如何更新缓存保证缓存和数据库双写一致性?
前言
在项目中缓存是经常用到的,为了减少和数据库的交互,小伙伴们利用缓存的思路如下:
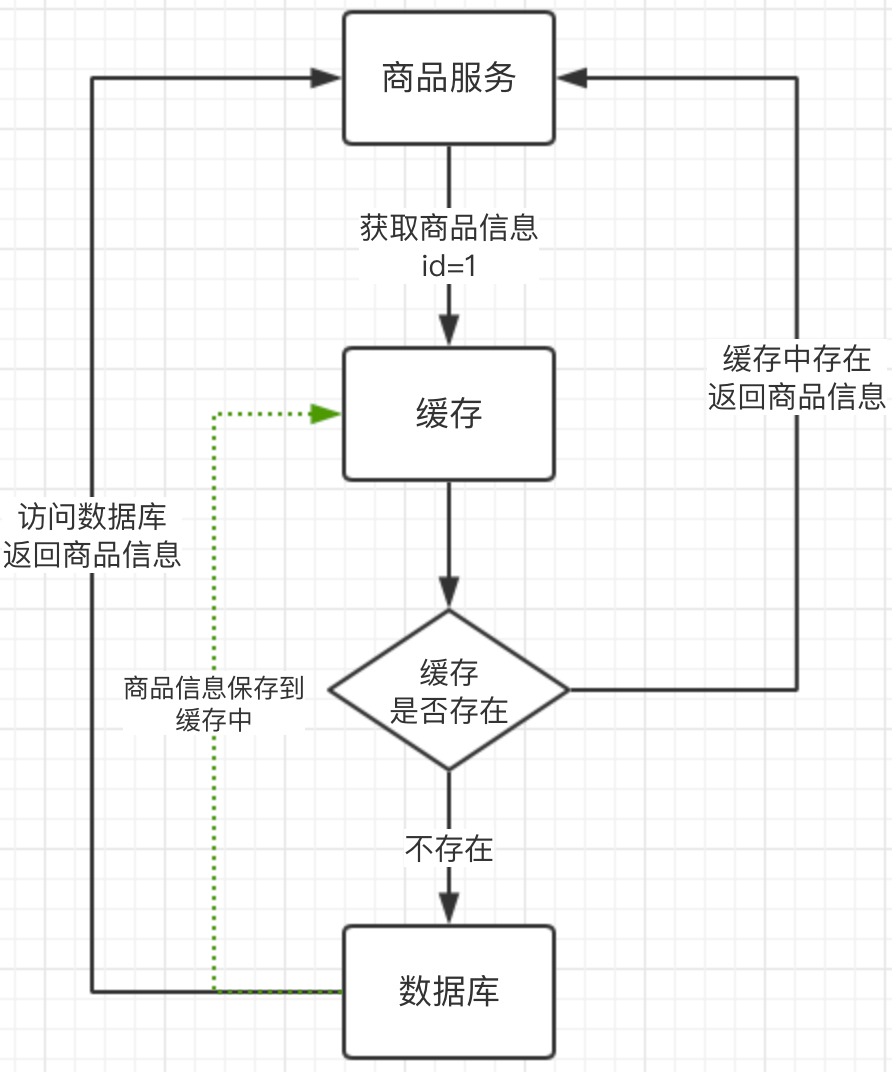
我们小伙伴们有没有考虑到缓存更新的问题,小伙伴们肯定会说肯定用过啊,有数据更新时,把缓存清空掉就行了啊,下一次访问的时候服务就会把新值设置到缓存中了。这样不就行了吗?对的,在一般项目中,这样的使用就够了。那么大家看看在高并发场景下,会有什么问题?
