[源码分析]ArrayList和LinkedList如何实现的?我看你还有机会!
点赞再看,动力无限。Hello world : ) 微信搜「 程序猿阿朗 」。
本文 Github.com/niumoo/JavaNotes 和 未读代码博客 已经收录,有很多知识点和系列文章。
前言
说真的,在 Java 使用最多的集合类中,List 绝对占有一席之地的,它和 Map 一样适用于很多场景,非常方便我们的日常开发,毕竟存储一个列表的需求随处可见。尽管如此,还是有很多同学没有弄明白 List 中 ArrayList 和 LinkedList 有什么区别,这简直太遗憾了,这两者其实都是数据结构中的基础内容,这篇文章会从基础概念开始,分析两者在 Java 中的具体源码实现,寻找两者的不同之处,最后思考它们使用时的注意事项。
这篇文章会包含以下内容。
- 介绍线性表的概念,详细介绍线性表中数组和链表的数据结构。
- 进行 ArrayList 的源码分析,比如存储结构、扩容机制、数据新增、数据获取等。
- 进行 LinkedList 的源码分析,比如它的存储结构、数据插入、数据查询、数据删除和 LinkedList 作为队列的使用方式等。
- 进行 ArrayList 和 LinkedList 的总结。
线性表
要研究 ArrayList 和 LinkedList ,首先要弄明白什么是线性表,这里引用百度百科的一段文字。
线性表是最基本、最简单、也是最常用的一种数据结构。线性表(linear list)是数据结构的一种,一个线性表是n个具有相同特性的数据元素的有限序列。
你肯定看到了,线性表在数据结构中是一种最基本、最简单、最常用的数据结构。它将数据一个接一个的排成一条线(可能逻辑上),也因此线性表上的每个数据只有前后两个方向,而在数据结构中,数组、链表、栈、队列都是线性表。你可以想象一下整整齐齐排队的样子。

看到这里你可能有疑问了,有线性表,那么肯定有非线性表喽?没错。二叉树和图就是典型的非线性结构了。不要被这些花里胡哨的图吓到,其实这篇文章非常简单,希望同学耐心看完点个赞。
数组
既然知道了什么是线性表,那么理解数组也就很容易了,首先数组是线性表的一种实现。数组是由相同类型元素组成的一种数据结构,数组需要分配一段连续的内存用来存储。注意关键词,相同类型,连续内存,像这样。

不好意思放错图了,像这样。
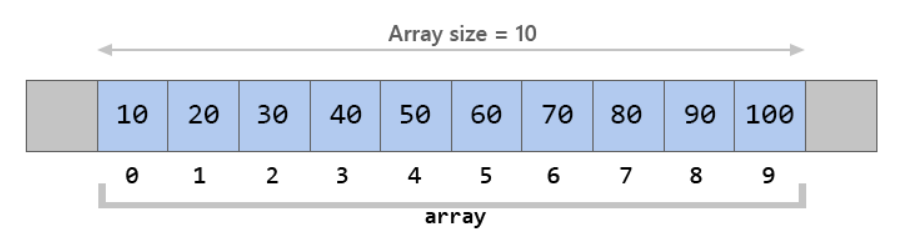
上面的图可以很直观的体现数组的存储结构,因为数组内存地址连续,元素类型固定,所有具有快速查找某个位置的元素的特性;同时也因为数组需要一段连续内存,所以长度在初始化长度已经固定,且不能更改。Java 中的 ArrayList 本质上就是一个数组的封装。
链表
链表也是一种线性表,和数组不同的是链表不需要连续的内存进行数据存储,而是在每个节点里同时存储下一个节点的指针,又要注意关键词了,每个节点都有一个指针指向下一个节点。那么这个链表应该是什么样子呢?看图。
哦不,放错图了,是这样。
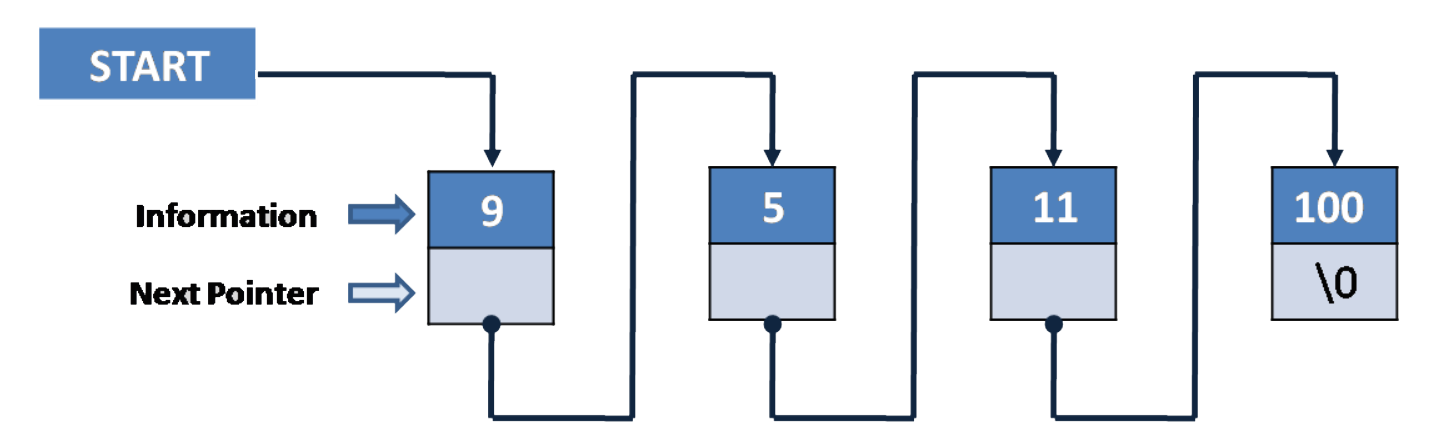
上图很好的展示了链表的存储结构,图中每个节点都有一个指针指向下一个节点位置,这种我们称为单向链表;还有一种链表在每个节点上还有一个指针指向上一个节点,这种链表我们称为双向链表。图我就不画了,像下面这样。

可以发现链表不必连续内存存储了,因为链表是通过节点指针进行下一个或者上一个节点的,只要找到头节点,就可以以此找到后面一串的节点。不过也因此,链表在查找或者访问某个位置的节点时,需要O(n)的时间复杂度。但是插入数据时可以达到O(1)的复杂度,因为只需要修改节点指针指向。
ArratList
上面介绍了线性表的概念,并举出了两个线性表的实际实现例子,既数组和链表。在 Java 的集合类 ArrayList 里,实际上使用的就是数组存储结构,ArrayList 对 Array 进行了封装,并增加了方便的插入、获取、扩容等操作。因为 ArrayList 的底层是数组,所以存取非常迅速,但是增删时,因为要移动后面的元素位置,所以增删效率相对较低。那么它具体是怎么实现的呢?不妨深入源码一探究竟。
