Beautiful Soup[解析HTML页面、信息标记与提取方法] 》》》实战_中国大学排名爬虫
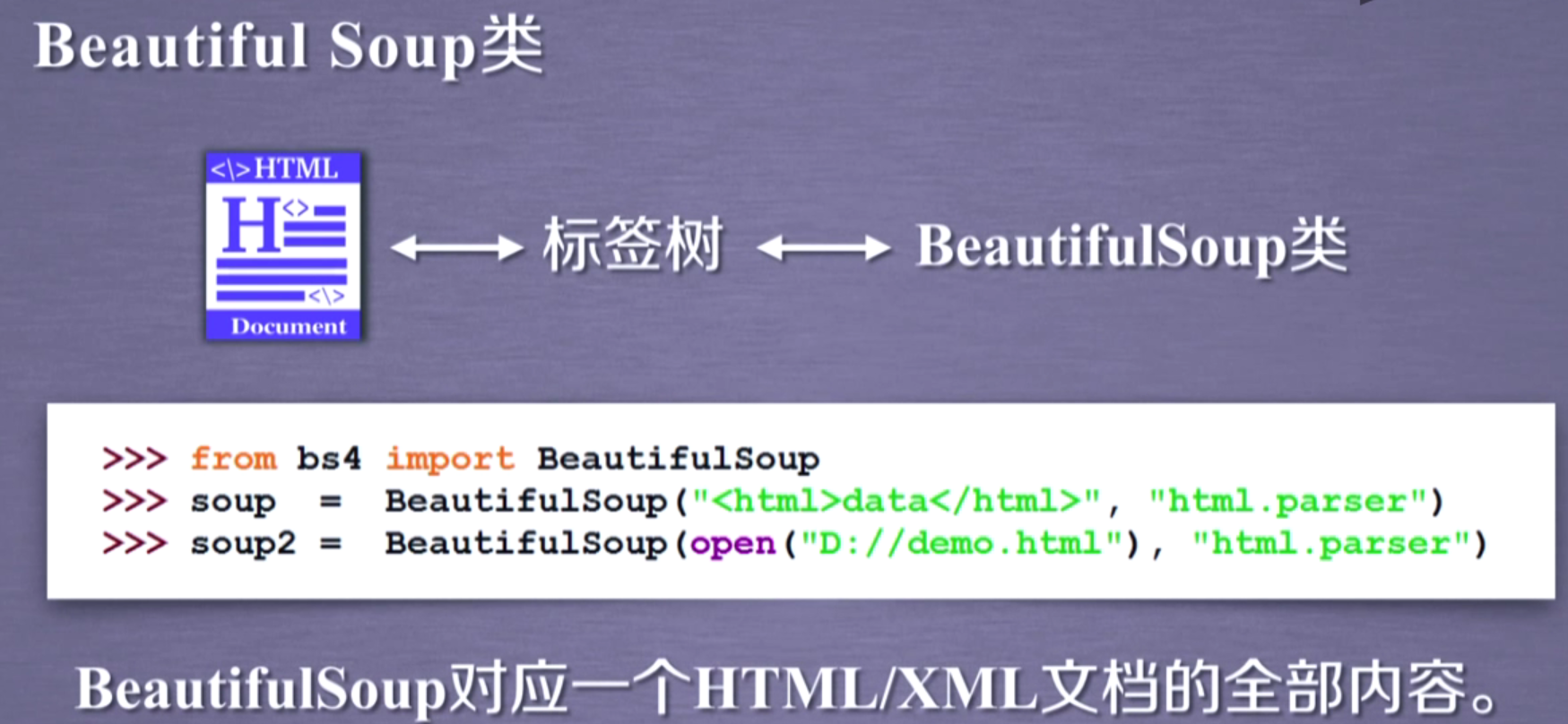
Beautiful Soup库是解析HTML和XML文件的库
引入方法

