一直爬虫的自我修养~~~!!!
*Python如何访问互联网
使用python的内置电池【url+lib=urllib】》》他是一个包
使用urlopen访问网页
实战一,从网站上下载一张猫的图片‘

这俩个实际是一样的,正常话传字符串会简单,但是对于好多爬虫我们需要修改head等等,只能使用Request了,string办不到

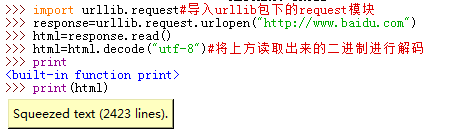
对于response我们还可以用
*geturl()
访问的链接地址
*info()
http远程对象..
*getcode()
访问状态
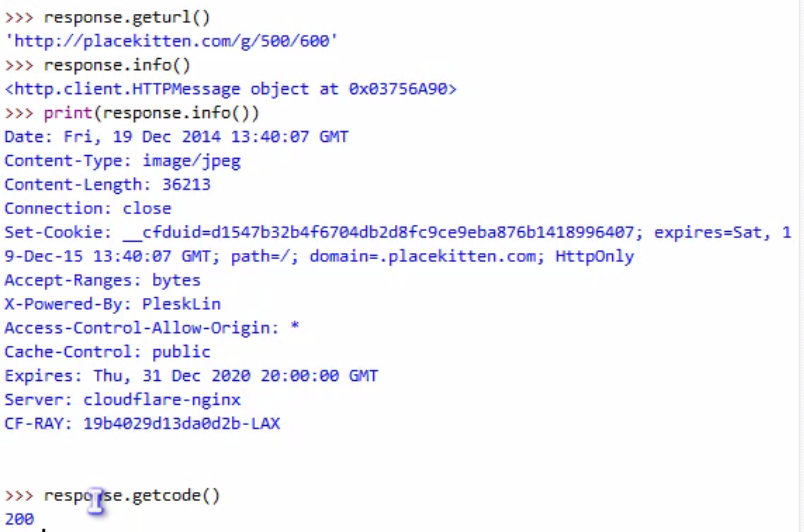
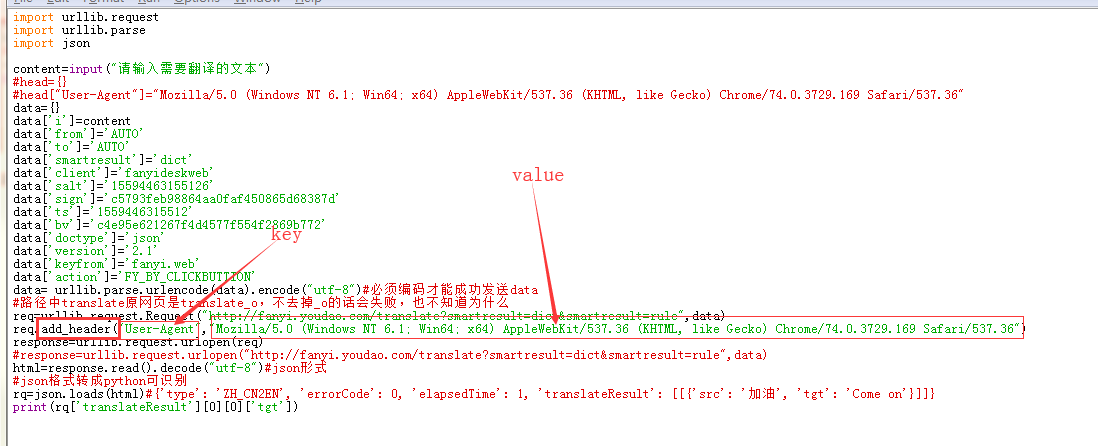
实战二,通过python获取有道网址,在python上进行翻译
在【审查元素】的network下找我发起请求,在那里获取网站工作的地址等信息
#过程就是访问链接,包装文本,改变用户代理,开始访问,回应解析,调用j变成可解析,输出
隐藏/看起来更像浏览器访问

1)修改User-Agent #在request生成之前加入,直接在Request加

2)修改User-Agent #在request生成之后加入Request下的add_header,个人觉得写这个!!