ArrayList 存储结构
查看 ArrayList 的源码可以看到它就是一个简单的数组,用来数据存储。
/**
* The array buffer into which the elements of the ArrayList are stored.
* The capacity of the ArrayList is the length of this array buffer. Any
* empty ArrayList with elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA
* will be expanded to DEFAULT_CAPACITY when the first element is added.
*/
transient Object[] elementData; // non-private to simplify nested class access
/**
* Shared empty array instance used for default sized empty instances. We
* distinguish this from EMPTY_ELEMENTDATA to know how much to inflate when
* first element is added.
*/
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
/**
* Default initial capacity.
*/
private static final int DEFAULT_CAPACITY = 10;
通过上面的注释了解到,ArrayList 无参构造时是会共享一个长度为 0 的数组 DEFAULTCAPACITY_EMPTY_ELEMENTDATA. 只有当第一个元素添加时才会第一次扩容,这样也防止了创建对象时更多的内存浪费。
ArrayList 扩容机制
我们都知道数组的大小一但确定是不能改变的,那么 ArrayList 明显可以不断的添加元素,它的底层又是数组,它是怎么实现的呢?从上面的 ArrayList 存储结构以及注释中了解到,ArrayList 在初始化时,是共享一个长度为 0 的数组的,当第一个元素添加进来时会进行第一次扩容,我们可以想像出 ArrayList 每当空间不够使用时就会进行一次扩容,那么扩容的机制是什么样子的呢?
依旧从源码开始,追踪 add() 方法的内部实现。
/**
* Appends the specified element to the end of this list.
*
* @param e element to be appended to this list
* @return <tt>true</tt> (as specified by {@link Collection#add})
*/
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
// 开始检查当前插入位置时数组容量是否足够
private void ensureCapacityInternal(int minCapacity) {
// ArrayList 是否未初始化,未初始化是则初始化 ArrayList ,容量给 10.
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
// 比较插入 index 是否大于当前数组长度,大于就 grow 进行扩容
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
/**
* Increases the capacity to ensure that it can hold at least the
* number of elements specified by the minimum capacity argument.
