网约车的车辆热点聚类1

类似Uber,需要处理处不同时间段的不同地区的订单热点区域,帮助进行网约车的及时调度处理
每个成交单Order中,都会有订单上车位置的起始经纬度:open_lat , open_lng
那么在这个时间段内,哪些地区是高密集订单区域,好进行及时的调度,所以需要得到不同地区的热力图
初期想法是基于经纬度做聚类操作,典型的聚类算法是K- means,一种基于层次的聚类操作:
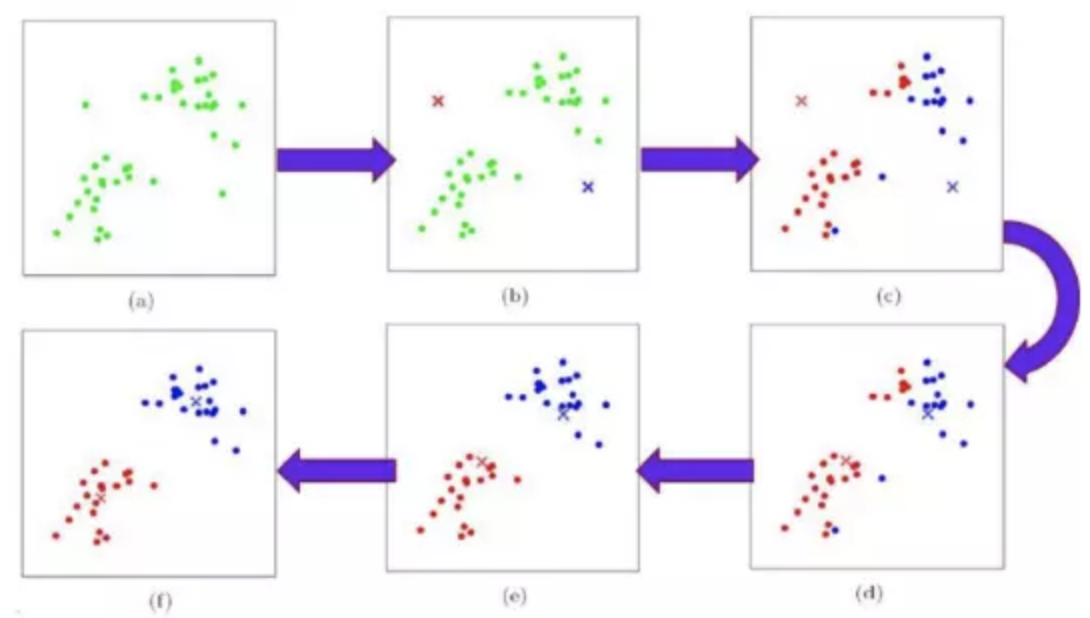
但是注意,kmeans是不适合做车辆聚类的,因为未来哪些地方会有订单其实是位置的,而kmeans要求必须制定K值,这就相当于,我最终要分成多少个聚类,显示不合适;
因此,想到了基于密度的聚类,而且不需要制定类别数,还可以自动识别噪点的DBScan算法
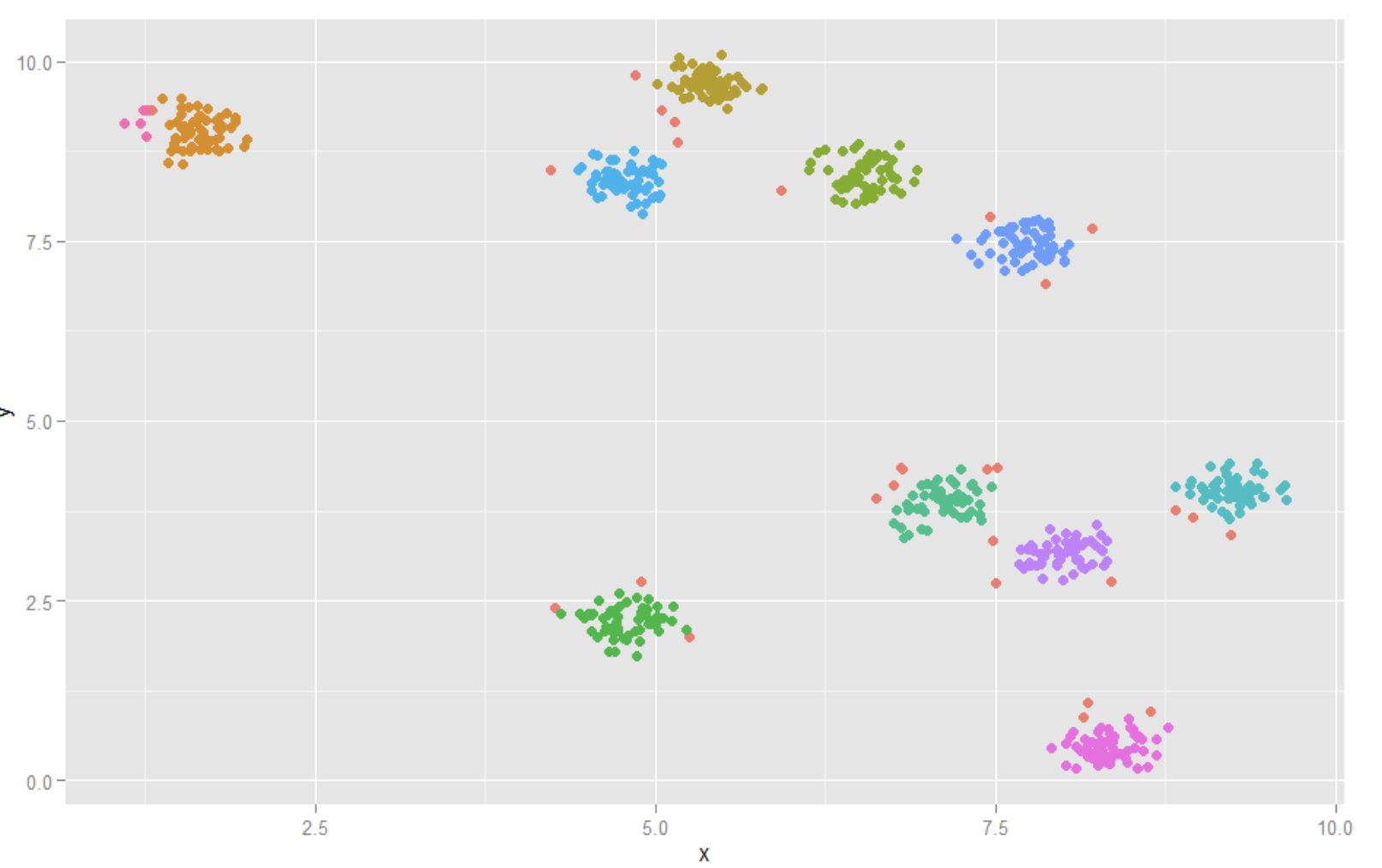

dbscan算法的思路:
输入:样本集D=(x1,x2,...,xm),邻域参数(ϵ,MinPts), 样本距离度量方式 输出: 簇划分C. 1)初始化核心对象集合Ω=∅, 初始化聚类簇数k=0,初始化未访问样本集合Γ = D, 簇划分C = ∅ 2) 对于j=1,2,...m, 按下面的步骤找出所有的核心对象: a) 通过距离度量方式,找到样本xj的ϵ-邻域子样本集Nϵ(xj) b) 如果子样本集样本个数满足|Nϵ(xj)|≥MinPts, 将样本xj加入核心对象样本集合:Ω=Ω∪{xj} 3)如果核心对象集合Ω=∅,则算法结束,否则转入步骤4. 4)在核心对象集合Ω中,随机选择一个核心对象o,初始化当前簇核心对象队列Ωcur={o}, 初始化类别序号k=k+1,初始化当前簇样本集合Ck={o}, 更新未访问样本集合Γ=Γ−{o} 5)如果当前簇核心对象队列Ωcur=∅,则当前聚类簇Ck生成完毕, 更新簇划分C={C1,C2,...,Ck}, 更新核心对象集合Ω=Ω−Ck, 转入步骤3。 6)在当前簇核心对象队列Ωcur中取出一个核心对象o′,通过邻域距离阈值ϵ找出所有的ϵ-邻域子样本集Nϵ(o′),令Δ=Nϵ(o′)∩Γ, 更新当前簇样本集合Ck=Ck∪Δ, 更新未访问样本集合Γ=Γ−Δ, 更新Ωcur=Ωcur∪(Δ∩Ω)−o′,转入步骤5. 输出结果为: 簇划分C={C1,C2,...,Ck}
