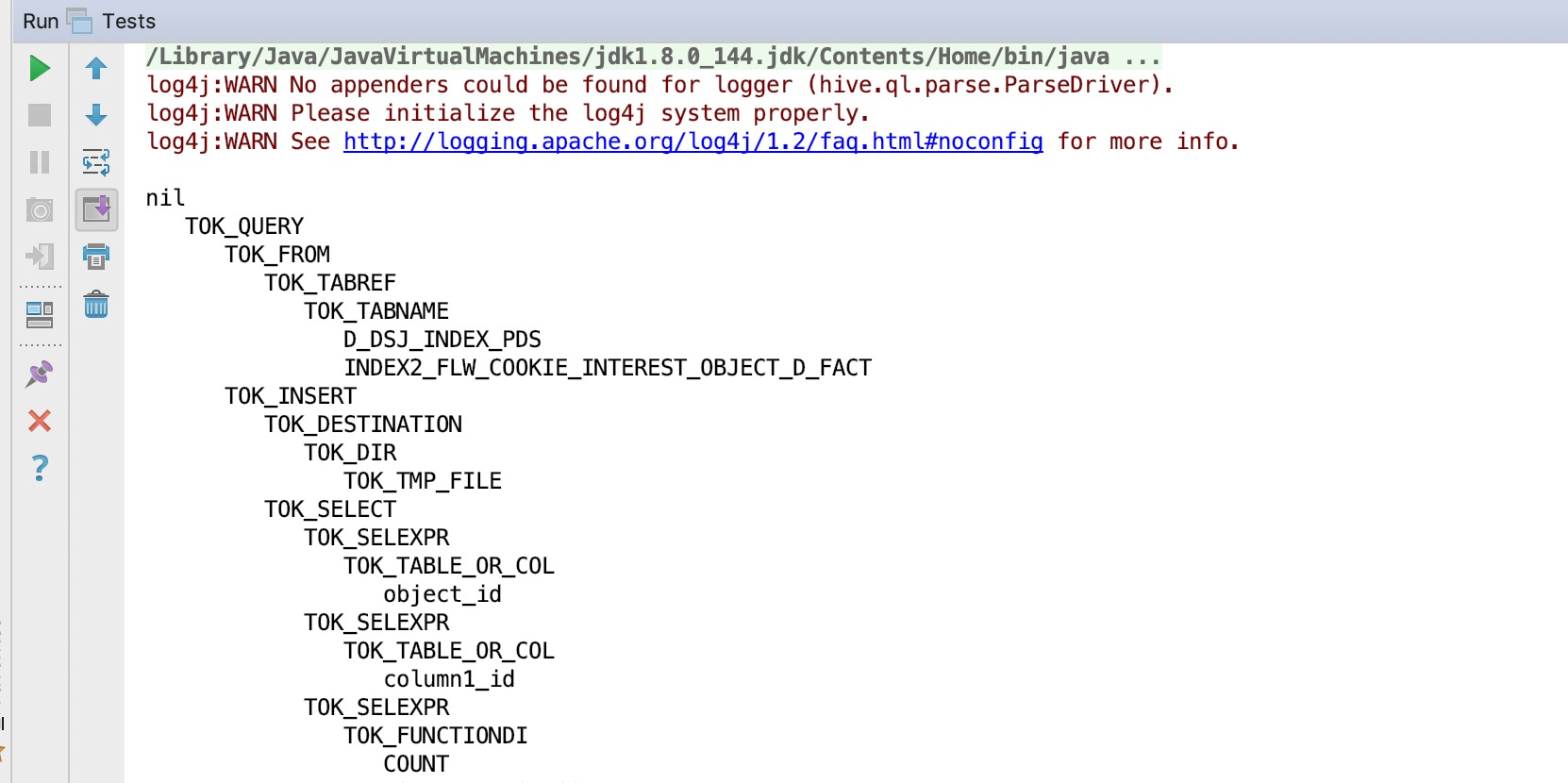
通过以上方式,即可将sql解析出ASTNode
######################################################################################################################################################
接着之前的源码,看下在生成ASTNode之后 , 是如何根据ASTNode来做优化的;
请查看下一篇:基于calcite做傻瓜式的sql优化(三)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号