
JVM整理文档
大致先记录到这里,以后有时间我会更加详细的总结出自己的一套东西,下面是我对jvm基础的算精简的总结,加油!
jvm官方说明:https://docs.oracle.com/en/java/javase/11/tools/tools-and-command-reference.html
main-tools-create-and-build-applications/java就能看到各种可以调整的参数设置
https://docs.oracle.com/javase/8/docs/technotes/tools/unix/java.html
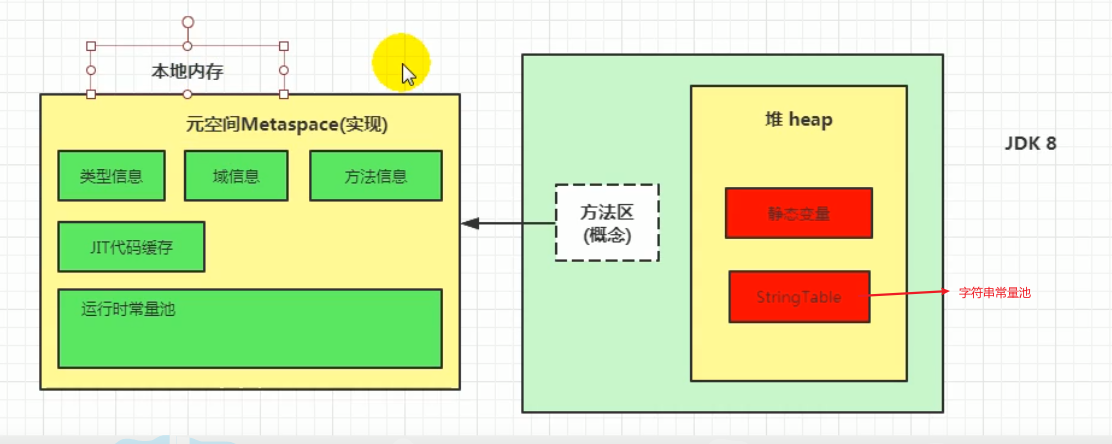
常量池是在方法区的,但是字符串除外,字符串的常量池存储在堆空间【静态变量也是存放在堆空间的】【针对于jdk7及以后,jdk6及以前是存放在永久代,这都快过时了,下面主要针对于jdk8】
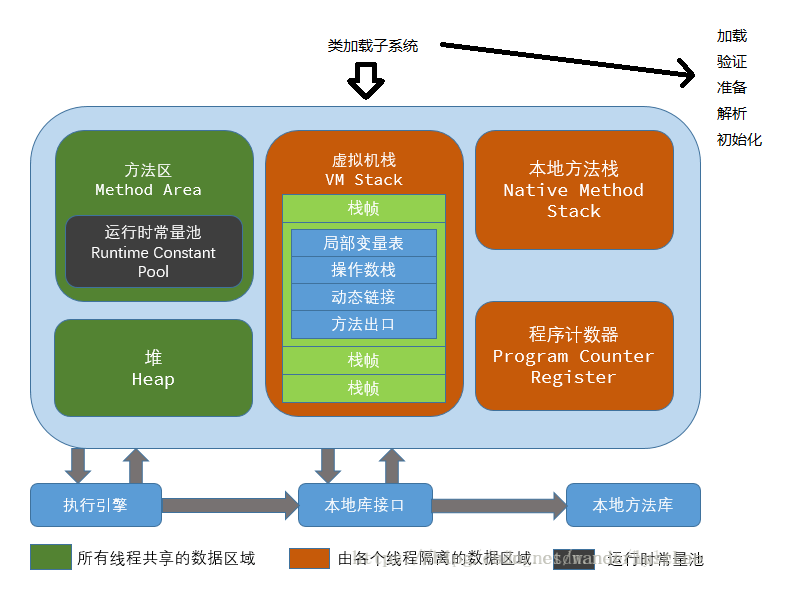
类加载子系统
类加载过程
类加载器:系统类加载器-》扩展类加载器-》系统类加载器/自定义类加载器
其实除了系统类加载器外,它是用C或C++编写的,其它的都可以叫做自定义类加载器
整个加载过程只会执行一次,包括加载、验证、准备、解析、初始化!
类的二进制流加载进来
实例化该类的时候,直接进行以下操作:
验证
准备
解析【将符号引用转为直接引用】
初始化【只要有static就会生成
(),加载的时候执行这个方法】 加载完毕后的类的数据被放在方法区的元空间(jdk8)
一个子类要被实例化之前,它的父类必须完全加载完,包括加载、验证、准备、解析、初始化(由此下面代码就很好理解了)
static class Father{ static int a = 1; static{ a = 2; } } static class Son extends Father{ static int b = a; // 此时b的值是2 }
由此可以看出,一个类被加载一次之后,就不用再次加载了,它被存储在元空间了,以后实例化它只需要继续执行接下来操作即可。
双亲委派机制
当前类的加载首先往上找父类加载器,如果父类能加载则直接加载,如果不能,再递减,直至子类加载器,举个例子:
我们自己创建java.lang包,在里面写String类,这样是外部是加载不了的,因为String所处的包是java.lang,而这个包可以被BootStrap加载,因此加载的是系统的String类,即使我们在自己创建的java.lang下放其它系统里没有的类,去访问也是有问题的,因为java.lang的加载归启动类加载器管,而我们是没有权限访问这个加载器的。
沙箱安全机制
双亲委派机制就是沙箱安全的,也就是我们无论怎么操作,都不会影响外部正常的使用,这就叫沙箱安全。
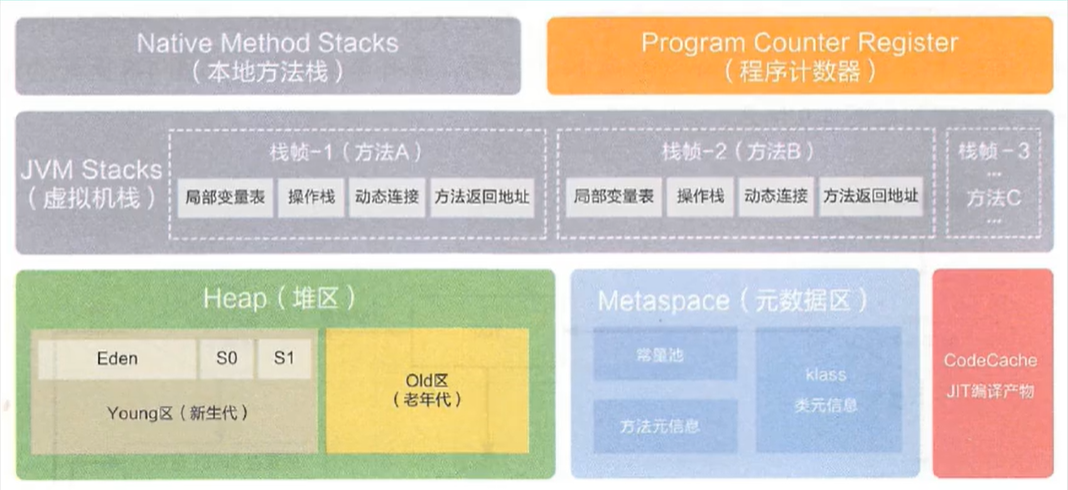
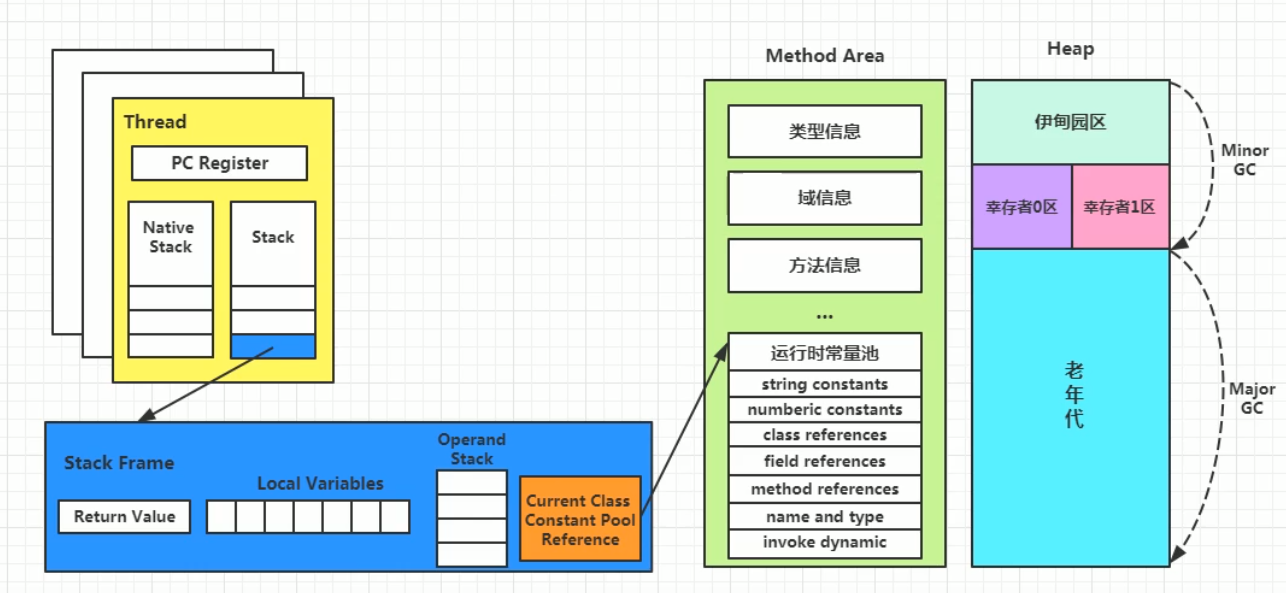
运行时数据区
查看
jps
返回:java进程号 进程名
jinfo -flag MetaspaceSize 进程号
返回:-XX:MetaspaceSize=21807104 #使用的元空间内存大小
jinfo -flag MaxMetaspaceSize 进程号
#非管理员禁止访问,返回的是本地可用内存大小
-XX:MaxMetaspaceSize=18446744073709486080
JVM栈
参数调节
-Xss256k:设置栈空间大小设置为256kb
-Xss1m
-Xss1024k
-Xss1048576栈内部有局部变量、方法返回地址、操作数栈、动态链接、一些附加信息。*
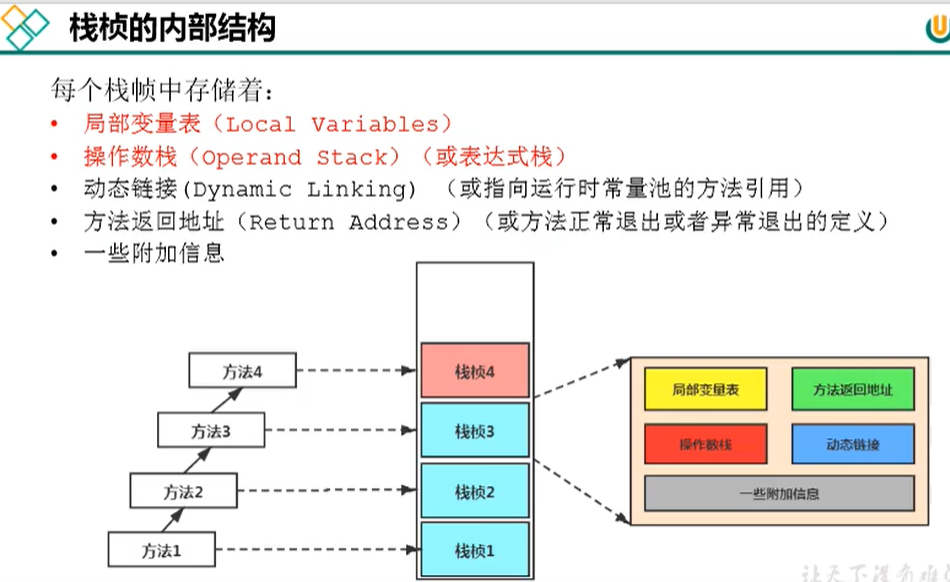
局部变量表把需要的数据汇总,操作数栈从这里面取,按步骤去执行
操作数栈取数据计算,存储临时数据,计算完成后,将数据放回局部变量表中
局部变量表
局部变量表的大小在编译阶段就确定了,运行阶段不会动态调整!
方法形参,及方法内部使用的局部变量,包括8种值类型,引用类型则存放引用地址
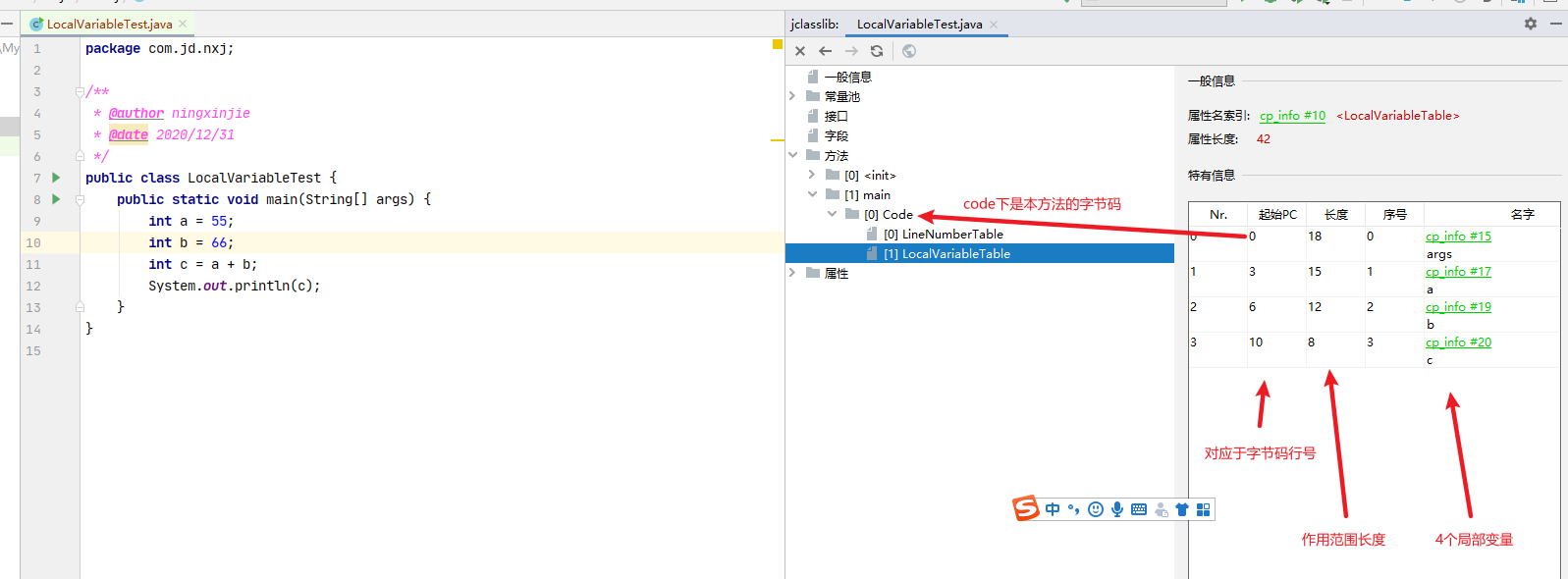
局部变量表的基本单位是slot,double与long占用2个slot,其余占用一个slot【是double与long,如果是Double与Long就是引用类型了,它也是占用1个slot】
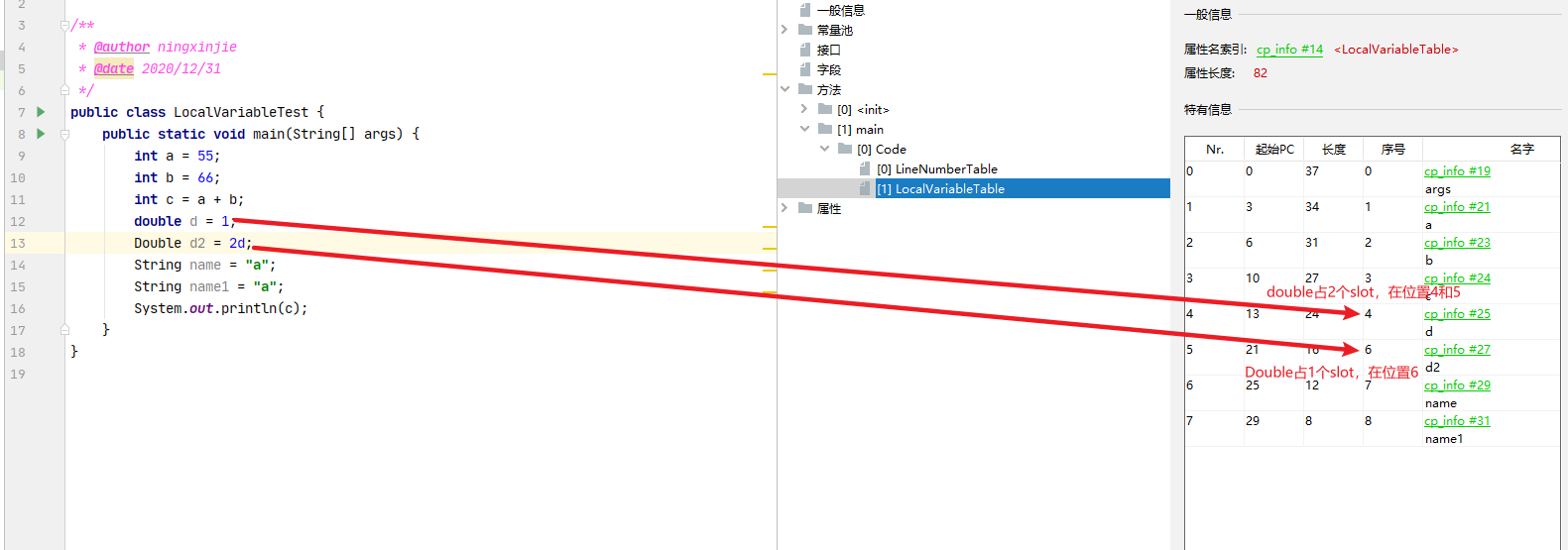
非静态方法和构造器,第一个slot放的是this,因此我们可以在构造方法和非静态方法中使用this,而static中并没有,因此无法调用this
slot可以重复利用的,如下示例
int a = 1; { int b = a + 1; } int c = 2;0位放的是a
1位放的是b,b的作用范围没了
1位放c【此时这个slot就被重用了】
private static String sstr;// 这样在初始化阶段就不用显示赋值了,也就是在prepare准备阶段,赋值为默认的null private static String staticStr = "静态变量在prepare阶段,默认赋值(默认值,引用类型就是null),在初始化阶段显示赋值为当前写的字符串"; private String nstr;// 实例化的时候随着对象创建,默认初始化 private String newStr = "实例变量随着对象的创建会在堆空间分配变量空间,并进行默认赋值";
局部变量表也是GC回收的根节点,只要被局部变量表直接或间接引用的对象,是不会被GC的
操作数栈
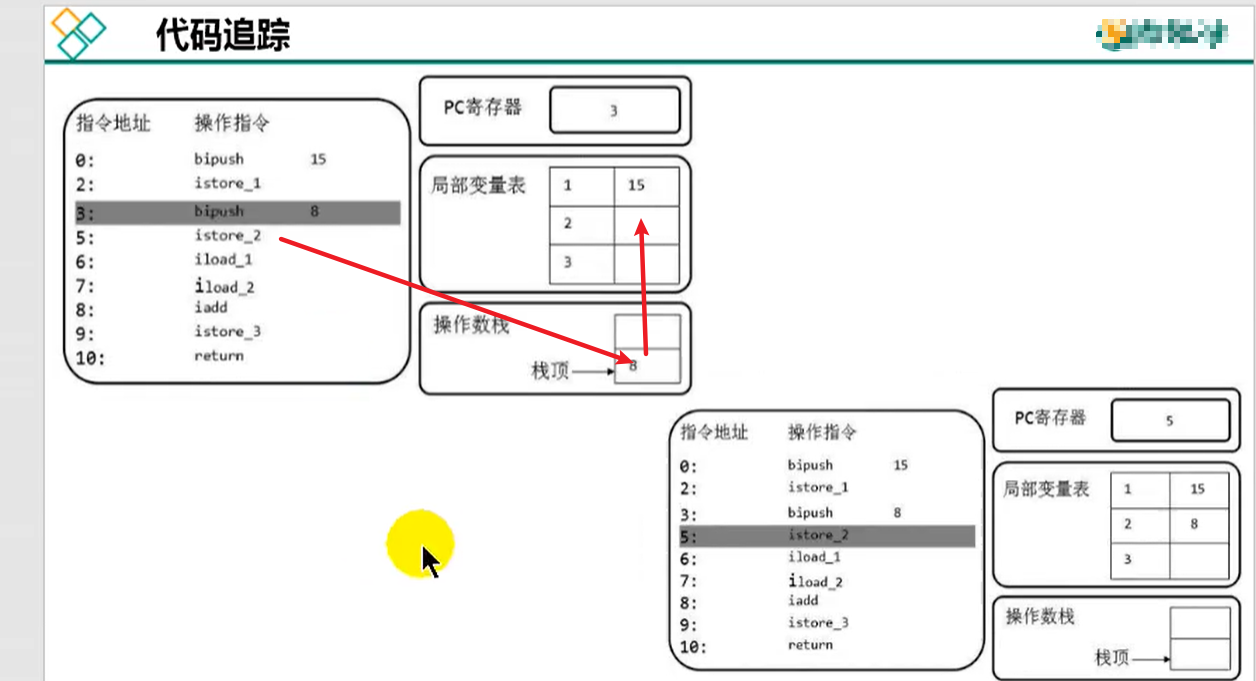
执行的整个过程:https://www.bilibili.com/video/BV1PJ411n7xZ?p=53
动态链接
java代码被编译到字节码文件的时候,所有的变量和方法都作为符号引用,保存在class文件的常量池里
动态链接作用就是为了将这些符号引用转换为调用方法的引用
常量池实际上是放在方法区的,在运行的时候将类的变量和方法生成常量池信息,放入方法区,因此动态链接也可以叫做指向运行时常量池的方法引用
【即将符号引用转为直接引用】

