
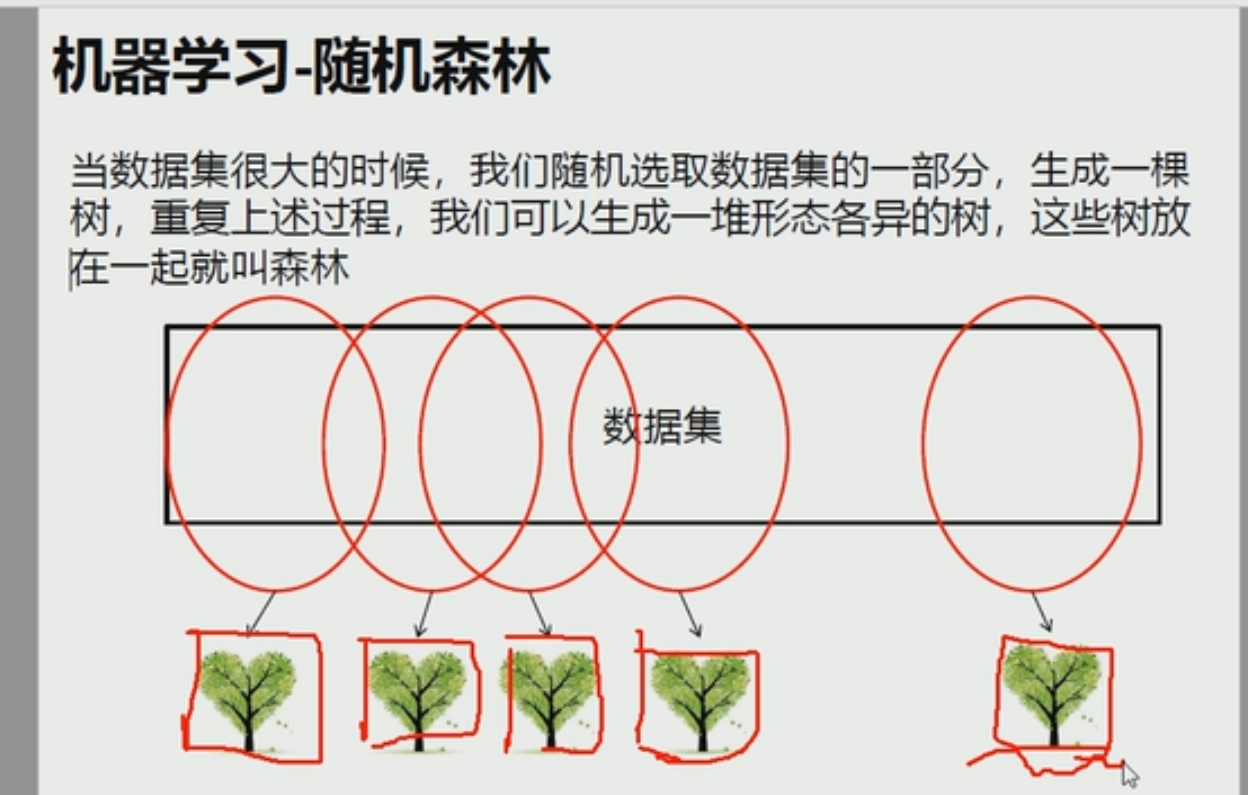
随机森林开始
随机森林 是并行的思想(集体智慧)
大大减少了单机的运算量和有效的排除了异常值对我们决策的影响

决策树
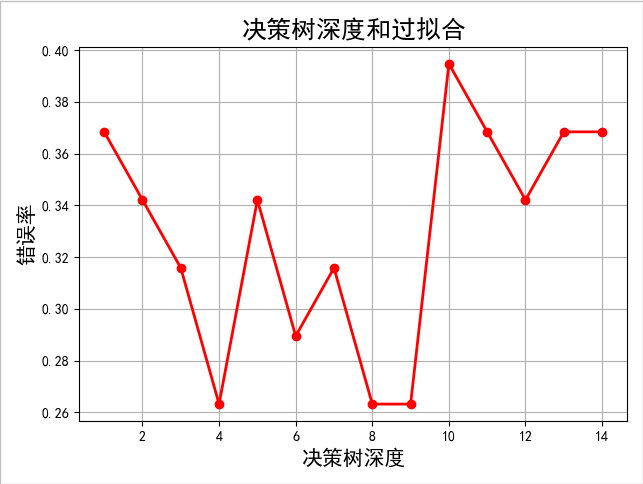
import numpy as np import pandas as pd from sklearn.datasets import load_iris from sklearn.tree import DecisionTreeClassifier #决策树类别 from sklearn.tree import export_graphviz from sklearn.tree import DecisionTreeRegressor #决策树做回归 from sklearn.model_selection import train_test_split #切分训练集和测试集的比例~~ from sklearn.metrics import accuracy_score #metrics指标 accuracy_score评估准确率 import matplotlib.pyplot as plt import matplotlib as mpl iris=load_iris() print(list(iris.keys())) print(iris["feature_names"]) data=pd.DataFrame(iris["data"])#将数据转成pandas的数据集 data["Species"]=iris.target #增加一列 # print(data) x=data.iloc[:,:2] #花萼的长度 和 宽度 y=data.iloc[:,-1] #最后一列Species种类 》》就是0 1 2 #把原有数据集切成两部分 #train_size=0.75 》75%训练集 25%测试集 #random_state写死每次运行切割数据都是一样的,不写死的话系统会每次随机赋值,》》就会使得每次的数据内容是不一样的 x_train,x_test,y_train,y_test=train_test_split(x,y,train_size=0.75,random_state=42) #max_depth=2限制数的深度只有2层 #分割的标准 tree_clf=DecisionTreeClassifier(max_depth=8,criterion='entropy') tree_clf.fit(x_train,y_train) y_test_hat=tree_clf.predict(x_test) # print(y_test_hat) #评估准确度,正例就对,负例纠错,得出浮点数 *100就是百分比 print("acc score:",accuracy_score(y_test,y_test_hat)) print(tree_clf.predict_proba([[5,1],[1,1.5]]))#[[0. 1. 0.],[1. 0. 0.]] 