粘包
粘包问题:
所谓粘包问题主要还是因为接收方不知道消息之间的界限,不知道一次性提取多少字节的数据所造成的。
两种情况下会发生粘包。
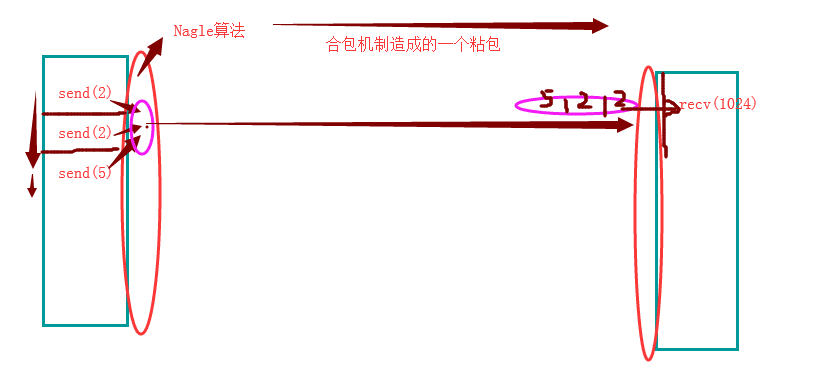
- 发送端需要等缓冲区满才发送出去,造成粘包(发送数据时间间隔很短,数据了很小,会合到一起,产生粘包)
- 接收方不及时接收缓冲区的包,造成多个包接收(客户端发送了一段数据,服务端只收了一小部分,服务端下次再收的时候还是从缓冲区拿上次遗留的数据,产生粘包)
只有tcp协议才会发送粘包,udp不会发生
EX: 发送端发送数据,接收端不知道应该如何去接收,造成的一种数据混乱的现象
在tcp协议中,
有一个合包机制(nagle算法): 将多次连续发送且间隔较小的数据,进行打包成一块数据传送.
还有一个机制是拆包机制: 在发送端,因为受到网卡的MTU限制,会将大的超过MTU限制的数据,进行拆分,拆分成多个小的数据,进行传输. 当传输到目标主机的操作系统层时,会重新将多个小的数据合并成原本的数据

针对使用udp协议发送数据,一次收发大小究竟多少合适?
num < 1472 是比较理想的状态
udp不会发生粘包,udp协议本层对一次收发数据大小的限制是:
65535 - ip包头(20) - udp包头(8) = 65507
站在数据链路层,因为网卡的MTU一般被限制在了1500,
所以对于数据链路层来说,一次收发数据的大小被限制在 1500 - ip包头(20) - udp包头(8) = 1472
得到结论:
如果sendto(num)
num > 65507 报错
1472 < num < 65507 会在数据链路层拆包,而udp本身就是不可靠协议,所以一旦拆包之后,造成的多个小数据包在网络传输中,如果丢任何一个,那么此次数据传输失败
num < 1472 是比较理想的状态
使用struct解决黏包
借助struct模块,我们知道长度数字可以被转换成一个标准大小的4字节数字。因此可以利用这个特点来预先发送数据长度。

我们还可以把报头做成字典,字典里包含将要发送的真实数据的详细信息,然后json序列化,然后用struck将序列化后的数据长度打包成4个字节(4个自己足够用了)