*
* @param minCapacity the desired minimum capacity
*/
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
// 扩容规则是当前容量 + 当前容量右移1位。也就是1.5倍。
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
// 是否大于 Int 最大值,也就是容量最大值
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
// 拷贝元素到扩充后的新的 ArrayList
elementData = Arrays.copyOf(elementData, newCapacity);
}
通过源码发现扩容逻辑还是比较简单的,整理下具体的扩容流程如下:
-
开始检查当前插入位置时数组容量是否足够
-
ArrayList 是否未初始化,未初始化是则初始化 ArrayList ,容量给 10.
-
判断当前要插入的下标是否大于容量
- 不大于,插入新增元素,新增流程完毕。
-
如果所需的容量大于当前容量,开始扩充。
-
扩容规则是当前容量 + 当前容量右移1位。也就是1.5倍。
int newCapacity = oldCapacity + (oldCapacity >> 1); -
如果扩充之后还是小于需要的最小容量,则把所需最小容量作为容量。
-
如果容量大于默认最大容量,则使用 最大值 Integer 作为容量。
-
拷贝老数组元素到扩充后的新数组
-
-
插入新增元素,新增流程完毕。
ArrayList 数据新增
上面分析扩容时候已经看到了新增一个元素的具体逻辑,因为底层是数组,所以直接指定下标赋值即可,非常简单。
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e; // 直接赋值
return true;
}
但是还有一种新增数据得情况,就是新增时指定了要加入的下标位置。这时逻辑有什么不同呢?
/**
* Inserts the specified element at the specified position in this
* list. Shifts the element currently at that position (if any) and
* any subsequent elements to the right (adds one to their indices).
*
* @param index index at which the specified element is to be inserted
* @param element element to be inserted
* @throws IndexOutOfBoundsException {@inheritDoc}
*/
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
// 指定下标开始所有元素后移一位
System.arraycopy(elementData, index, elementData, index + 1,size - index);
elementData[index] = element;
size++;
}
可以发现这种新增多了关键的一行,它的作用是把从要插入的坐标开始的元素都向后移动一位,这样才能给指定下标腾出空间,才可以放入新增的元素。
比如你要在下标为 3 的位置新增数据100,那么下标为3开始的所有元素都需要后移一位。
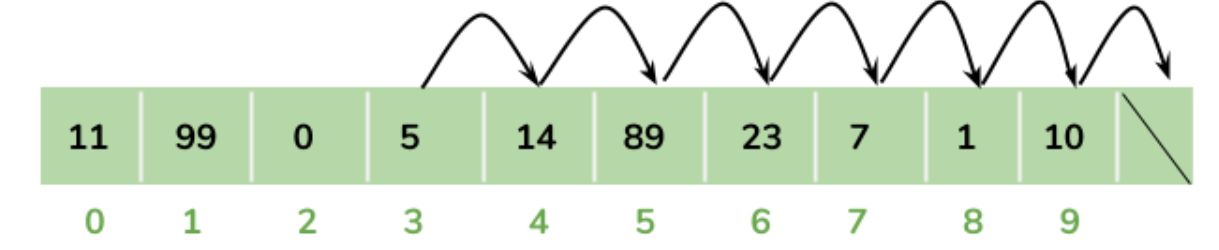
由此也可以看到 ArrayList 的一个缺点,随机插入新数据时效率不高。
ArrayList 数据获取
数据下标获取元素值,一步到位,不必多言。
public E get(int index) {
rangeCheck(index);
return elementData(index);
}
E elementData(int index) {
return (E) elementData[index];
}
LinkedList
LinkedList 的底层就是一个链表线性结构了,链表除了要有一个节点对象外,根据单向链表和双向链表的不同,还有一个或者两个指针。那么 LinkedList 是单链表还是双向链表呢?
LinkedList 存储结构
依旧深入 LinkedList 源码一探究竟,可以看到 LinkedList 无参构造里没有任何操作,不过我们通过查看变量 first、last 可以发现它们就是存储链表第一个和最后 一个的节点。
transient int size = 0;
/**
* Pointer to first node.
* Invariant: (first == null && last == null) ||
* (first.prev == null && first.item != null)
*/
transient Node<E> first;
/**
* Pointer to last node.
* Invariant: (first == null && last == null) ||
* (last.next == null && last.item != null)
*/
transient Node<E> last;
/**
* Constructs an empty list.
