

Mysql-二刷一些重要知识点记录
-
执行DDL的时候,即使此DDL被其他DML阻塞了,但是后续DML都会被此DDL阻塞
(个人理解:DDL、DML按照申请顺序排队执行)[DML加MDL读锁,DDL加MDL写锁,读写之间互斥]
使用online ddl也就不害怕线上DDL了
-
change buffer存储insert 和 update的数据。如果不马上查询,起到加速DML的作用
-
[尽量使用普通索引代替唯一索引]唯一索引因为要校验唯一性,因此不会使用change buffer
-
[索引长度尽量控制短一些]索引一页的大小16B,因此长度过长单页上存储的数据就少,查询效率就低一些,因此对于一些字符串索引使用 select count(distinct left(room_id, 4)) from live_playback 来找到包含95%的长度即可
-
[Mysql策略:内存中有一定是正确的,内存中没有磁盘一定是正确的]
因此从内存淘汰脏页会flush到磁盘的
-
[监控redo log和脏页使用率]
因为redo log满了则mysql的update等只能阻塞等flush到磁盘后操作了,业务无法接受的性能。
因为脏页过多,如果一次查询需要淘汰的脏页多的话,需要等flush到磁盘后再执行,业务无法接受的性能。
-
[删除记录不会让空间缩小]
数据页单个记录删除,删除的记录被标记为可复用(复用的位置,新增的记录必须满足原记录的范围关系,比如删除的记录左右两边范围是(600,800),那只有这个区间的插入才能复用到)
数据页整个页删除,删除的页被标记为可复用(这个页可以被直接应用)
随机插入,如果某个数据页满了,会也分裂,导致原页尾部空间的浪费
-
重建表alter table t engine=InnoDB每个数据页会预留1/16的空间,因此其也不是最紧凑的。这个命令在mysql5.6后是online ddl了
-
[count(*)效率最高,因为Mysql针对其进行了优化]
首先,其会在逻辑正确下,找最小的索引数进行统计
然后,它也不会取出字段值,直接让server层累加count(字段)<count(主键id)<count(1)≈count(*)
-
[order by无法借助索引,则会使用设定的内存排序,大小不足借助磁盘使用归并排序]
select a,b,c from table where b='xx' order a limit 1000
- 全字段排序
- 所有需要返回字段长度<设定的max_length_for_sort_data,排序使用(a,b,c)全字段
- rowid排序
- 排序使用(a,id)字段排序,排序后根据limit 1000 按照id回表聚簇索引,将a,b,c返回
- 联合索引(b,a),即可通过索引避免排序
- 全字段排序
-
[using temporary使用memory内存引擎,因此再其基础上的排序,优先使用rowid]
因为内存排序,字段越少,sort buffer空间有限时,能排序的越多
当然,小于tmp_table_size使用memroy内存临时表(默认16M),大于的话只能使用磁盘临时表了
-
[索引失效:加函数、类型隐式转换、字符集不一致]
说到底都是因为查询的字段加了函数,导致索引失效
- mysql默认将字符串转为数值,因此 varchar(32) b = 100,实际是cast(b int) = 100,索引失效
- 表的字符编码不一致,mysql默认转为父类的编码进行处理
-
[字符串查询大坑]
https://www.cnblogs.com/ningxinjie/p/17336895.html
[最下面上期问题时间]内详细说明
根据字符串字段设定长度阶段 + 查询 + server判断
比如字段b是varchar(4),数据库中b的值为1234有10万行,我们要查询b='12345',mysql会先截断前4位1234,然后查询,因为select *,因此一个个回表,然后server判断1234!=12345,最后返回为空。
因此这条查询语句执行是非常慢的
那业务该如何避免呢?