【更好理解】
静态链接:当一个字节码文件被装载进JVM内部时,如果在编译期即可确定被调用的方法,且运行期保持不变,这种情况下在编译器就会将符号引用转为直接引用,这过程就叫做静态链接。
动态链接:被调用的方法在编译器无法被确定下来,也就是说,只能在程序运行期将调用方法的符号引用转为直接引用,引用的转换过程具备动态性,因此也就被称为动态链接。
【个人理解】
因此常量(final)信息引用的这些,在编译的时候就确定了,因此这些变量在编译器就将符号引用转换为直接引用了。
早期绑定:在编译器就能确定,且在运行期不会改变的引用
晚期绑定:在编译器无法确定,在编译期会改变的引用(如我们方法传递的参数是一个接口,那么我们编译的时候根本无法确定,运行时到底要跑这个实现接口下哪个类的方法)
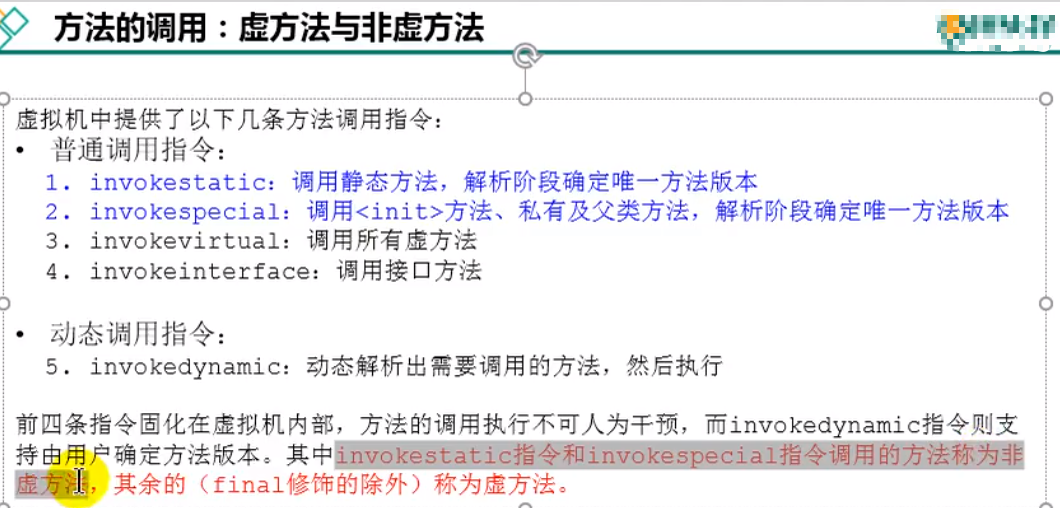
虚方法与非虚方法
非虚方法:静态方法、私有方法、构造方法、父类方法【invokestatic与invokespecial】
虚方法:编译期间无法确定下来调用哪个的方法【invokevirtual与invokeinterface,加了final的除外,是非虚方法】
方法返回地址
场景:A方法内部调用B方法
当方法内部调用其他方法的时候,其他方法调用完,会将它的返回值压入A方法的操作数栈,并恢复其PC寄存器,局部变量表,让A开始继续往下执行。
方法正常退出则有返回值,方法异常退出则无返回值压入,异常抛给A方法。
| 可能会出现Error | 是否需要GC | |
|---|---|---|
| PC寄存器 | 不 | 不 |
| JVM栈 | 可能(StackOverFlowError) | 不(用完栈帧就出栈了) |
| 本地方发展 | 可能 | 不 |
| 堆 | 可能(OOM) | 需要 |
| 方法区 | 可能(类字节码信息加载过多) | 需要(Full GC) |
本地方法栈
调用本地方法后,本地方法具有和jvm一样的权限,它可以直接使用本地寄存器、本地内存等,因此效率会高。(因为本地方法和操作系统一样,都是使用的C或C++实现的)
本地方法接口(native)
堆
1个进程对应1个JVM实例
JVM启动的时候,堆就被创建完成且大小固定
参数调节
-Xms20m -Xmx20m
-Xmn10m 指明新生代大小是10m
初始容量 最大容量
在D:\Enviroment\jdk1.8\bin\jvisualvm.exe启动能看到我们的进程
在工具->插件里,安装下visual GC
堆是线程共享的,但是内部又划分有线程私有的缓冲区(Thread Local Allocation Buffer,TLAB),每个线程占提分,提升更好的并发性(这样每个线程都可以单独操作堆内的数据)【我的理解就是不同线程要修改数据,都需要先拷贝但线程私有的TLAB操作,完成后在拷贝回堆(就是因为这样,线程之间不安全,因为默认线程之间是不可见的,这就是我的理解,随便写的。)】

