
深度学习之开端备注







Adagrad //适合稀疏样本
RMSprop//借鉴Adagrad的思想,改进使得不会出现学习率越来越低的问题


由此可见Adadelta既不需要输入学习率等参数,而且表现得非常好!!但是我试了几次,这个优化器效果极差!!还是具体问题具体分析吧
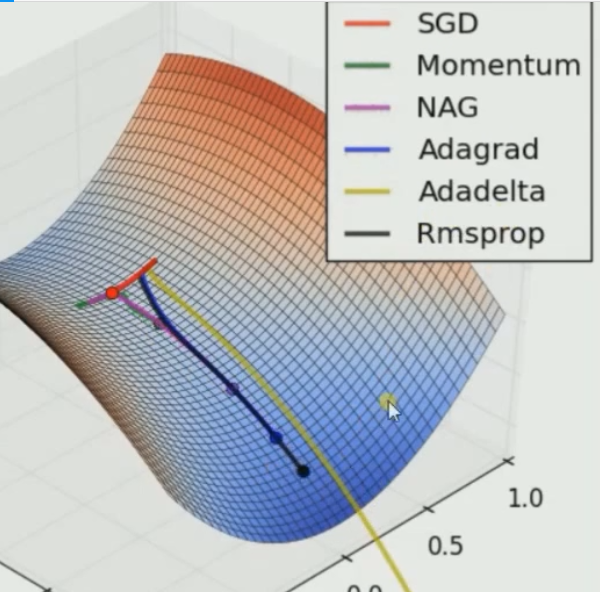 由此可见只有SGD无法逃离局部最小值,此处仍然是Adadelta速度最快
由此可见只有SGD无法逃离局部最小值,此处仍然是Adadelta速度最快
但是我们并不能因此不使用SGD,因为评价一个训练器的好坏不是靠速度,而是靠最终的准确率!
最好的训练器是在训练速度适中的情况下,准确率最高的!吴推荐Adam,具体是什么得因问题而定!
还是使用Adam吧!这个训练器很强!