- b区分区太低了,比如1234有10万行,这种如果是随机产生的,直接存到es中,使用倒排索引形式供用户或者业务查询
- 如果是业务含义,长度固定为4的话,则查询前校验合法性,比如长度不是4那不合法,直接报错返回,就不要查db了
-
[RR引入间隙锁的目的是为了解决binlog记录内容回放与实际执行不一致]
在读已提交下,不引入间隙锁,使用binlog的row格式即可解决(不过测试感觉并没有锁住那一行,执行更新的时候其他事务提交了,也会顺带把后续提交事务的那行数据改了,所以我感觉这种配置的作用是为了防止其他场景的数据不一致)
-
[加锁分析精髓都在这了:https://www.cnblogs.com/ningxinjie/p/17336904.html](针对读已提交的隔离级别)
- 2个原则
- 加锁单位是next-key-lock,即前开后闭
- 访问到的才会加锁
- 2个优化(都是针对索引的等值查询)
- [等值查询时]唯一索引存在,则next-key-lock退化为行锁
- [等值查询时]向右遍历最后一个值不满足,则next-key-lock退还为间隙锁,即前开后开
- 1个bug
- 唯一索引的范围查询也会访问到不满足第一个值为止(即不论你是普通索引还是唯一索引,找到当前值,也会继续找下一个,即使唯一索引下一个值一定不满足,也会找,访问到的就会加锁)
- 2个原则
-
[next-key-lock实质是间隙锁+行锁,加锁过程也是分两段加,先加间隙锁,再加行锁]
间隙锁之间不冲突,行锁之间冲突
sessionA sessionB begin select id from t where c=10 for update select id from t where c=10 for update
[block]insert into t value(8,8,8) error 1213
检测到死锁sessionA执行的语句,加(5,10]next-key-lock和(10,15)的间隙锁
虽然sessionB被block了,但是其加锁过程是:想要加(5,10]的next-key-lock,具体过程是先加(5,10)的间隙锁,加锁成功,再加10的行锁,被block了,因此sessionA需要插入数据时被sessionB的间隙锁阻塞了,造成了死锁!
-
[mysql是如何保证redo log与binlog完整性的]
原文地址:https://www.cnblogs.com/ningxinjie/p/17336913.html
write:是写到操作系统的page cache
fsync:是刷到磁盘(占用磁盘 IOPS)
引言:我们都知道redo log + binlog可以做到崩溃恢复(crash - safe),那redo log与binlog的完整性mysql是如何保证的呢?