元空间实际归属于方法区
我们设置的-Xms20m -Xmx20m针对的也是新生代和老年代
开发中建议将初始堆内存和最大堆内存设置成一样的,这样避免不断调整堆大小,造成服务器不必要的压力。
查看:-XX:+PrintGCDetails
堆的可用内存是Eden区大小 + 一个survivor大小 + 老年代大小
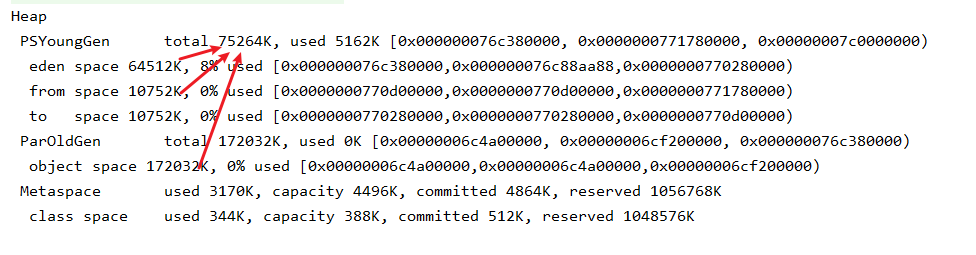

参数
jps
-XX:+PrintGCDetails #执行完毕后,打印GC细节情况
-XX:NewRatio=2 #设置新生代与老年代的占比为1:2
-XX:NewRatio=4 #设置新生代与老年代的占比为1:4
-XX:SurvivorRatio=8 #设置Eden区与survivor区的占比(显示指定,则就是按照显示指定比率的来分配空间)
-XX:-UseAdaptiveSizePolicy #默认是开启自适应的内存分配策略的,我们通过这条命令关掉
-XX:+UseAdaptiveSizePolicy #开启自适应的内存分配策略(+就是用 -就是不用)
-XX:MaxTenuringThreshold=15 #设置对象经过MinorGC几次之后直接放入老年代
总结:
频繁收集年轻代,较少收集老年代,基本不动永久代(jdk7)/元空间(jdk8)
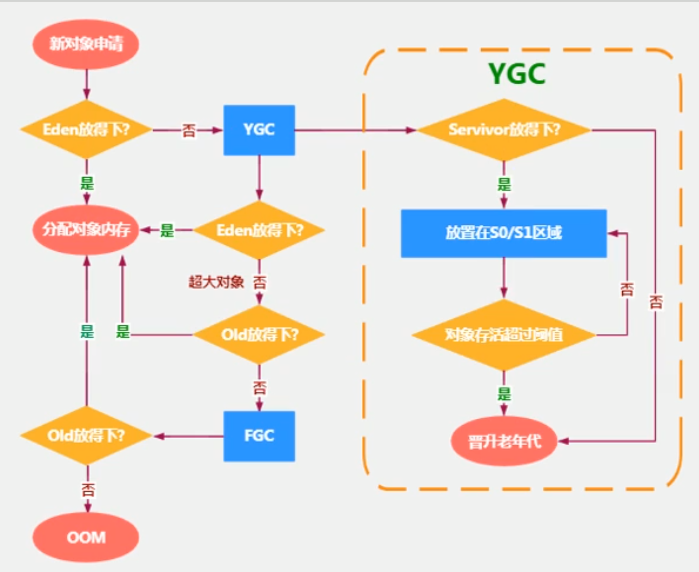
Minor GC、Major GC、Full GC
Minor GC:Eden区满了进行收集
Major GC:只收集老年代
Full GC:收集整个堆及方法区
只有Eden区满的之后才会触发MinorGC




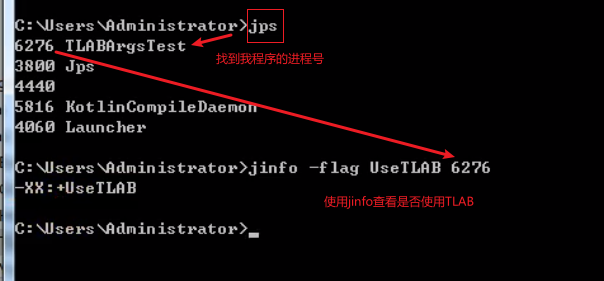
TLAB(及查看)
每个线程私有的,存放在堆里,分配的空间大约占Eden区的1%
以下说明很清晰:【TLAB就是解决对象分配内存的问题】
防止这块内存已经分配给某个对象,另外一个对象又过来占用,导致对象创建失败
因此每个线程创建的时候有自己一块TLAB,这样就不用加锁,创建就行,其他线程可以访问,但是不能在那里创建,如果创建的线程TLAB空间不足了,那么就需要在Eden的非TLAB区加锁创建(防止这块区域被其他对象创建覆盖了!)


可见TLAB针对于的是对象实例化之前,如果能在TLAB分配则在这里分配,如果不能则在Eden的非本线程的TLAB区分配。
堆空间参数设置
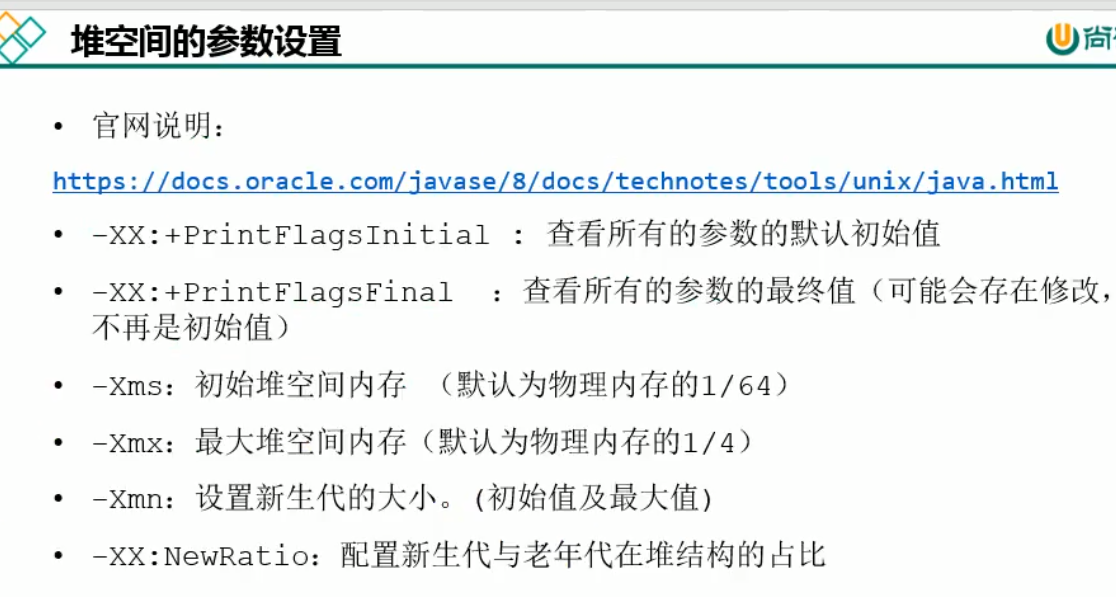


-XX:HandlePromotionFailure 目前jd7及以后修改无效,也就是说下面的情况,满足则Minor GC否则直接Full GC

对象一定在堆上吗?
答案是不一定的,如果没有发生逃逸,对象是可以在栈上创建,使用完随着栈帧的弹出而销毁。答案是:目前我们使用HotSpot是对象只能存放在堆上的,栈上不能存放对象,只能讲开启了逃逸分析和标量替换,它将不逃逸的对象替换成标量存放在了局部变量表中了!
逃逸分析
-XX:+DoEscapeAnalysis #默认也是开启的逃逸分析 -XX:-DoEscapeAnalysis #关闭逃逸分析
什么叫逃逸? 就是看当前new的对象实体有没有在方法外被使用【与本方法中调用方法接收没关系,关心的是本方法内部new的对象有没有在外部被使用】,如果当前对象从当前方法创建,外部无法使用到这个对象是,那么则说这个对象不会发生逃逸,这时就可能将这个对象分配在栈上(为什么呢?因为这个对象进入到堆里在GC的时候一定会被GC,这样做就是为了减少GC)
由此可见,能使用局部变量的就不要使用在方法外定义全局变量【也就是尽量让我们创建的对象不发生逃逸,从而减少往Eden区放入无用对象,从而减少GC的次数】
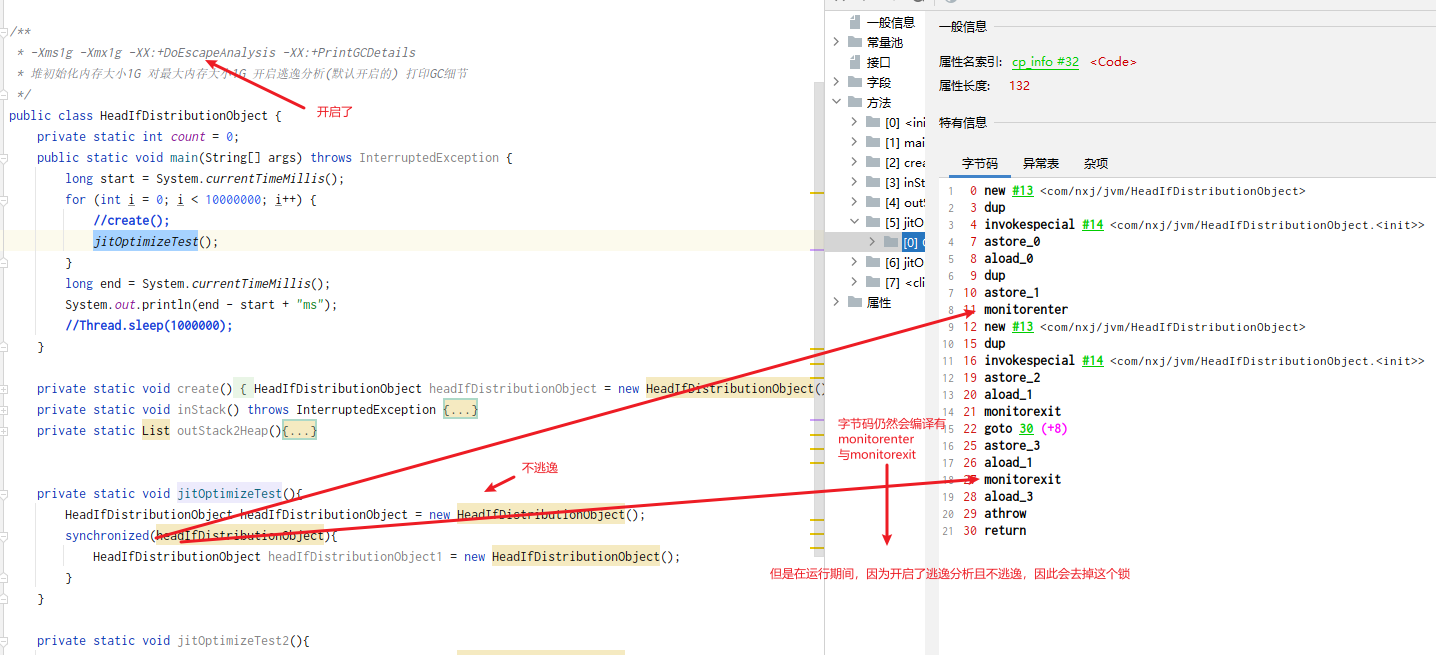
同步省略(锁消除)
有些对象只会被当前的对象访问到,因此即使加锁了,JIT也会在编译阶段进行优化,因此以下执行代码速度是一样的,因为JIT将上方代码优化为下方的代码了,当然我们开发中不要去这样写【默认是开启的逃逸分析,只要开启】
private static void jitOptimizeTest(){ HeadIfDistributionObject headIfDistributionObject = new HeadIfDistributionObject(); synchronized(headIfDistributionObject){ HeadIfDistributionObject headIfDistributionObject1 = new HeadIfDistributionObject(); } }private static void jitOptimizeTest2(){ HeadIfDistributionObject headIfDistributionObject = new HeadIfDistributionObject(); HeadIfDistributionObject headIfDistributionObject1 = new HeadIfDistributionObject();\ }只有开启了逃逸分析,这两段代码速度才一样,进位jvm根据逃逸分析发现我们加锁的对象只在方法内使用了,因此优化为不加锁,如果不开启逃逸分析,那么就会加锁执行,性能严重下降!
无论是否开启逃逸分析,在生成字节码的时候,只要加synchronized锁都会看到monitorenter与monitorexit,只是在运行的时候,开启逃逸分析的,可能会去掉。
标量替换
参数
-XX:+EliminateAllocations
默认是开启的
其实就是对象未发生逃逸,那么我将对象中的属性,如int,double等类型其内部的数据替换这个对象,并将这些值放在栈(局部变量表)中

小结:
测试了一下即使开启了逃逸分析,但是关闭标量替换,仍然是和没开启逃逸分析GC效果是一样的
目前Oracle公司也就是我们用的Hospot虚拟机,还不支持栈上分配,因此它基于的只有标量替换!