我们举例说明,就拿商品的库存作为缓存。那现在我们要更新缓存中的库存值,怎么进行操作,我们看下面几个场景:
先更新数据库,再更新缓存
存在的问题场景:请求A更新值为99,请求B更新值为98
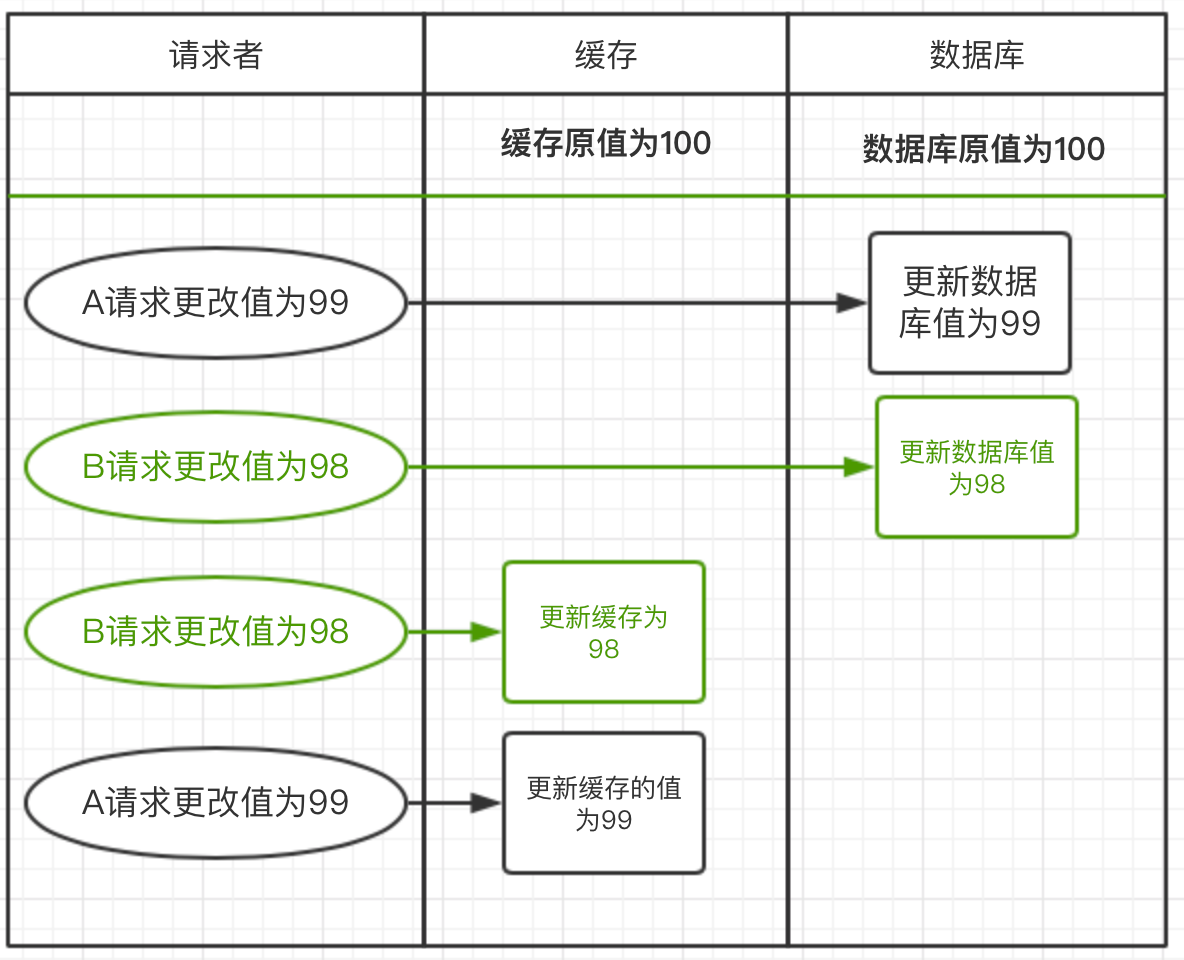
上图流程:
1)请求A先发起,更新数据库为99,但还没有来得及更新缓存
2)请求B发起,更新数据库为98,又更新了缓存值为98
3)请求A这时才更新缓存的值为99
这样数据库的值为98,但缓存的值为99,数值不一致。(不推荐)
先更新缓存,再更新数据库
这个流程跟上面很类似,出现的问题也很类似
1)请求A先更新缓存为99,但还没有来得及更新数据库