*/
public LinkedList() {
}
变量 first 和 last 都是 Node 类型,继而查看 Node 源码。
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
可以看到这就是一个典型的双向链表结构,item 用来存放元素值;next 指向下一个 node 节点,prev 指向上一个 node 节点。
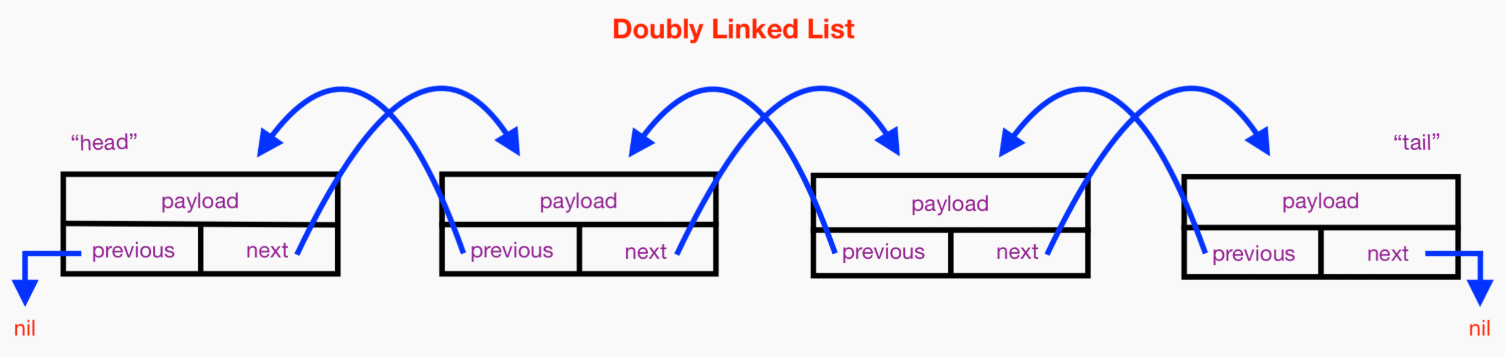
LinkedList 数据获取
链表不像数组是连续的内存地址,链表是通过next 和 prev 指向记录链接路径的,所以查找指定位置的 node 只能遍历查找,查看源码也是如此。
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
/**
* Returns the (non-null) Node at the specified element index.
*/
// 遍历查找 index 位置的节点信息
Node<E> node(int index) {
// assert isElementIndex(index);
// 这里判断 index 是在当前链表的前半部分还是后半部分,然后决定是从
// first 向后查找还是从 last 向前查找。
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
查找指定位置的 node 对象,这个部分要注意的是,查找会首先判断 index 是在当前链表的前半部分还是后半部分,然后决定是从 first 向后查找还是从 last 向前查找。这样可以增加查找速度。从这里也可以看出链表在查找指定位置元素时,效率不高。
LinkedList 数据新增
因为 LinkedList 是链表,所以 LinkedList 的新增也就是链表的数据新增了,这时候要根据要插入的位置的区分操作。
-
尾部插入
public boolean add(E e) { linkLast(e); return true; } void linkLast(E e) { final Node<E> l = last; // 新节点,prev 为当前尾部节点,e为元素值,next 为 null, final Node<E> newNode = new Node<>(l, e, null); last = newNode; if (l == null) first = newNode; else // 目前的尾部节点 next 指向新的节点 l.next = newNode; size++; modCount++; }默认的 add 方式就是尾部新增了,尾部新增的逻辑很简单,只需要创建一个新的节点,新节点的 prev 设置现有的末尾节点,现有的末尾 Node 指向新节点 Node,新节点的 next 设为 null 即可。
-
中间新增
下面是在指定位置新增元素,涉及到的源码部分。
public void add(int index, E element) { checkPositionIndex(index); if (index == size) // 如果位置就是当前链表尾部,直接尾插 linkLast(element); else // 获取 index 位置的节点,插入新的元素 linkBefore(element, node(index)); } /** * Inserts element e before non-null Node succ. */ // 在指定节点处新增元素,修改指定元素的下一个节点为新增元素,新增元素的下一个节点是查找到得 node 的next节点指向, // 新增元素的上一个节点为查找到的 node 节点,查找到的 node 节点的 next 指向 node 的 prev 修改为新 Node void linkBefore(E e, Node<E> succ) { // assert succ != null; final Node<E> pred = succ.prev; final Node<E> newNode = new Node<>(pred, e, succ); succ.prev = newNode; if (pred == null) first = newNode; else pred.next = newNode; size++; modCount++; }可以看到指定位置插入元素主要分为两个部分,第一个部分是查找 node 节点部分,这部分就是上面介绍的 LinkedList 数据获取部分,
第二个部分是在查找到得 node 对象后插入元素。主要就是修改 node 的 next 指向为新节点,新节点的 prev 指向为查找到的 node 节点,新节点的 next 指向为查找到的 node 节点的 next 指向。查找到的 node 节点的 next 指向的 node 节点的 prev 修改为新节点。
![LinkedLst 插入元素]()

LinkedList 数据删除
依旧查看源码进行分析,源码中看到如果节点是头结点或者尾节点,删除比较简单。我们主要看删除中间一个节点时的操作
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}
/**
* Unlinks non-null node x.