导入模块使用语句
from bs4 import BeautifulSoup
下方返回的HTML文本就是通过requests获得的网页HTML文本,将它解析成HTML
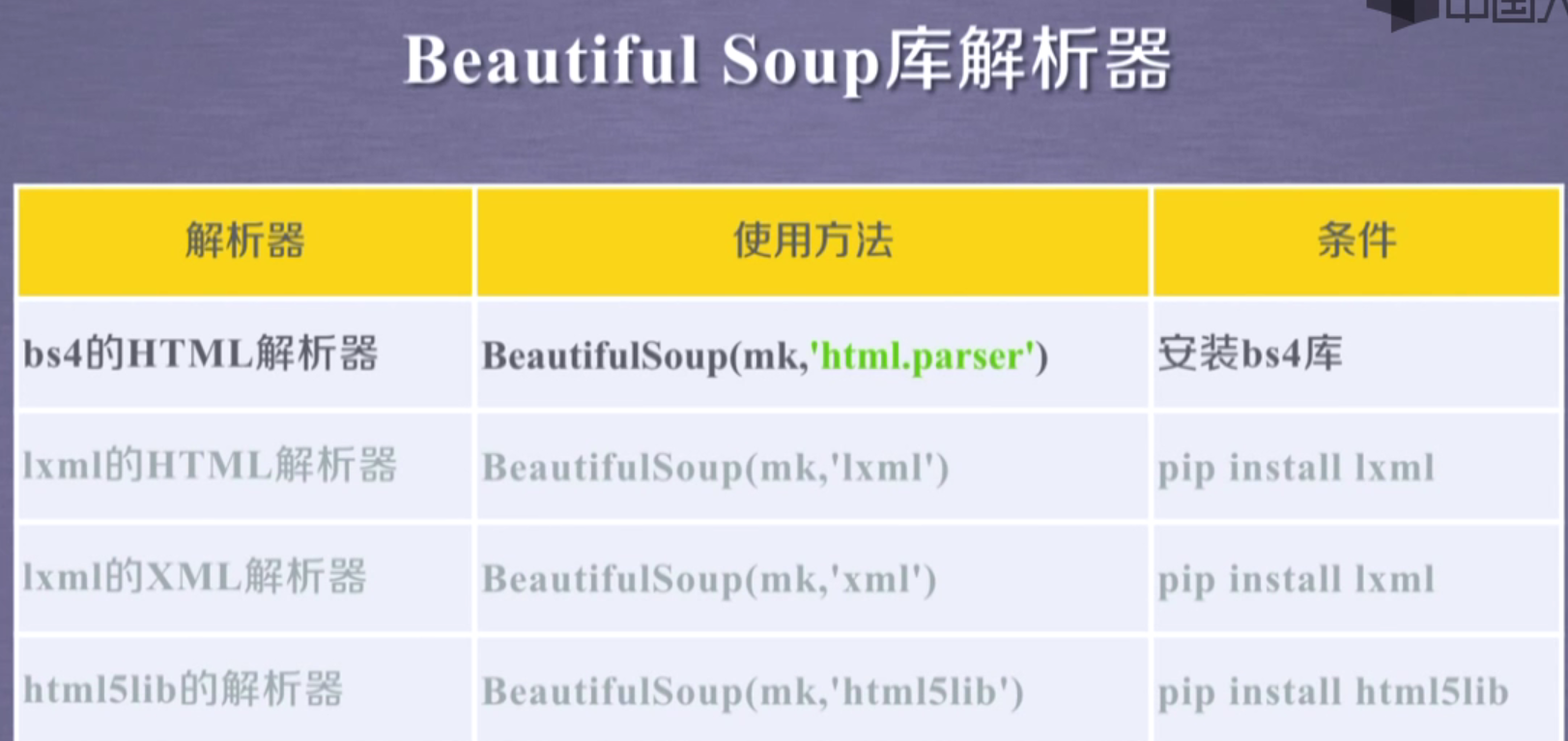
html.parser是解析html的解析器

print(soup.prettify())
就可以和HTML布局一样打印出来

可以看成Beautiful Soup将HTML转换成Beautiful Soup类,然后对这些标签树进行操作

基本元素

bs获得元素节点【和HTML操作类似】
获得的是满足的第一个匹配!!!!,这点还是没有lxm下的etree使用xpath好呀
但是有select方法适合etree使用xpath一样而且它使用的是CSS选择器,很方便!,如下访问音乐名
import requests from bs4 import BeautifulSoup import time # 请求头 headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/' '537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36' } # 定义函数get_info() def get_info(url): # 请求网业 wb_data = requests.get(url, headers=headers) # 解析网业 soup = BeautifulSoup(wb_data.text, 'lxml') # 定位元素并通过selector方法提取 ranks = soup.select('span.pc_temp_num ') titles = soup.select('div.pc_temp_songlist > ul > li > a') times = soup.select(' span.pc_temp_num ') # 循环遍历 for rank, title, time, in zip(ranks, titles, times): data = { 'rank': rank.get_text().strip(), 'singer': title.get_text().split('-')[0], 'song': title.get_text().split('-')[1], 'time': time.get_text().strip() } print(data) if __name__ == '__main__': urls = ['https://www.kugou.com/yy/rank/home/{}-8888.html?from=rank'.format(i) for i in range(1, 24)] # for i in urls: # print(i) for url in urls: get_info(url) time.sleep(1)