2)请求B更新缓存为98,又更新了数据库为98
3)请求A这时更新数据库为99
这样就缓存的值为98,数据库为99导致不一致。(不推荐)
先删除缓存,再更新数据库
存在的问题场景:请求A更新值为99,请求B获取值
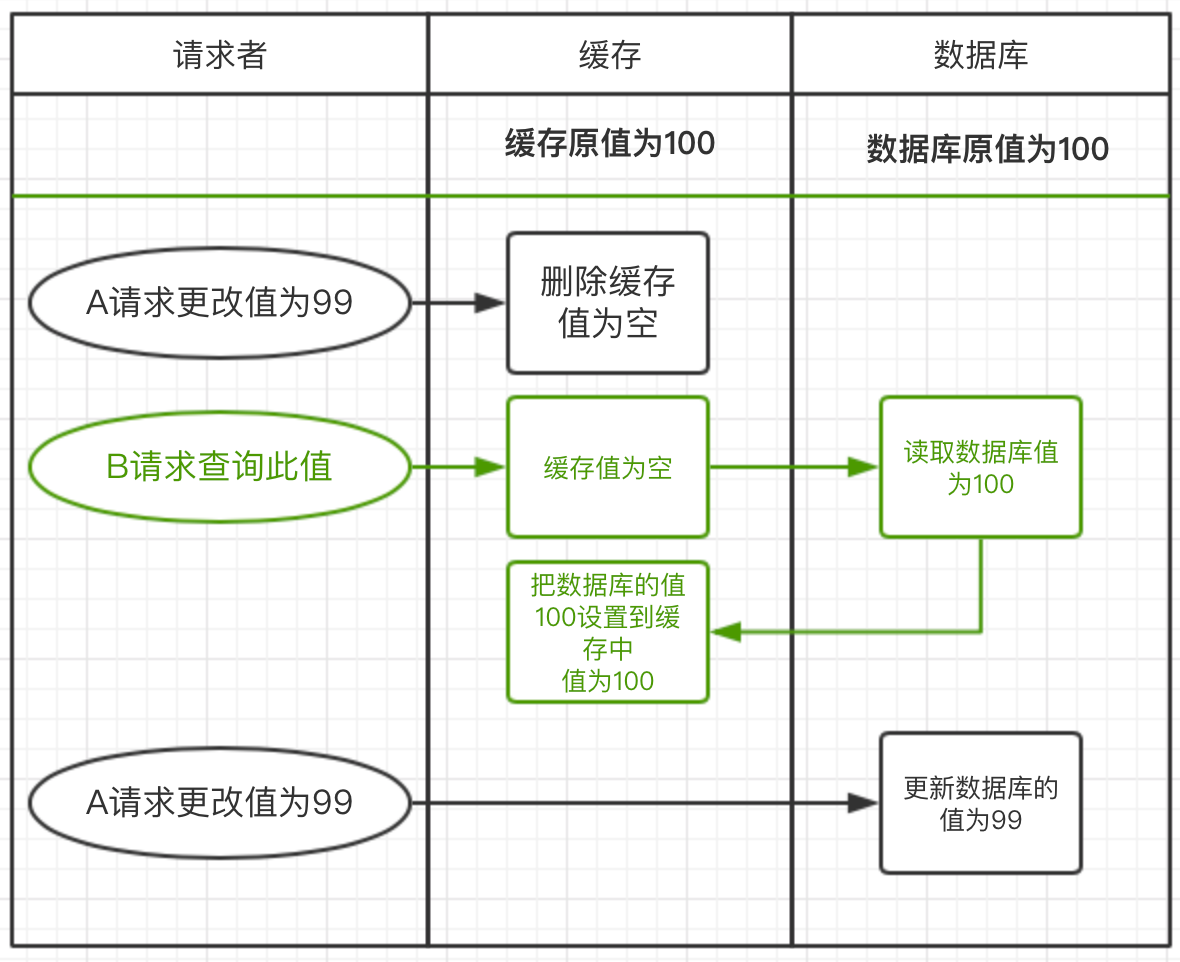
上图中请求流程:
1)请求A更新值,先把缓存中的值删除,但还没有来得及更新数据库
2)此时请求B过来查询此值,发现缓存中不存在,就到数据库中查询
3)请求B在数据库中获取到值,在把值设置到缓存中。
4)请求A这时才更新数据库里面的值为99
这样就导致了缓存和数据库的不一致问题,缓存中的值一直是旧数据。(不推荐)
先更新数据库,再删除缓存