说明[5,1]属于1类型 [1,1.5]属于0类别 print(tree_clf.predict([[5,1],[1,1.5]]))#[1 0] #决策树类别的max_depth参数每次都是自己手动调节参数太麻烦,我们让代码自动实现 depth=np.arange(1,15) err_list=[] for d in depth: clf=DecisionTreeClassifier(max_depth=d,criterion='entropy') clf.fit(x_train,y_train) y_test_hat=clf.predict(x_test) result=(y_test_hat==y_test) # if d==1: # print(result) # print(np.mean(result))#True为1 False为0 err=1-np.mean(result) # print(err*100) err_list.append(err) # print(d,"错误率:%.2f%%"%(err*100)) mpl.rcParams['font.sans-serif']=['SimHei']#把字体设置为黑体 plt.figure(facecolor='w')#图的底色是白色. plt.plot(depth,err_list,'ro-',lw=2)#横坐标,纵坐标,'ro-'(红色,每个点画成o用-连接),lw线宽 plt.xlabel('决策树深度',fontsize=15) plt.ylabel('错误率',fontsize=15) plt.title('决策树深度和过拟合',fontsize=18) plt.grid(True) plt.show()
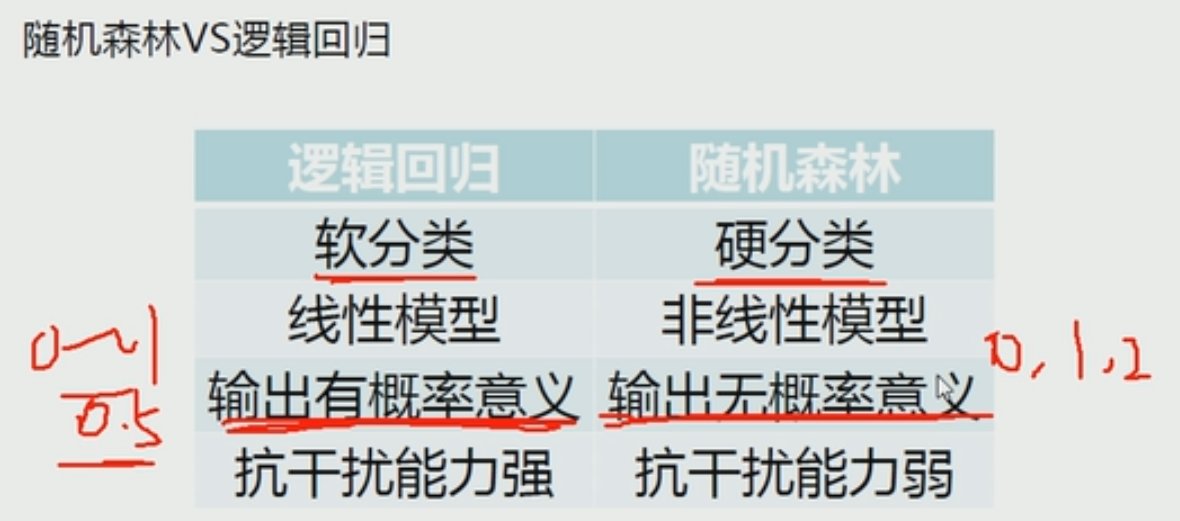
随机森林
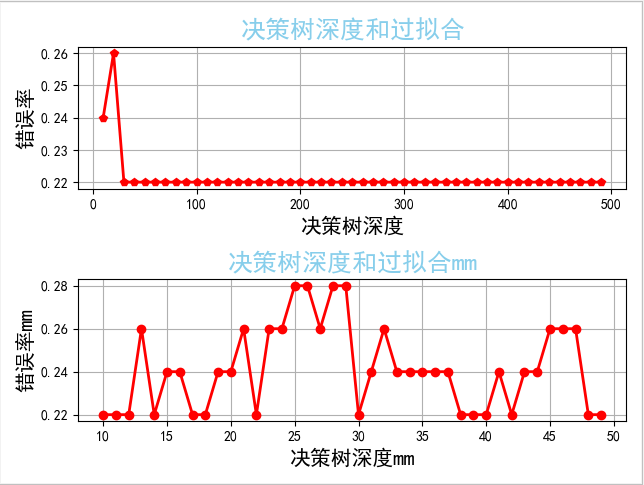
from sklearn.ensemble import RandomForestClassifier#随机森林 from sklearn.model_selection import train_test_split#分隔的方式 from sklearn.ensemble import BaggingClassifier #装袋分类器 from sklearn.tree import DecisionTreeClassifier#决策树 from sklearn.metrics import accuracy_score#metrics指标 accuracy_score评估准确率 from sklearn.datasets import load_iris import numpy as np import matplotlib as mlt import matplotlib.pyplot as plt iris=load_iris() print(list(iris.keys())) print(iris["feature_names"]) x=iris["data"][:,:2]#花萼的长度和宽度 y=iris["target"] x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.33,random_state=42) #n_estimators=500用500颗小决策树构成森林 max_leaf_nodes最大叶节点数 n_jobs用几个线程 rnd_clf=RandomForestClassifier(n_estimators=100,max_leaf_nodes=16,n_jobs=1) rnd_clf.fit(x_train,y_train) #这个 #max_samples=1.0 训练整个样本(是来随机样本的比例) #splitter="random"每个小树取出所有样本但是使用随机的维度,主要在于随机维度,而不在于随机样本数 