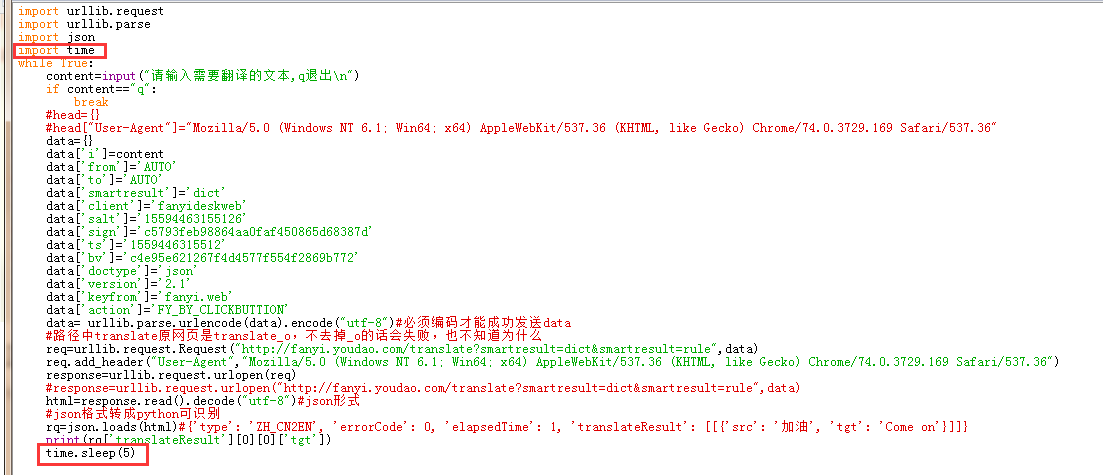
正常人浏览网页不可能像爬虫一样一秒钟上百个下载等等,目前解决方案,俩种,1.延迟提交2.代理!!!
1.延迟提交
2代理!!!
原理就是我每次访问随即使用一个非我自己的ip,让那个IP访问将结果给我


import urllib.request import random #url='http://www.whatismyip.com.tw' url='http://ip.tool.chinaz.com/' #url="http://www.baidu.com" #https://www.kuaidaili.com/free/inha/这个网站下有好多代理ip #下面是代理的流程,首先随机ip,然后创建opener并改变用户代理,最后安装这个代理,安装好了之后我们使用urllib.request就会以代理的ip来访问 iplist=["163.204.241.233:9999",'182.34.34.181:9999','163.204.245.246:9999',"222.135.28.235:8060"] proxuy_support=urllib.request.ProxyHandler({"HTTP":random.choice(iplist)})#HTTP需要大写,小写连接不上 我擦... opener=urllib.request.build_opener(proxuy_support) opener.addheaders=[("User-Agent","Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36")] urllib.request.install_opener(opener) response=urllib.request.urlopen(url) html=response.read() print(html)