-
binlog:
-
要点:事务提交后才能写入binlog,且要保证事务的完整性。(因为记录到binlog备库就要使用了,因此事务未提交绝对不能记录到binlog)
-
先写binlog cache(每个线程/会话 1份,大小不足使用磁盘临时文件来记录),再写binlog文件
-
sync_binlog 含义 0 每次提交只write,不fsync 1 每次提交都会fsync N 累计N次提交后fsync
-
-
redo log
-
要点:和binlog不同,其事务是否提交记录到redo log,备库也不用,因此无所谓
-
先写redo log buffer(共用1个),再写redo log文件
-
innodb_flush_log_at_trx_commit 含义 0 每次提交只把redo 留到redo log buffer中 1 每次提交都会把redo log buffer fync到磁盘 2 每次提交都会把redo log buffer write到page cache
-
-
双1配置:
- sync_binlog=1&innodb_flush_log_at_trx_commit=1
-
mysql的优化
-
redo log的组提交:redo log buffer空间是共享的,因此在一个事务提交时,会连同其他事务的redo log一起fsync,这些被连带提交的事务,在真正提交时发现自己需要提交的redo log已经被fsync了,就不必再操作了。(使用LSN的概念来记录长度的,这个说后文会讲,先记录下)
-
binlog的组提交:因为binlog是每个先成一份cache,因此在binlog cache没法使用组提交,因此mysql将binlog的write后,需要fsync时,将write的部分一起fsync。
-
binlog_group_commit_sync_delay 表示redo log repare阶段fsync后延迟多少微秒后再执行binlog的fsync binlog_group_commit_sync_no_delay_count 表示累计多少次以后再执行fsync 以上表格binlog希望尽量应用到组提交的属性,是或的关系(即满足1个就fsync了)
-
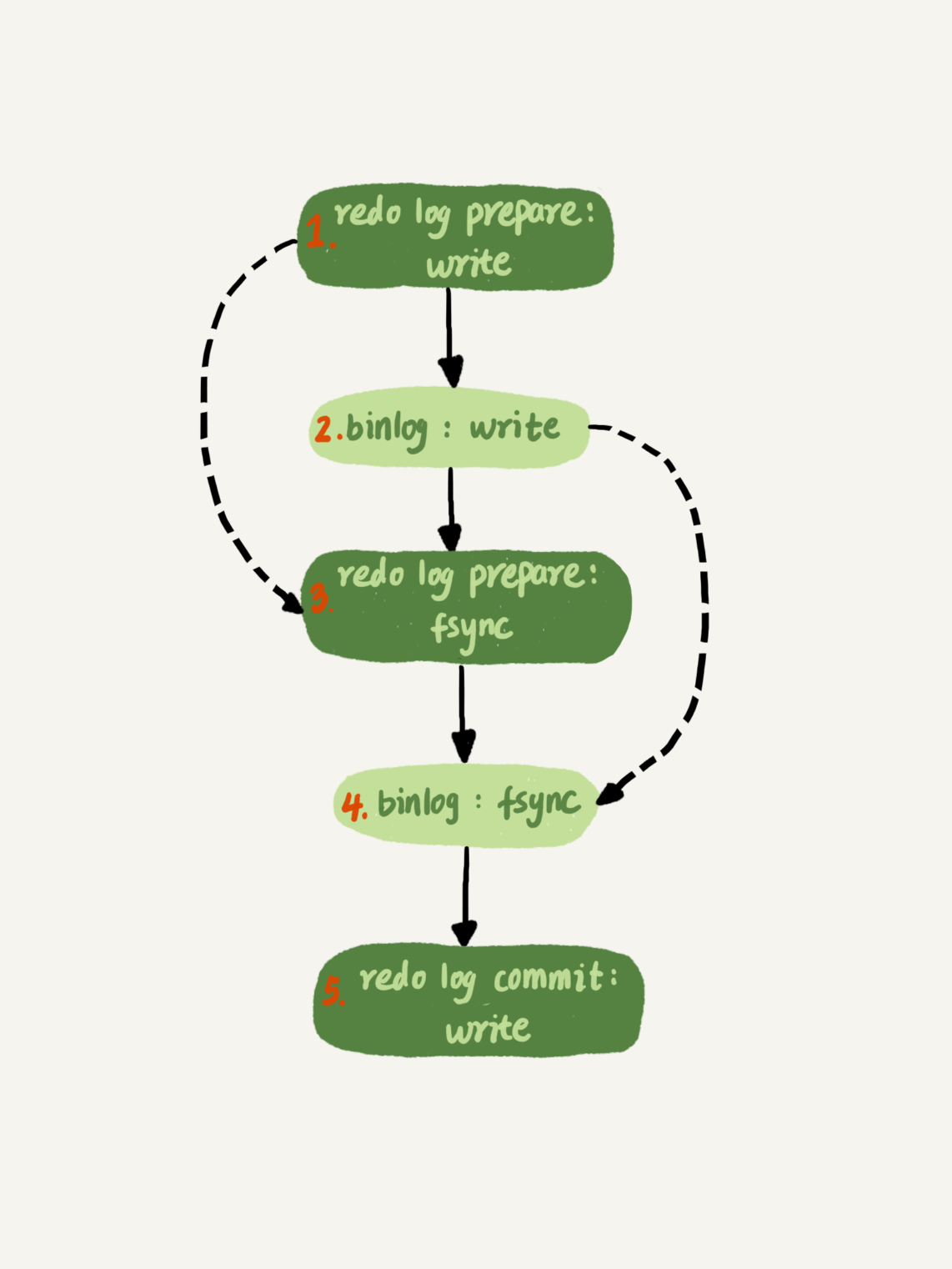
-
-
说明一点:fsync是针对redo log的prepare阶段和binlog的写入阶段的。redo log的commit阶段是直接write的,因为有了前两个阶段就已经能实现crash-safe了,因此redo log的commit阶段不直接刷盘了!