*/
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
node(index) 方法依旧是二分查找目标位置,然后进行删除操作。比如要删除的节点叫做 X,删除操作主要是修改 X 节点的 prev 节点的 next 指向为 X 节点的 next 指向,修改 X 节点的 next 节点的 prev 指向为 X 节点的 prev 指向,最后把 X 节点的 prev 和 next 指向清空。如果理解起来有点费劲,可以看下面这个图,可能会比较明白。
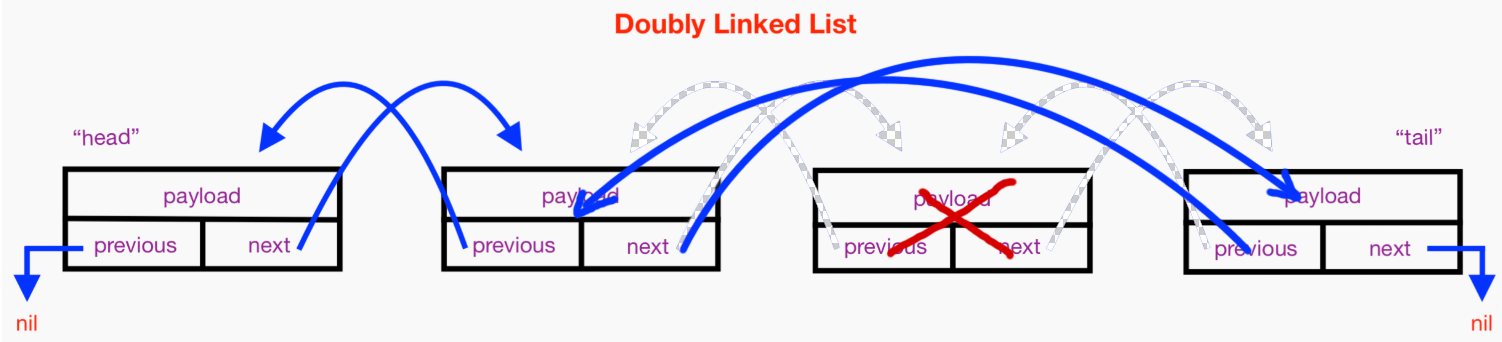
扩展
你以为 LinkedList 只是一个 List,其他它不仅实现了 List 接口,还实现了 Deque ,所以它表面上是一个 List,其实它还是一个队列。
public class LinkedList<E> extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
体验一下先进先出的队列。
Queue<String> queue = new LinkedList<>();
queue.add("a");
queue.add("b");
queue.add("c");
queue.add("d");
System.out.println(queue.poll());
System.out.println(queue.poll());
System.out.println(queue.poll());
System.out.println(queue.poll());
// result:
// a
// b
// c
// d
同学可以思考一下这个队列是怎么实现的,其实很简单对不对,就是先进先出嘛,poll 时删除 first 节点不就完事了嘛。
总结
不管是 ArrayList 还是 LinkedList 都是开发中常用的集合类,这篇文章分析了两者的底层实现,通过对底层实现的分析我们可以总结出两者的主要优缺点。
- 遍历,ArrayList 每次都是直接定位,LinkedList 通过 next 节点定位,不相上下。这里要注意的是 LinkedList 只有使用迭代器的方式遍历才会使用 next 节点。如果使用
get,则因为遍历查找效率低下。 - 新增,ArrayList 可能会需要扩容,中间插入时,ArrayList 需要后移插入位置之后的所有元素。LinkedList 直接修改 node 的 prev, next 指向,LinkedList 胜出。
- 删除,同 2.
- 随机访问指定位置,ArrayList 直接定位,LinkedList 从头会尾开始查找,数组胜出。
综上所述,ArrayList 适合存储和访问数据,LinkedList 则更适合数据的处理,希望你以后在使用时可以合理的选择 List 结构。
<完>
Hello world : ) 我是阿朗,一线技术工具人,认认真真写文章。
点赞的个个都是人才,不仅长得帅气好看,说话还好听。
文章持续更新,可以关注公众号「 程序猿阿朗 」或访问「未读代码博客 」。
回复【资料】有我准备的各系列知识点和必看书籍。
本文 Github.com/niumoo/JavaNotes 已经收录,有很多知识点和系列文章,欢迎Star。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号