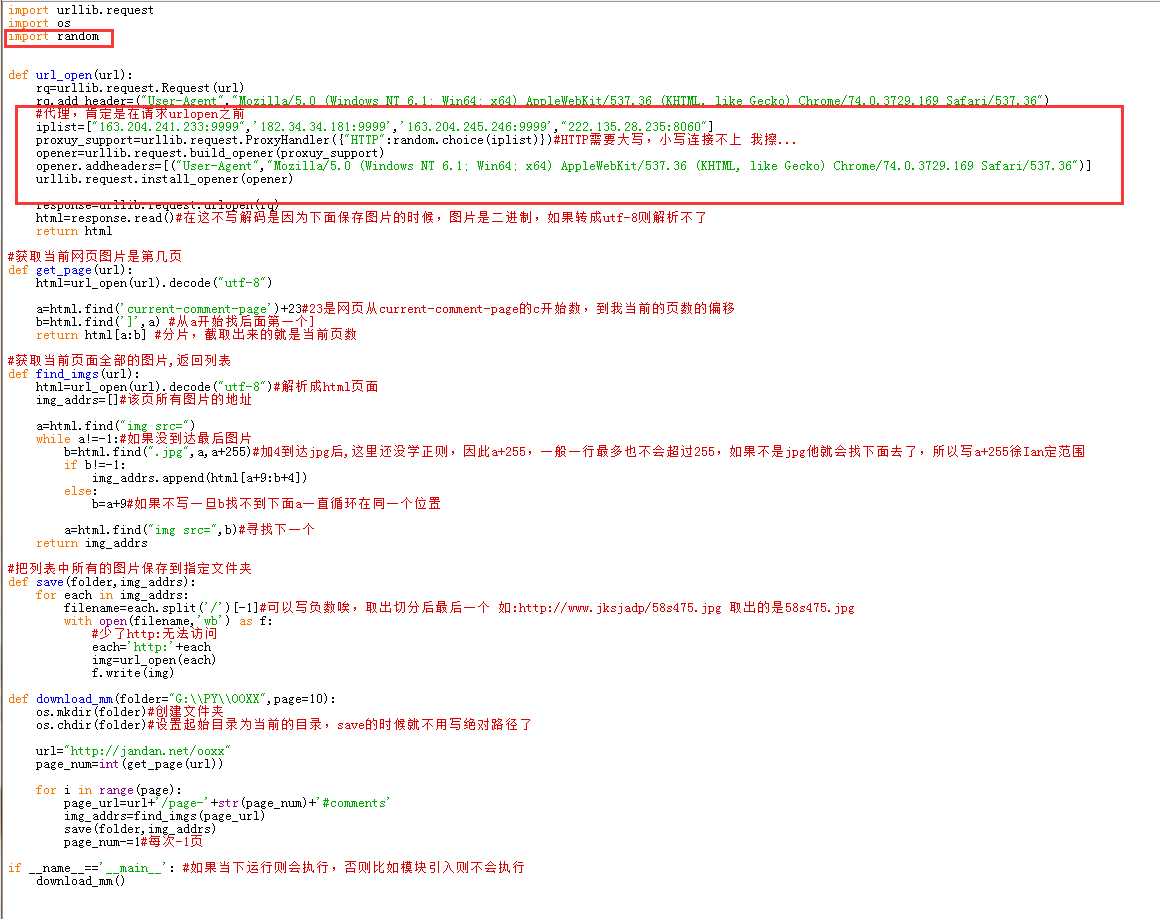
爬图片,这里引用的是和小甲鱼视频一样的网站,可能内容有点劲爆,下面代码,可用~!!
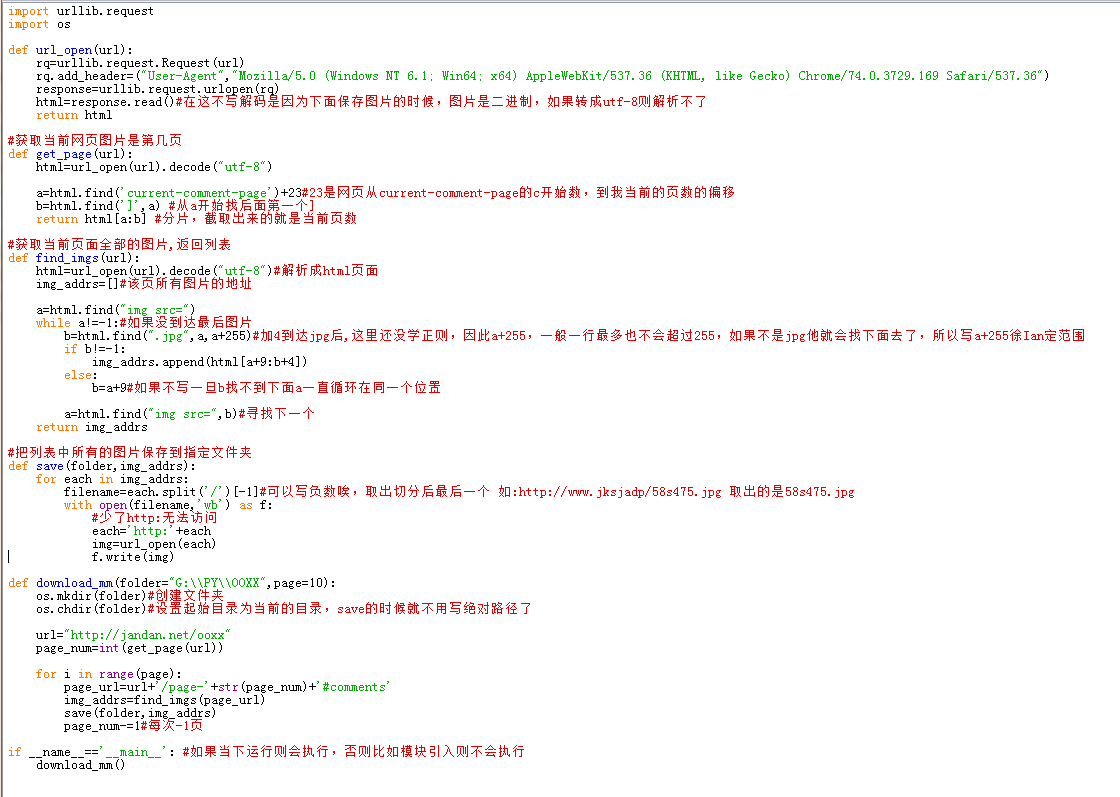
import urllib.request import os def url_open(url): rq=urllib.request.Request(url) rq.add_header=("User-Agent","Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36") response=urllib.request.urlopen(rq) html=response.read()#在这不写解码是因为下面保存图片的时候,图片是二进制,如果转成utf-8则解析不了 return html #获取当前网页图片是第几页 def get_page(url): html=url_open(url).decode("utf-8") a=html.find('current-comment-page')+23#23是网页从current-comment-page的c开始数,到我当前的页数的偏移 b=html.find(']',a) #从a开始找后面第一个] return html[a:b] #分片,截取出来的就是当前页数 #获取当前页面全部的图片,返回列表 def find_imgs(url): html=url_open(url).decode("utf-8")#解析成html页面 img_addrs=[]#该页所有图片的地址 a=html.find("img src=") while a!=-1:#如果没到达最后图片 b=html.find(".jpg",a,a+255)#加4到达jpg后,这里还没学正则,因此a+255,一般一行最多也不会超过255,如果不是jpg他就会找下面去了,所以写a+255徐Ian定范围 if b!=-1: img_addrs.append(html[a+9:b+4]) else: b=a+9#如果不写一旦b找不到下面a一直循环在同一个位置 a=html.find("img src=",b)#寻找下一个 return img_addrs #把列表中所有的图片保存到指定文件夹 def save(folder,img_addrs): for each in img_addrs: filename=each.split('/')[-1]#可以写负数唉,取出切分后最后一个 如:http://www.jksjadp/58s475.jpg 取出的是58s475.jpg with open(filename,'wb') as f: #少了http:无法访问 each='http:'+each img=url_open(each) f.write(img) def download_mm(folder="G:\\PY\\OOXX",page=10): os.mkdir(folder)#创建文件夹 os.chdir(folder)#设置起始目录为当前的目录,save的时候就不用写绝对路径了 url="http://jandan.net/ooxx" page_num=int(get_page(url)) for i in range(page): page_url=url+'/page-'+str(page_num)+'#comments' img_addrs=find_imgs(page_url) save(folder,img_addrs) page_num-=1#每次-1页 if __name__=='__main__': #如果当下运行则会执行,否则比如模块引入则不会执行 download_mm()
使用代理,下载的不仅仅是我们本网站这些图片,原因是什么,等下再说哦~~~