kafka知识
1 kafka简单介绍
kafka是一款分布式、支持分区的、多副本,基于zookeeper协调的分布式消息系统。最大的特性就是可以实时处理大量数据来满足需求。特点是生产者消费者模式,先进先出(FIFO)保证顺序,自己不丢数据,默认每隔7天清理数据。
https://blog.csdn.net/hyj_king/article/details/105710993
2 kafka使用场景
1,日志收集:可以用kafka收集各种服务的日志 ,通过已统一接口的形式开放给各种消费者。
2,消息系统:解耦生产和消费者,缓存消息。
3,用户活动追踪:kafka可以记录webapp或app用户的各种活动,如浏览网页,点击等活动,这些活动可以发送到kafka,然后订阅者通过订阅这些消息来做监控。
4,运营指标:可以用于监控各种数据。
3 kafka基本概念
Kafka中发布订阅的对象是topic。我们可以为每类数据创建一个topic,把向topic发布消息的客户端称作producer,从topic订阅消息的客户端称作consumer。Producers和consumers可以同时从多个topic读写数据。一个kafka集群由一个或多个broker服务器组成,它负责持久化和备份具体的kafka消息。
kafka是一个分布式的分区的消息,提供消息系统应该具备的功能。
- broker 消息中间件处理节点,一个broker就是一个kafka节点,多个broker构成一个kafka集群。
