彻底解决,sparkSQL读取csv中Map字段类型的问题

先说历史情况:
在spark2.0版本之前(比如1.6版本),spark sql如果读取csv格式数据,要导入:
<dependency>
<groupId>com.databricks</groupId>
<artifactId>spark-csv_2.11</artifactId>
</dependency>
代码:
spark .format("com.databricks.spark.csv") .option("header", "true") .load("csv数据路径")
在spark2.0以后,spark把databricks的代码内置到了自己的源码系统中,在通过一套非常简单的模板API就能读取到csv数据,比如:
spark.read.csv("csv数据路径")
以上操作,都去普通简单的数据类型均没有问题,比如读取这些类型:
ByteType、ShortType、IntegerType、LongType、FloatType、DoubleType、BooleanType、DecimalType、TimestampType、DateType、StringType
但是一旦读取复杂一些的,比如你读取csv文件,将数据写入hive表中【但是hive表的schema中有个字段的类型是Map<String,String>】,那么以上的方式就出现不兼容了;
我的csv数据格式:

我的生产问题:
生产spark版本切换,要从1.6版本直接升级到目前2.x最稳定的版本(2.4.6)
首先是历史原因,会有一些支线业务,通过rsink把csv文件分发到机器A上,然后spark会读取csv文件,将csv文件内容以orc格式写入hive某张表
但是之前说过的问题,sparksql读取csv文件 ,不知道Map类型,所以生产报错;
解决:
思路就是:通过自定义数据源的方式来支持这个Map格式,自定义数据源的思路看我之前写的这篇文章:
关于自定义sparkSQL数据源(Hbase)操作中遇到的坑
https://www.cnblogs.com/niutao/p/10801259.html
如何让spark sql写mysql的时候支持update操作
https://www.cnblogs.com/niutao/p/11809695.html
第一步:
去git上把com.databricks:spark-csv的源码拉下来
git clone https://github.com/databricks/spark-csv.git
第二步:
这里面实现的思路也是通过自定义数据源的方式来支持spark读取csv的;
所以,复制com.databricks:spark-csv源码到你的工程下(随便新建一个spark工程),比如:
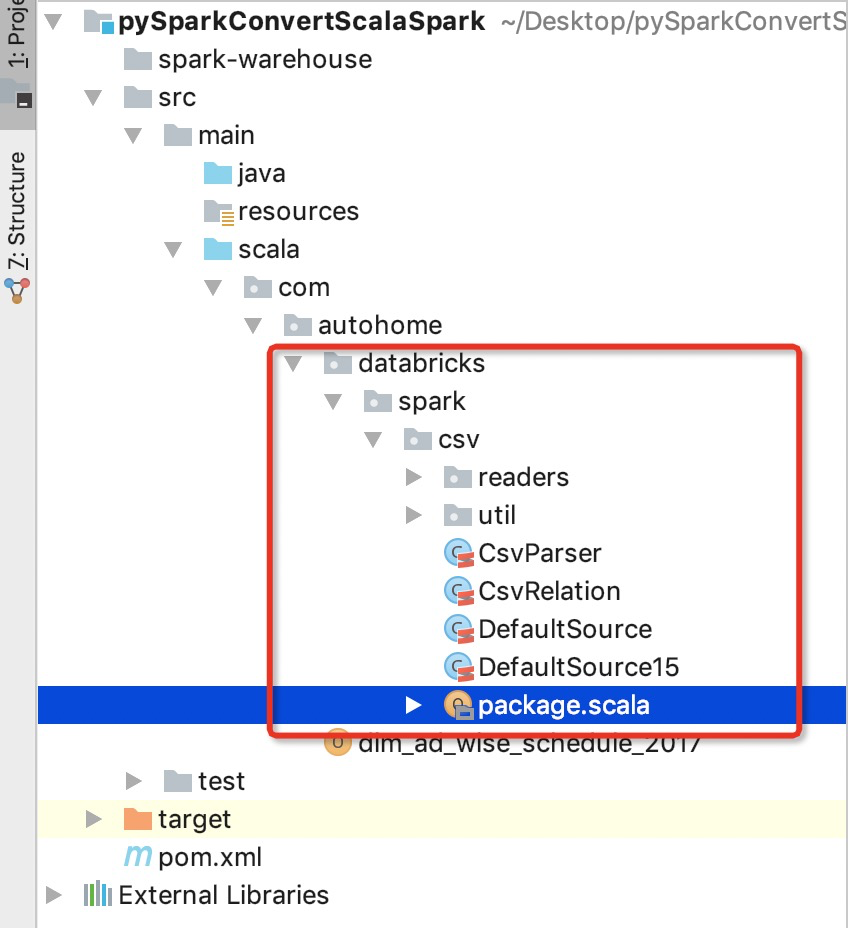
上面就是复制过来的源码,然后找到TypeCast这个object;
spark读取csv,适配csv里面的类型,就是在这个TypeCast.castTo代码中进行适配的:
/** * Casts given string datum to specified type. * Currently we do not support complex types (ArrayType, MapType, StructType). * * For string types, this is simply the datum. For other types. * For other nullable types, this is null if the string datum is empty. * * @param datum string value * @param castType SparkSQL type */ private[csv] def castTo( datum: String, castType: DataType, nullable: Boolean = true, treatEmptyValuesAsNulls: Boolean = false, nullValue: String = "", dateFormatter: SimpleDateFormat = null): Any = { if (datum == nullValue && nullable || (treatEmptyValuesAsNulls && datum == "")){ null } else { castType match { case _: ByteType => datum.toByte case _: ShortType => datum.toShort case _: IntegerType => datum.toInt case _: LongType => datum.toLong case _: FloatType => Try(datum.toFloat) .getOrElse(NumberFormat.getInstance(Locale.getDefault).parse(datum).floatValue()) case _: DoubleType => Try(datum.toDouble) .getOrElse(NumberFormat.getInstance(Locale.getDefault).parse(datum).doubleValue()) case _: BooleanType => datum.toBoolean case _: DecimalType => new BigDecimal(datum.replaceAll(",", "")) case _: TimestampType if dateFormatter != null => new Timestamp(dateFormatter.parse(datum).getTime) case _: TimestampType => Timestamp.valueOf(datum) case _: DateType if dateFormatter != null => new Date(dateFormatter.parse(datum).getTime) case _: DateType => Date.valueOf(datum) case _: StringType => datum //适配Map类型 case _: MapType => { var map = Map[String,String]() val arr = datum.split(":") map += (arr(0) -> arr(1)) map } case _ => throw new RuntimeException(s"Unsupported type: ${castType.typeName}") } } }
如上,添加一个适配Map类型即可
第三步:
对这个工程打包,最终生成一个jar包,必须叫做example.jar
然后导入这个新包,就完美解决读取csv中Map类型了
代码放在git了:https://github.com/niutaofan/pareCSV.git

