
一只想成长的爬虫——RObots协议~~ 爬取实例!!!~~~~~
京东的rotobs协议,网址:
User-agent: * #任何爬虫的来源都应该遵守如下协议额 Disallow: /?* #不允许爬取以?开头的路径 Disallow: /pop/*.html #不允许访问/pop/....html的页面 Disallow: /pinpai/*.html?* #不允许访问 /pinpai/....html?...
接下来的4个爬虫禁止访问京东的任何资源(被认为是恶意爬虫) User-agent: EtaoSpider Disallow: / User-agent: HuihuiSpider Disallow: / User-agent: GwdangSpider Disallow: / User-agent: WochachaSpider Disallow: /


Robots协议的遵守方式~~~~
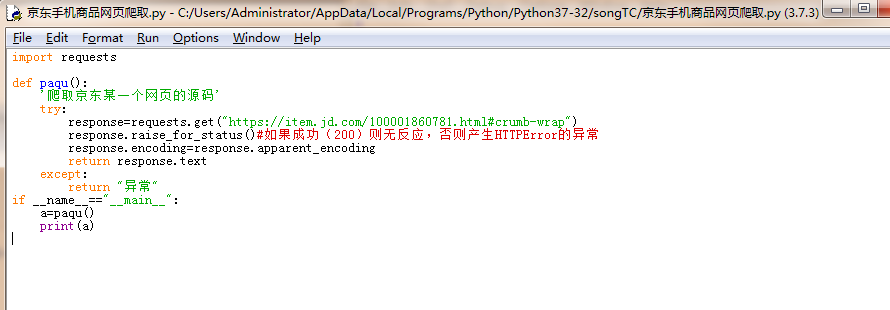
1.京东商品页面的爬取
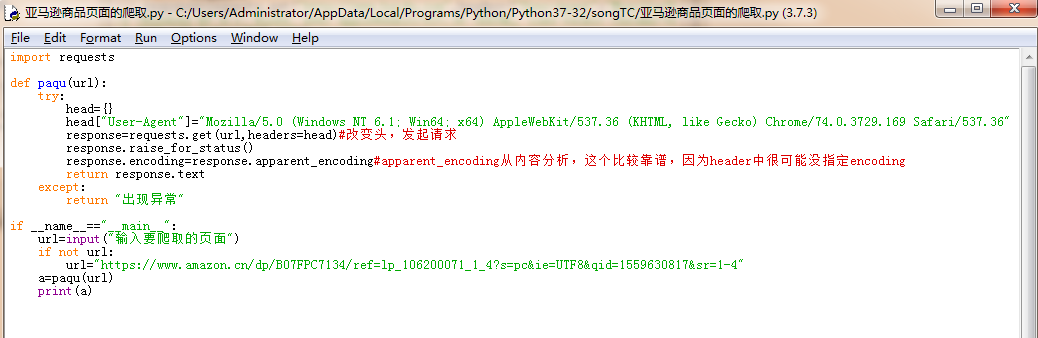
2.亚马逊商品页面的爬取【改变头部User-Agent为浏览器(伪装自己)】
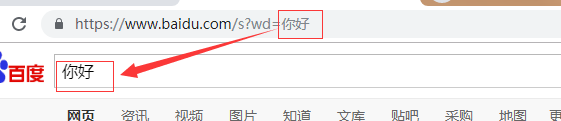
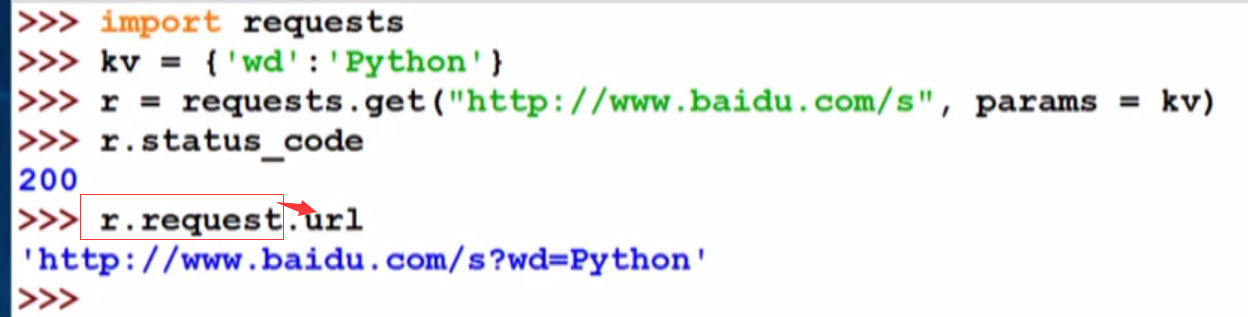
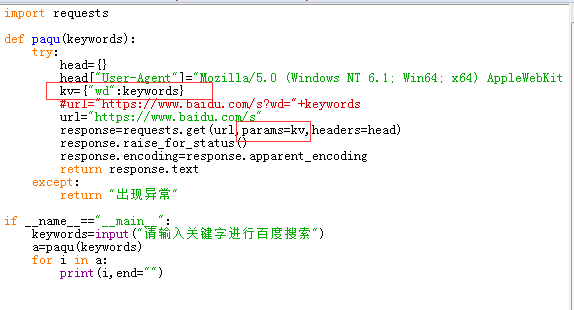
3.百度360搜索关键词提交

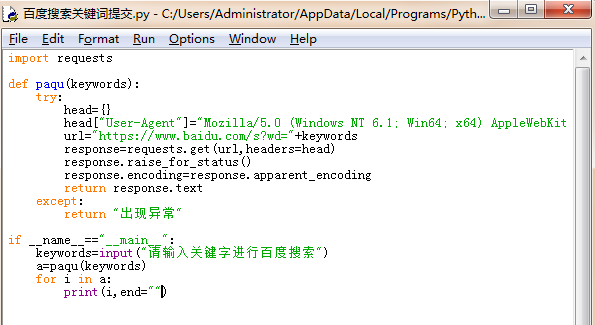
直接使用params
4.网络图片的爬取和存储[这个只是一张图片的]
附上自己按照小甲鱼方法写的爬取地理网图片,无限刷!!!