- topic kafka根据消息进行分类,发布到kafka的每个消息都有一个对应的topic
- producer 消息生产(发布)者
- consumer 消息消费(订阅)者
- consumergroup 消息订阅集群,一个消息可以被多个consumergroup消费,但是一个consumergroup只有一个consumer可以消费消息。
Offsetoffset绑定每一个消息,对于消息在分区中的位置,我们将offset称为“偏移量”;对于消费者消费到的位置,将 offset 称为“位移”,有时候也会更明确地称之为“消费位移”。
Offset在Zookeeper中由一个专门节点进行记录,其节点门路为:
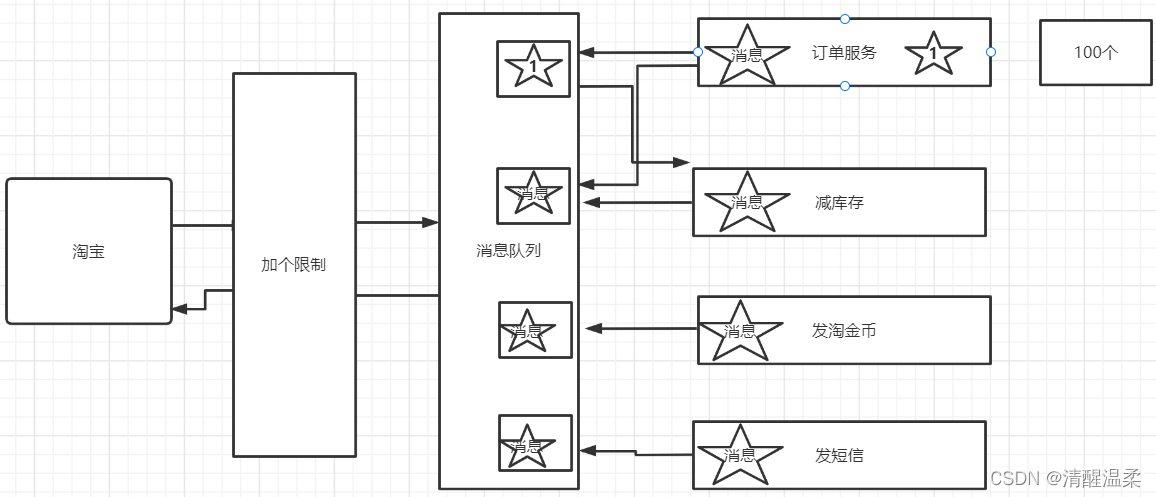

4 kafka集群
https://blog.csdn.net/lzxlfly/article/details/80672284
https://blog.51cto.com/u_13941177/2175653
与生产者的交互
生产者在向kafka集群发送消息的时候,可以通过指定分区来发送到指定的分区中,也可以通过指定均衡策略来将消息发送到不同的分区中,如果不指定,就会采用默认的随机均衡策略,将消息随机的存储到不同的分区中

与消费者的交互
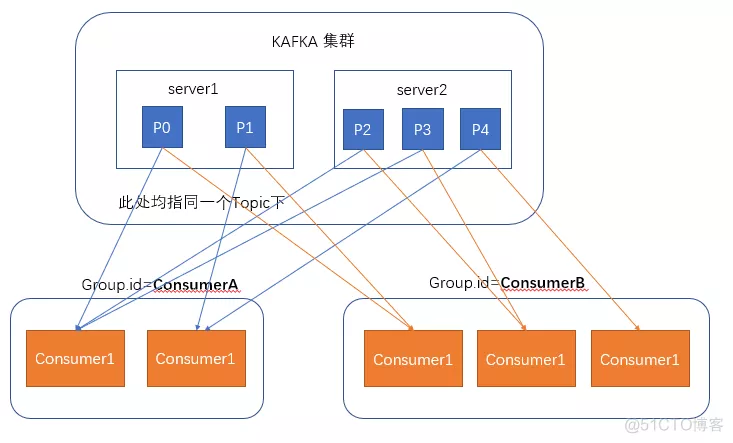
