
Spring-Data-Redis
1.Redis支持
Spring Data支持的其中一个关键值存储是Redis。 官方如下:
“Redis是一个高级键值存储库。它类似于memcached数据集不是易变的,值可以是字符串,就像memcached一样,还有列表集和有序集。所有这些数据类型都可以操作使用原子操作来推送/弹出元素,添加/删除元素,执行服务器端联合、交集、集合之间的差异等等。Redis支持不同的排序能力。“
Spring Data Redis提供了从Spring应用程序轻松配置和访问Redis的功能。它提供了用于与存储交互的低级和高级抽象,使用户不必再关注基础设施。
1.1Redis要求
Spring Redis要求Redis 2.6或以上,Java SE 6.0或以上。在语言绑定方面Spring Redis与Jedis、JRedis(从1.7开始就弃用了)、SRP(弃用了)集成从1.7)和Lettuce,四个流行的开源Java库的Redis。如果你知道的话我们需要集成的其他连接器请给我们反馈。
1.2Redis支持高级视图
Redis支持提供几个组件(按照依赖关系的顺序):
对于大多数任务,高级抽象和支持服务是最佳选择。注意,在任何时候,都可以在层之间移动——例如,很容易获得低级连接(甚至本机库)来直接与Redis通信。
1.3连接Redis
使用Redis和Spring时的首要任务之一是通过IoC容器连接到存储。为此,需要一个Java连接器(或绑定)。无论您选择哪个库,您都只需要使用一组Spring Data Redis API,该API在所有连接器(即org.springframework.data.redis)上都具有一致的行为。连接包及其重新断开连接和重新断开连接工厂接口,用于处理并检索活动与Redis的联系。
1.3.1RedisConnection和RedisConnectionFactory
RedisConnection为Redis通信提供核心构建块,因为它处理与Redis后端的通信。 它还会自动将底层连接库异常转换为Spring的一致DAO异常层次结构,以便您可以在不更改任何代码的情况下切换连接器,因为操作语义保持不变。
注意:对于需要本机库API的极端情况,RedisConnection提供了一个专用方法(getNativeConnection),它返回用于通信的原始底层对象。
通过RedisConnectionFactory创建RedisConnection。 另外,工厂充当PersistenceExceptionTranslator,意思是一旦声明,它们允许一个人做透明的异常翻译。 例如,通过使用@Repository注释和AOP进行异常转换。 有关更多信息,请参阅Spring Framework文档中的专用部分
注意:根据基础配置的不同,工厂可以返回新的连接或现有连接(如果使用池或共享本机连接)。
使用RedisConnectionFactory最简单的方法是通过IoC容器配置相应的连接器并将其注入所要使用的类上。
不幸的是,目前并非所有连接器都支持所有Redis功能。 在基础库不支持的Connection API上调用方法时,将引发UnsupportedOperationException。
1.3.2配置Jedis连接器
Jedis是Spring Data Redis模块通过org.springframework.data.redis.connection.jedis包支持的连接器之一。 在最简单的形式中,Jedis配置如下所示:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
<!-- Jedis ConnectionFactory -->
<bean id="jedisConnectionFactory" class="org.springframework.data.redis.connection.jedis.JedisConnectionFactory"/>
</beans>但是,对于生产用途,您可能需要调整主机或密码等设置,如以下示例所示:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:p="http://www.springframework.org/schema/p"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="jedisConnectionFactory" class="org.springframework.data.redis.connection.jedis.JedisConnectionFactory" p:host-name="server" p:port="6379" />
</beans>1.3.3配置Lettuce连接器
Lettuce是Spring Data Redis通过org.springframework.data.redis.connection.lettuce包支持的第四个开源连接器。(有两个已经废弃了)
它的配置可能很容易猜到:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:p="http://www.springframework.org/schema/p"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="lettuceConnectionFactory" class="org.springframework.data.redis.connection.lettuce.LettuceConnectionFactory" p:host-name="server" p:port="6379"/>
</beans>还有一些可以调整的特定于Lettuce的连接参数。 默认情况下,LettuceConnectionFactory创建的所有LettuceConnection都为所有非阻塞和非事务操作共享相同的线程安全本机连接。 将shareNativeConnection设置为false以每次使用专用连接。 LettuceConnectionFactory也可以配置LettucePool用于池阻塞和事务连接,如果shareNativeConnection设置为false,则配置所有连接。
1.3.4Redis对哨兵模式的支持
为了处理高可用性Redis,Spring Data Redis使用RedisSentinelConfiguration支持Redis Sentinel,如以下示例所示:
请注意,目前只有Jedis和lettuce支持Redis Sentinel。
/**
* jedis
*/
@Bean
public RedisConnectionFactory jedisConnectionFactory() {
RedisSentinelConfiguration sentinelConfig = new RedisSentinelConfiguration() .master("mymaster")
.sentinel("127.0.0.1", 26379) .sentinel("127.0.0.1", 26380);
return new JedisConnectionFactory(sentinelConfig);
}
/**
* lettuce
*/
@Bean
public RedisConnectionFactory lettuceConnectionFactory() {
RedisSentinelConfiguration sentinelConfig = new RedisSentinelConfiguration().master("mymaster")
.sentinel("127.0.0.1", 26379) .sentinel("127.0.0.1", 26380);
return new LettuceConnectionFactory(sentinelConfig);
}RedisSentinelConfiguration也可以使用PropertySource定义,它允许您设置以下属性:
配置属性
spring.redis.sentinel.master:主节点的名称。
spring.redis.sentinel.nodes:逗号分隔的主机:端口对列表。
以上spring.redis.sentinel.master,spring.redis.sentinel.nodes也是在springboot中的配置。
有时,需要与其中一个Sentinels直接交互。 使用RedisConnectionFactory.getSentinelConnection()或RedisConnection.getSentinelCommands()可以访问配置的第一个活动Sentinel。