这个方案也是老外提出的《Cache-Aside pattern》更新缓存的策略。这种策略先保证了源头的数据一定是正确的。这种策略是不是万无一失呢,有一种非常特殊的场景
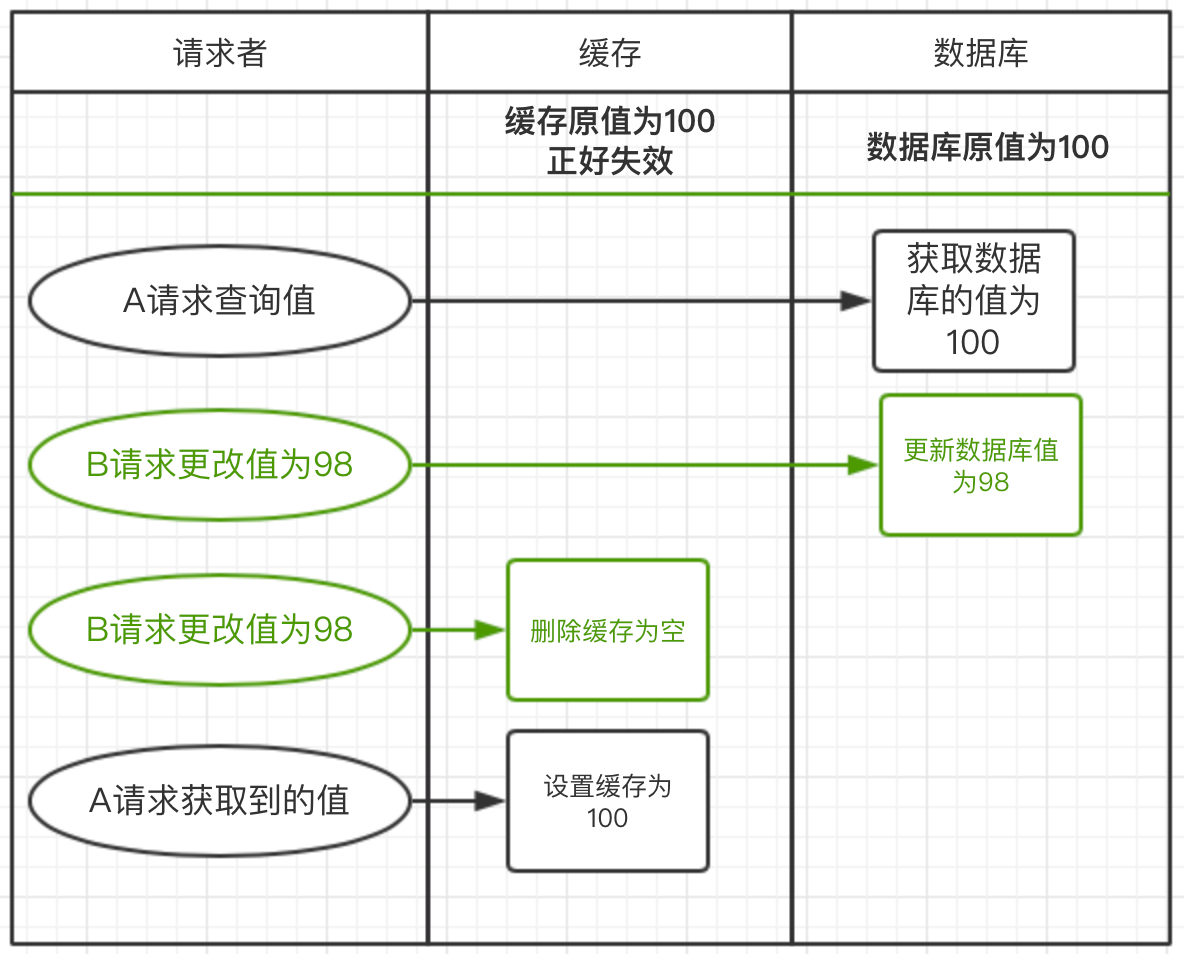
上图流程:建立中缓存突然失效了
1)请求A发起查询请求,直接到数据库查询到100,但还没有来得及去设置缓存
2)请求B更新值,先更新数据库,在删除缓存
3)请求A这时才设置缓存为100
这种情况发生的不一致,是因为缓存突然失效了。而且还要保证请求B更新操作 比 请求A的查询操作还要快;才会导致不一致。这种情况概率会很少。一般要求不高的项目可以采用此方式(推荐)。
