jemalloc内存分配原理【转】
原文:http://www.cnblogs.com/gaoxing/p/4253833.html
内存分配是面向虚拟内存的而言的,以页为单位进行管理的,页的大小一般为4kb,当在堆里创建一个对象时(小于4kb),会分配一个页,当再次创建一个对象时会判断该页剩余大小是否够,够的话使用该页剩余的内存,减少系统调用。真实的内存分配算法比这个复杂了,效率不好的内存算法会导致出现很多内存碎片。
内存分配的核心思想概括起来有3条
1:首先讲内存区(memory pool)以最小单位(chunk)定义出来 ,然后区分对象大小分别管理内存,小内存定义不同的规格(bins),根据不同的bin分配固定大小的内存块,并用一个表
管理起来,大对象则以页为单位进行管理,配合小对象所在的页,降低碎片,设计一个好的存储方案(metadata)减少对内存的占用,同时优化内存信息的存储。以使对每个bin或大内存区域的访问性能最优且有上限。
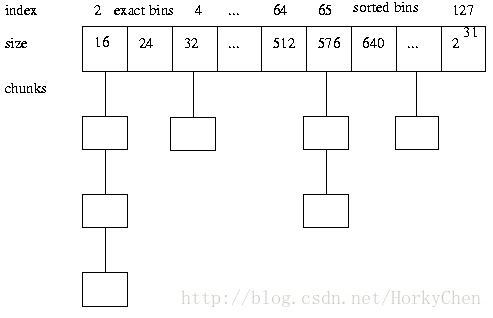
2:当释放内存时,要能够合并小内存为大内存,该保留的保留下次可快速响应,不该保留的释放给系统
3:多线程环境下,每个线程可以独立的占有一段内存区间(TLS),这样线程内操作可以不加锁
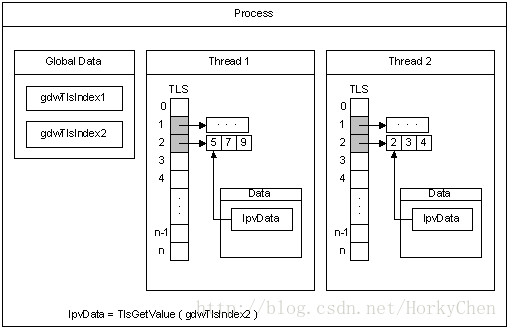
jemalloc是freebsd的内存分配算法,他的layout如下:
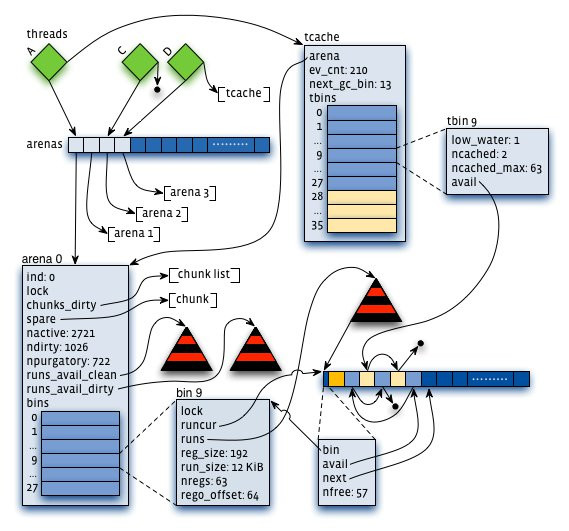
1:arena:把内存分成许多不同的小块来分而治之,该小块便是arena,让我们想象一下,给几个小朋友一张大图纸,让他们随意地画点。结果可想而知,他们肯定相互顾忌对方而不敢肆意地画(synchronization),从而影响画图效率。但是如果老师事先在大图纸上划分好每个人的区域,小朋友们就可以又快又准地在各自地领域上画图。这样的概念就是arena。它是jemalloc的核心分配管理区域,对于多核系统,会默认分配4*cores个arena 。线程采用轮询的方式来选择响应的arena进行内存分配。
2: chunk。具体进行内存分配的区域,默认大小是4M,chunk以page为单位进行管理,每个chunk的前6个page用于存储后面page的状态,比如是否分配或已经分配
3:bin:用来管理各个不同大小单元的分配,比如最小的Bin管理的是8字节的分配,每个Bin管理的大小都不一样,依次递增。
4:run:每个bin在实际上是通过对它对应的正在运行的Run进行操作来进行分配的,一个run实际上就是chunk里的一块区域,大小是page的整数倍,具体由实际的bin来决定,比如8字节的bin对应的run就只有1个page,可以从里面选取一个8字节的块进行分配。在run的最开头会存储着这个run的信息,比如还有多少个块可供分配。
5:tcache。线程对应的私有缓存空间,默认是使用的。因此在分配内存时首先从tcache中找,miss的情况下才会进入一般的分配流程。
arena和bin的关系:每个arena有个bin数组,每个bin管理不同大小的内存(run通过它的配置去获取相应大小的内存),每个tcahe有一个对应的arena,它本身也有一个bin数组(称为tbin),前面的部分与arena的bin数组是对应的,但它长度更大一些,因为它会缓存一些更大的块;而且它也没有对应的run的概念
chunk与run的关系:chunk默认是4M,而run是在chunk中进行实际分配的操作对象,每次有新的分配请求时一旦tcache无法满足要求,就要通过run进行操作,如果没有对应的run存在就要新建一个,哪怕只分配一个块,比如只申请一个8字节的块,也会生成一个大小为一个page(默认4K)的run;再申请一个16字节的块,又会生成一个大小为4096字节的run。run的具体大小由它对应的bin决定,但一定是page的整数倍。因此实际上每个chunk就被分成了一个个的run。
内存分配的,具体流程如下:
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号