
分布式架构基础、Paxos算法、Raft算法、系统网络通信
SpringCloudAlibaba微服务实战教程系列
-------------------------目录-------------------------------------
第一部分:分布式架构理论
一、分布式与集群区别
二、传统架构的弊端:
三、分布式系统面临的问题
四、分布式中的一致性理论(CAP与BASE理论)
五、一致性协议:2PC协议
六、一致性协议:3PC协议
七、分布式一致性:Paxos算法
八、分布式一致性:Raft算法
第二部分:分布式系统设计策略
心跳机制、高可用、容错性、负载均衡
-----------------------------------------------------------------
第一部分:分布式架构理论
一、分布式与集群区别
分布式:是多个人在一起做不同的事情;
集群:是多个在一起做同样的事情;
二、传统架构的弊端:
互联网发展单机处理所有的业务弊端比较明显,比如修改下单业务的逻辑,用户登录的功能没有修改也需要重启项目,同时团队开发同一个项目沟通协作的成本也会随着业务的发展而增多。
1、升级单机处理能力的性价比越来越低。
2、单机处理能力存在瓶颈。
3、稳定性和可用性这两个标准很难达到。
三、分布式系统面临的问题
1、通信异常
主要包括消息丢失与消息延时:网络本来不可靠每次通信都可能存在网络不可用的风险,最终导致分布式系统无法顺利的进行网络通信,另一种是分布式节点正常执行也会出现单机延时处理,从而影响整个业务处理的消息丢失和消息延迟
2、网络分区
网络之间出现网络不通,但是各个子节点网络正常通信,导致真个系统网络环境被分隔独立的区域,在分布式中就会存在局部小集群,对与数理的事务处理分布式一致性挑战比较大
3、节点故障
节点故障是分布式系统比较常见的问题,制的是组成分布式系统的服务器节点出现宕机或者僵死
4、三态
分布式系统每次请求响应存在三态:成功、失败、超时
超时有两种情况:
1、网络原因请求发出后对方没有收到,
2、请求接收方收到请求,业务处理成功,返回失败
四、分布式中的一致性理论
首先分布式中处理数据的一致性,保证一致性使用的是多副本存储,副本存储就是多份拷贝;
一致性分类:强一致性、弱一致性、单调弱一致性、最终一致性。
1、分布式理论:CAP理论
CAP理论含义:一个分布式系统中不可能同时满足一致性(C:Consistency)、可用性(A:Availability)、分区容错性(P:Partition tolerance)三个基本需求,最多只能同时满足其中两个。
一致性(C):分布式系统中的一致性是所有节点的数据一致,或者说所有的副本数据一致,强一致性
可用性(A):系统一直可用
分区容错性(P):系统在遇到节点或者网络分区故障的时候,还可以通过一致性和可用性的服务。
CAP理论具体应用:
Redis :属于 cp 模型。Redis-cluster 属于 ap 模型Redis-cluster
Zookeeper:属于cp模型。
MongoDB :属于cp模型。
Eureka:属于ap模型。
2、分布式理论:BASE理论
五、一致性协议:2PC协议
什么事2PC:2PC就是分布式一致性协议,Two-Phase commit的缩写,就是两阶段提交协议,将整个事务流程分为连个阶段:准备阶段和提交阶段,2是两个阶段,p准备阶段,c是提交阶段。
例如:事务的提交(如下图),
第一阶段事务管理者向两个资源发起准备请求,两个资源返回准备完成,
第二阶段:资源记录日志undo/redo,事务管理者向两个资源发起提交请求,两个资源发起ack确认。
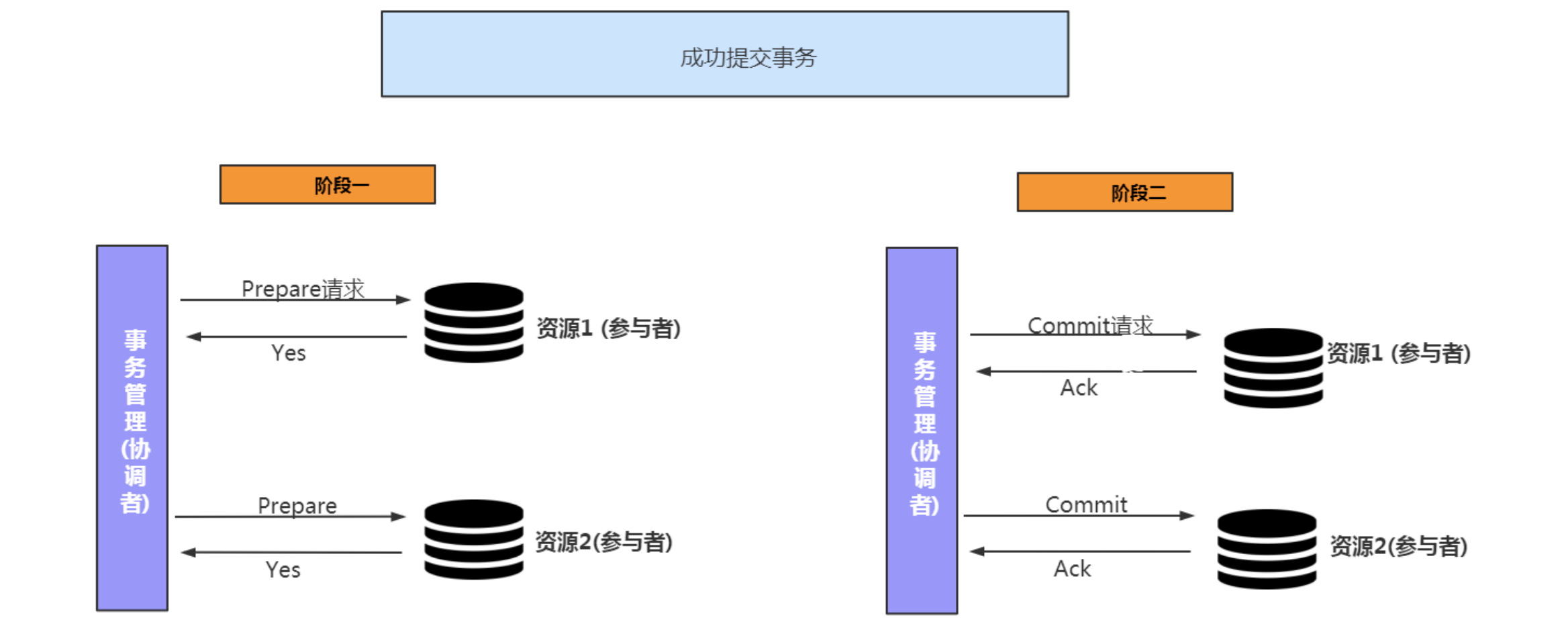
如果事务异常,那么第二阶段事务管理这会发起事务回滚请求,都是资源返回ack确认。
优点: 原理简单,实现方便
确定:- 同步阻塞
- 单点问题
- 数据不一致(第一个资源提交,第二个资源超时)
六、一致性协议:3PC协议
3PC是2PC的改进版,把二阶段提交协议的“提交事务请求”过程一分为二。形成了CanCommit、PreCommit、DoCommit三个阶段。

第一阶段CanCommit:1、事务询问参与者,2、各参与者返回是否支持事务
