Yolov3模型训练并转化为onnx
下载yolov3代码,
github上下载,https://github.com/ultralytics/yolov3
我下载的v9.5.0版本
数据集划分,分为train,val,test
# 将图片和标注数据按比例切分为 训练集和测试集
import shutil
import random
import os
# 原始路径
image_original_path = r'D:\yolov3-9.5.0\VOCdevkit\VOC2007\JPEGImages/'
label_original_path = r'D:\yolov3-9.5.0\VOCdevkit\VOC2007\YOLOLabels/'
# 训练集路径
train_image_path = r'D:\yolov3-9.5.0\VOCdevkit\images\train/'
train_label_path = r'D:\yolov3-9.5.0\VOCdevkit\labels\train/'
# 验证集路径
val_image_path = r'D:\yolov3-9.5.0\VOCdevkit\images\val/'
val_label_path = r'D:\yolov3-9.5.0\VOCdevkit\labels\val/'
# 测试集路径
test_image_path = r'D:\yolov3-9.5.0\VOCdevkit\images\test/'
test_label_path = r'D:\yolov3-9.5.0\VOCdevkit\labels\test/'
# 数据集划分比例,训练集75%,验证集15%,测试集15%
train_percent = 0.7
val_percent = 0.15
test_percent = 0.15
# 检查文件夹是否存在
def mkdir():
if not os.path.exists(train_image_path):
os.makedirs(train_image_path)
if not os.path.exists(train_label_path):
os.makedirs(train_label_path)
if not os.path.exists(val_image_path):
os.makedirs(val_image_path)
if not os.path.exists(val_label_path):
os.makedirs(val_label_path)
if not os.path.exists(test_image_path):
os.makedirs(test_image_path)
if not os.path.exists(test_label_path):
os.makedirs(test_label_path)
def main():
mkdir()
total_txt = os.listdir(label_original_path)
num_txt = len(total_txt)
list_all_txt = range(num_txt) # 范围 range(0, num)
num_train = int(num_txt * train_percent)
num_val = int(num_txt * val_percent)
num_test = num_txt - num_train - num_val
train = random.sample(list_all_txt, num_train)
# train从list_all_txt取出num_train个元素
# 所以list_all_txt列表只剩下了这些元素:val_test
val_test = [i for i in list_all_txt if not i in train]
# 再从val_test取出num_val个元素,val_test剩下的元素就是test
val = random.sample(val_test, num_val)
# 检查两个列表元素是否有重合的元素
# set_c = set(val_test) & set(val)
# list_c = list(set_c)
# print(list_c)
# print(len(list_c))
print("训练集数目:{}, 验证集数目:{},测试集数目:{}".format(len(train), len(val), len(val_test) - len(val)))
for i in list_all_txt:
name = total_txt[i][:-4]
srcImage = image_original_path + name + '.jpeg'
srcLabel = label_original_path + name + '.txt'
if i in train:
dst_train_Image = train_image_path + name + '.jpeg'
dst_train_Label = train_label_path + name + '.txt'
try:
shutil.copyfile(srcImage, dst_train_Image)
shutil.copyfile(srcLabel, dst_train_Label)
except:
print("有错误")
elif i in val:
dst_val_Image = val_image_path + name + '.jpeg'
dst_val_Label = val_label_path + name + '.txt'
try:
shutil.copyfile(srcImage, dst_val_Image)
shutil.copyfile(srcLabel, dst_val_Label)
except:
print("1")
else:
dst_test_Image = test_image_path + name + '.jpeg'
dst_test_Label = test_label_path + name + '.txt'
try:
shutil.copyfile(srcImage, dst_test_Image)
shutil.copyfile(srcLabel, dst_test_Label)
except:
print("2")
if __name__ == '__main__':
main()划分完数据集后,即可训练对应的模型
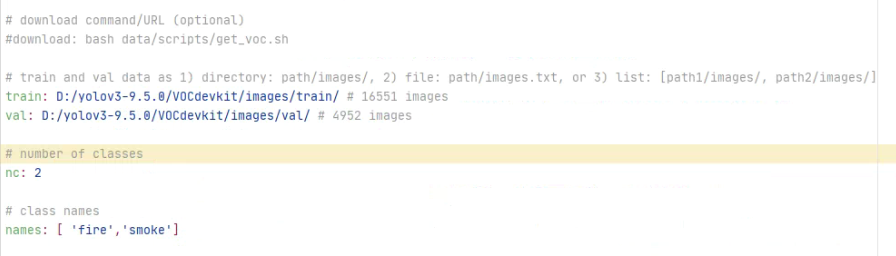
1.复制一个voc.yaml文件,并重命名为smoke.yaml(做的烟雾检测识别)

进入文件,修改路径为筛选后的数据集路径,nc为标签种类,names为标签名称,同时注销掉下载的代码
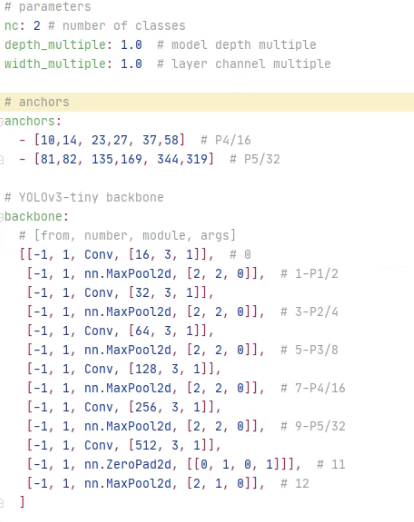
2.复制yolov3-tiny.yaml文件,并重命名为yolov3-tiny_smoke.yaml

打开文件,仅需更改nc即可
3.打开train.py文件,进行设置更改

其中主要更改路径,以及epochs的次数,batch-size每批数据量的大小
4.开始训练
5.转化为onnx模型代码
export程序可以直接跑,但是会报错:
ONNX: export failure: Your model ir_version is higher than the checker's.
原因是onnx版本过低,
推荐安装1.11.0版本
pip install -i https://mirrors.aliyun.com/pypi/simple onnx==1.11.0
其它遇到的问题,参考博文
https://blog.csdn.net/thy0000/article/details/124579443

 浙公网安备 33010602011771号
浙公网安备 33010602011771号