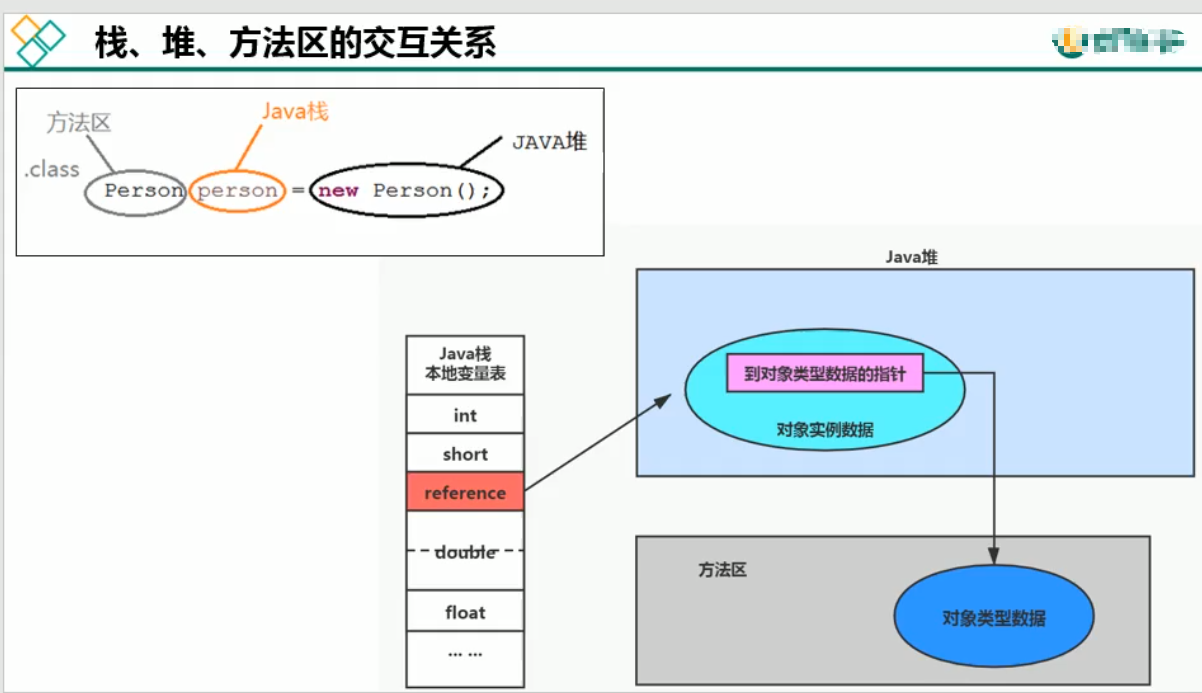
方法区
方法区(Method Area)与 Java 堆一样,是各个线程共享的内存区域,它用于存储已被虚拟机加载的类信息、静态变量、及时编译器编译后的代码等数据。

元空间使用的是本地内存,也就是非jvm的内存
参数设置:
查询
jps
返回:java进程号 进程名
jinfo -flag MetaspaceSize 进程号
返回:-XX:MetaspaceSize=21807104 #使用的元空间内存大小
jinfo -flag MaxMetaspaceSize 进程号
#非管理员禁止访问,返回的是本地可用内存大小
-XX:MaxMetaspaceSize=18446744073709486080
jconsole #也是一个jdk自带监控的,cmd直接输入即可
-XX:MetaspaceSize=100m #设置元数据区初始化大小,默认21M左右
元数据
使用的是本地内存,默认是21M左右,最大默认无限的
如何解决OOM思路

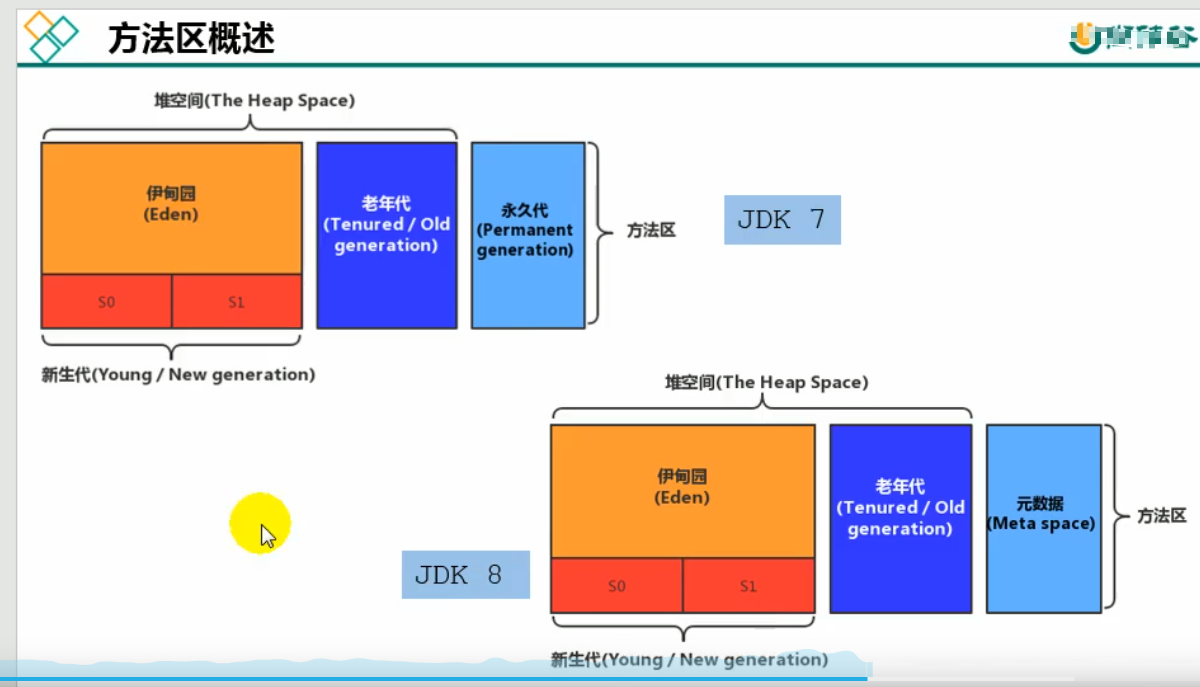
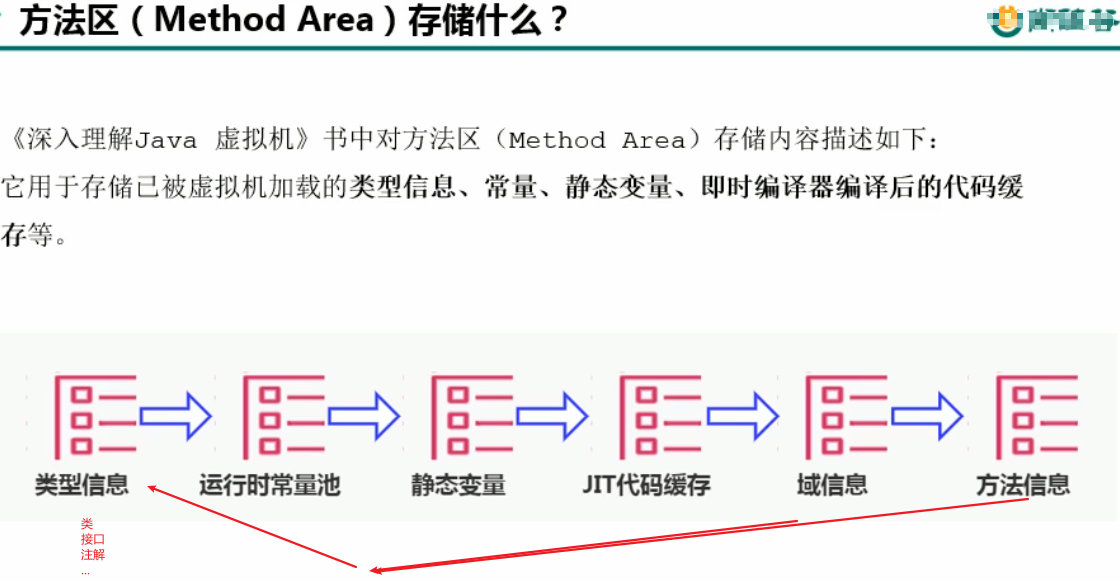
方法区的内部结构
类型信息、运行时常量池、静态变量(对于静态变量如何是new的对象,我的理解仍然是存放在堆中,这里保存的是引用地址)、JIT编译后的代码缓存【随着jdk版本的变化,不断改变,目前String类型的常量池就在堆中】【针对的是经典的版本来讲的】



javap -v -p HeadIfDistributionObject.class > text.txt:将反编译的字节码文件放入text.txt中
目前反编译的是准备进入到类加载器的编译文件,经过类加载器之后,除了会将类中一些信息记录,还会带上这个类是被哪个类加载器加载进来的,同时,类加载器在方法区也记录了它加载过哪些类
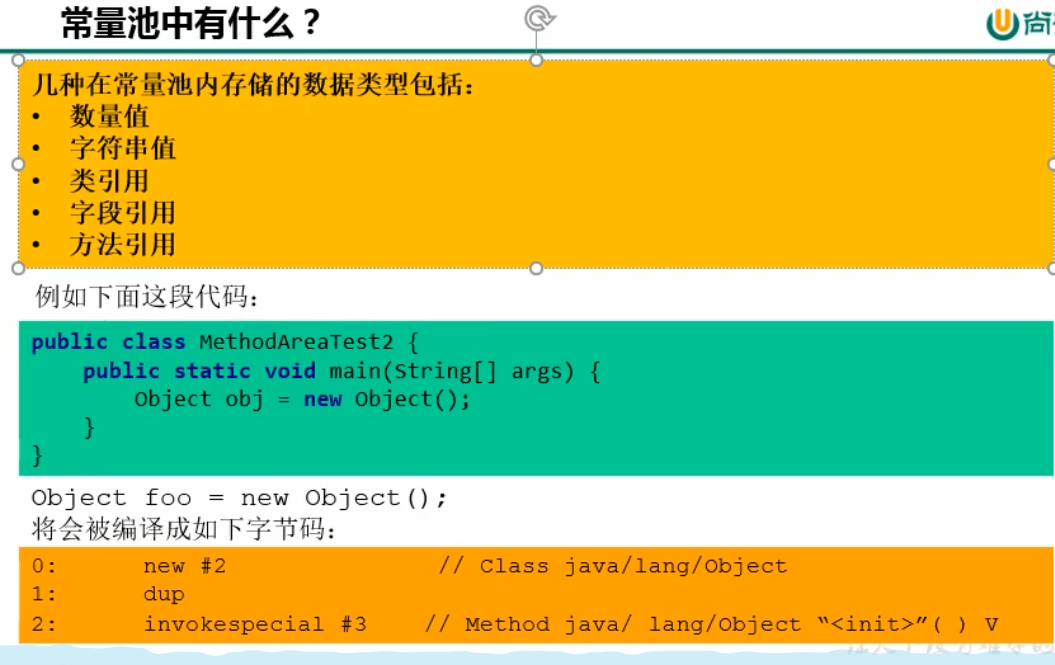
常量池:
方法区内有运行时常量池
字节码文件,内部包含了常量池
常量池就是将我们的字面量用符号引用代替
为什么要用常量池?
最简单举例子,我们写的类都是继承自Object,如果每次加载的时候我们都去加载一次Object显然是没必要的,我们用符号代替Object这个类,在解析阶段,将符号引用替换为直接引用即可。
常量池,可以看作是一张表,虚拟机指令根据这张常量表找到要执行的类名[类、接口、注解、枚举等]、方法名、参数类型、字面量等类型
运行时常量池:

jdk各版本方法区的区别
对象都是在堆中,以下指的都是变量名或方法名【名字】;

