分布式以及微服务
CAP理论
CAP 也就是 Consistency(一致性)、Availability(可用性)、Partition Tolerance(分区容错性) 这三个单词首字母组合。
在理论计算机科学中,CAP 定理(CAP theorem)指出对于一个分布式系统来说,当设计读写操作时,只能同时满足以下三点中的两个:
- 一致性(Consistency) : 所有节点访问同一份最新的数据副本
- 可用性(Availability): 非故障的节点在合理的时间内返回合理的响应(不是错误或者超时的响应)。
- 分区容错性(Partition tolerance) : 分布式系统出现网络分区的时候,仍然能够对外提供服务。


CAP理论使用场景以及CP、AP选择
1、注册中心

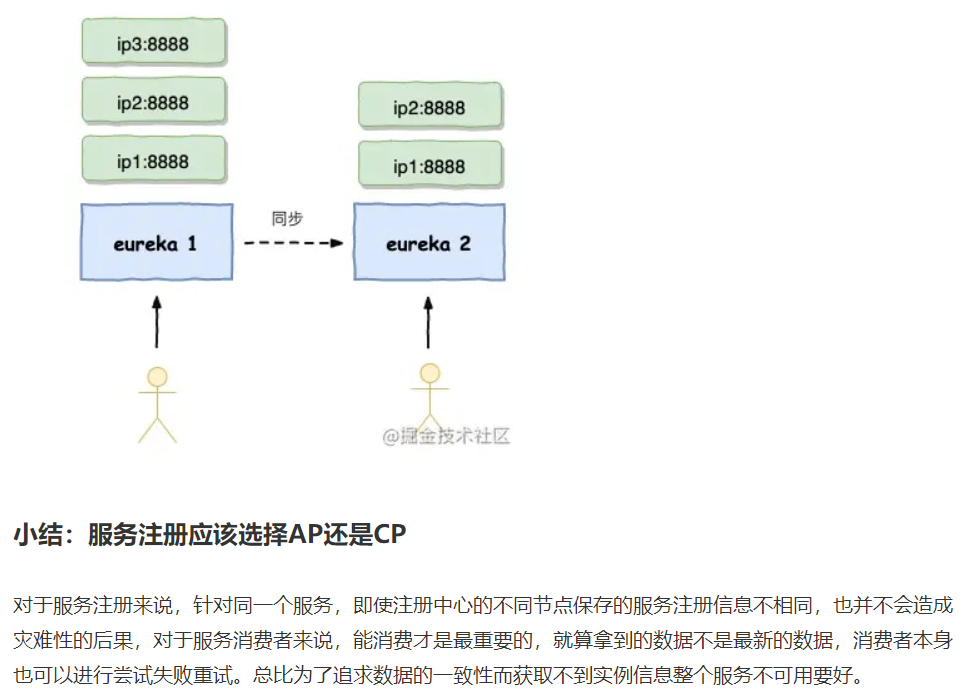
2、分布式锁

基于数据库实现的分布式锁对于单主却无法自动切换主从的mysql来说,基本就无法现实P分区容错性,(Mysql自动主从切换在目前并没有十分完美的解决方案)。
BASE理论