1.4通过RedisTemplate处理对象
大多数用户可能会使用RedisTemplate及其相应的软件包org.springframework.data.redis.core。 事实上,模板由于其丰富的功能集而成为Redis模块的中心类。 该模板为Redis交互提供了高级抽象。 虽然RedisConnection提供接受和返回二进制值(字节数组)的低级方法,但模板负责序列化和连接管理,使用户无需处理此类详细信息。
此外,模板提供操作视图(在Redis命令参考的分组之后),提供丰富的,通用的接口,用于处理特定类型或某些密钥(通过KeyBound接口),如下表所述:
表1.操作视图
| Interface | Description |
|---|---|
|
Key Type Operations |
|
|
|
Redis geospatial operations, such as |
|
|
Redis hash operations |
|
|
Redis HyperLogLog operations, such as |
|
|
Redis list operations |
|
|
Redis set operations |
|
|
Redis string (or value) operations |
|
|
Redis zset (or sorted set) operations |
|
HashOperations |
Redis hash operations |
|
HyperLogLogOperations |
Redis HyperLogLog operations like (pfadd, pfcount,…) |
|
GeoOperations |
Redis geospatial operations like |
|
Key Bound Operations |
|
|
|
Redis key bound geospatial operations |
|
|
Redis hash key bound operations |
|
|
Redis key bound operations |
|
|
Redis list key bound operations |
|
|
Redis set key bound operations |
|
|
Redis string (or value) key bound operations |
|
|
Redis zset (or sorted set) key bound operations |
|
BoundHashOperations |
Redis hash key bound operations |
|
BoundGeoOperations |
Redis key bound geospatial operations. |
配置完成后,模板是线程安全的,可以跨多个实例重用。
RedisTemplate在其大多数操作中使用基于Java的序列化程序。 这意味着模板编写或读取的任何对象都是通过Java序列化和反序列化的。 您可以更改模板上的序列化机制,Redis模块提供了几个实现,这些实现可以在org.springframework.data.redis.serializer包中找到。 有关更多信息,请参阅序列化器 您还可以将任何序列化程序设置为null,并通过将enableDefaultSerializer属性设置为false将RedisTemplate与原始字节数组一起使用。 请注意,模板要求所有键都为非null。 但是,只要底层序列化程序接受它们,值就可以为null。 阅读每个序列化程序的Javadoc以获取更多信息。
对于需要特定模板视图的情况,请将视图声明为依赖项并注入模板。 容器自动执行转换,消除了opsFor [X]调用,如以下示例所示:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:p="http://www.springframework.org/schema/p"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="jedisConnectionFactory" class="org.springframework.data.redis.connection.jedis.JedisConnectionFactory" p:use-pool="true"/>
<!-- redis template definition -->
<bean id="redisTemplate" class="org.springframework.data.redis.core.RedisTemplate" p:connection-factory-ref="jedisConnectionFactory"/>
...
</beans>public class Example {
// 注入实际模板
@Autowired
private RedisTemplate<String, String> template;
// 将模板注入ListOperations
@Resource(name="redisTemplate")
private ListOperations<String, String> listOps;
public void addLink(String userId, URL url) {
listOps.leftPush(userId, url.toExternalForm());
}
}1.5以字符串为中心的便捷类
由于存储在Redis中的键和值通常是java.lang.String,因此Redis模块提供了RedisConnection和RedisTemplate的两个扩展,分别是StringRedisConnection(及其DefaultStringRedisConnection实现)和StringRedisTemplate作为方便的一站式解决方案 用于密集的String操作。 除了绑定到String键之外,模板和连接还使用下面的StringRedisSerializer,这意味着存储的键和值是人类可读的(假设在Redis和代码中都使用相同的编码)。 以下列表显示了一个示例:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:p="http://www.springframework.org/schema/p"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="jedisConnectionFactory" class="org.springframework.data.redis.connection.jedis.JedisConnectionFactory" p:use-pool="true"/>
<bean id="stringRedisTemplate" class="org.springframework.data.redis.core.StringRedisTemplate" p:connection-factory-ref="jedisConnectionFactory"/>
...
</beans>public class Example {
@Autowired
private StringRedisTemplate redisTemplate;
public void addLink(String userId, URL url) {
redisTemplate.opsForList().leftPush(userId, url.toExternalForm());
}
}与其他Spring模板一样,RedisTemplate和StringRedisTemplate允许您通过RedisCallback接口直接与Redis对话。 此功能为您提供完全控制,因为它直接与RedisConnection对话。 请注意,当使用StringRedisTemplate时,回调会接收StringRedisConnection的实例。 以下示例显示如何使用RedisCallback接口:
public void useCallback() {
redisTemplate.execute(new RedisCallback<Object>() {
public Object doInRedis(RedisConnection connection) throws DataAccessException {
Long size = connection.dbSize();