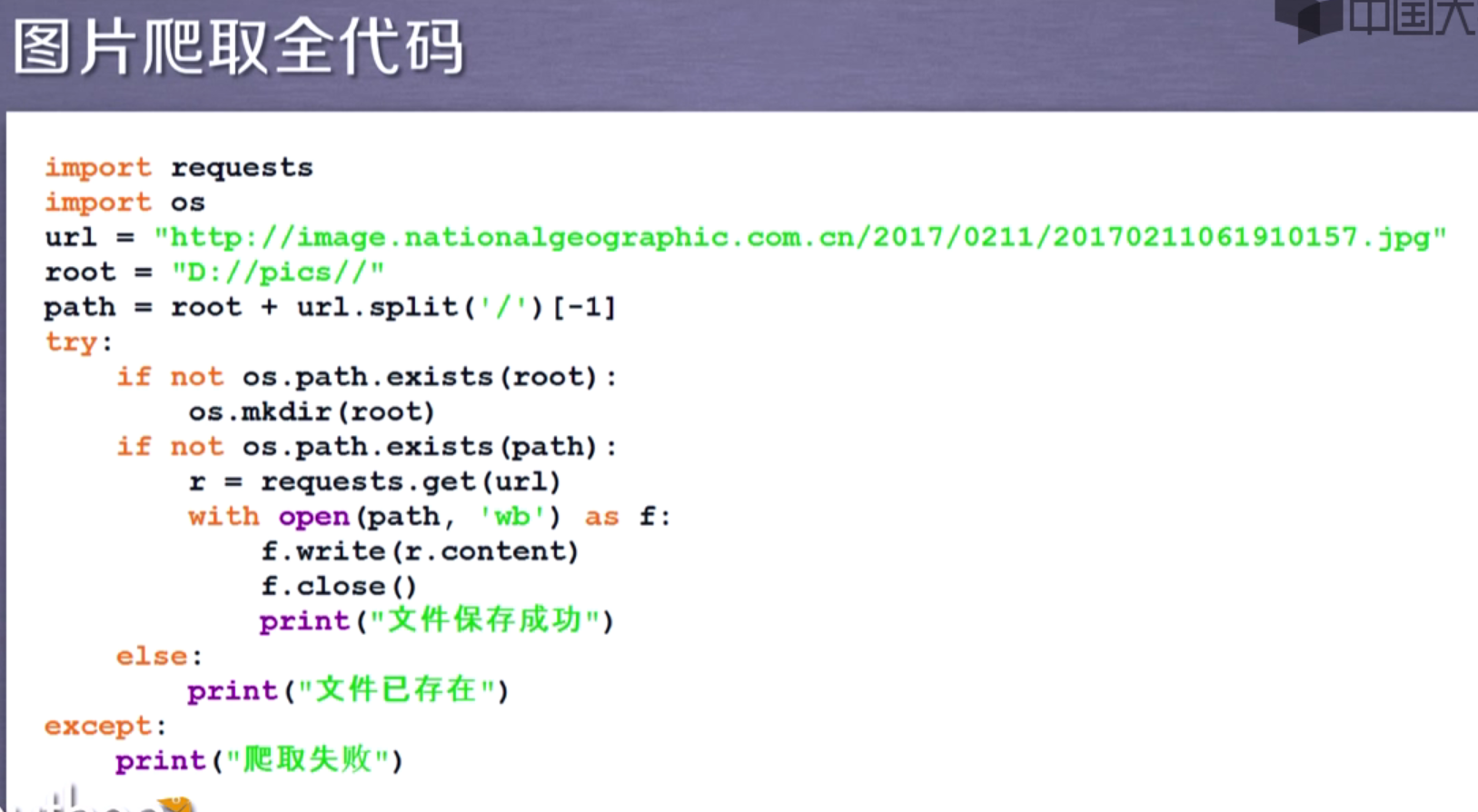
直接可用!!!