总结
ACID 是数据库事务完整性的理论,CAP 是分布式系统设计理论,BASE 是 CAP 理论中 AP 方案的延伸。
一致性hash算法
一致性哈希算法在1997年由麻省理工学院的Karger等人在解决分布式Cache中提出的,设计目标是为了解决因特网中的热点(Hot spot)问题
原理:简单来说,一致性哈希将整个哈希值空间组织成一个虚拟的圆环,如假设某哈希函数H的值空间为0-2^32-1(即哈希值是一个32位无符号整形)
将各个服务器使用Hash进行一个哈希,具体可以选择服务器的ip或主机名作为关键字进行哈希,这样每台机器就能确定其在哈希环上的位置
定位数据访问到相应服务器:将数据key使用相同的函数Hash计算出哈希值,并确定此数据在环上的位置,从此位置沿环顺时针“行走”,第一台遇到的服务器就是其应该定位到的服务器。
综上所述,一致性哈希算法对于节点的增减都只需重定位环空间中的一小部分数据(即增删节点沿着逆时针方向走遇到的第一个节点之间的数据),具有较好的容错性和可扩展性。
虚拟节点:一致性哈希算法在服务节点太少时,容易因为节点分部不均匀而造成数据倾斜问题。比如只有两个节点A和B,如果A和B靠得很近,那么会导致大量数据落在一个节点,为了解决这种数据倾斜问题,一致性哈希算法引入了虚拟节点机制,即对每一个服务节点计算多个哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点。比如A#1,A#2,A#3,B#1,B#2,B#3,同时数据定位算法不变,只多了从虚拟节点到实际节点的映射。在实际应用中,通常将虚拟节点数设置为32甚至更大,因此即使很少的服务节点也能做到相对均匀的数据分布。
分布式ID常见解决方案
分布式ID就是分布式系统下的ID,比如分库之后, 数据遍布在不同服务器上的数据库,数据库的自增主键已经没办法满足生成的主键唯一了。我们如何为不同的数据节点生成全局唯一主键呢?这时候就用到了分布式ID。
基于数据库的解决方案:
1、数据库自增
创建一个sequence_id专门用来生成分布式ID,每次都需要利用数据库主键自增原里,往数据库插入一条数据,返回的主键用来做分布式ID。
支持的并发度比较低,每次都需要访问一次数据库,还有安全问题(利用主键就能推出每天有多少ID生成,比如每天有多少订单)
2、数据库号段模式
同上创建一个数据库表用来获取分布式ID,只不过这个表支持批量获取分布式ID段,放在内存,然后随去随用,用完后再次申请分布式ID段。
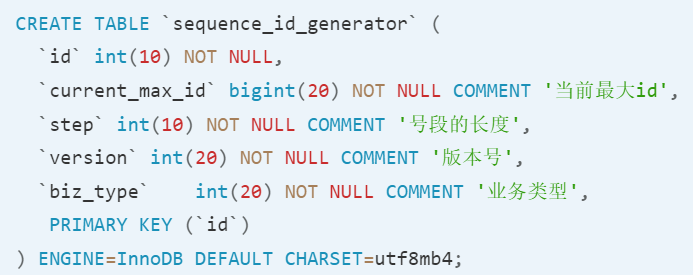
解决了自增并发度的问题,但是仍然有安全问题和单点问题(可以用数据库集群解决,提高了复杂度)
3、利用redis的incr命令实现对id的原子递增

并且redis原生支持集群模式,可以使用集群模式提高并发度和可用性
生成分布式ID的算法:
1、UUID
UUID 是 Universally Unique Identifier(通用唯一标识符) 的缩写。UUID 包含 32 个 16 进制数字(8-4-4-4-12)。
UUID 可以保证唯一性,因为其生成规则包括 MAC 地址、时间戳、名字空间(Namespace)、随机或伪随机数、时序等元素,计算机基于这些规则生成的 UUID 是肯定不会重复的。不过一般不会用UUID,因为UUID有随机性和128位,不适合用来做数据库主键(主键最好不要太大且最好自增)。