在消费者消费消息时,kafka使用offset来记录当前消费的位置,在kafka的设计中,可以有多个不同的group来同时消费同一个topic下的消息,如图,我们有两个不同的group同时消费,他们的的消费的记录位置offset各不项目,不互相干扰。
5 kafka消息丢失原因及解决方案
https://blog.csdn.net/YoungJ_Zhou/article/details/125605128
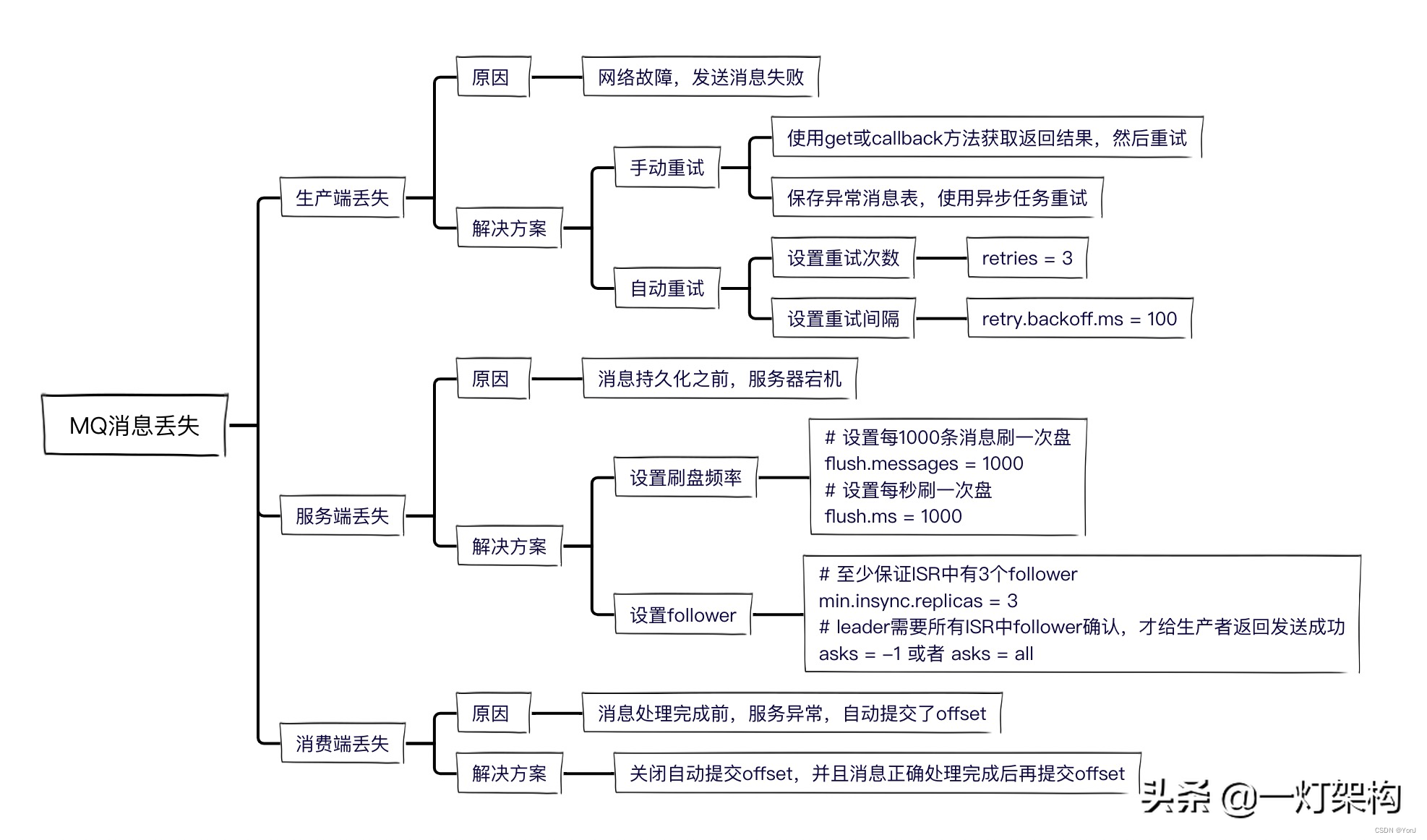
5.1 生产过程丢失消息
丢失原因:一般可能是网络故障,导致消息没有发送出去。
解决方案:重发就行了。
如果发送失败了,有两种重试方案:
- 手动重试 在catch逻辑或else逻辑中,再调用一次send方法。如果还不成功怎么办? 在数据库中建一张异常消息表,把失败消息存入表中,然后搞个异步任务重试,便于控制重试次数和间隔时间。
- 自动重试 kafka支持自动重试,设置参数如下,当集群Leader选举中或者Follower数量不足等原因返回失败时,就可以自动重试。
- # 设置重试次数为3
retries = 3# 设置重试间隔为100msretry.backoff.ms = 100 - 一般我们不会用kafka自动重试,因为超过重试次数,还是会返回失败,还需要我们手动重试。
5.2 服务端持久化过程丢失消息
为了保证性能,kafka采用的是异步刷盘,当我们发送消息成功后,Broker节点在刷盘之前宕机了,就会导致消息丢失。
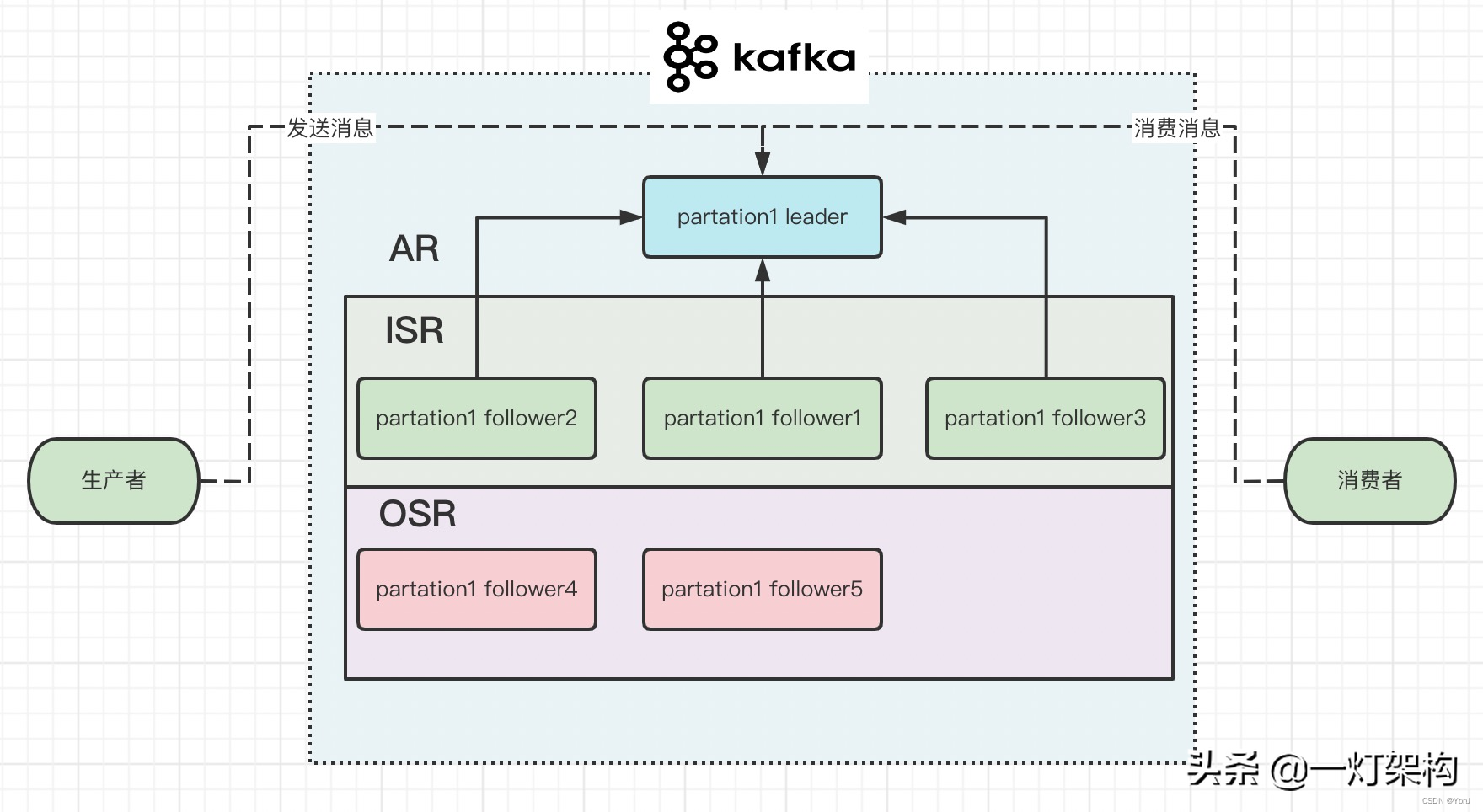