-

-
补充:redo log的组提交的个人新理解:第一个事务提交的时候,会等待一小段时间,如果这段时间其他事务也提交了,就一起刷到redo log中(标记这些为prepare阶段)。针对其他正在进行中的但是未提交事务,我理解就是不会标记prepare阶段
-
[当主从延迟变大时,从库可以修改redo log和binlog的刷盘时机,来加速主从同步]
-
-
[主从延迟second_behind_master的计算值 = 从库执行完SQL时间 - 主库提交binlog的时间]
-
主库执行完语句,从binlog cache写入binlog,时间为T1
细说就是:redo log的prepare阶段写入完成,binlog写入,此时就会同步了,而不用等redo log的commit阶段
-
主库发送给从库,从库接收并记录到relay log,时间为T2
-
从库执行relay log中的语句,时间为T3
second_behind_master = T3 - T1
【通常,
seconds_behind_master的值是根据从库正在执行的 relay log 语句的时间戳与最新接收的 relay log 语句的时间戳之间的差异来计算的。这个差异表示了从库在执行当前语句之前所滞后的时间。】
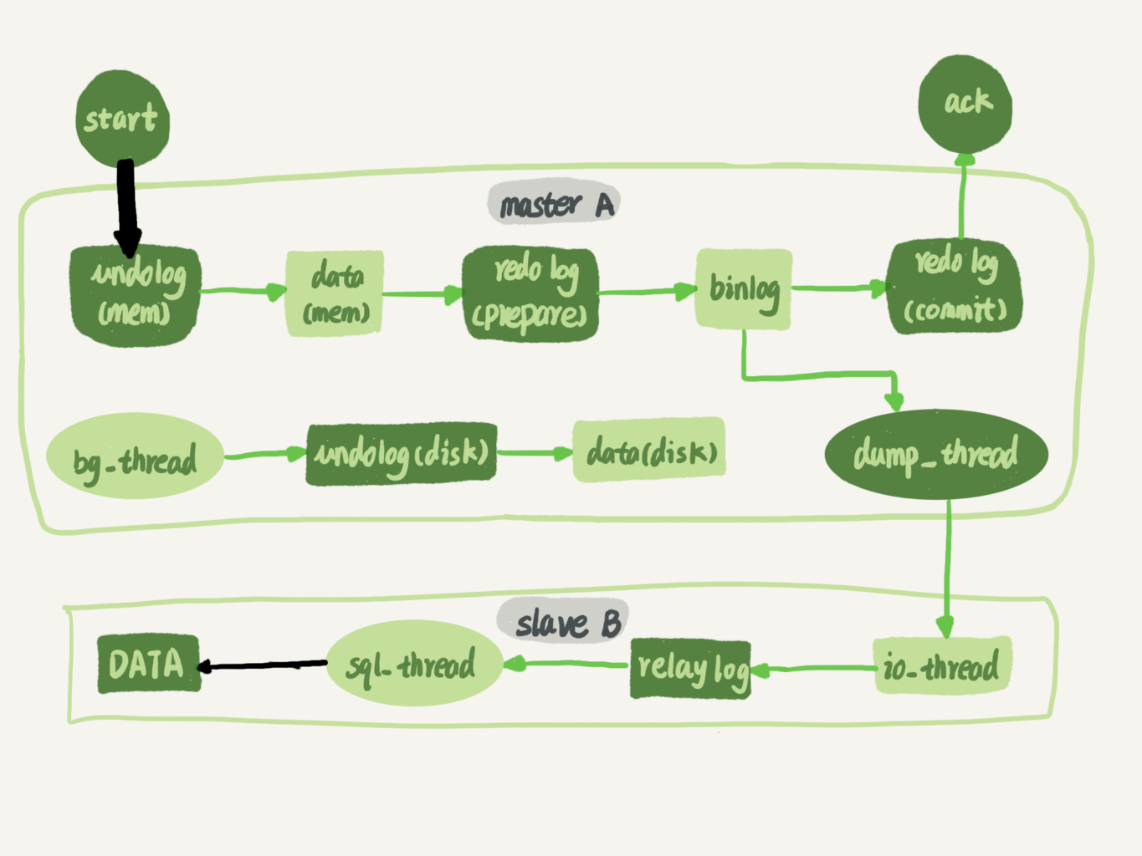
-
-
[只有在事务提交的时候,才会写入binlog,从库才会收到]
这部分内容在上方有说明,但是因为写的太长了,就把要点单独抽出来写一下
事务未提交的时候
-
对于binlog:语句一定在binlog cache(线程隔离、事务隔离)
-
(我个人的理解,因为按照这个理解,下面才能串通)对于redo log:语句不一定都在redo log buffer,因为组提交可能随着一个事务的提交,已经写入了redo log。第一个事务需要提交时,稍等一小段时间再提交
- 这段时间提交了的事务,则同时记录prepare阶段
- 这段时间未提交的事务,则只记录到redo log不标记阶段
-
-
[为了减少主从延迟,从库尽量针对不同事务并行复制]
原文地址:https://www.cnblogs.com/ningxinjie/p/17336925.html
以下2个为原则:
- 同一个事务不拆解(为了保证从库查询事务的一致性)【因此1个大事务不会被拆解并行同步】
- 操作同一行的不同事务,不能并行(为了保证主从数据的一致性)
总结下从库并行复制的思路:
- 按表复制
- 按行复制(采用这个)
只要不同事务不涉及同一个行,就可以并发,执行逻辑如下:
- 不同事务不涉及处理同一行,直接分配给空闲worker处理即可
- 涉及同一行,且与多个worker冲突,阻塞等待
- 涉及同一行,且只与一个worker冲突,分配给那个冲突的worker排队执行,不再阻塞,继续分发并行后置relay log
期间纠正到的知识点:
- redo log的组提交是第一个事务在提交的时候等待一小段时间,如果期间有其他事务也提交了,就一起写入redo log的prepare阶段
- 处于prepare一起可提交的,和redo log commit期间的,这两部门的事务都是可以直接并行执行的(因为如果涉及到行锁,他们就不可能处于同时提交状态)
总结:
记住按行复制的思路即可(除了id,也得考虑唯一键等)。
事务A:拆解涉及到哪些行修改
事务B:拆解涉及到哪些行修改
无冲突则并行,有冲突则看是否只有一个冲突,是则排队,否则阻塞等待
-
[GTID——切到新主库 和 新接从库 的优雅稳定的方式]
GTID模式默认选取的主库包含全部的数据,如果新选择的主库比从库少数据,那GTID模式的主从同步会直接报错!