bag_clf=BaggingClassifier( DecisionTreeClassifier(splitter="random",max_leaf_nodes=16), n_estimators=100,max_samples=1.0,bootstrap=True,n_jobs=1 ) bag_clf.fit(x_train,y_train) y_pred_bg=bag_clf.predict(x_test) print(accuracy_score(y_test,y_pred_bg)) y_pred_tf=rnd_clf.predict(x_test) print(accuracy_score(y_test,y_pred_tf)) count=np.arange(10,500,10) err_list=[] n_estimators_list=[] for i in count: t_rnd_clf=RandomForestClassifier(n_estimators=i,max_leaf_nodes=16,n_jobs=1) t_rnd_clf.fit(x_train,y_train) y_pred_tf=t_rnd_clf.predict(x_test) err_list.append(1-accuracy_score(y_test,y_pred_tf)) n_estimators_list.append(i) #找出错误率最低的小决策树数量 minnum=err_list[0]#初始化 for i in err_list: if i<minnum: minnum=i minindex=err_list.index(minnum) minerroCount=n_estimators_list[minindex] countR=np.arange(10,50) err_listR=[] for i in countR: t_rnd_clfR=RandomForestClassifier(n_estimators=minerroCount,max_leaf_nodes=i,n_jobs=1) t_rnd_clfR.fit(x_train,y_train) y_pred_tf=t_rnd_clfR.predict(x_test) err_listR.append(1-accuracy_score(y_test,y_pred_tf)) mlt.rcParams['font.sans-serif']=['SimHei']#把字体设置为黑体 fig=plt.figure(facecolor='w')#图的底色是白色. ax1=fig.add_subplot(2,1,1) ax1.plot(count,err_list,'rp-',lw=2)#横坐标,纵坐标,'ro-'(红色,每个点画成o用-连接),lw线宽 plt.title('决策树深度和过拟合',fontsize=18,c='skyblue') plt.xlabel('决策树深度',fontsize=15) plt.ylabel('错误率',fontsize=15) plt.grid(True) ax2=fig.add_subplot(2,1,2) ax2.plot(countR,err_listR,'ro-',lw=2) plt.title('决策树深度和过拟合mm',fontsize=18,c='skyblue') plt.xlabel('决策树深度mm',fontsize=15) plt.ylabel('错误率mm',fontsize=15) # ax1.title('决策树深度和过拟合',fontsize=18) # ax1.grid(True) plt.grid(True) plt.show() #Feature