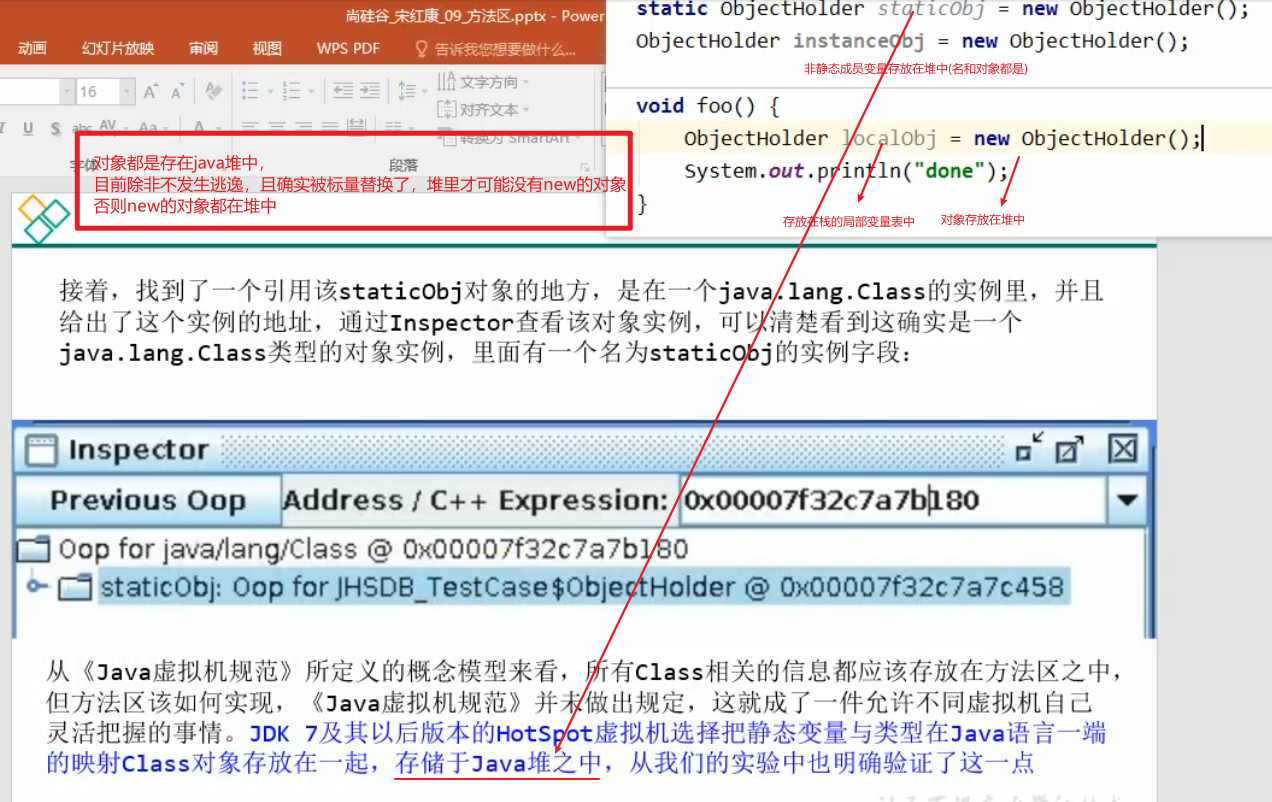
小结:
static final一起修饰的,在编译的时候就赋值了【要赋值的是对象除外】
只有static是在prepare设置默认值,在initialization设置我们想要赋予的值
之后带着类加载器写入方法区(记住,此时并没有产生这个类的对象)
示例:
源代码:
public static int count = 1; public static final int count1 = 2; public static StringBuilder sb = new StringBuilder("ouhou"); public static final StringBuilder sb2 = new StringBuilder("aiya");编译后classfile部分如下(此时只是经过编译,并没有进入类加载器):
public static int count; descriptor: I flags: (0x0009) ACC_PUBLIC, ACC_STATIC public static final int count1; descriptor: I flags: (0x0019) ACC_PUBLIC, ACC_STATIC, ACC_FINAL ConstantValue: int 2 //可以看到在编译阶段2就被赋予进去了 public static java.lang.StringBuilder sb; descriptor: Ljava/lang/StringBuilder; flags: (0x0009) ACC_PUBLIC, ACC_STATIC public static final java.lang.StringBuilder sb2; descriptor: Ljava/lang/StringBuilder; flags: (0x0019) ACC_PUBLIC, ACC_STATIC, ACC_FINAL //因为是对象,因此在编译阶段并没有赋予进去总结:
基本类型变量有final与static在编译阶段就赋值完成;
引类型有final与static,不会在编译阶段赋值,因为需要赋值的对象还没new出来啊,我认为如下:在prepare阶段设置初始值null,在initialization阶段创建对象并赋值【待验证】
不过有一点可以肯定,static修饰的类成员变量在进入方法区之前一定有值,因为测试如下代码就知道了:
class Order{ public static int count = 1; } //以下是main方法里面代码: Order order = null; order.count;//是不会报错的
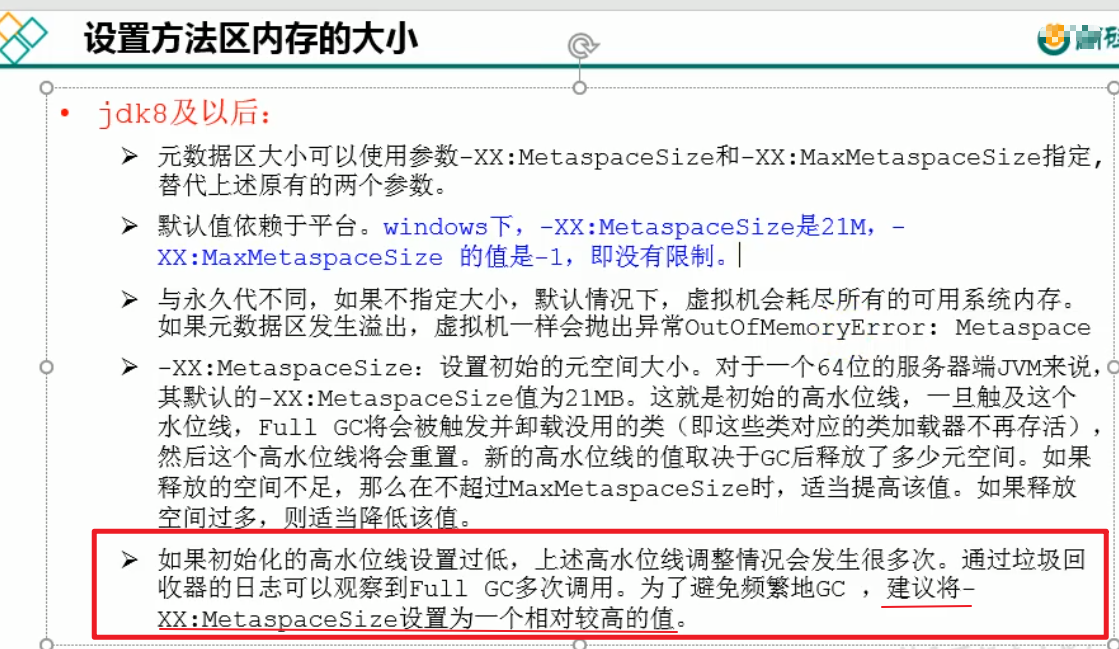
当我们要加载第三方jar包很多的时候,因为元数据区存放类的方法,属性,构造器,及类本身的字节码等信息,因此我们可以稍微调整初始大小大一点,否则一旦设定的初始化大小满了,则会触发Full GC,如果类还没完全加载完就满了 ,显然白白进行Full GC,因为空间不足,类才刚刚加载进来,就需要继续扩大元空间大小,这期间不断执行没必要的Full GC.
以下三个条件就是方法区的类信息被回收的必要条件,都满足了才有可能被回收
实例都被回收了
Class对象不被使用了,没有反射生成的对象
类加载器被回收了
面试题

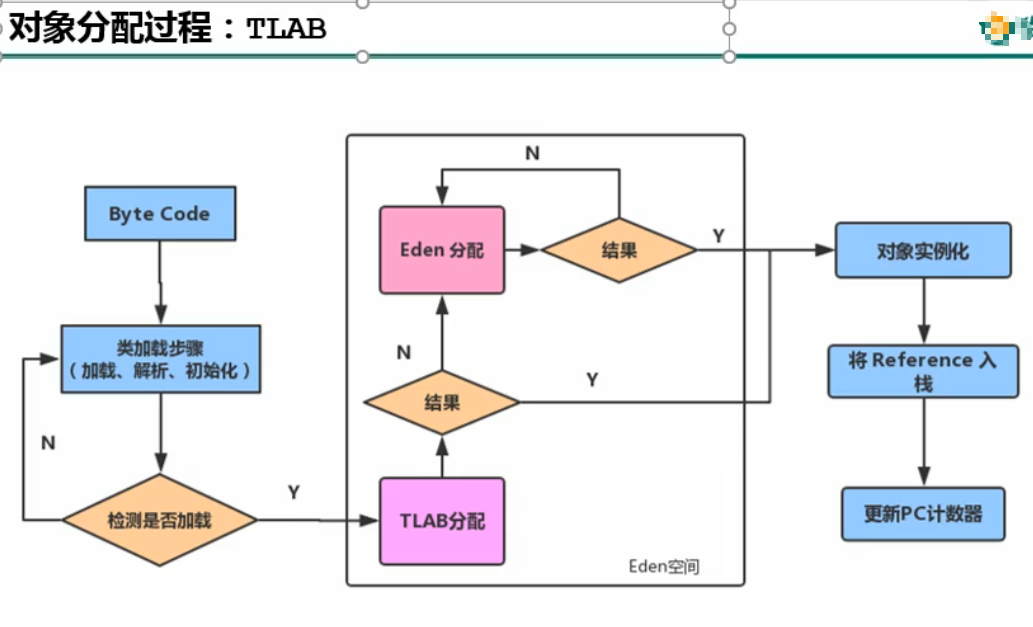
对象实例化方式及步骤
- 加载类元信息
- 为对象分配内存
- 如果开启TLAB,首先在本线程TLAB分配,如果不能则在Eden其与区域创建,并需要加锁(CAS)
- 对象属性设置默认值
- 设置对象头信息(包括指向方法区的类元信息等)
- 对象中的属性显示初始化、代码块中的初始化、构造器中的初始化。
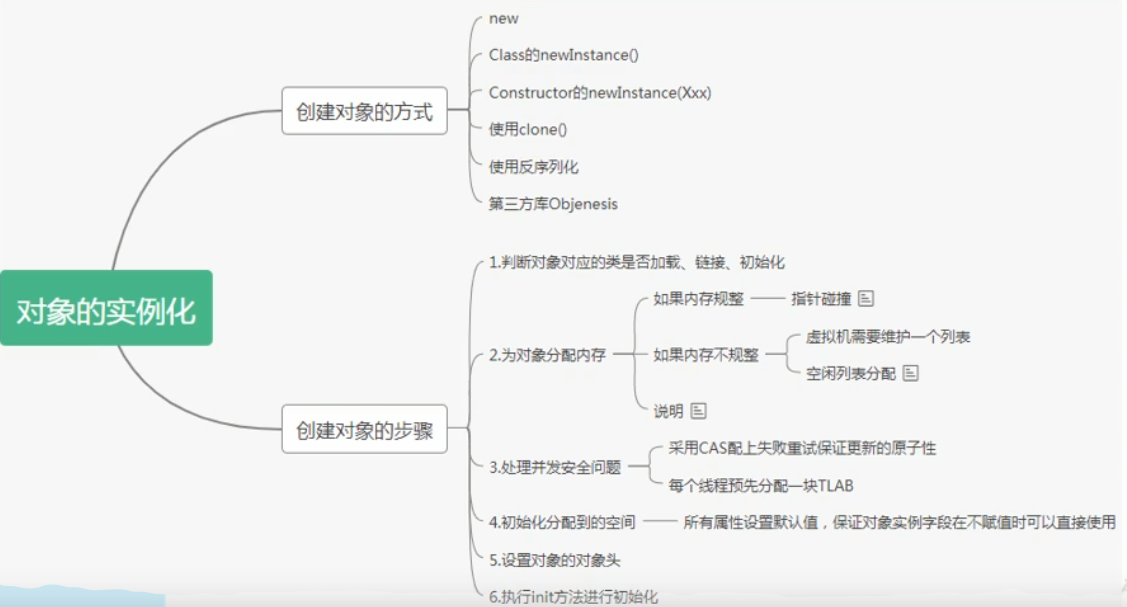
对象内的属性显示赋值、代码块、构造函数赋值等都在执行init方法内执行。