// 如果使用StringRedisTemplate,则可以强制转换为StringRedisConnection
((StringRedisConnection)connection).set("key", "value");
}
});
}1.6序列化
从框架的角度来看,存储在Redis中的数据只是字节数。 虽然Redis本身支持各种类型,但在大多数情况下,这些类型指的是数据的存储方式而不是它所代表的方式。 由用户决定信息是否被翻译成字符串或任何其他对象。
在Spring Data中,用户(自定义)类型和原始数据之间的转换在Redis的org.springframework.data.redis.serializer包中处理。
![]() 以上为redis序列化支持的方式。
以上为redis序列化支持的方式。
该软件包包含两种类型的序列化程序,顾名思义,它们负责序列化过程:
- 基于RedisSerializer的双向序列化器。
- 使用RedisElementReader和RedisElementWriter的元素读取器和写入器。
这些变体之间的主要区别是,RedisSerializer主要被序列化为byte[],而读取器和写入器则使用ByteBuffer。
可以使用多种实现(包括本文档中已经提到的两种实现):
- JdkSerializationRedisSerializer,默认用于RedisCache和RedisTemplate。
- StringRedisSerializer。
但是,可以使用OxmSerializer通过Spring OXM支持进行对象/ XML映射,或者使用Jackson2JsonRedisSerializer或GenericJackson2JsonRedisSerializer来以JSON格式存储数据。
注意:
默认情况下,RedisCache和RedisTemplate配置为使用Java本机序列化。众所周知,Java本机序列化允许远程执行由有效负载导致的代码,有效负载利用漏洞库和类注入未经验证的字节码。在反序列化过程中,被操纵的输入可能导致应用程序中不必要的代码执行。因此,不要在不可信的环境中使用序列化。通常,我们强烈建议使用任何其他消息格式(比如JSON)。
如果您担心由于Java序列化导致的安全漏洞,请考虑核心JVM级别的通用序列化过滤机制,最初是为JDK 9开发但向后移植到JDK 8,7和6:
- 过滤传入的序列化数据。
- JEP 290。
- OWASP:不受信任数据的反序列化。
1.7哈希映射(Hash Map)
可以使用Redis中的各种数据结构存储数据。 Jackson2JsonRedisSerializer可以转换JSON格式的对象。 理想情况下,可以使用普通键将JSON存储为值。 您可以使用Redis哈希实现更复杂的结构化对象映射。 Spring Data Redis提供了各种将数据映射到哈希的策略(取决于用例):
- 通过使用HashOperations和序列化程序直接映射
- 使用Redis存储库
- 使用HashMapper和HashOperations
1.7.1Hash Mappers
哈希映射器是映射对象到Map<K, V> 和Back的转换器。HashMapper用于与Redis哈希表一起使用。
- 使用Spring的BeanUtils的BeanUtilsHashMapper。
- ObjectHashMapper使用Object-to-Hash Mapping。
- Jackson2HashMapper使用FasterXML Jackson。
以下示例显示了实现哈希映射的一种方法:
public class Person {
String firstname;
String lastname;
// …
}
public class HashMapping {
@Autowired
HashOperations<String, byte[], byte[]> hashOperations;
HashMapper<Object, byte[], byte[]> mapper = new ObjectHashMapper();
public void writeHash(String key, Person person) {
Map<byte[], byte[]> mappedHash = mapper.toHash(person);
hashOperations.putAll(key, mappedHash);
}
public Person loadHash(String key) {
Map<byte[], byte[]> loadedHash = hashOperations.entries("key");
return (Person) mapper.fromHash(loadedHash);1.7.1Jackson2HashMapper
Jackson2HashMapper使用FasterXML Jackson为域对象提供Redis Hash映射。 Jackson2HashMapper可以将顶级属性映射为哈希字段名称,并可选择展平结构。 简单类型映射到简单值。 复杂类型(嵌套对象,集合,映射等)表示为嵌套JSON。
Flattening 为所有嵌套属性创建单独的哈希条目,并尽可能将复杂类型解析为简单类型。
考虑以下类及其包含的数据结构:
public class Person {
String firstname;
String lastname;
Address address;
}
public class Address {
String city;
String country;
}下表显示了前一类中的数据如何在法线贴图中显示:
![]()
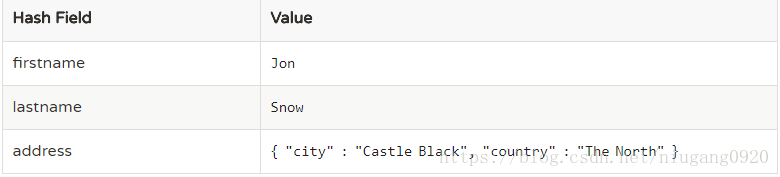
下表显示了前一类中的数据如何在平面映射中显示:
![]()

Flattening需要所有属性名称不会干扰JSON路径。 使用Flattening时,不支持在地图键中使用点或括号或作为属性名称。 生成的哈希不能映射回Object。
注意JSON序列化,需要修改RedisTemplate默认的序列化方式,默认是采用JDK序列化。添加如下配置(附带配置了redis中的发布与订阅模式,下一节也会讲到redis中的发布与订阅者模式):
#redis
spring.redis.host=localhost
spring.redis.port=6379
spring.redis.pool.max-idle=3
spring.redis.pool.max-active=20
package org.niugang.config;
import org.niugang.mq.MessageDelegate;
import org.niugang.mq.MessageDelegateImpl;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.jedis.JedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.data.redis.listener.ChannelTopic;
import org.springframework.data.redis.listener.RedisMessageListenerContainer;
import org.springframework.data.redis.listener.adapter.MessageListenerAdapter;
import org.springframework.data.redis.serializer.Jackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.StringRedisSerializer;
import com.fasterxml.jackson.annotation.JsonAutoDetect;
import com.fasterxml.jackson.annotation.PropertyAccessor;
import com.fasterxml.jackson.databind.ObjectMapper;
import redis.clients.jedis.JedisPoolConfig;
/**
*
* @Description:redis配置相关类
* @Project:boot-sis
* @File:RedisConfig.java
* @Package:org.niugang.config
* @Date:2018年7月2日上午9:32:36
* @author:niugang
* @Copyright (c) 2018, 863263957@qq.com All Rights Reserved.