利用java代码实现dbscan:


package com.df.dbscan; import java.util.ArrayList; /** * Created by angel */ public class DBScan { private double radius; private int minPts; /** * @param radius 单位米 * @param minPts 最小聚合数 * */ public DBScan(double radius,int minPts) { this.radius = radius; this.minPts = minPts; } public void process(ArrayList<Point> points) { int size = points.size(); int idx = 0; int cluster = 1; while (idx<size) { Point p = points.get(idx++); //choose an unvisited point if (!p.getVisit()) { p.setVisit(true);//set visited ArrayList<Point> adjacentPoints = getAdjacentPoints(p, points); //set the point which adjacent points less than minPts noised if (adjacentPoints != null && adjacentPoints.size() < minPts) { p.setNoised(true); } else { p.setCluster(cluster); for (int i = 0; i < adjacentPoints.size(); i++) { Point adjacentPoint = adjacentPoints.get(i); //only check unvisited point, cause only unvisited have the chance to add new adjacent points if (!adjacentPoint.getVisit()) { adjacentPoint.setVisit(true); ArrayList<Point> adjacentAdjacentPoints = getAdjacentPoints(adjacentPoint, points); //add point which adjacent points not less than minPts noised if (adjacentAdjacentPoints != null && adjacentAdjacentPoints.size() >= minPts) { //adjacentPoints.addAll(adjacentAdjacentPoints); for (Point pp : adjacentAdjacentPoints){ if (!adjacentPoints.contains(pp)){ adjacentPoints.add(pp); } } } } //add point which doest not belong to any cluster if (adjacentPoint.getCluster() == 0) { adjacentPoint.setCluster(cluster); //set point which marked noised before non-noised if (adjacentPoint.getNoised()) { adjacentPoint.setNoised(false); } } } cluster++; } } if (idx%1000==0) { System.out.println(idx); } } } private ArrayList<Point> getAdjacentPoints(Point centerPoint,ArrayList<Point> points) { ArrayList<Point> adjacentPoints = new