1.3:聚类
K-means聚类

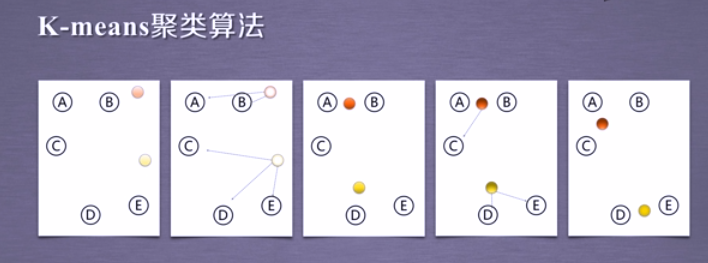
K-means的应用
数据介绍:
现有1999年全国31个省份城镇居民家庭平均每人全年消费性支出的八个主
要变量数据,这八个变量分别是:食品、衣着、家庭设备用品及服务、医疗
保健、交通和通讯、娱乐教育文化服务、居住以及杂项商品和服务。利用已
有数据,对31个省份进行聚类。
实验目的:
通过聚类,了解1999年各个省份的消费水平在国内的情况。
技术路线:sklearn.cluster.Kmeans
示例代码
1 import numpy as np 2 from sklearn.cluster import KMeans 3 4 5 def loadData(filePath): 6 fr = open(filePath, 'r+') 7 lines = fr.readlines() 8 retData = [] 9 retCityName = [] 10 for line in lines: 11 items = line.strip().split(",") 12 retCityName.append(items[0]) 13 retData.append([float(items[i]) for i in range(1, len(items))]) 14 return retData, retCityName 15 16 17 if __name__ == '__main__': 18 data, cityName = loadData('city.txt') 19 km = KMeans(n_clusters=4) 20 label = km.fit_predict(data) 21 expenses = np.sum(km.cluster_centers_, axis=1) 22 # print(expenses) 23 CityCluster = [[], [], [], []] 24 for i in range(len(cityName)): 25 CityCluster[label[i]].append(cityName[i]) 26 for i in range(len(CityCluster)): 27 print("Expenses:%.2f" % expenses[i]) 28 print(CityCluster[i])
拓展&&改进
计算两条数据相似性时,Sklearn 的K-Means默认用的是欧式距离。虽然还有余弦相
似度,马氏距离等多种方法,但没有设定计算距离方法的参数。
建议使用 scipy.spatial.distance.cdist 方法
源码地址:https://github.com/scikit-learn/scikit-learn/blob/master/sklearn/metrics/pairwise.py
使用形式:scipy.spatial.distance.cdist(A, B, metric=‘cosine’)
重要参数:
• A:A向量
• B:B向量
• metric: 计算A和B距离的方法,更改此参数可以更改调用的计算距离的方法
详细:https://docs.scipy.org/doc/scipy/reference/generated/scipy.spatial.distance.cdist.html#scipy.spatial.distance.cdist
DBSCAN聚类(DBSCAN密度聚类)
DBSCAN算法是一种基于密度的聚类算法:
• 聚类的时候不需要预先指定簇的个数
• 最终的簇的个数不定
DBSCAN算法将数据点分为三类:
• 核心点:在半径Eps内含有超过MinPts数目的点
• 边界点:在半径Eps内点的数量小于MinPts,但是落在核心点的邻域内
• 噪音点:既不是核心点也不是边界点的点
DBSCAN算法流程:
1.将所有点标记为核心点、边界点或噪声点;
2.删除噪声点;
3.为距离在Eps之内的所有核心点之间赋予一条边;
4.每组连通的核心点形成一个簇;
5.将每个边界点指派到一个与之关联的核心点的簇中(哪一个核心点的半
径范围之内)。

注:采用曼哈顿距离
DBSCAN的应用实例
数据介绍:
现有大学校园网的日志数据,290条大学生的校园网使用情况数据,数据包
括用户ID,设备的MAC地址,IP地址,开始上网时间,停止上网时间,上
网时长,校园网套餐等。利用已有数据,分析学生上网的模式。

实验目的:
通过DBSCAN聚类,分析学生上网时间和上网时长的模式。
技术路线:sklearn.cluster.DBSCAN
实验过程:
1. 建立工程,导入sklearn相关包
import numpy as np
from sklearn.cluster import DBSCAN
DBSCAN主要参数:
- eps: 两个样本被看作邻居节点的最大距离
- min_samples: 簇的样本数
- metric:距离计算方式
例:sklearn.cluster.DBSCAN(eps=0.5, min_samples=5, metric='euclidean')
详细:http://scikit-learn.org/stable/modules/generated/sklearn.cluster.DBSCAN.html#sklearn.cluster.DBSCAN



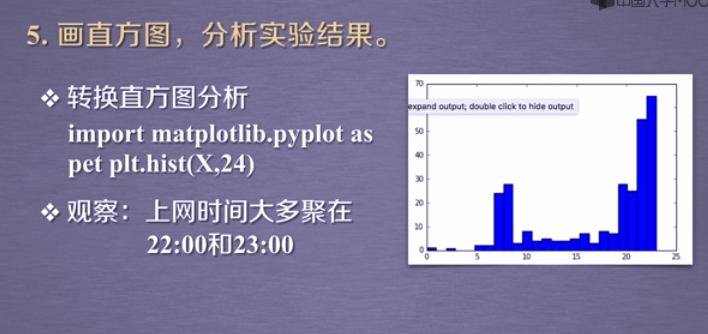
import matplotlib.pyplot as pltplt.hist(X,24)


数据分布 vs 聚类
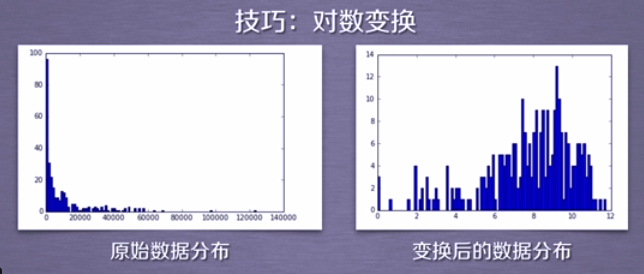
技巧:对数变换
import numpy as np import sklearn.cluster as skc from sklearn import metrics import matplotlib.pyplot as plt mac2id = dict() onlinetimes = [] f = open('TestData.txt', encoding='utf-8') for line in f: mac = line.split(',')[2] onlinetime = int(line.split(',')[6]) starttime = int(line.split(',')[4].split(' ')[1].split(':')[0]) if mac not in mac2id: mac2id[mac] = len(onlinetimes) onlinetimes.append((starttime, onlinetime)) else: onlinetimes[mac2id[mac]] = [(starttime, onlinetime)] real_X = np.array(onlinetimes).reshape((-1, 2)) X = real_X[:, 0:1] db = skc.DBSCAN(eps=0.01, min_samples=20).fit(X) labels = db.labels_ print('Labels:') print(labels) raito = len(labels[labels[:] == -1]) / len(labels) print('Noise raito:', format(raito, '.2%')) n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0) print('Estimated number of clusters: %d' % n_clusters_) print("Silhouette Coefficient: %0.3f" % metrics.silhouette_score(X, labels)) for i in range(n_clusters_): print('Cluster ', i, ':') print(list(X[labels == i].flatten())) plt.hist(X, 24)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号