*
*/
@Configuration
public class RedisConfig {
@Value("${spring.redis.host}")
public String host;
@Value("${spring.redis.port}")
public int port;
@Value("${spring.redis.pool.max-idle}")
public int maxIdle;
@Value("${spring.redis.pool.max-active}")
public int maxActive;
@Bean
public JedisConnectionFactory jedisConnectionFactory() {
JedisConnectionFactory jedisConnectionFactory = new JedisConnectionFactory();
jedisConnectionFactory.setHostName(host);
jedisConnectionFactory.setPort(port);
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
jedisPoolConfig.setMaxIdle(maxIdle);
jedisPoolConfig.setMaxTotal(maxActive);
jedisConnectionFactory.setPoolConfig(jedisPoolConfig);
return jedisConnectionFactory;
}
// 默认用的是用JdkSerializationRedisSerializer进行序列化的
@Bean
@SuppressWarnings({ "rawtypes", "unchecked" })
public RedisTemplate<String, Object> redisTemplate() {
RedisTemplate<String, Object> redisTemplate = new RedisTemplate<String, Object>();
// 注入数据源
redisTemplate.setConnectionFactory(jedisConnectionFactory());
// 使用Jackson2JsonRedisSerialize 替换默认序列化
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
StringRedisSerializer stringRedisSerializer = new StringRedisSerializer();
ObjectMapper objectMapper = new ObjectMapper();
objectMapper.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
objectMapper.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
jackson2JsonRedisSerializer.setObjectMapper(objectMapper);
// key-value结构序列化数据结构
redisTemplate.setKeySerializer(stringRedisSerializer);
redisTemplate.setValueSerializer(jackson2JsonRedisSerializer);
// hash数据结构序列化方式,必须这样否则存hash 就是基于jdk序列化的
redisTemplate.setHashKeySerializer(stringRedisSerializer);
redisTemplate.setHashValueSerializer(jackson2JsonRedisSerializer);
// 启用默认序列化方式
redisTemplate.setEnableDefaultSerializer(true);
redisTemplate.setDefaultSerializer(jackson2JsonRedisSerializer);
/// redisTemplate.afterPropertiesSet();
return redisTemplate;
}
@Bean
public StringRedisTemplate stringRedisTemplate() {
return new StringRedisTemplate(jedisConnectionFactory());
}
// ################发布订阅配置###################################
@Bean
public MessageDelegate messageDelegate() {
return new MessageDelegateImpl();
}
@Bean
public MessageListenerAdapter messageListener() {
MessageListenerAdapter messageListenerAdapter = new
MessageListenerAdapter(messageDelegate());
return messageListenerAdapter;
}
/**
* RedisMessageListenerContainer充当消息侦听器容器;它用于接收来自Redis通道的消息,
* 并驱动注入到其中的MessageListeners。侦听器容器负责消息接收的所有线程,并将消息分派到侦听器中进行处理。
* 消息侦听器容器是MDP(message-driven POJOs)和消息传递提供程序之间的中介 负责注册接收消息,资源获取和发布,异常。
*
* 转换等
*/
@Bean
public RedisMessageListenerContainer redisContainer() {
RedisMessageListenerContainer con = new RedisMessageListenerContainer();
con.setConnectionFactory(jedisConnectionFactory());
ChannelTopic channelTopic = new ChannelTopic("log_queue");
con.addMessageListener(messageListener(), channelTopic);
return con;
}
}package org.niugang.mq;
import java.io.Serializable;
import java.util.Map;
/**
* 考虑下面的接口定义。
* 注意,尽管接口没有扩展MessageListener接口,仍然可以通过使用MessageListenerAdapter将其用作MDP
* 类(容器中配置)。还要注意各种消息处理方法是如何根据
*
* 它们可以接收和处理的各种消息类型的内容
*
* @author niugang
*
*/
public interface MessageDelegate {
// 默认监听的方法就是handleMessage
void handleMessage(String message);
/*
* void handleMessage(Map message); void handleMessage(byte[] message); void
* handleMessage(Serializable message); // pass the channel/pattern as well
* void handleMessage(Serializable message, String channel);
*/
}
package org.niugang.mq;
import java.util.UUID;
import org.apache.commons.lang3.StringUtils;
import org.niugang.bean.LogParseBean;
import org.niugang.elasticsearch.entity.LogEntity;
import org.niugang.elasticsearch.service.LogService;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.BeanUtils;
import org.springframework.beans.factory.annotation.Autowired;
import com.alibaba.fastjson.JSON;
/**
*
* @Description:reids消息接收实现类
* @Project:boot-sis
* @File:MessageDelegateImpl.java
* @Package:org.niugang.mq
* @Date:2018年7月2日上午9:37:08
* @author:niugang
* @Copyright (c) 2018, 863263957@qq.com All Rights Reserved.
*
*/
public class MessageDelegateImpl implements MessageDelegate {
private static final Logger logger = LoggerFactory.getLogger(MessageDelegateImpl.class);
@Autowired
private LogService logService;
public void handleMessage(String message) {
if (StringUtils.isNotBlank(message)) {
logger.info("log message :{}", message);
LogParseBean parseObject = JSON.parseObject(message, LogParseBean.class);
if(StringUtils.isNotBlank(parseObject.getType())) {
LogEntity logEntity = new LogEntity();
BeanUtils.copyProperties(parseObject, logEntity);
logEntity.setId(UUID.randomUUID().toString().replaceAll("\\-", ""));
logService.save(logEntity);
}
}
}
}
1.8Redis消息(Pub / Sub)
Spring Data为Redis提供了专用的消息传递集成,功能类似,并命名为Spring Framework中的JMS集成。
Redis消息传递大致可分为两个功能区域:
- 发布或制作消息
- 订阅或消费消息
这是通常称为Publish / Subscribe(简称Pub / Sub)的模式示例。 RedisTemplate类用于生成消息。 对于类似于Java EE的消息驱动bean样式的异步接收,Spring Data提供了一个专用的消息监听器容器,用于创建消息驱动的POJO(MDP),以及用于同步接收的RedisConnection合同。
org.springframework.data.redis.connection和org.springframework.data.redis.listener 包提供了Redis消息传递的核心功能。
1.8.1发布(发送消息)
要发布消息,您可以像使用其他操作一样使用低级RedisConnection或高级RedisTemplate。 两个实体都提供publish方法,该方法接受消息和目标通道作为参数。 虽然RedisConnection需要原始数据(字节数组),但RedisTemplate允许将任意对象作为消息传入,如以下示例所示:
// send message through connection RedisConnection con = ...
byte[] msg = ...
byte[] channel = ...
con.publish(msg, channel); // send message through RedisTemplate
RedisTemplate template = ...