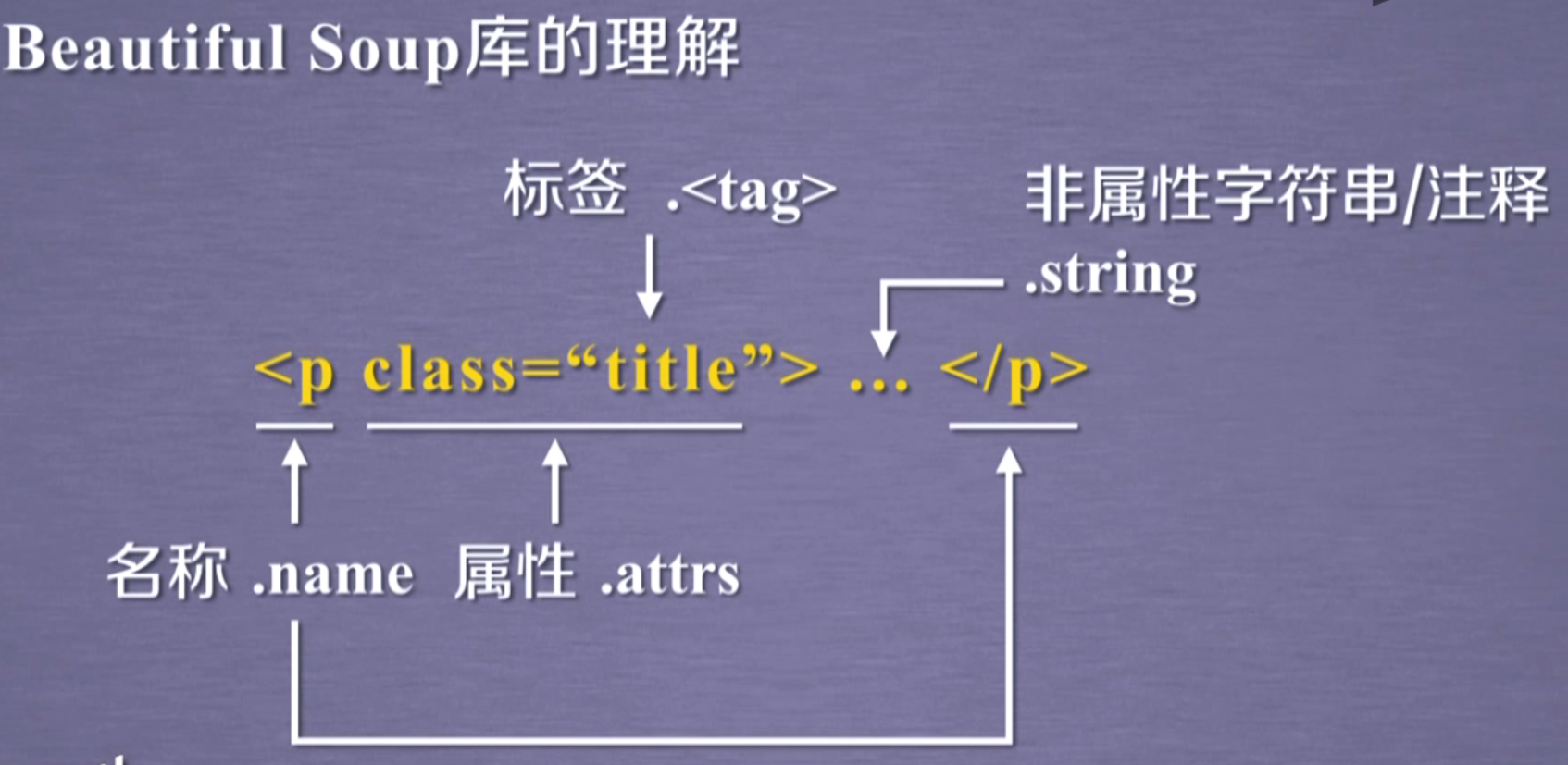
获得标签属性信息

获得标签内的文本
.string

注释内容