ArrayList<Point>(); for (Point p:points) { //include centerPoint itself double distance = centerPoint.GetDistance(p); if (distance<=radius) { adjacentPoints.add(p); } } return adjacentPoints; } }
我的处理方式:
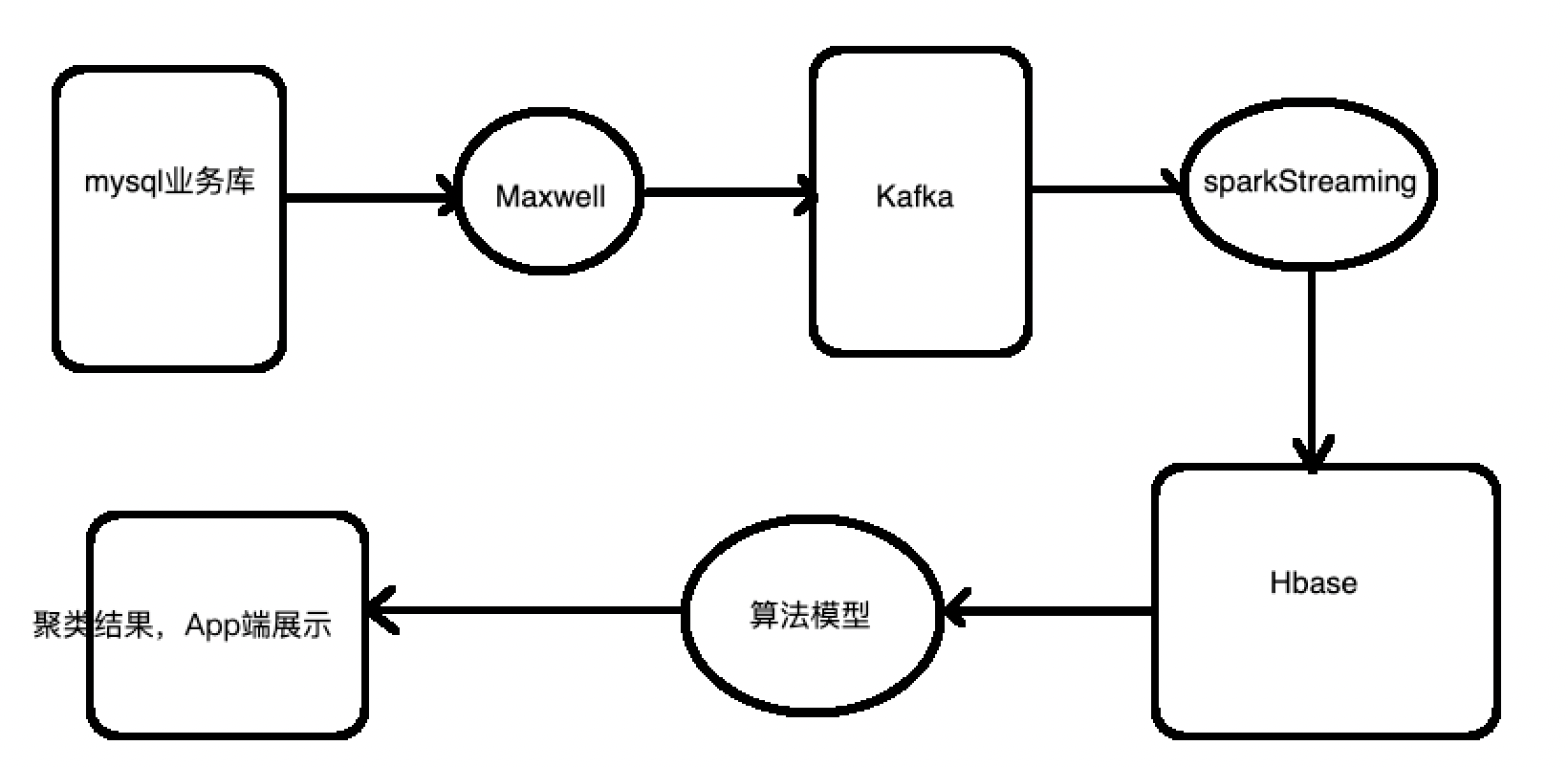
所以,我只需要将数据从Hbase中查询出来,在封装好具体的需要数据,就可以推送到算法中,最后识别出结果
//查询Hbase操作 val result = Controll.rowEndFilter2(tableName, startDate, endDate) //将查询出来的数据组装成算法需要的结构 import scala.collection.JavaConversions._ for (map <- result) { val lon = map.get("open_lng") val lat = map.get("open_lat") val begin_address_code = map.get("begin_address_code") points.add(new Point(lat.toDouble, lon.toDouble,begin_address_code)) } //算法处理 val dbScan = new DBScan(radius, density) dbScan.process(points) //将java的list转成scala的list val point_List: List[Point] = JavaConverters.asScalaIteratorConverter(points.iterator()).asScala.toList //得到每一个族下的坐标系 val groupData: Map[Int, List[Point]] = point_List.groupBy(line => line.getCluster) //在将结果进一步处理发送出去即可

