删除了原有的offset之后再次启动会报错park Streaming from Kafka has error numRecords must not ...
笔者使用Spark streaming读取Kakfa中的数据,做进一步处理,用到了KafkaUtil的createDirectStream()方法;该方法不会自动保存topic partition的offset到zk,需要在代码中编写提交逻辑,此处介绍了保存offset的方法。
当删除已经使用过的kafka topic,然后新建同名topic,使用该方式时出现了"numRecords must not be negative"异常
详细信息如下图:

是不合法的参数异常,RDD的记录数目必须不能是负数。
下文详细分析该问题的出现的场景,以及解决方法。
异常分析
numRecords确定
首先,定位出异常出现的问题,和大致原因。异常中打印出了出现的位置org.apache.spark.streaming.scheduler.StreamInputInfo.InputInfoTracker的第38行,此处代码:
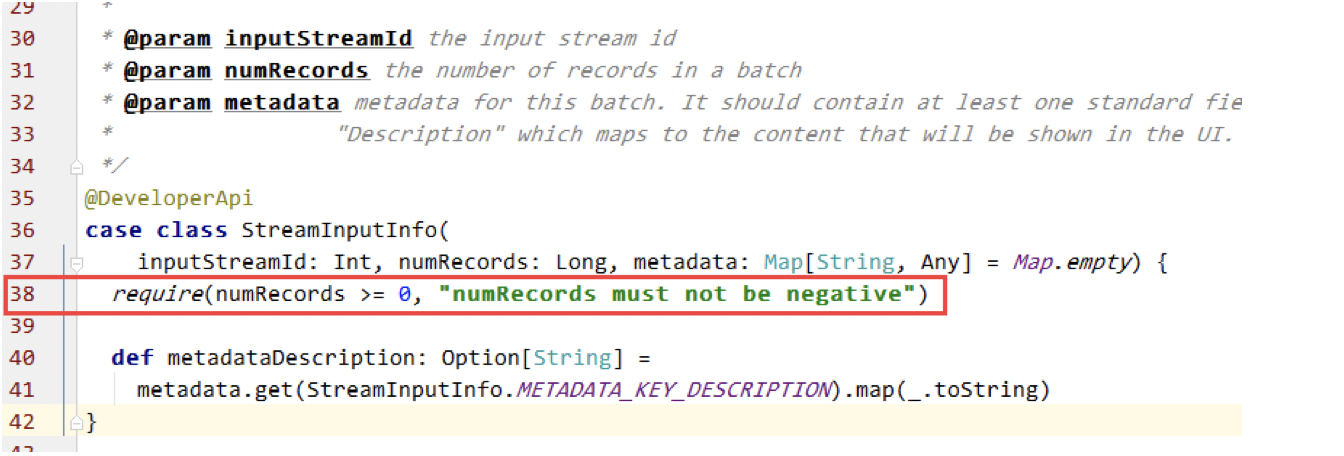
代码38行,判断了numRecords是否大于等于0,当不满足条件时抛出异常,可判断此时numRecords<0。
numRecords的解释:
numRecords: the number of records in a batch
应该是当前rdd中records 数目计算出了问题。
numRecords 构造StreamInputInfo时的参数,结合异常中的信息,找到了DirectKafkaInputDStream中的构造InputInfo的位置:
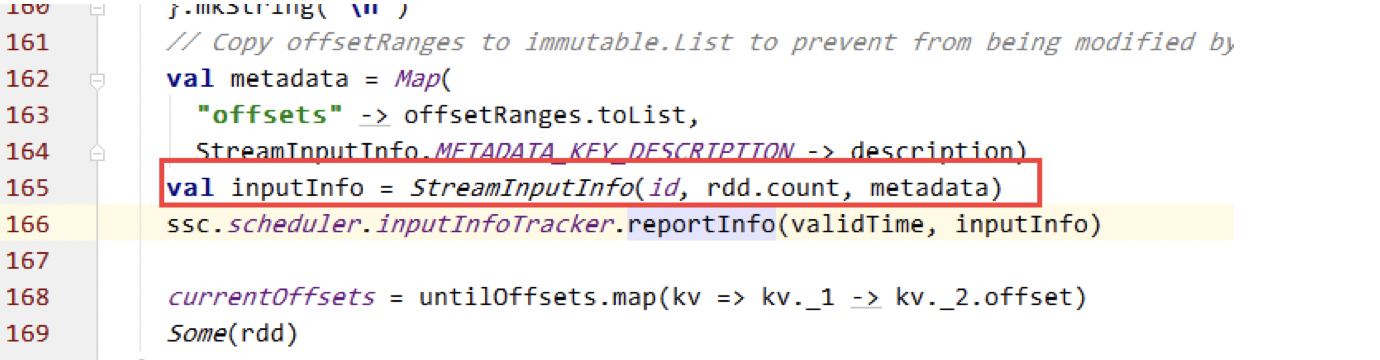
可知 numRecords是rdd.count()的值。
rdd.count的计算
根据以上分析可知rdd.count()值为负值,因此需要分析rdd的是如何生成的。
同样在DirectKafkaInputDStream中找到rdd的生成代码:


offsetRanges的计算逻辑
offsetRanges的定义
offsetRanges: offset ranges that define the Kafka data belonging to this RDD
在KafkaRDDPartition 40行找到kafka partition offsetRange的计算逻辑:
def count(): Long = untilOffset - fromOffset
fromOffset: per-topic/partition Kafka offset defining the (inclusive) starting point of the batch
untilOffset: per-topic/partition Kafka offset defining the (inclusive) ending point of the batch
fromOffset来自zk中保存;
untilOffset通过DirectKafkaInputDStream第145行:
val untilOffsets = clamp(latestLeaderOffsets(maxRetries))
计算得到,计算过程得到最新的offset,然后使用spark.streaming.kafka.maxRatePerPartition做clamp,得到允许的最大untilOffsets,##而此时新建的topic,如果topic中没有数据,untilOffsets应该为0##
原因总结
当删除一个topic时,zk中的offset信息并没有被清除,因此KafkaDirectStreaming再次启动时仍会得到旧的topic offset为old_offset,作为fromOffset。
当新建了topic后,使用untiloffset计算逻辑,得到untilOffset为0(如果topic已有数据则>0);
再次被启动的KafkaDirectStreaming Job通过异常的计算逻辑得到的rdd numRecords值为可计算为:
numRecords = untilOffset - fromOffset(old_offset)
当untilOffset < old_offset时,此异常会出现,对于新建的topic这种情况的可能性很大
解决方法
思路
根据以上分析,可在确定KafkaDirectStreaming 的fromOffsets时判断fromOffset与untiloffset的大小关系,当untilOffset < fromOffset时,矫正fromOffset为offset初始值0。
流程
- 从zk获取topic/partition 的fromOffset(获取方法链接)
- 利用SimpleConsumer获取每个partiton的lastOffset(untilOffset )
- 判断每个partition lastOffset与fromOffset的关系
- 当lastOffset < fromOffset时,将fromOffset赋值为0
通过以上步骤完成fromOffset的值矫正。
核心代码