template.convertAndSend("hello!", "world");1.8.2订阅(接收消息)
在接收方,可以通过直接命名它们或使用模式匹配来订阅一个或多个通道。 后一种方法非常有用,因为它不仅可以使用一个命令创建多个订阅,还可以监听尚未在订阅时创建的通道(只要它们与模式匹配)。
在低级别,RedisConnection提供subscribe和pSubscribe方法,分别映射Redis命令以按通道或按模式进行订阅。 请注意,可以使用多个通道或模式作为参数。 要更改连接或查询是否正在侦听的订阅,RedisConnection将提供getSubscription和isSubscribed方法。
注意:
Spring Data Redis中的订阅命令是阻止的。 也就是说,在连接上调用subscribe会导致当前线程在开始等待消息时阻塞。 只有在取消订阅时才会释放该线程,这在另一个线程在同一连接上调用unsubscribe或pUnsubscribe时会发生。 有关此问题的解决方案,请参阅“消息侦听器容器”(本文档后面部分)。
如前所述,一旦订阅,连接就开始等待消息。 仅允许添加新订阅,修改现有订阅和取消现有订阅的命令。 调用除subscribe,pSubscribe,unsubscribe或pUnsubscribe之外的任何内容都会引发异常。
为了订阅消息,需要实现MessageListener回调。 每次新消息到达时,都会调用回调,并且用户代码由onMessage方法运行。 该接口不仅可以访问实际消息,还可以访问通过它接收的通道以及订阅用于匹配通道的模式(如果有)。 此信息使被叫方不仅可以通过内容区分各种消息,还可以检查其他详细信息。
消息侦听器容器
由于其阻塞性质,低级订阅不具吸引力,因为它需要每个侦听器的连接和线程管理。 为了缓解这个问题,Spring Data提供了RedisMessageListenerContainer,它完成了所有繁重的工作。 如果您熟悉EJB和JMS,那么您应该找到熟悉的概念,因为它的设计尽可能接近Spring Framework及其消息驱动的POJO(MDP)中的支持。
RedisMessageListenerContainer充当消息侦听器容器。 它用于从Redis通道接收消息并驱动注入其中的MessageListener实例。 侦听器容器负责消息接收的所有线程并将其分派到侦听器进行处理。 消息监听器容器是MDP和消息传递提供者之间的中介,并负责注册以接收消息,资源获取和释放,异常转换等。 这使您作为应用程序开发人员可以编写与接收消息(并对其做出反应)相关联的(可能是复杂的)业务逻辑,并将样板Redis基础结构关注委托给框架。
此外,为了最小化应用程序占用空间,RedisMessageListenerContainer允许多个侦听器共享一个连接和一个线程,即使它们不共享订阅。 因此,无论应用程序跟踪多少个侦听器或通道,运行时成本在其整个生命周期内保持不变。 此外,容器允许更改运行时配置,以便您可以在应用程序运行时添加或删除侦听器,而无需重新启动。 此外,容器使用延迟订阅方法,仅在需要时使用RedisConnection。 如果所有侦听器都已取消订阅,则会自动执行清理,并释放该线程。
为了帮助消息的异步性,容器需要一个java.util.concurrent.Executor(或Spring的TaskExecutor)来分派消息。 根据负载,侦听器数量或运行时环境,您应该更改或调整执行程序以更好地满足您的需求。 特别是,在托管环境(例如app服务器)中,强烈建议选择适当的TaskExecutor来利用其运行时。
MessageListenerAdapter
MessageListenerAdapter类是Spring异步消息传递支持的最后一个组件。 简而言之,它允许您将几乎任何类暴露为MDP(尽管存在一些约束)。
请考虑以下接口定义:
public interface MessageDelegate {
void handleMessage(String message);
void handleMessage(Map message); void handleMessage(byte[] message);
void handleMessage(Serializable message);
// pass the channel/pattern as well
void handleMessage(Serializable message, String channel);
}请注意,虽然接口不扩展MessageListener接口,但仍可以使用MessageListenerAdapter类将其用作MDP。 还要注意各种消息处理方法如何根据它们可以接收和处理的各种消息类型的内容进行强类型化。 此外,发送消息的通道或模式可以作为String类型的第二个参数传递给方法:
public class DefaultMessageDelegate implements MessageDelegate {
// implementation elided for clarity...
}注意MessageDelegate接口的上述实现(上面的DefaultMessageDelegate类)根本没有Redis依赖。 它确实是我们用MDP制作的POJO,具有以下配置:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:redis="http://www.springframework.org/schema/redis"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/redis http://www.springframework.org/schema/redis/spring-redis.xsd">
<!-- the default ConnectionFactory -->
<redis:listener-container>
<!-- the method attribute can be skipped as the default method name is "handleMessage" -->
<redis:listener ref="listener" method="handleMessage" topic="chatroom" />
</redis:listener-container>
<bean id="listener" class="redisexample.DefaultMessageDelegate"/>
...