内存布局
对象的内存布局:对象头(运行时数据区,类型指针),实例数据,对齐填充
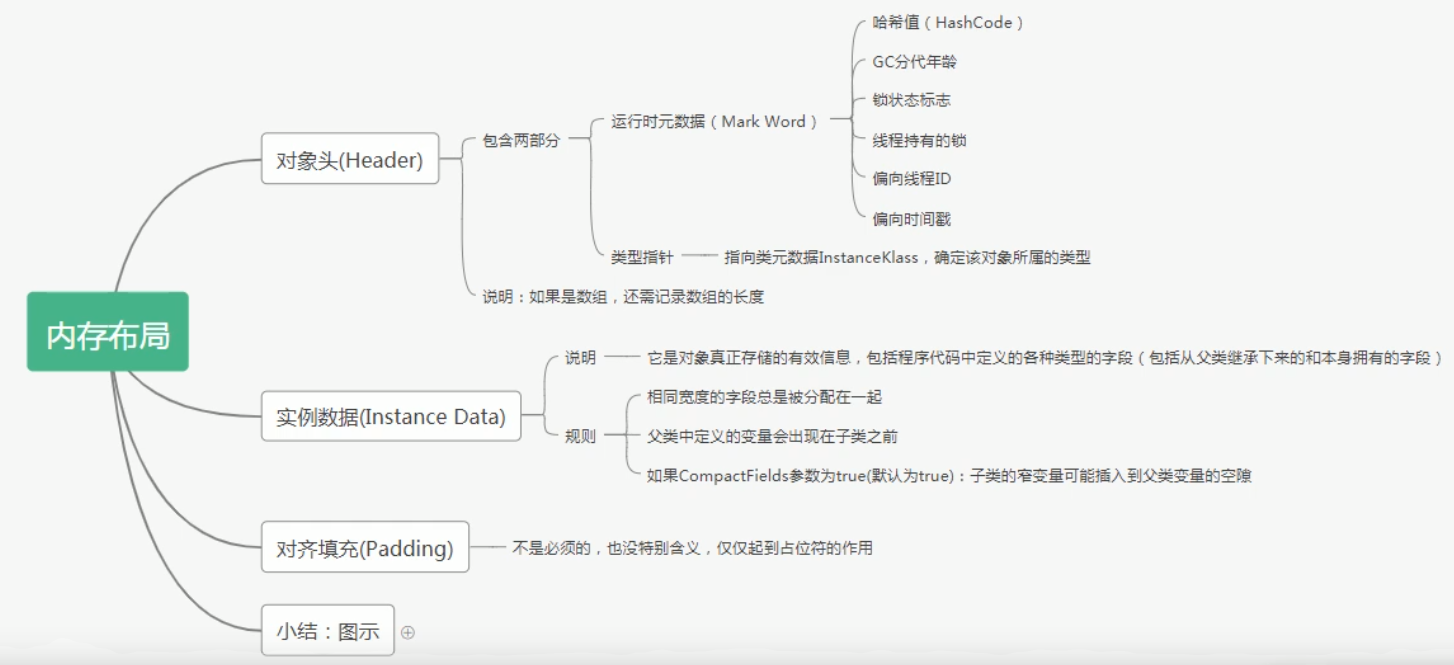

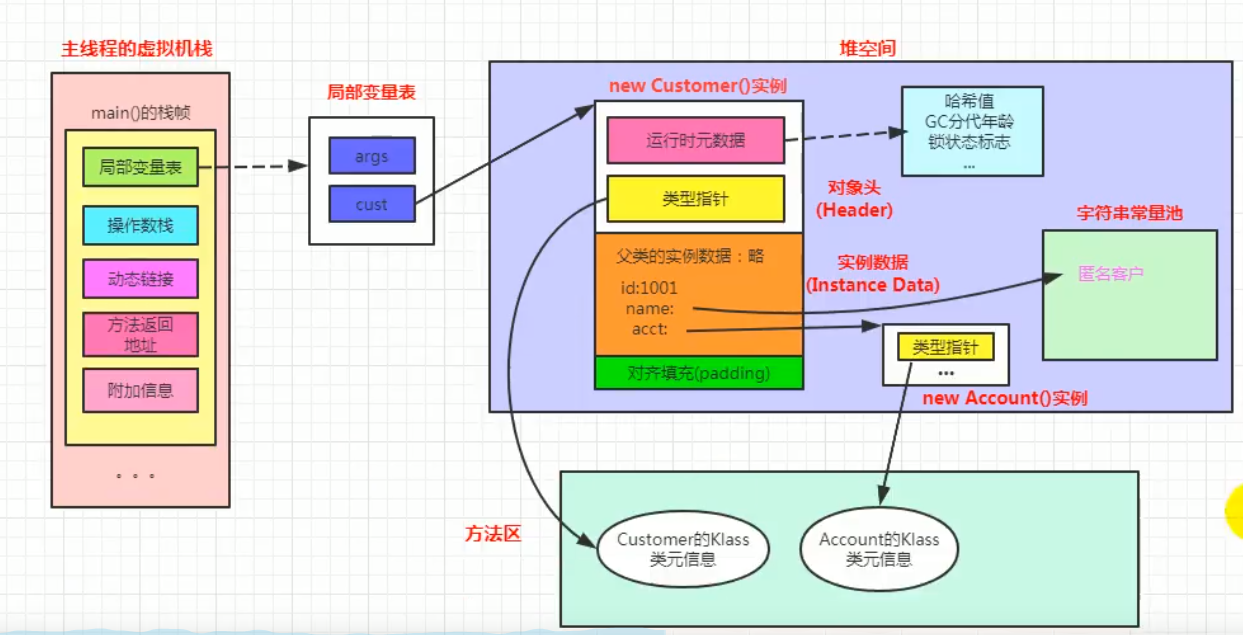
对象访问定位
1.使用句柄访问,也就是栈中的栈帧中局部变量表中变量指向的是堆中的对象的句柄,这个句柄指向这个对象,对于该对象的类元数据也是这样
2.使用直接指针(hotspot采用这种方式),变量直接指向堆中的对象,对象内部有类型指针执行方法区中该类元信息。
直接内存
-XX:MaxDirectMemorySize1G 来设置直接内存(防止占用本地过多内存,这些一般是在NIO的时候可以操作本地内存)
package com.nxj.other; import java.nio.ByteBuffer; import java.util.Scanner; /** * @author ningxinjie * @date 2021/1/3 * NIO使得用户程序可以直接使用直接内存,用于数据缓冲区,这样一来,对于文件频繁读写 * 效率显然会提升,因为不需要内核态与用户态来回切换,来回拷贝了 */ public class NIOBufferTest { private static final int BUFFER = Integer.MAX_VALUE ; public static void main(String[] args) { ByteBuffer byteBuffer = ByteBuffer.allocateDirect(BUFFER); System.out.println("直接内存分配完毕"); Scanner scanner = new Scanner(System.in); scanner.next(); System.out.println("直接内存开始释放"); byteBuffer = null; System.gc(); } }元数据和使用NIO操作的直接内存都是本地内存。
因此我们java占用系统的内存实际上是jvm占用内存与程序占用本地内存的和
执行引擎
解释器与即使编译器(JIT编译器)
解释器:逐行解释字节码执行
JIT编译器:将字节码编译为机器指令并缓存。
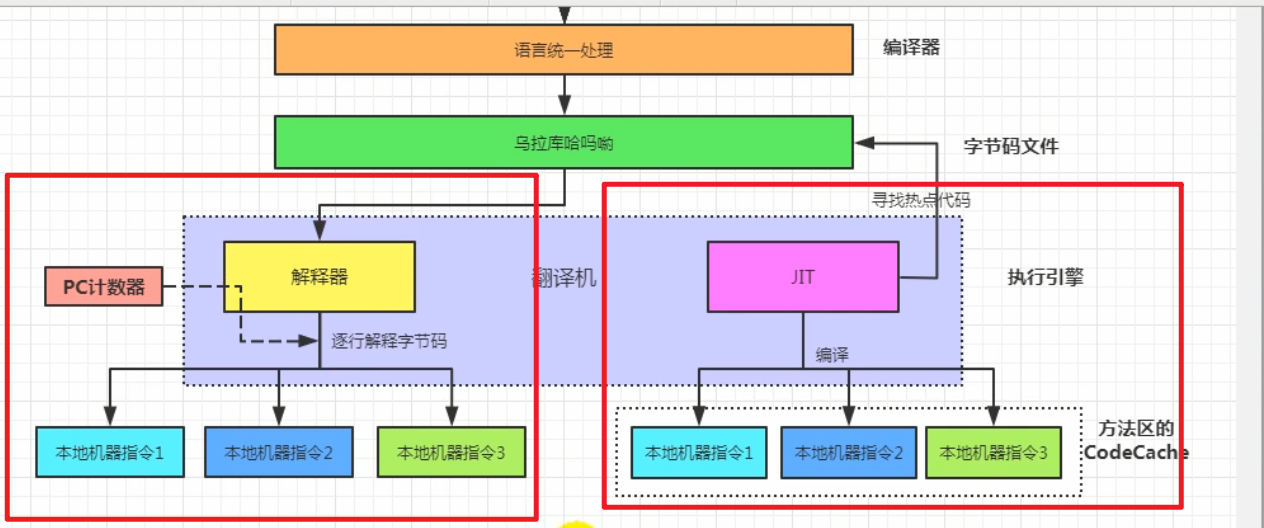
JIT编译器
解释器的好处是响应速度快,它可以直接将字节码进行逐行执行,但是JIT需要先编译,编译完后才能执行,当然编译完了之后执行效率就非常高了
因此jvm让二者互补,将二者都留了下来

解释器与编译器模式设置,默认是混合模式
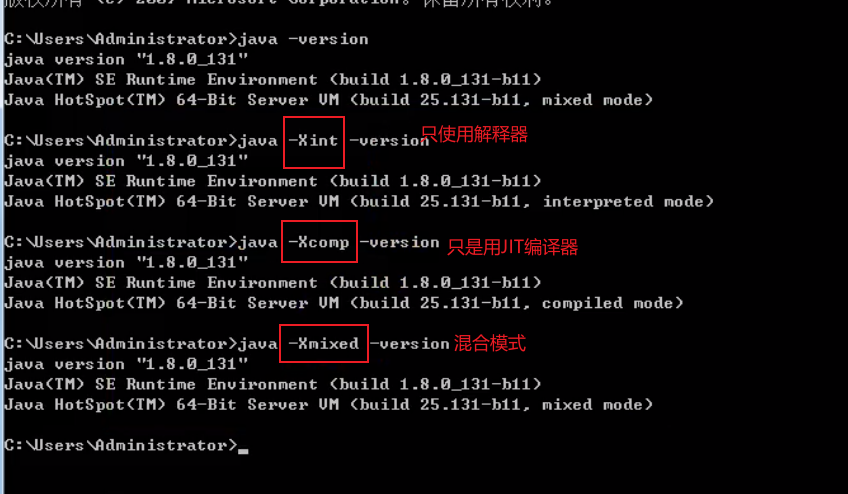
String常量池【jdk8及以后】
底层就是数组+链表【它不扩容】
可以通过-XX:StringTableSize=10000来设置数组长度
字符串常量池是放在堆里的
使用字面量或者.intern()方法将字符创放入字符创常量池

intern()方法!
将字符串放入字符串常量池
如果字符串常量池中有则将字符串放入
如果没有,则会把对象的引用地址复制一份,放入字符串常量池中,并返回串池中的引用地址(实际就是它自己)
很重要的String理解!
private static void testStringNiuBi(){ String str1 = new String("a");//生成2个对象,一个new的时候在堆里创建,另一个在常量池创建a(如果没有的话) str1.intern();//将字符串字面量放入常量池(此时a在创建的时候已经放入了,这里只是返回刚刚创建的结果 String str2 = "a";//字面量,去常量池找,没有则创建,有则返回地址 System.out.println(str1 == str2);//false /** * str3:创建对象: * 对象1:StringBuilder 变量+的时候,编译会帮我们优化为StringBuilder的拼接 * 对象2:new String("a") 在堆里 * 对象3:a 在字符串常量池 * 对象4 new String("b") * 对象5 StringBuilder在toString的时候 new String(char[]) 创建一个在堆里 */ String str3 = new String("a") + new String("b");//生成5个对象 3个在堆里,2个在常量池(如果常量池不存在的话) str3.intern();//将字符串字面量放入常量池(此时因为str3的字面量就是ab,为了节省空间,常量池会以一个指针形式指向str3) String str4 = "ab";//字面量,去常量池找,没有则创建,有则返回地址 System.out.println(str3 == str4);//true }对于程序中如果存在很多重复的字符串,使用intern会节省很大空间,如下所示:
String[] strs = new String[100000]; int[] arr = new int[]{1, 2, 3, 4, 5}; for(int i = 0; i < 100000 ;i++){ // 以下两种截然不同 // 给每一个String.valueOf(arr[i % 5])都生成一个对象 // String.valueOf(arr[i % 5]).intern();返回的是字符串常量池中的常量字符串地址 strs[i] = String.valueOf(arr[i % 5]); strs[i] = String.valueOf(arr[i % 5]).intern(); }
-XX:PrintStringTableStatistics
垃圾回收
hotspot回收的是堆和方法区
频繁回收年轻代
较少回收老年代
基本不动元空间
标记阶段
引用计数法
无法处理循环引用的问题
可达性分析算法GC Roots

总之最常见GC Roots的就是:
- 栈内的变量(局部变量表)【因为它指向堆内的对象】
- 本地方法栈同样
- 堆内静态变量区的变量
- 方法区的运行时常量池、堆内的字符串常量池。
- 具有synchronized锁的对象
- 内部基本类型对应的类及基本异常或者错误类等对象,也包括类加载器
- jvm本地代码缓存等,这些都是GC Roots不能被回收
面试题:


对象的finalization机制
对象在GC回收之前会调用其finalize方法

获取dump文件
方式一:命令行使用jmap
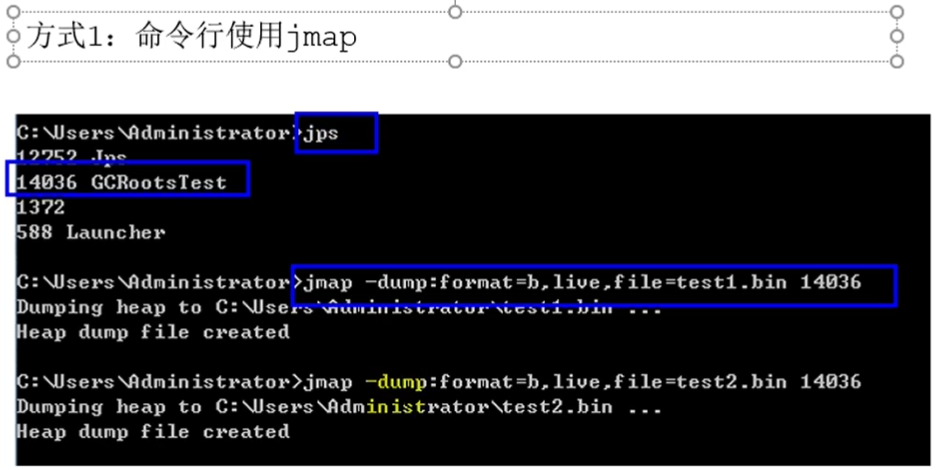
方式二:使用JVisualVM导出

参数
-XX:HeapDumpOnOutOfMemoryError
这个参数就是当我们出现OOM的时候回生成一个dump文件
dump文件可以通过MAT或者Jprofileer来查看,寻找问题
清除阶段
标记-清除
遍历两次,第一次标记存活,第二次清除垃圾(维护一个空闲列表,记录这些地址,下次有对象来直接来这个列表找,如果有足够空间直接覆盖【它是这样做的】)
标记:从根节点出发,标记可达的对象(非垃圾),记录在对象的对象头中
清除:遍历堆内所有的对象,如果该对象的对象头没有被标记则清除。
缺点:效率低,内存碎片严重
复制算法
优点:高效,内部连续(因为直接将存活的对象复制过去)
缺点:内存缩小一半,如果对象存活多的话,性能就很差了,因为全部要复制过去,而且原来栈中指向也要重新指向我复制的内存区域。
因此复制算法适用于朝生夕死较多的时候,如年轻代就很适合
标记-整理
执行过程:
第一阶段和标记-清除算法一样,从根节点开始标所有被引用的对象。
第二阶段:将所有存活的对象压缩到内存的一端,按顺序排放(解决了内存不连续),
然后将边界外所有空间清除
优点:内存连续
增量回收算法:
用户线程和GC线程切换执行,这样用户线程体验稍微好一些,因为不用完全STW,但是这样增加了CPU调度成本,系统吞吐量下降
分区算法:
将堆区划分一小块一小块独立的内存,进行GC的时候独立回收(这样我们限定回收时间,就会按照时间之内选择region进行回收)
内存溢出
堆空间不足以放下对象了,导致内存溢出
内存泄漏
对象我们不用了,但是通过可达性分析仍然能找到这些对象,导致虽然我们不用、用不到,但是无法回收,造成内存泄漏,内存泄漏累积过多就会产生内存溢出,从而报OOM

安全点

安全区域

四种引用
强引用
软引用
内存足够不回收,内存不够即回收
弱引用
gc发现就回收
虚引用
内部维护队列,回收的时候会找到这个队列,然后就能知道这个对象被回收了,也就是说追踪垃圾回收的过程
垃圾回收器

吞吐量:GC时间占比尽可能少
低延迟:用户线程被暂停的时间越短越好
二者是矛盾的,G1就是二者这种的方案,也就是规定最大暂停时间,在这个时间之内,吞吐量越大越好


垃圾回收期可组合的方式
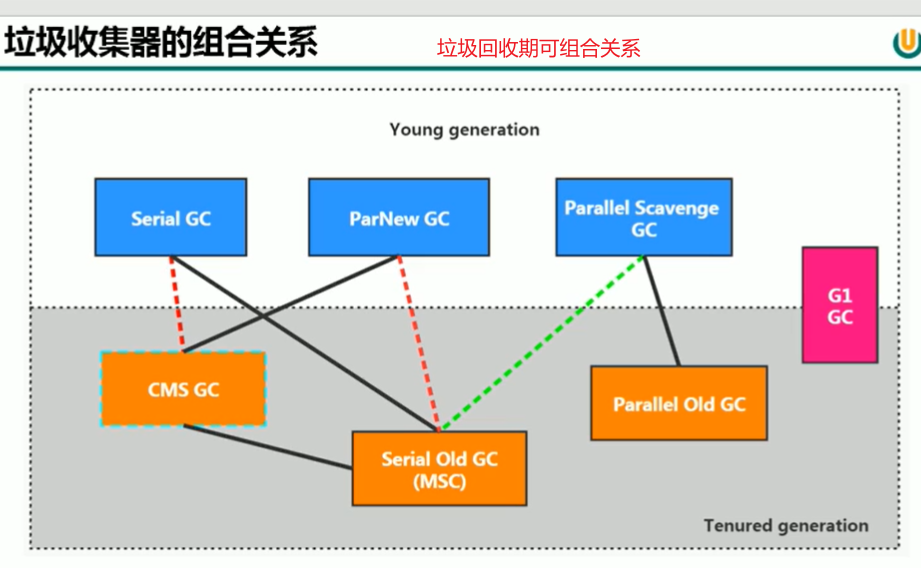
查看垃圾回收器
参数
-XX:+PrintCommandLineFlags
jdk1.8结果:-XX:InitialHeapSize=10485760 -XX:MaxHeapSize=10485760 -XX:+PrintCommandLineFlags -XX:+PrintGCDetails -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:-UseLargePagesIndividualAllocation -XX:+UseParallelGC
jdk1.9默认就是G1了
-XX:+PrintCommandLineFlags #查看目前使用的垃圾回收器
-XX:+UseSerialGC
-XX:+UseParNewGC
以下二者互相激活,即激活一个另一个自动激活
-XX:+UseParallelGC 新生代使用
-XX:+UseParallelOldGC 老年代使用
-XX:+UserAdaptiveSizePolicy 自适应调节策略(堆空间自适应调整,尽量使用程序高吞吐,性能优一点)
-XX:ParallelGCThreads 设置年轻代并行收集器的线程数
CMS【老年代使用】
初始标记:寻找GC Roots,是STW的
并发标记:顺着这些GC Roots寻找对象,是并发的与用户线程一起执行
重新标记:对已经标记对象进行修正,移除掉不使用的对象,在并发标记阶段分不清到底是不是垃圾在这里进行了修正(因为这些是与用户线程一起并发标记的嘛),是STW的
并发清除:删除掉标记阶段判断已经死亡的对象,释放内存,因为是标记清理,存活的对象不用移动,因此与用户线程并发的执行
缺点:
-
产生内存碎片
-
对CPU资源很敏感
-
无法处理浮动垃圾
无法清除浮动垃圾:在并发阶段如果用户线程让一些对象变成垃圾了,本次CMS操作无法感知了,只能下一次CMS才能知道,这些垃圾就叫做浮动垃圾。
因为CMS与用户并发执行,因此不能等待内存快不足的时候再回收,否则OOM风险就很高,为了解决CMS过程中OOM,从而无法使用,CMS有一个备选方案,此时使用SerialOld垃圾回收期,STW单线程的回收。
正是由于CMS这些缺点,CMS在jdk14后被jvm彻底移除
参数设置
-XX:+UserConcMarkSweepGC 开启该参数后就会自动将-XX:UserParNewGC打开。
这个就不写那么多了,因为G1完全是目前的主流垃圾回收期,此CMS后期也被移除了,因此了解一下即可。。。
G1【年轻代与老年代通用】
Garbage first(垃圾优先)
分代回收 jdk9之后默认的垃圾回收器
参数设置
-XX:UseG1GC #显示开启G1

特点



G1是为了简化jvm的调优的,只要设置如下三个参数,jvm就可以自动调优:
- 开启G1: -XX:UseG1GC
- 设置堆的大小:-Xms -Xmx
- 设置期望达到GC最大停顿时间:-XX:MaxGCPauseMillis
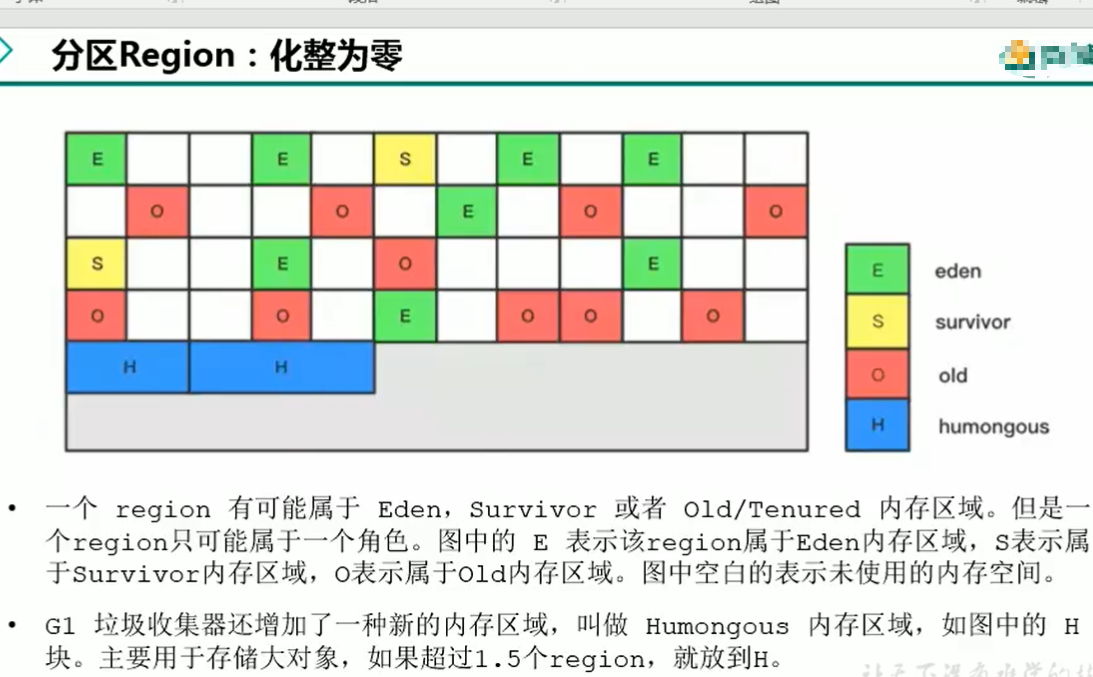
Region是一块一块的,大小相同的,物理空间可以不连续的(一块region可以在某一时刻是Eden块,也可以是Survivor块的,也可以是Old块的,就是一个region被清空放入空闲列表中后,它是可以切换角色的)

G1回收过程
每一个region是复制算法,但整体上看又是标记-整理算法

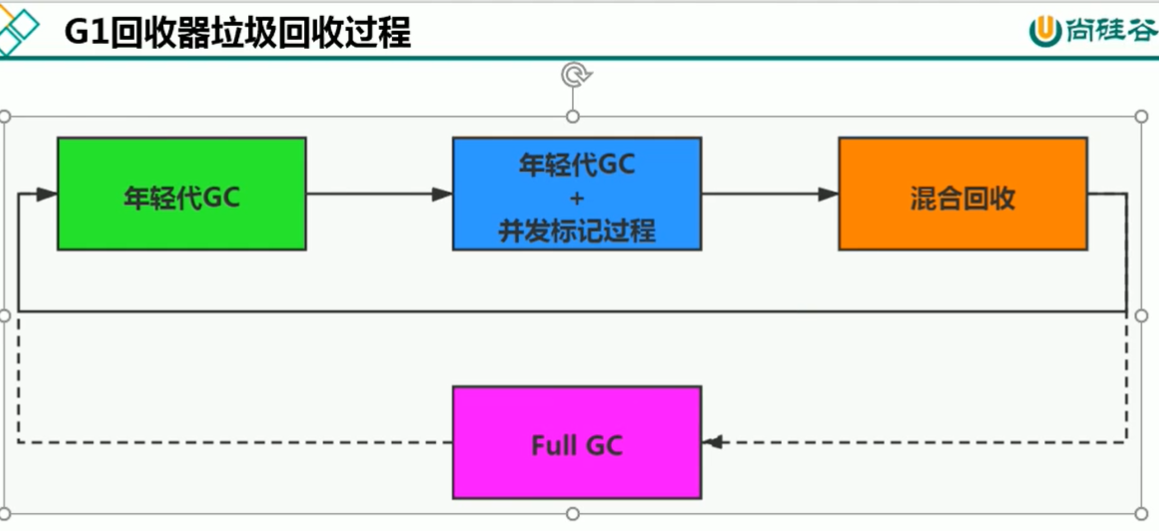

R SET让本region记录一下里面的对象哪些被其他区域引用了,如果有则不回收,如果没有则回收,这样就不用遍历整个堆来确保我这个对象是否可以被回收了,用空间换取了时间
年轻代GC