kafka为了加快持久化消息的性能,把性能较好的follower组成一个ISR列表(in-sync replica),把性能较差的follower组成一个OSR列表(out-of-sync replica),ISR+OSR=AR(assigned repllicas)。 如果某个follower一段时间没有向leader拉取消息,落后leader太多,就把它移出ISR,放到OSR之中。 如果某个follower追上了leader,又会把它重新放到ISR之中。 如果leader挂掉,就会从ISR之中选一个follower做leader。
5.3 消费过程丢失消息
kafka中有个offset的概念,consumer从partition中拉取消息,consumer本地处理完成后需要commit一下offset,表示消费完成,下次就不会再拉取到这条消息。
所以我们需要关闭自动commit offset的配置,防止consumer拉到消息后,服务宕机,导致消息丢失。
6 数据同步机制
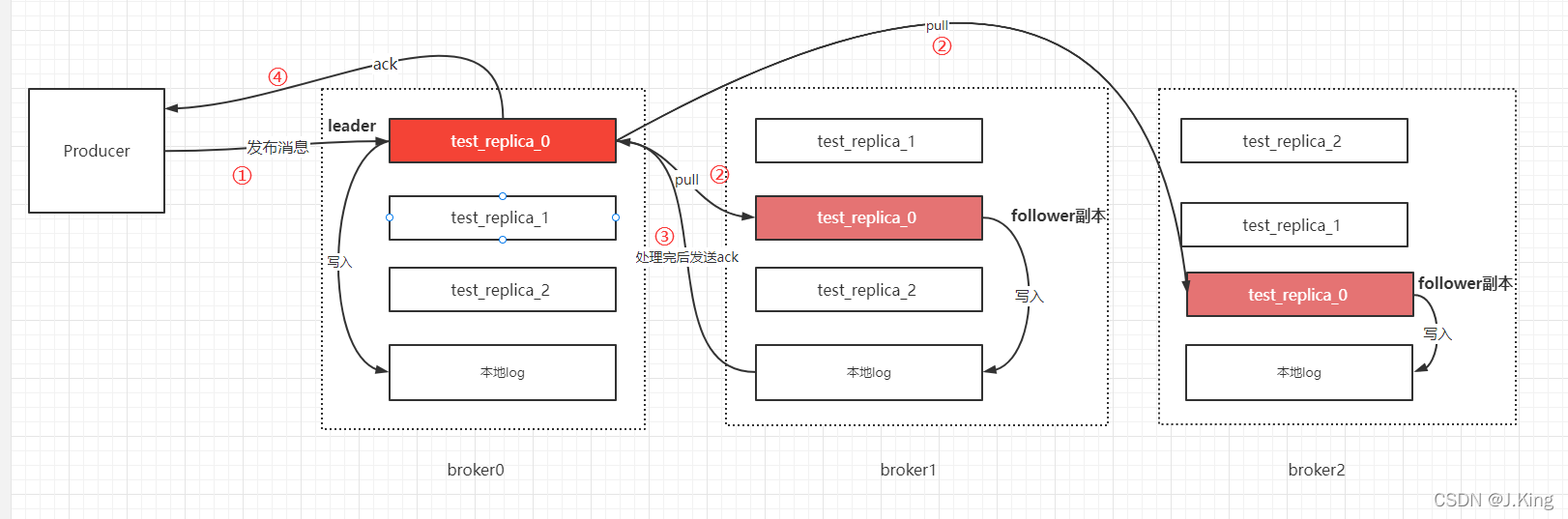
资源:
https://blog.csdn.net/weixin_64881460/article/details/123974331
https://blog.csdn.net/u011109589/article/details/124920047

 浙公网安备 33010602011771号
浙公网安备 33010602011771号