缓存删除失败,导致不一致
这种先更新数据库,再删除缓存的策略中,因为要删除缓存,但如果缓存删除失败,就会导致数据库与缓存不一致。这个问题怎么办?我们正常想到的是利用我们MQ中间件去实现。
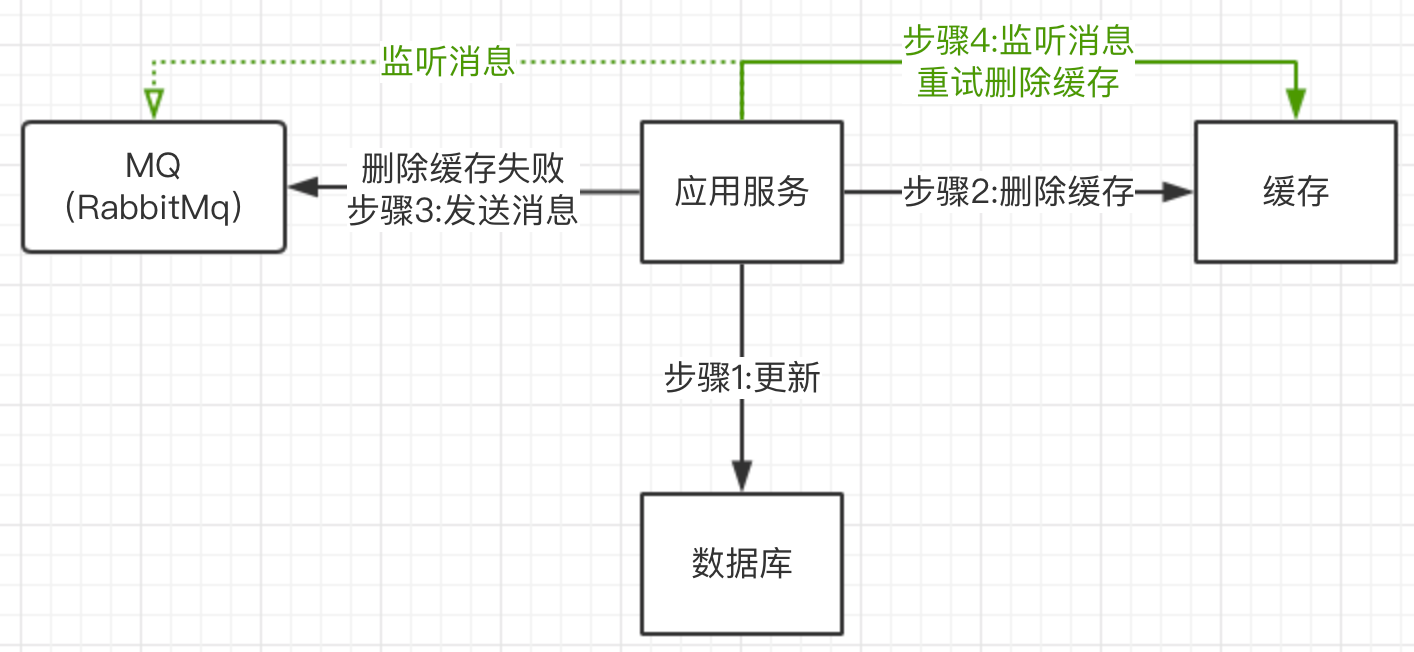
上图的流程,如果删除缓存失败,发送消息投递到消息中间件中,进入消息队列。也许有小伙伴就会问,如果消息投递失败怎么办?我们可以利用消息中间件那边的保证100%消息投递的机制(这个以后再讲)。这样就保证了即使删除消息失败,我们也会重试。
不过这个方案有个问题,就是和我们应用服务的业务代码耦合的比较厉害。代码业务不清晰。
那我们有没有别的方案呢,对业务没有侵入呢?