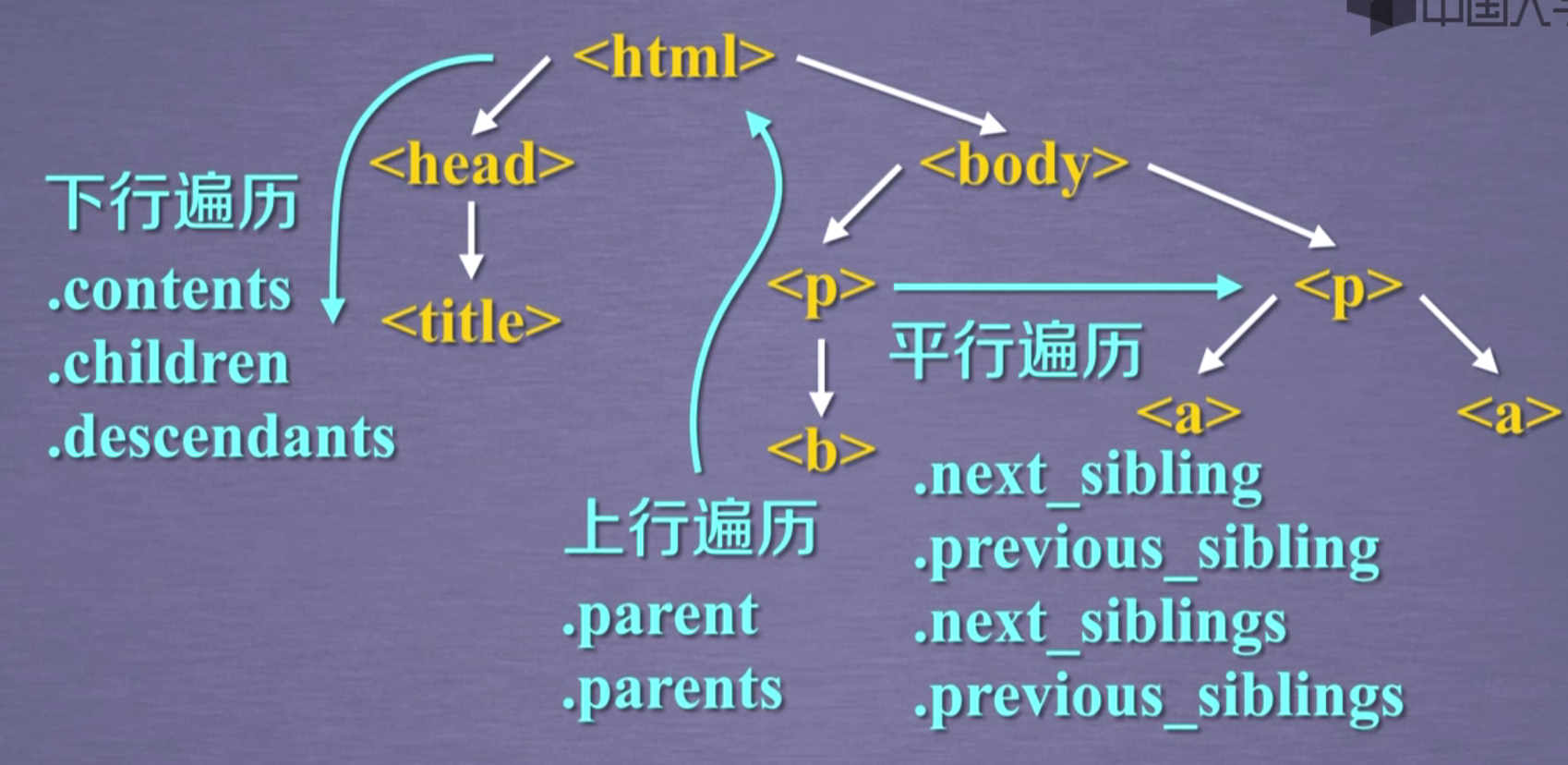
下行遍历
返回列表,除了包括元素节点也包括文本节点
 》》》
》》》 
上行遍历


平行遍历


平行遍历可能获得的是string类型