import urllib.request import os def url_oprn(url): rq=urllib.request.Request(url) rq.add_header=("User-Agent","Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36") response=urllib.request.urlopen(rq) html=response.read() return html def find_img(page_url): imglist=[] html=url_oprn(page_url).decode('utf-8') a=html.find("img src=") while a!=-1: b=html.find(".jpg",a,a+255) if b!=-1: imglist.append(html[a+9:b+9]) else: b=a+9 a=html.find("img src=",b) return imglist def save(img_addrs): for each in img_addrs: filename=each.split("/")[-1].split("@")[0] #print(filename) try: with open(filename,'wb') as f: img=url_oprn(each) f.write(img) except: continue def download_img(path="G:\\PY\\imgs",page=5): ok=True a=0 while ok: a+=1 path=path+str(a) if not os.path.exists(path): ok=False os.mkdir(path) os.chdir(path) url="http://www.dili360.com/cng/pic/" page_num=2019 for i in range(page): page_url=url+str(page_num)+'.htm' img_addrs=find_img(page_url) save(img_addrs) page_num-=1 if __name__=="__main__": download_img()
5.IP地址归属地的自动查询
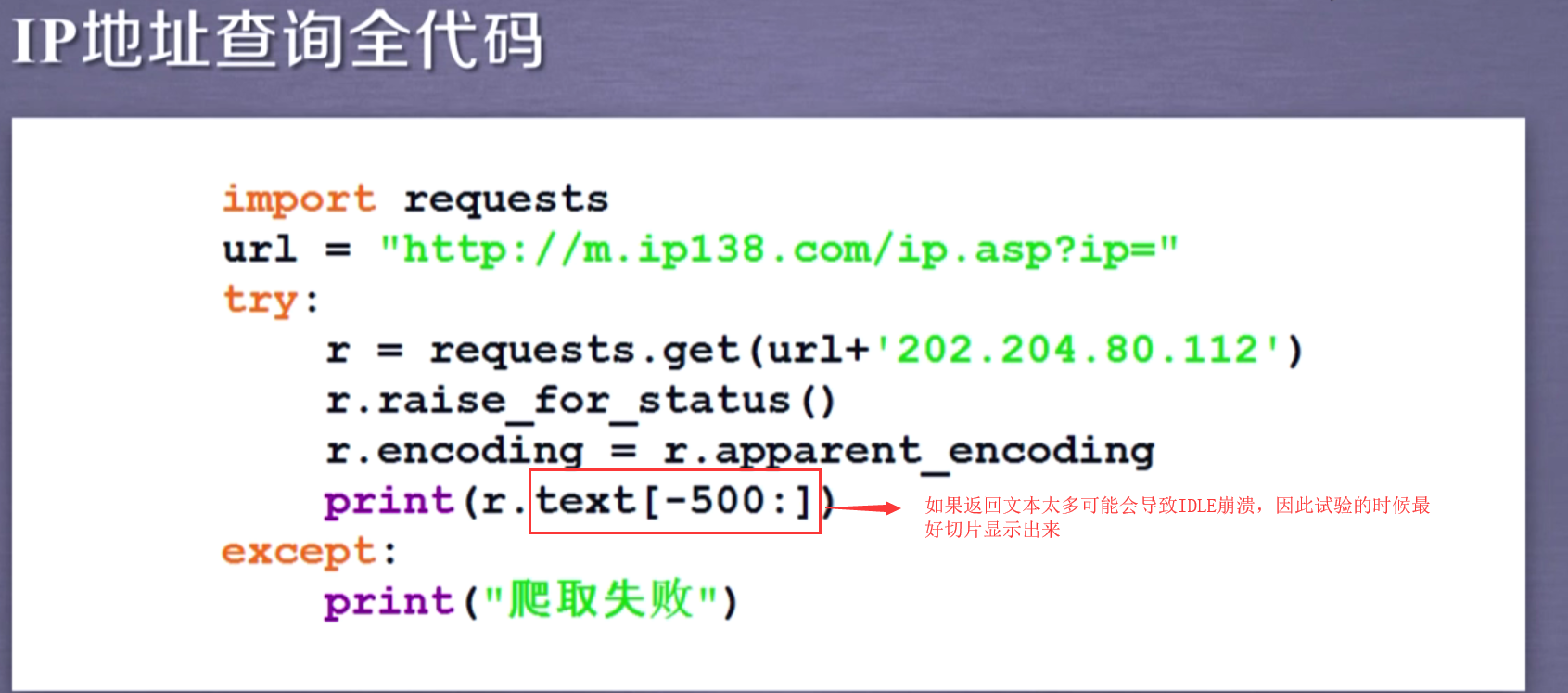
import requests from lxml import etree url="http://www.ip138.com/ips138.asp?ip=" ip=input("请输入查询ip") if not ip: ip="192.168.1.22" try: response=requests.get(url+ip) response.raise_for_status() response.encoding=response.apparent_encoding html=response.text dom=etree.HTML(html) textBD=dom.xpath('//ul[@class="ul1"]/li/text()') print("查询的ip地址为:"+ip) print(textBD) except: print("出现异常")