<beans>侦听器主题可以是通道(例如,topic =“chatroom”)或模式(例如,topic =“*room”)
前面的示例使用Redis命名空间声明消息侦听器容器并自动将POJO注册为侦听器。 完整的bean定义如下:
<bean id="messageListener" class="org.springframework.data.redis.listener.adapter.MessageListenerAdapter">
<constructor-arg>
<bean class="redisexample.DefaultMessageDelegate"/>
</constructor-arg>
</bean>
<bean id="redisContainer" class="org.springframework.data.redis.listener.RedisMessageListenerContainer">
<property name="connectionFactory" ref="connectionFactory"/>
<property name="messageListeners">
<map>
<entry key-ref="messageListener">
<bean class="org.springframework.data.redis.listener.ChannelTopic">
<constructor-arg value="chatroom">
</bean>
</entry>
</map>
</property>
</bean>每次收到消息时,适配器都会自动且透明地在低级格式和所需对象类型之间执行转换(使用配置的RedisSerializer)。 由方法调用引起的任何异常都由容器捕获并处理(默认情况下,会记录异常)。
1.9Redis事务
Redis通过multi,exec和discard命令为事务提供支持。 RedisTemplate上提供了这些操作。 但是,不保证RedisTemplate使用相同的连接执行事务中的所有操作。
Spring Data Redis提供SessionCallback接口,以便在需要使用相同连接执行多个操作时使用,例如使用Redis事务时。 以下示例使用multi方法:
//执行一个事务
List<Object> txResults = redisTemplate.execute(new SessionCallback<List<Object>>() {
public List<Object> execute(RedisOperations operations) throws DataAccessException {
operations.multi();
operations.opsForSet().add("key", "value1");
//这将包含事务中所有操作的结果
return operations.exec();
}
});
System.out.println("Number of items added to set: " + txResults.get(0));RedisTemplate使用其值,散列键和散列值序列化程序在返回之前反序列化exec的所有结果。 还有一个额外的exec方法,允许您为事务结果传递自定义序列化程序。
从1.1版开始,RedisConnection和RedisTemplate的exec方法发生了重大变化。 以前,这些方法直接从连接器返回事务的结果。 这意味着数据类型通常与RedisConnection方法返回的数据类型不同。 例如,zAdd返回一个布尔值,指示元素是否已添加到有序集。 大多数连接器将此值作为long返回,Spring Data Redis执行转换。 另一个常见的区别是大多数连接器为诸如set之类的操作返回状态答复(通常是字符串,OK)。 Spring Data Redis通常会丢弃这些回复。 在1.1之前,没有对exec的结果进行这些转换。 此外,RedisTemplate中的结果未反序列化,因此它们通常包含原始字节数组。 如果此更改破坏了您的应用程序,请在RedisConnectionFactory上将convertPipelineAndTxResults设置为false以禁用此行为。
1.9.1@Transactional支持
默认情况下,事务支持已禁用,必须通过设置setEnableTransactionSupport(true)为每个正在使用的RedisTemplate显式启用。 这样做会强制将当前RedisConnection绑定到触发MULTI的当前Thread。 如果事务完成且没有错误,则调用EXEC。 否则调用DISCARD。 进入MULTI后,RedisConnection会对写入操作进行排队。 所有只读操作(如KEYS)都通过管道传输到一个新的(非线程绑定的)RedisConnection。
以下示例显示了如何配置事务管理:
示例1.启用事务管理的配置
@Configuration
@EnableTransactionManagement //1
public class RedisTxContextConfiguration {
//2
@Bean
public StringRedisTemplate redisTemplate() {
StringRedisTemplate template = new StringRedisTemplate(redisConnectionFactory());
// 显式地启用事务支持
template.setEnableTransactionSupport(true);
return template;
}
@Bean
public RedisConnectionFactory redisConnectionFactory() {
// jedis || Lettuce
}
//2
@Bean
public PlatformTransactionManager transactionManager() throws SQLException {
return new DataSourceTransactionManager(dataSource());
}
@Bean
public DataSource dataSource() throws SQLException {
// ...
}
}1.配置Spring Context以启用声明式事务管理。
2.将RedisTemplate配置为通过绑定到当前线程的连接来参与事务。
3.事务管理需要PlatformTransactionManager。 Spring Data Redis不附带PlatformTransactionManager实现。 假设您的应用程序使用JDBC,Spring Data Redis可以使用现有的事务管理器参与事务。
以下示例均演示了使用限制:
示例2.使用限制
// 必须在线程绑定上执行
template.opsForValue().set("thing1", "thing2");
// 读取操作必须在一个自由的(不支持事务的)连接上执行
template.keys("*");
// 返回null,因为事务中设置的值不可见
template.opsForValue().get("thing1");1.10Pipelining
Redis支持流水线操作,包括将多个命令发送到服务器而无需等待回复,然后在一个步骤中读取回复。 当您需要连续发送多个命令时,流水线操作可以提高性能,例如向同一个List添加许多元素。
Spring Data Redis提供了几种RedisTemplate方法,用于在管道中执行命令。 如果您不关心流水线操作的结果,则可以使用标准的execute方法,为pipeline参数传递true。 executePipelined方法在管道中运行提供的RedisCallback或SessionCallback并返回结果,如以下示例所示:
@Autowired
private StringRedisTemplate stringRedisTemplate;
@Autowired
private RedisTemplate redisTemplate;
@Test
public void test3() {
List<Object> results = stringRedisTemplate.executePipelined(new RedisCallback<Object>() {
public Object doInRedis(RedisConnection connection) throws DataAccessException {
StringRedisConnection stringRedisConn = (StringRedisConnection) connection;
for (int i = 0; i < 10; i++) {
stringRedisConn.lPush("333", i + "");
}
return null;
}
});
System.out.println(results);
}
@SuppressWarnings("unchecked")
@Test
public void test4() {
//即命令的执行执行