获取kafka topic partition lastoffset代码: package org.frey.example.utils.kafka; import com.google.common.collect.Lists; import com.google.common.collect.Maps; import kafka.api.PartitionOffsetRequestInfo; import kafka.cluster.Broker; import kafka.common.TopicAndPartition; import kafka.javaapi.*; import kafka.javaapi.consumer.SimpleConsumer; import java.util.Date; import java.util.HashMap; import java.util.List; import java.util.Map; /** * KafkaOffsetTool * * @author angel * @date 2016/4/11 */ public class KafkaOffsetTool { private static KafkaOffsetTool instance; final int TIMEOUT = 100000; final int BUFFERSIZE = 64 * 1024; private KafkaOffsetTool() { } public static synchronized KafkaOffsetTool getInstance() { if (instance == null) { instance = new KafkaOffsetTool(); } return instance; } public Map<TopicAndPartition, Long> getLastOffset(String brokerList, List<String> topics, String groupId) { Map<TopicAndPartition, Long> topicAndPartitionLongMap = Maps.newHashMap(); Map<TopicAndPartition, Broker> topicAndPartitionBrokerMap = KafkaOffsetTool.getInstance().findLeader(brokerList, topics); for (Map.Entry<TopicAndPartition, Broker> topicAndPartitionBrokerEntry : topicAndPartitionBrokerMap .entrySet()) { // get leader broker Broker leaderBroker = topicAndPartitionBrokerEntry.getValue(); SimpleConsumer simpleConsumer = new SimpleConsumer(leaderBroker.host(), leaderBroker.port(), TIMEOUT, BUFFERSIZE, groupId); long readOffset = getTopicAndPartitionLastOffset(simpleConsumer, topicAndPartitionBrokerEntry.getKey(), groupId); topicAndPartitionLongMap.put(topicAndPartitionBrokerEntry.getKey(), readOffset); } return topicAndPartitionLongMap; } /** * 得到所有的 TopicAndPartition * * @param brokerList * @param topics * @return topicAndPartitions */ private Map<TopicAndPartition, Broker> findLeader(String brokerList, List<String> topics) { // get broker's url array String[] brokerUrlArray = getBorkerUrlFromBrokerList(brokerList); // get broker's port map Map<String, Integer> brokerPortMap = getPortFromBrokerList(brokerList); // create array list of TopicAndPartition Map<TopicAndPartition, Broker> topicAndPartitionBrokerMap = Maps.newHashMap(); for (String broker : brokerUrlArray) { SimpleConsumer consumer = null; try { // new instance of simple Consumer consumer = new SimpleConsumer(broker, brokerPortMap.get(broker), TIMEOUT, BUFFERSIZE, "leaderLookup" + new Date().getTime()); TopicMetadataRequest req = new TopicMetadataRequest(topics); TopicMetadataResponse resp = consumer.send(req); List<TopicMetadata> metaData = resp.topicsMetadata(); for (TopicMetadata item : metaData) { for (PartitionMetadata part : item.partitionsMetadata()) { TopicAndPartition topicAndPartition = new TopicAndPartition(item.topic(), part.partitionId()); topicAndPartitionBrokerMap.put(topicAndPartition, part.leader()); } } } catch (Exception e) { e.printStackTrace(); } finally { if (consumer != null) consumer.close(); } } return topicAndPartitionBrokerMap; } /** * get last offset * @param consumer * @param topicAndPartition * @param clientName * @return */ private long getTopicAndPartitionLastOffset(SimpleConsumer consumer, TopicAndPartition topicAndPartition, String clientName) { Map<TopicAndPartition, PartitionOffsetRequestInfo> requestInfo = new HashMap<TopicAndPartition, PartitionOffsetRequestInfo>(); requestInfo.put(topicAndPartition, new PartitionOffsetRequestInfo( kafka.api.OffsetRequest.LatestTime(), 1)); OffsetRequest request = new OffsetRequest( requestInfo, kafka.api.OffsetRequest.CurrentVersion(), clientName); OffsetResponse response = consumer.getOffsetsBefore(request); if (response.hasError()) { System.out .println("Error fetching data Offset Data the Broker. Reason: " + response.errorCode(topicAndPartition.topic(), topicAndPartition.partition())); return 0; } long[] offsets = response.offsets(topicAndPartition.topic(), topicAndPartition.partition()); return offsets[0]; } /** * 得到所有的broker url * * @param brokerlist * @return */ private String[] getBorkerUrlFromBrokerList(String brokerlist) { String[] brokers = brokerlist.split(","); for (int i = 0; i < brokers.length; i++) { brokers[i] = brokers[i].split(":")[0]; } return brokers; } /** * 得到broker url 与 其port 的映射关系 * * @param brokerlist * @return */ private Map<String, Integer> getPortFromBrokerList(String brokerlist) { Map<String, Integer> map = new HashMap<String, Integer>(); String[] brokers = brokerlist.split(","); for (String item : brokers) { String[] itemArr = item.split(":"); if (itemArr.length > 1) { map.put(itemArr[0], Integer.parseInt(itemArr[1])); } } return map; } public static void main(String[] args) { List<String> topics = Lists.newArrayList(); topics.add("ys"); topics.add("bugfix"); Map<TopicAndPartition, Long> topicAndPartitionLongMap = KafkaOffsetTool.getInstance().getLastOffset("broker001:9092,broker002:9092", topics, "my.group.id"); for (Map.Entry<TopicAndPartition, Long> entry : topicAndPartitionLongMap.entrySet()) { System.out.println(entry.getKey().topic() + "-"+ entry.getKey().partition() + ":" + entry.getValue()); } } } 矫正offset核心代码: /** 以下 矫正 offset */ // 得到Topic/partition 的lastOffsets Map<TopicAndPartition, Long> topicAndPartitionLongMap = KafkaOffsetTool.getInstance().getLastOffset(kafkaParams.get("metadata.broker.list"), topicList, "my.group.id"); // 遍历每个Topic.partition for (Map.Entry<TopicAndPartition, Long> topicAndPartitionLongEntry : fromOffsets.entrySet()) { // fromOffset > lastOffset时 if (topicAndPartitionLongEntry.getValue() > topicAndPartitionLongMap.get(topicAndPartitionLongEntry.getKey())) { //矫正fromoffset为offset初始值0 topicAndPartitionLongEntry.setValue(0L); } } /** 以上 矫正 offset */