Importance iris=load_iris() #n_jobs=-1不限制线程数,有几线程就用几个线程 rnd_clf=RandomForestClassifier(n_estimators=500,n_jobs=-1) rnd_clf.fit(iris["data"],iris["target"]) #feature_importances_随机森林和决策树的副产品,可以做特征的提取 #就是fit(x,y) x的每个维度和y的相关度 for name,score in zip(iris["feature_names"],rnd_clf.feature_importances_): print(name,score) #上方输出结果 # sepal length (cm) 0.10375860847964496 # sepal width (cm) 0.024341448023000867 # petal length (cm) 0.4439466177026777 # petal width (cm) 0.42795332579467654
决策树回归
from sklearn.tree import DecisionTreeRegressor#决策树回归 import numpy as np import matplotlib.pyplot as plt n=100 x=np.random.rand(n)*4-1 x.sort() y=np.sin(x)+np.random.rand(n)*0.05 # print(y) x=x.reshape(-1,1)#变成2维 每个列表只有一个列向量,行自适应,每个只有一列 # print(x) dt_reg=DecisionTreeRegressor(criterion="mse",max_depth=3) dt_reg.fit(x,y) x_test=np.linspace(-3,3,50).reshape(-1,1)#-3~3 平均分成50个数,然后一个列只有一列 # print(x_test) y_hat=dt_reg.predict(x_test) # print(y_hat) ''' plt.plot(x,y,'m*',label="actual") plt.plot(x_test,y_hat,'r-',lw=2,label='predict') # print(help(plt.legend)) plt.legend(loc="best") plt.grid() plt.show() ''' depth=[2,4,6,8,10] color="ygbym" x_test=np.linspace(-3,3,50).reshape(-1,1) plt.plot(x,y,'r*',label="actual") for d,c in zip(depth,color): dt_reg=DecisionTreeRegressor(criterion="mse",max_depth=d) dt_reg.fit(x,y) y_hat=dt_reg.predict(x_test) plt.plot(x_test,y_hat,'-',color=c,lw=2,label='depth=%d'%d) plt.legend(loc="best") plt.grid(b=True) plt.show()