List<Object> results = redisTemplate.executePipelined(new RedisCallback<Object>() {
public Object doInRedis(RedisConnection connection) throws DataAccessException {
for (int i = 0; i < 10; i++) {
connection.lPush("4444".getBytes(),RandomStringUtils.randomNumeric(5).getBytes());
}
return null;
}
});
System.out.println(results);
}请注意,从RedisCallback返回的值必须为null,因为此值将被丢弃,以支持返回流水线命令的结果。
从1.1版开始,RedisConnection和RedisTemplate的exec方法发生了重大变化。 以前,这些方法直接从连接器返回事务的结果。 这意味着数据类型通常与RedisConnection方法返回的数据类型不同。 例如,zAdd返回一个布尔值,指示元素是否已添加到有序集。 大多数连接器将此值作为long返回,Spring Data Redis执行转换。 另一个常见的区别是大多数连接器为诸如set之类的操作返回状态答复(通常是字符串,OK)。 Spring Data Redis通常会丢弃这些回复。 在1.1之前,没有对exec的结果进行这些转换。 此外,RedisTemplate中的结果未反序列化,因此它们通常包含原始字节数组。 如果此更改破坏了您的应用程序,请在RedisConnectionFactory上将convertPipelineAndTxResults设置为false以禁用此行为。
1.11 Redis 脚本
Redis 2.6及更高版本通过eval和evalsha命令提供对Lua脚本执行的支持。 Spring Data Redis为脚本执行提供高级抽象,处理序列化并自动使用Redis脚本缓存。
可以通过调用RedisTemplate和ReactiveRedisTemplate的execute方法来运行脚本。 两者都使用可配置的ScriptExecutor(或ReactiveScriptExecutor)来运行提供的脚本。 默认情况下,ScriptExecutor(或ReactiveScriptExecutor)负责序列化提供的键和参数以及反序列化脚本结果。 这是通过模板的键和值序列化程序完成的。 还有一个额外的重载,允许您为脚本参数和结果传递自定义序列化程序。
默认的ScriptExecutor通过检索脚本的SHA1并首先尝试运行evalsha来优化性能,如果Redis脚本缓存中尚不存在脚本,则回退到eval。
以下示例使用Lua脚本运行常见的“检查和设置”方案。 这是Redis脚本的理想用例,因为它要求以原子方式运行一组命令,并且一个命令的行为受另一个命令的结果的影响。
@Bean
public RedisScript<Boolean> script() {
ScriptSource scriptSource = new ResourceScriptSource(new ClassPathResource("META-INF/scripts/checkandset.lua");
return RedisScript.of(scriptSource, Boolean.class);
}public class Example {
@Autowired
RedisScript<Boolean> script;
public boolean checkAndSet(String expectedValue, String newValue) {
return redisTemplate.execute(script, singletonList("key"), asList(expectedValue, newValue));
}
}-- checkandset.lua
local current = redis.call('GET', KEYS[1])
if current == ARGV[1]
then redis.call('SET', KEYS[1], ARGV[2])
return true
end
return false上面的代码配置一个指向名为checkandset.lua的文件的RedisScript,该文件应返回一个布尔值。 脚本resultType应该是Long,Boolean,List或反序列化值类型之一。 如果脚本返回丢弃状态(具体地说,OK),它也可以为null。
在应用程序上下文中配置DefaultRedisScript的单个实例是理想的,以避免在每次脚本执行时重新计算脚本的SHA1。
然后上面的checkAndSet方法运行脚本。 脚本可以作为事务或管道的一部分在SessionCallback中运行。 有关详细信息,请参阅“Redis Transactions”和“Pipelining”。
Spring Data Redis提供的脚本支持还允许您使用Spring Task和Scheduler抽象来安排Redis脚本定期执行。 有关更多详细信息,请参阅Spring Framework文档。
2.Redis集群
使用Redis群集需要Redis Server 3.0+版。 有关详细信息,请参阅群集教程。
https://redis.io/topics/cluster-tutorial
2.1 启用Redis群集
群集支持基于与非群集通信相同的构建块。 RedisClusterConnection是RedisConnection的扩展,它处理与Redis群集的通信,并将错误转换为Spring DAO异常层次结构。 RedisClusterConnection实例是使用RedisConnectionFactory创建的,必须使用关联的RedisClusterConfiguration进行设置,如以下示例所示:
示例3. Redis群集的RedisConnectionFactory配置示例
@Component
@ConfigurationProperties(prefix = "spring.redis.cluster")
public class ClusterConfigurationProperties {
/*
* spring.redis.cluster.nodes[0] = 127.0.0.1:7379
* spring.redis.cluster.nodes[1] = 127.0.0.1:7380
* ...
*/
List<String> nodes;
/**
* Get initial collection of known cluster nodes in format {@code host:port}.
*
* @return
*/
public List<String> getNodes() {
return nodes;
}
public void setNodes(List<String> nodes) {
this.nodes = nodes;
}
}
@Configuration
public class AppConfig {
/**
* Type safe representation of application.properties
*/
@Autowired ClusterConfigurationProperties clusterProperties;
public @Bean RedisConnectionFactory connectionFactory() {
return new JedisConnectionFactory(
new RedisClusterConfiguration(clusterProperties.getNodes()));
}
}RedisClusterConfiguration也可以通过PropertySource定义,并具有以下属性:
配置属性
spring.redis.cluster.nodes:逗号分隔的主机:端口对列表。
spring.redis.cluster.max-redirects:允许的群集重定向数。
注意:初始配置将驱动程序库指向一组初始集群节点。 实时群集重新配置导致的更改仅保留在本机驱动程序中,不会写回配置。
2.2使用Redis群集连接
如前所述,Redis Cluster的行为与单节点Redis或Sentinel监控的主从环境不同。 这是因为自动分片将密钥映射到16384个插槽之一,这些插槽分布在节点上。 因此,涉及多个密钥的命令必须断言所有密钥映射到完全相同的插槽,以避免跨时隙执行错误。 单个群集节点仅提供一组专用密钥。 针对一个特定服务器发出的命令仅返回该服务器所服务的密钥的结果。 举个简单的例子,考虑一下KEYS命令。 当发布到群集环境中的服务器时,它仅返回请求发送到的节点所服务的密钥,而不一定返回群集中的所有密钥。 因此,要在集群环境中获取所有密钥,必须从所有已知主节点读取密钥。
虽然驱动程序库可以处理特定键到相应插槽服务节点的重定向,但RedisClusterConnection可以涵盖更高级别的功能,例如跨节点收集信息或向集群中的所有节点发送命令。 从前面提取密钥示例,这意味着密钥(模式)方法获取集群中的每个主节点,同时在每个主节点上执行KEYS命令,同时获取结果并返回累积的密钥集。 要仅请求单个节点的密钥,RedisClusterConnection会为这些方法提供重载(例如,密钥(节点,模式))。