并发标记

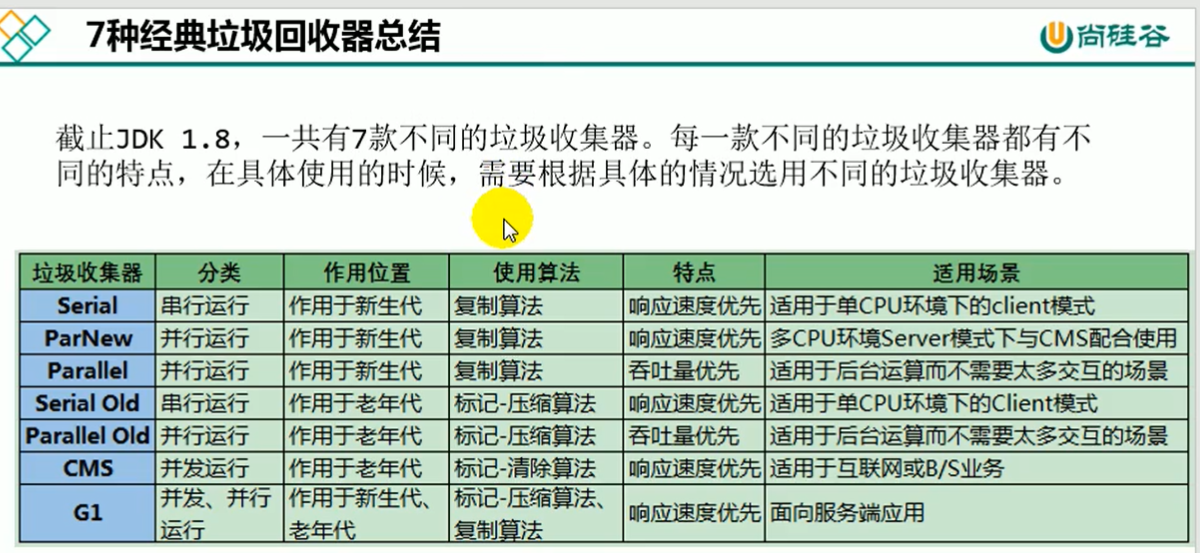
垃圾回收器总结
GC日志分析(-XX:+PrintGCDetails)
参数
-XX:+PrintCommandLineFlags -XX:+UseG1GC -XX:+UseParallelGC(默认) -XX:+PrintGCDetails
查看当前垃圾回收期及基本情况 使用G1垃圾回收器 使用Parallel回收器(jkd8默认) 打印GC详细日志
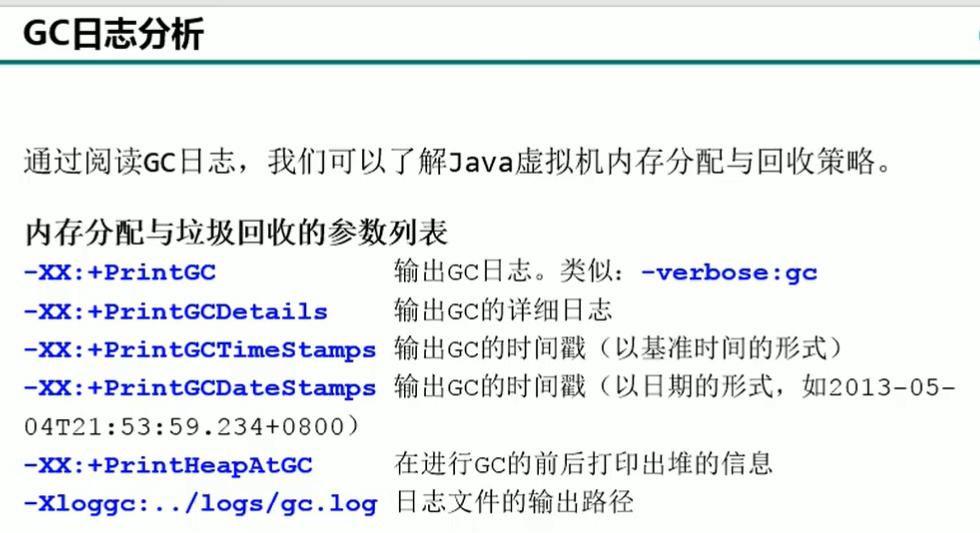
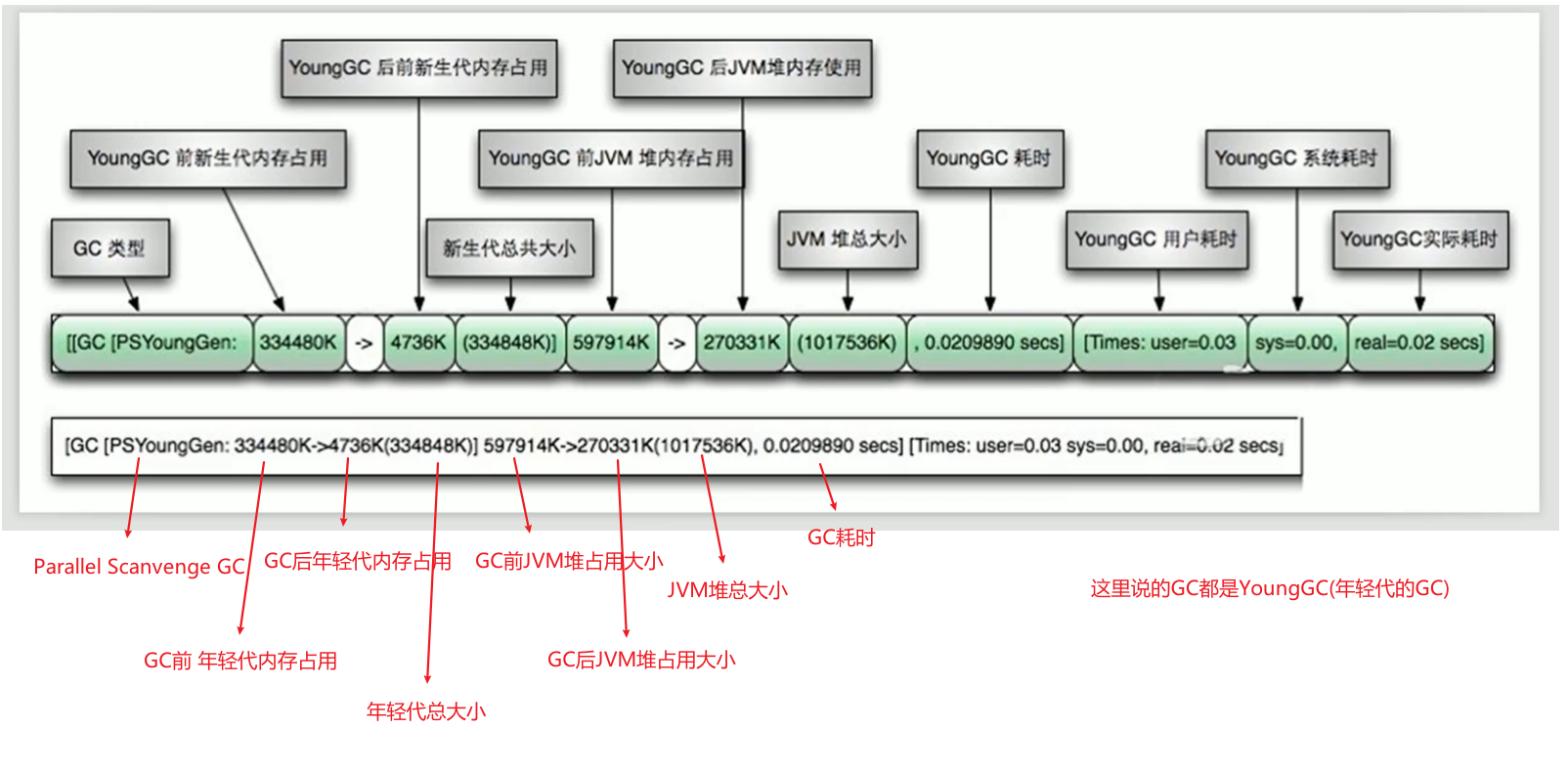
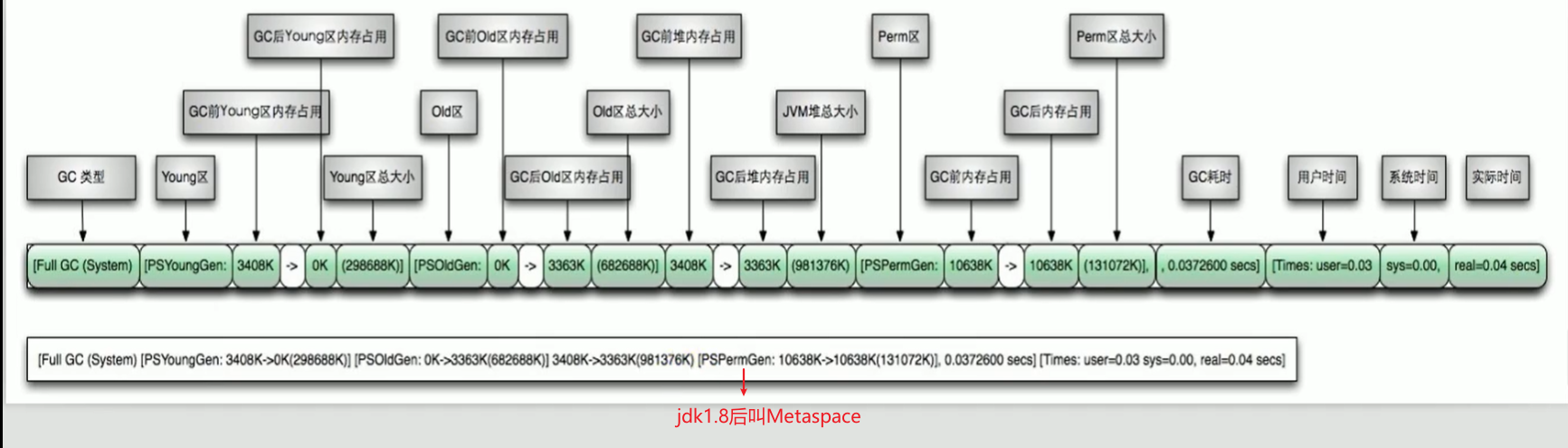
-Xms10m -Xmx10m -XX:+PrintGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -Xloggc:./logs/gc.log
将GC日志记录下来:-Xloggc:./logs/gc.log,其中./指的是在当前工程下,必须文件夹存在才可以,否则不会自动创建,会报警告:
Java HotSpot(TM) 64-Bit Server VM warning: Cannot open file ./logs/gc.log due to No such file or directory
日志分析
GCViewer 【git hub上下载】
GC Easy https://gceasy.io/
通过 -Xloggc:./logs/gc.log将gc日志输出,然后将文件导入进去,进行分析
自定义类加载器
loadClass #上方是实现类的双亲委派机制
findClass #实现自定义的加载
建议我们重新findClass,保留双亲委派机制
自定义类加载器
package com.jd.classloader;
import java.io.*;
/**
* @author ningxinjie
* @date 2021/1/9
*/
public class CustomClassLoader extends ClassLoader {
private String byteCodePath;
public CustomClassLoader(String byteCodePath) {
this.byteCodePath = byteCodePath;
}
public CustomClassLoader(ClassLoader parentClassLoader, String byteCodePath) {
super(parentClassLoader);
this.byteCodePath = byteCodePath;
}
@Override
protected Class<?> findClass(String className) throws ClassNotFoundException {
// 获取字节码文件的完整路径
String fileName = byteCodePath + className +".class";
BufferedInputStream bin = null;
ByteArrayOutputStream barrout = null;
try {
// 获取输入流
bin = new BufferedInputStream(new FileInputStream(fileName));
// 获取输出流
barrout = new ByteArrayOutputStream();
// 具体读入数据并写出的过程
int len;
byte[] data = new byte[1024];
while ((len = bin.read(data)) != -1){
barrout.write(data,0,len);
}
// 获取内存中完整的字节数组的数据
byte[] byteCodes =barrout.toByteArray();
// 调用defineClass将自己数组的数据转换为Class的实例
Class<?> clazz = defineClass(null, byteCodes, 0, byteCodes.length);
return clazz;
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
if(barrout != null)
barrout.close();
if(bin != null)
bin.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return null;
}
}
测试类
package com.jd.classloader;
/**
* @author ningxinjie
* @date 2021/1/9
*
* javac HotClassTest.java 编译
*/
public class HotClassTest {
public void print(){
System.out.println("HotClassTest -- new");
}
}
编译成字节码
打开终端
D:\ningxinjie\code\AnyTest\src\main\java\com\jd\classloader> javac HotClassTest.java #在当前目录下
测试
package com.jd.classloader;
import java.lang.reflect.InvocationTargetException;
import java.lang.reflect.Method;
/**
* @author ningxinjie
* @date 2021/1/9
*/
public class CustomClassLoaderTest {
public static void main(String[] args) throws ClassNotFoundException, IllegalAccessException, InstantiationException, NoSuchMethodException, InvocationTargetException, InterruptedException {
//此时的while (true) 仅仅是为了不停地读取字节码,这样我在运行期间修改了测试类,重新编译下,就能热加载了
while (true){
CustomClassLoader loader = new CustomClassLoader("D:/ningxinjie/code/AnyTest/src/main/java/com/jd/classloader/");
Class<?> clazz = loader.loadClass("HotClassTest");
System.out.println("加载此类的类的加载器为" + clazz.getClassLoader().getClass().getName());
Object o = clazz.newInstance();
Method print = clazz.getMethod("print");
print.invoke(o);
Thread.sleep(3000);
}
}
}