第二阶段PreCommit:1、向各个参与者发送预提交处理,2、参与者记录日志undo/redo,各参与者返回ack响应:同时等待提交commit或终止abort请求。
如果其中一个参与者下返回no或者超时,接下来协调者会发送alber终止请求
第三阶段Docommit:1、向各个参与者发起提交请求,2、参与者提交事务完成后返回ack确认,
如果参与者中间事务中断或者超时,协调者发起abort请求,执行第二阶段的undo日志。
3PC详细文章:https://blog.csdn.net/yulong1026/article/details/81002618
七、分布式一致性:Paxos算法
1、Paxos 算中中必须认识的三个角色
- Proposer:议案发起者(提议者)。提案者提倡客户请求,试图说服Acceptor对此达成一致,并在发生突时充当协调者以推动协议向前发展
- Acceptor:决策者,可以批准议案。Acceptor可以接受(accept)提案;如果某个提案被选(chosen),那么该提案里的value就被选定了
- Learner:最终决策的学习者(接受者)。
2、Proposer生成提案
首先Proposer在生成提案之前,需要先学习已经被选定或者可能被选定的value,然后以该value作为自己提出的议案的value,没有value被选中的时候才可以自己决定value值,学习value是通过一个prepare请求实现的。
第一步:proposer选择新提案编号N,然后向半数以上的Acceptor发送请求,要求每个acceptor做出下面的响应
a、Acceptor向Propose承诺保证不再接受任何编号小于N的提案。
b、如果Acceptor已经接受过提案,那么就想proposer反馈已经接受过编号小于N的,但是值是最大编号的提案值。
我们将这请求称为编号为N的prepare请求
第二步:
3、Acceptor接受提案
Paxos算法推导过程:https://my.oschina.net/u/150175/blog/2992187
Paxos算法在线演示:http://thesecretlivesofdata.com/raft/
八、分布式一致性:Raft算法
Raft将系统中的角色分为领导者(Leader)、跟从者(Follower)和候选者(Candidate):
-
Leader:接受客户端请求,并向Follower同步请求日志,当日志同步到大多数节点上后告诉Follower提交日志。
-
Follower:接受并持久化Leader同步的日志,在Leader告之日志可以提交之后,提交日志。
-
Candidate:Leader选举过程中的临时角色。
https://blog.csdn.net/daaikuaichuan/article/details/98627822
第二部分:分布式系统设计策略
一、心跳检测
二、高可用性

三、容错性
1、缓存穿透
描述: 缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求,如发起为id为“-1”的数据或id为特别大不存在的数据。这时的用户很可能是攻击者,攻击会导致数据库压力过大。
解决方案:接口层增加校验,如用户鉴权校验,id做基础校验,id<=0的直接拦截;从缓存取不到的数据,在数据库中也没有取到,这时也可以将key-value对写为key-null,缓存有效时间可以设置短点,如30秒(设置太长会导致正常情况也没法使用)。这样可以防止攻击用户反复用同一个id暴力攻击
2、缓存击穿
描述: 缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力
解决方案:设置热点数据永远不过期。加互斥锁:
四、缓存雪崩
描述: 缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至down机。和缓存击穿不同的是, 缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
解决方案:缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。如果缓存数据库是分布式部署,将热点数据均匀分布在不同搞得缓存数据库中。设置热点数据永远不过期。
四、负载均衡
负载有硬件负载与软件负载,负载算法:轮询、权重、ip_hash、最少链接等