可以从RedisClusterConnection.clusterGetNodes获取RedisClusterNode,也可以使用主机和端口或节点Id构建RedisClusterNode。
以下示例显示了在集群中运行的一组命令:
redis-cli@127.0.0.1:7379 > cluster nodes
6b38bb... 127.0.0.1:7379 master - 0 0 25 connected 0-5460 1
7bb78c... 127.0.0.1:7380 master - 0 1449730618304 2 connected 5461-10922 2
164888... 127.0.0.1:7381 master - 0 1449730618304 3 connected 10923-16383 3
b8b5ee... 127.0.0.1:7382 slave 6b38bb... 0 1449730618304 25 connected 4
RedisClusterConnection connection = connectionFactory.getClusterConnnection();
connection.set("thing1", value); 5
connection.set("thing2", value); 6
connection.keys("*"); 7
connection.keys(NODE_7379, "*"); 8
connection.keys(NODE_7380, "*"); 9
connection.keys(NODE_7381, "*"); 10
connection.keys(NODE_7382, "*"); 11 1.主节点服务时隙0到5460在7382复制到从机
2.主节点服务时隙5461到10922
3.主节点服务时隙10923到16383
4.从节点在7379处持有主节点的复制者
5.请求路由到服务时隙12182的7381处的节点
6.请求路由到7379服务时隙5061的节点
7.请求路由到节点7379,7380,7381→[thing1,thing2]
8.请求路由到节点7379→[thing2]
9.请求路由到节点7380→[]
10.请求路由到7381→[thing1]节点
11.请求路由到7382→[event2]节点
当所有键映射到同一插槽时,本机驱动程序库会自动提供跨插槽请求,例如MGET。 但是,如果不是这种情况,RedisClusterConnection会对插槽服务节点执行多个并行GET命令,并再次返回累积结果。 这比单槽执行效率低,因此应谨慎使用。 如果有疑问,请考虑通过在大括号中提供前缀来将密钥固定到同一个插槽,例如{my-prefix} .thing1和{my-prefix} .thing2,它们都映射到相同的插槽号。 以下示例显示了跨槽请求处理:
示例5.交叉槽请求处理的示例
redis-cli@127.0.0.1:7379 > cluster nodes
6b38bb... 127.0.0.1:7379 master - 0 0 25 connected 0-5460 1
7bb...RedisClusterConnection connection = connectionFactory.getClusterConnnection();
connection.set("thing1", value); // slot: 12182
connection.set("{thing1}.thing2", value); // slot: 12182
connection.set("thing2", value); // slot: 5461
connection.mGet("thing1", "{thing1}.thing2"); 2
connection.mGet("thing1", "thing2"); 3 与之前的示例相同的配置。
键映射到相同的插槽→127.0.0.1:7381 MGET thing1 {thing1} .thing2
密钥映射到不同的插槽,并分成单个插槽,路由到相应的节点
→127.0.0.1:7379获取thing2
→127.0.0.1:7381获取thing1
前面的示例演示了Spring Data Redis遵循的一般策略。 请注意,某些操作可能需要将大量数据加载到内存中以计算所需的命令。 此外,并非所有跨时隙请求都可以安全地移植到多个单个插槽请求,如果误用,则会出错(例如,PFCOUNT)。
2.3使用RedisTemplate和ClusterOperations
有关RedisTemplate的一般用途,配置和用法的信息,请参阅“使用RedisTemplate处理对象”部分。
RedisTemplate通过ClusterOperations接口提供对特定于群集的操作的访问,该接口可以从RedisTemplate.opsForCluster()获得。 这使您可以在集群中的单个节点上显式运行命令,同时保留为模板配置的序列化和反序列化功能。 它还提供管理命令(例如CLUSTER MEET)或更高级别的操作(例如,重新分片)。
以下示例显示如何使用RedisTemplate访问RedisClusterConnection:
示例6.使用RedisTemplate访问RedisClusterConnection
ClusterOperations clusterOps = redisTemplate.opsForCluster();
clusterOps.shutdown(NODE_7379); 1 1 在7379关闭节点并交叉手指有一个可以接管的从站。
3 Redis存储库
使用Redis存储库可以在Redis Hashes中无缝转换和存储域对象,应用自定义映射策略以及使用二级索引。
Redis存储库至少需要Redis服务器版本2.8.0。
3.1 用法
示例7.示例人员实体
@RedisHash("people")
public class Person {
@Id String id;
String firstname;
String lastname;
Address address;
}我们这里有一个非常简单的域对象。 请注意,它在其类型上有一个@RedisHash注释,以及一个名为id的属性,该属性使用org.springframework.data.annotation.Id进行注释。 这两个项目负责创建用于持久化哈希的实际密钥。
用@Id和那些已命名id注释的属性被认为是标识符属性。那些有注释的更受欢迎。
现在实际上有一个负责存储和检索的组件,我们需要定义一个存储库接口,如下例所示:
示例8.持久保存人员实体的基本存储库接口
public interface PersonRepository extends CrudRepository<Person, String> {
}由于我们的存储库扩展了CrudRepository,它提供了基本的CRUD和finder操作。 我们需要将事物粘合在一起的是相应的Spring配置,如下例所示:
示例9. Redis存储库的JavaConfig
@Configuration
@EnableRedisRepositories
public class ApplicationConfig {
@Bean
public RedisConnectionFactory connectionFactory() {
return new JedisConnectionFactory();
}
@Bean
public RedisTemplate<?, ?> redisTemplate() {
RedisTemplate<byte[], byte[]> template = new RedisTemplate<byte[], byte[]>();
return template;
}
}鉴于前面的设置,我们可以将PersonRepository注入到我们的组件中,如以下示例所示:
示例10.访问人员实体
@Autowired PersonRepository repo;
public void basicCrudOperations() {
Person rand = new Person("rand", "al'thor");
rand.setAddress(new Address("emond's field", "andor"));
repo.save(rand); //1
repo.findOne(rand.getId()); //2
repo.count(); //3
repo.delete(rand); //4
}1.如果当前值为null或重新使用已设置的id值,则生成一个新的id,并使用具有keyspace模式的键在Redis Hash中存储Person类型的属性:id - 在这种情况下,它可能是people:5d67b7e1-8640-4475-BEEB-c666fab4c0e5。
2.使用提供的id来检索存储在keyspace:id的对象。
3.计算密钥空间中可用的实体总数,由@RedisHash on Person定义的人员。
4.从Redis中删除给定对象的键。
官网还有很多,就不一一介绍了。
微信公众号