2、雪花算法


分布式一致性算法——Raft
https://www.sofastack.tech/projects/sofa-jraft/raft-introduction/
RPC
RPC原理
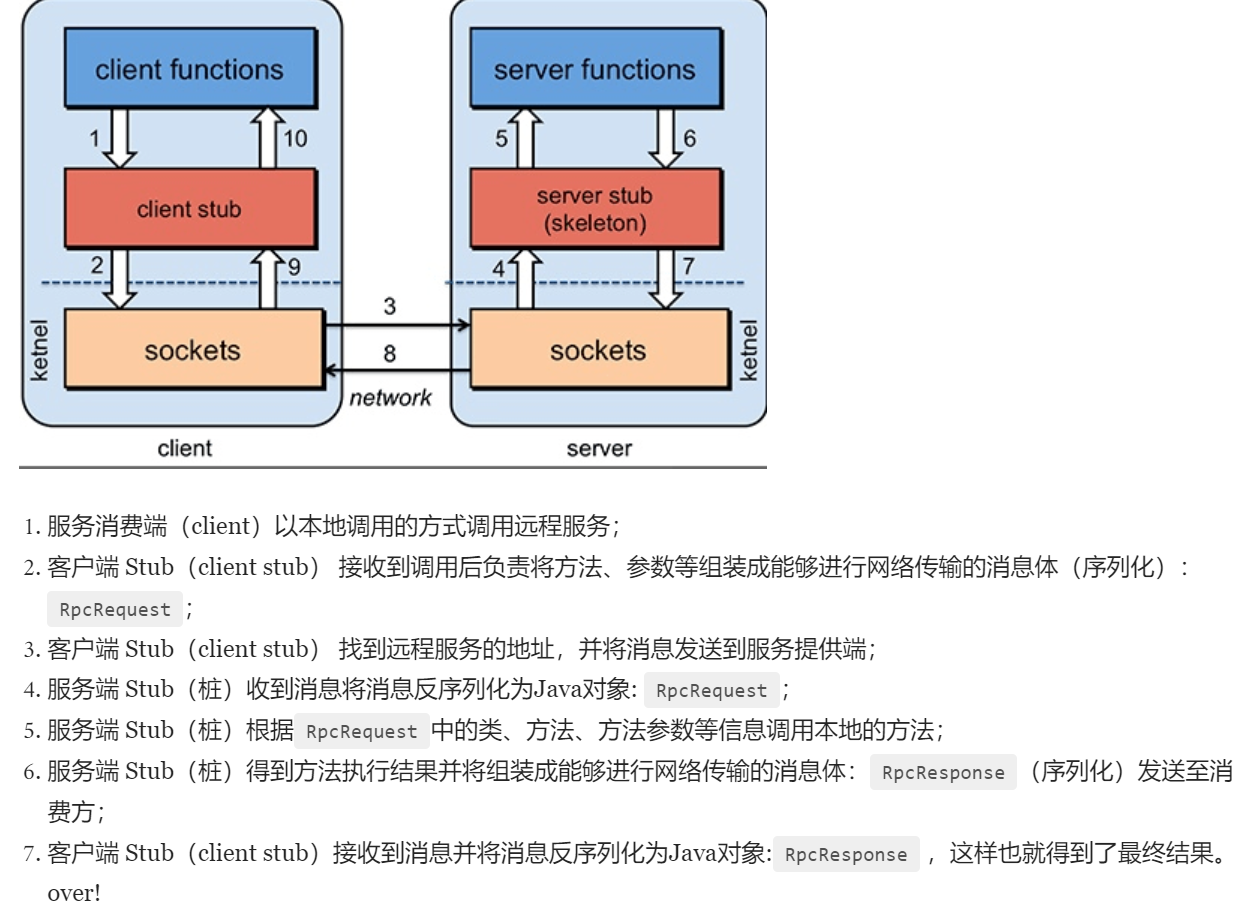
一次RPC调用过程大体如下:
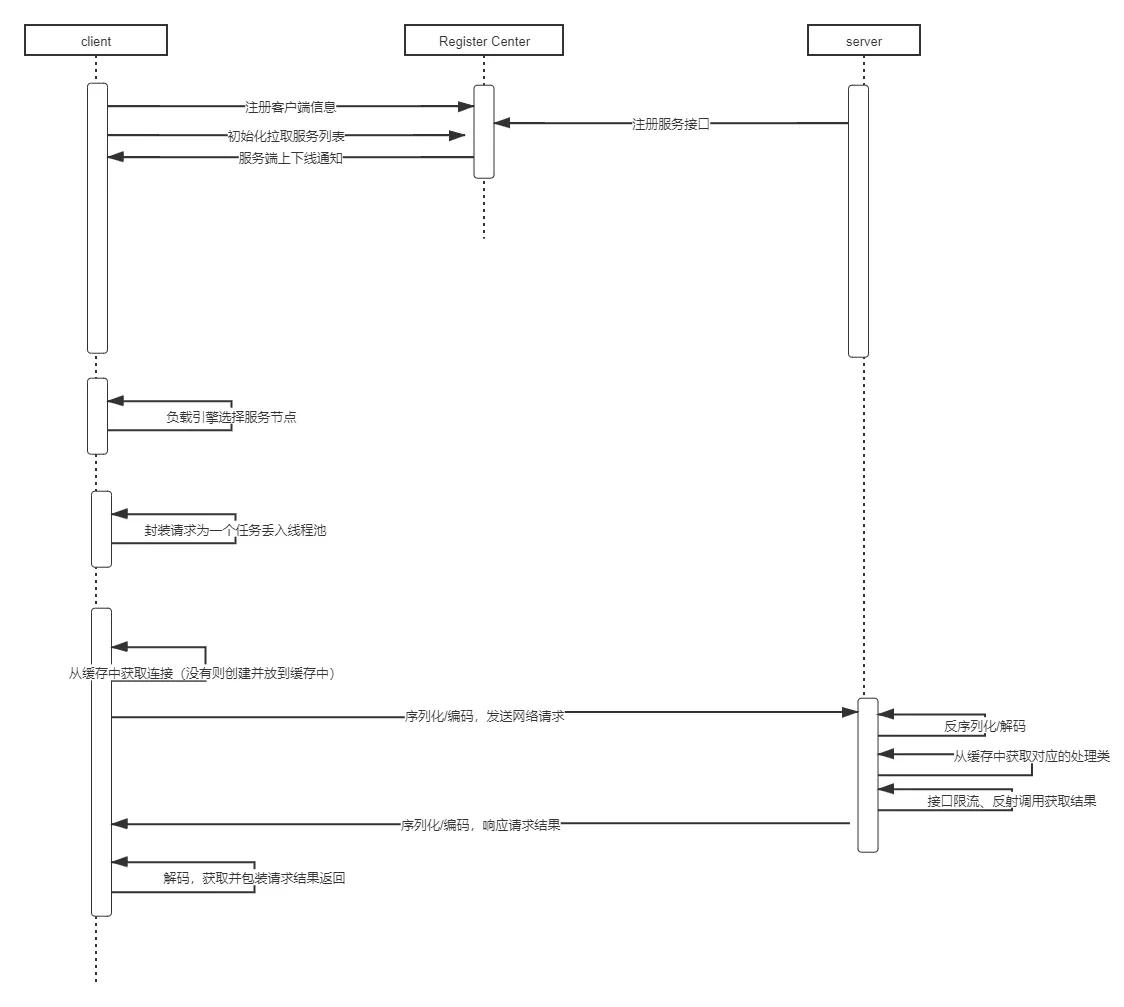
什么是分布式?
分布式或者说 SOA 分布式重要的就是面向服务,说简单的分布式就是我们把整个系统拆分成不同的服务然后将这些服务放在不同的服务器上减轻单体服务的压力提高并发量和性能。比如电商系统可以简单地拆分成订单系统、商品系统、登录系统等等,拆分之后的每个服务可以部署在不同的机器上,如果某一个服务的访问量比较大的话也可以将这个服务同时部署在多台机器上。
DDD领域驱动设计
https://zhuanlan.zhihu.com/p/411866735
grpc
dubbo

 浙公网安备 33010602011771号
浙公网安备 33010602011771号