三种方法实现 生产者消费者模型
在并发编程中使用生产者和消费者模式能够解决绝大多数并发问题。
该模式通过平衡生产进程和消费进程的工作能力来提高程序的整体处理数据的速度。
举个应用栗子:
全栈开发时候,前端接收客户请求,后端处理请求逻辑。
当某时刻客户请求过于多的时候,后端处理不过来,
此时完全可以借助队列来辅助,将客户请求放入队列中,
后端逻辑代码处理完一批客户请求后马上从队列中继续获取,
这样平衡两端的效率。
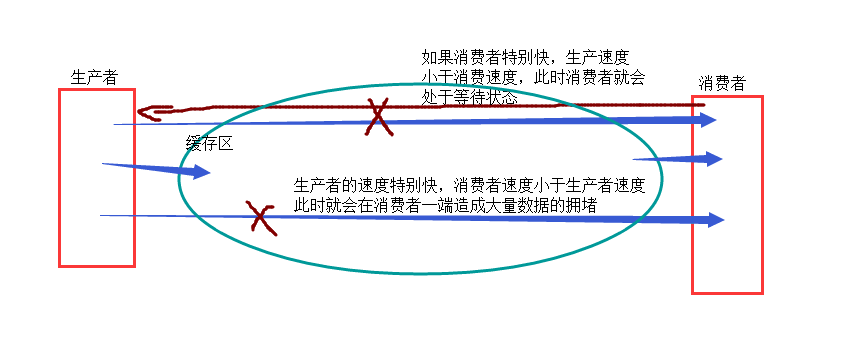
为什么要使用生产者和消费者模式
在进程世界里,生产者就是生产数据的进程,消费者就是消费数据的进程。
在多进程开发当中,如果生产者处理速度很快,而消费者处理速度很慢,那么生产者就必须等待消费者处理完,才能继续生产数据。
同样的道理,如果消费者的处理能力大于生产者,那么消费者就必须等待生产者。
为了解决这个问题于是引入了生产者和消费者模式。
什么是生产者消费者模式
生产者消费者模式是通过一个容器来解决生产者和消费者的强耦合问题。
生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,
所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,
消费者不找生产者要数据,而是直接从阻塞队列里取,
阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。
三种方法实现 生产者消费者模型:


1 from multiprocessing import Queue, Process 2 3 4 def producer(q, name): 5 for i in range(20): # 生产20个 6 info = name + '的娃娃%s' % str(i) # 产生数据 7 q.put(info) # 把数据放入队列 8 q.put(None) # 生产者生产完数据后,放入一个不再生产的标示None,消费者读取到None后可以知道数据已取完 9 10 11 def consumer(q, name): 12 while 1: # 循环接收数据 13 info = q.get() # 从队列中拿取数据 14 if info: # 如果队列中存在数据 15 print('%s拿走了%s' % (name, info)) # 打印 16 else: 17 break # 否则退出接收循环 18 19 20 if __name__ == '__main__': 21 q = Queue(10) # 先建立一个10长度的队列 22 p_pro = Process(target=producer, args=(q, '生产者')) # 创建生产者进程 23 p_con = Process(target=consumer, args=(q, '消费者')) # 创建消费者进程 24 p_pro.start() # 进程开始 25 p_con.start() # 进程开始
1 from multiprocessing import Process,Queue 2 3 def producer(q,name): 4 for i in range(1,21): 5 info = name + '的娃娃%s' % str(i) 6 q.put(info) 7 8 def consumer(q,name): 9 while 1: 10 info = q.get() 11 if info: 12 print(name+'拿了%s' % info) 13 else: 14 break 15 16 if __name__ == '__main__': 17 q = Queue(10) 18 p_pro1 = Process(target=producer,args=(q,'\033[31m生产者1\033[0m')) 19 p_pro2 = Process(target=producer,args=(q,'\033[32m生产者2\033[0m')) 20 p_pro3 = Process(target=producer,args=(q,'\033[33m生产者3\033[0m')) 21 p_con1 = Process(target=consumer,args=(q,'\033[34m消费者1\033[0m')) 22 p_con2 = Process(target=consumer,args=(q,'\033[35m消费者2\033[0m')) 23 p_l = [p_pro1,p_pro2,p_pro3,p_con1,p_con2] 24 [p.start() for p in p_l] #建立进程列表循环 开始每个进程 25 p_pro1.join() # 需要join 让主程序等待子程序结束,然后添加标示 26 p_pro2.join() # 有几个生产者 就需要几个join 27 p_pro3.join() # 28 q.put(None) # 有几个消费者就有几个结束标示 29 q.put(None) # 有几个消费者就有几个结束标示 30 # q.put(None) # 有几个消费者就有几个结束标示 31 # 这个None,先进后出,在队列的最后,所以最后读取到这个None的时候,表示队列已经取完了
1 from multiprocessing import Process, Pipe 2 3 4 def consumer(p, name): 5 produce, consume = p 6 produce.close() 7 while True: 8 try: 9 baozi = consume.recv() 10 print('%s 收到包子:%s' % (name, baozi)) 11 except EOFError: 12 break 13 14 15 def producer(seq, p): 16 produce, consume = p 17 consume.close() 18 for i in seq: 19 produce.send(i) 20 21 22 if __name__ == '__main__': 23 produce, consume = Pipe() 24 25 c1 = Process(target=consumer, args=((produce, consume), 'c1')) 26 c1.start() 27 28 seq = (i for i in range(10)) 29 producer(seq, (produce, consume)) 30 31 produce.close() 32 consume.close() 33 34 c1.join() 35 print('主进程')