对于当前已经存在得GTID,数据库会直接忽略此条SQL。
切新主库的时候:从库将自己的GTID发送给新主库,新主库验证全部GTID全都存在
- 不存在则直接报错,停止同步
- 存在则找到主库还未同步给从库最小的GTID语句,从此处开始同步给从库,从库对于GTID相同的直接忽略
可使用以下两条命令查看是否开启了gtid(小红书这边是开启的)
SELECT @@global.gtid_mode;SHOW GLOBAL VARIABLES LIKE 'gtid_mode'; -
[间隙锁看最右边,如果左边边界被删除,锁的范围会被放大]
锁的答疑文章:https://www.cnblogs.com/ningxinjie/p/17336941.html
再说一句:间隙锁和next-key-lock要求隔离级别是可重复度!如果你是读已提交,就不会有这些锁!
隔离级别的查询:
SELECT @@tx_isolation;-
比如sessionA加锁范围是(5,10],sessionB先删除5这行,再插入5这行就会被阻塞。因为当sessionB删除5这行时,sessionA的范围就变成(0,10](这里假设0是db存储5前面那个值)
sessionA sessionB begin
select * from t where c > 5 and c <10 for updatedelete from t where c = 5 此时 (5,10],因为5的缺失,锁范围变成(0,10] Insert t values(5,5)
会被阻塞- sessonA的加锁过程
- (等值查询)先找到c>5的第一个值c=10,对其加next-key-lock (5,10]
- 因为c=10已经不满足了,因此停止了遍历
多说一下:如果语句是
select * from t where c > 5 and c <10 for update则加锁过程是(先等值找,再后面都是范围查询,范围查询就不会进行优化条件)
- (等值查询)先找到c>5的第一个值c=10,对其加next-key-lock (5,10]
- (范围查询,因此不会退还为间隙锁)继续向右遍历下一个c=15,对其加next-key-lock (10,15]
- sessonA的加锁过程
-
-
[buffer pool 是引擎层的]
[大表全表查询发挥,服务端是分批返回给客户端的,因此即使是超大表,也不会因为数据过多造成OOM]server层:
net_buffer(每个线程独立各一个)
本地网络栈(server层共享一个)
- 查询结果数据写到net_buffer中。这块内存大小默认16k,每个线程一个
- 当本线程的net_buffer内存空间写满,则调用网络接口发给客户端
- 如果发送成功则清空net_buffer,继续读取数据
- 如果发送函数返回
EAGAIN或WSAEWOULDBLOCK,就表示本地网格栈写满了,只能阻塞等到本地网格栈有空间后才能继续。
innodb层:
buffer pool内存页的优化
内存页采用LRU的变形(划分为young区和old区域(5:3的占比))。
这个old和young跟之前理解相反,新读进来的内存页先放到old区头部,如果下次读取old区的内存页发现其已经在内存停留了1s则移到young区的头部(这样就避免了一部分历史大表的扫描,导致内存命中率降低)
-
[领略个核心要点:分析为什么需要加锁,可以看最终的binlog会不会造成数据不一致,如果从库回放数据不一致,那就需要锁来保证]