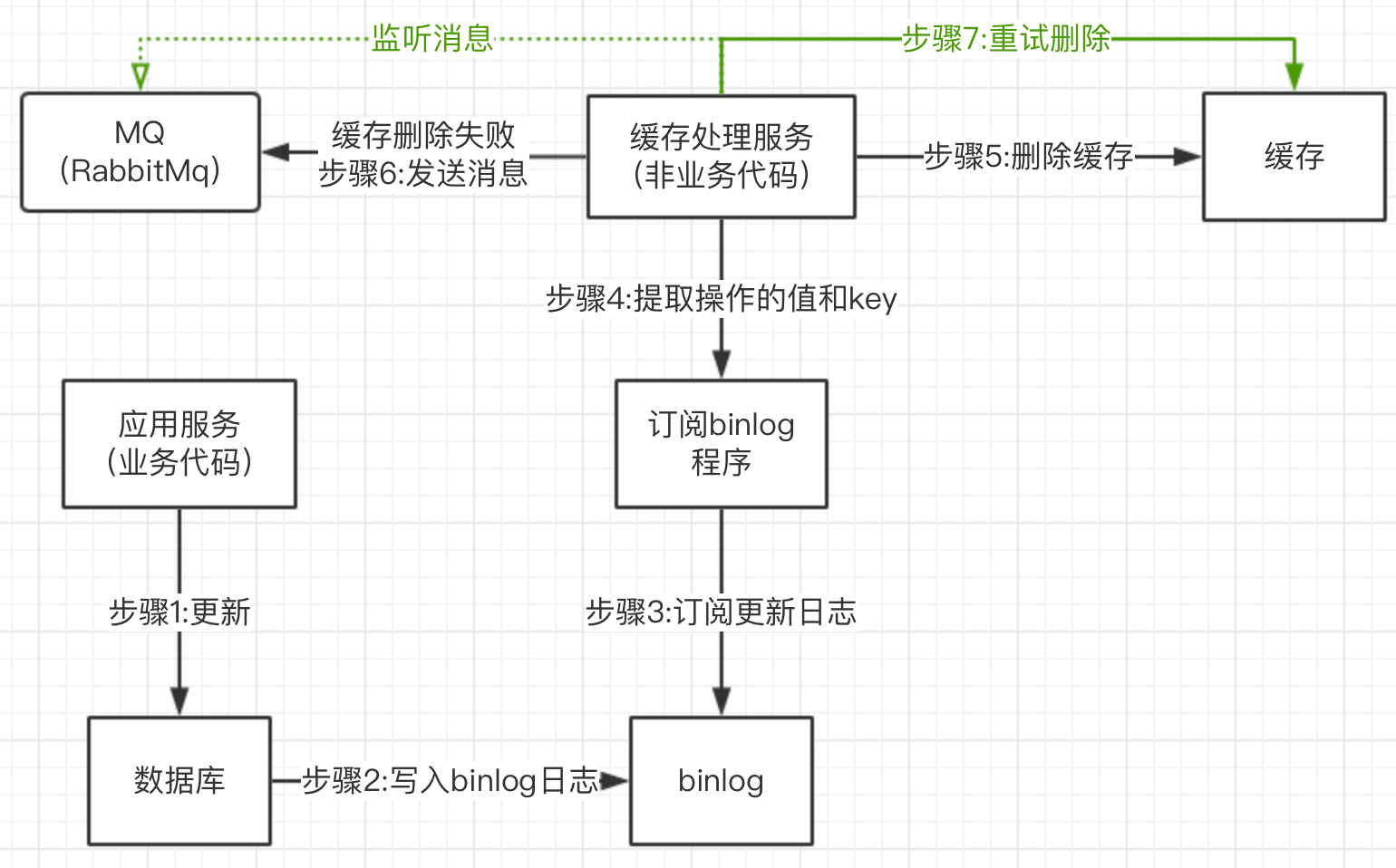
上图中其实是利用了mysql的底层机制,binlog日志进行删除缓存,这样就不需要和业务关联,删除缓存服务是独立的。我们可以利用阿里开源的canal去操作。
读写分离,导致不一致
这种先更新数据库,再删除缓存的策略是不是就没有问题呢?我们来看一下另一个场景,数据库的读写分离的场景。一般中大型项目都会用到数据库的读写分离。写请求在一个库,读请求在另一个库。读写分离会有个问题,就是库与库之间会存在数据延迟,因为存在数据同步。
那我们再看一下上面的场景流程,就会有问题,因为请求B更新数据 在一个库上面,请求A去读取数据时是另一个库。
1)请求B更新值99,删除缓存
2)请求A查询值100(读库数据还没有同步),在更新到缓存中(值为100)
这样就导致不一致,这个场景是经常出现的,不是小概率事件。那我们如何处理呢?
请看这一篇:怎么解决DB读写分离,导致数据不一致问题?
总结:整个导致不一致的原因就是因为高并发情况下各个请求执行的顺序是无法确定的,不知道哪个请求先执行,哪个后执行导致。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号