MongoDB介绍
1 MongoDB介绍
MongoDB 是免费开源的跨平台 NoSQL 数据库,命名源于英文单词 humongous,意思是「巨大无比」,可见开发组对 MongoDB 的定位。与关系型数据库不同,MongoDB 的数据以类似于 JSON 格式的二进制文档存储:
{ name: "Angeladady", age: 18, hobbies: ["Steam", "Guitar"] }
文档型的数据存储方式有几个重要好处:文档的数据类型可以对应到语言的数据类型,如数组类型(Array)和对象类型(Object);文档可以嵌套,有时关系型数据库涉及几个表的操作,在 MongoDB 中一次就能完成,可以减少昂贵的连接花销;文档不对数据结构加以限制,不同的数据结构可以存储在同一张表
2 数据操作
查询数据库 show databases 切换数据库 use test 查询当前数据库下面的集合 show collections 创建集合 db.createCollection("集合名称") 删除集合 db.集合名称.drop() 删除数据库 db.dropDatabase() //首先要通过use切换到当前的数据库
Mongodb增删改查(CURD)
id 系统会自动加一个
时间戳+机器码 生成
2 mongodb集群
复制提供了数据的冗余备份,并在多个服务器上存储数据副本,提高了数据的可用性, 并保证数据的安全性。
主从复制集群
主从复制只有 1 个主节点,至少有 1 个从节点,可以有多个从节点。它们的身份是在启 MongoDB数据库服务时就需要指定的。所有的从节点都会自动地去主节点获取最新数据,做到主从节点数据保持一致。注意主节点是不会去从节点上读取数据的,只会输出数据到从节点。理论上 1 个集群中可以有无数个从节点,但是这么多的从节点对主节点进行访问,主节点会受不了。《MongoDB 权威指南》中有说不超过 12 个从节点的集群就可以运作良好。
工作原理
复制集中主要有三个角色:主节点(primary)、从节点(secondary)、仲裁者(非必需)。要组建复制集集群至少需要两个节点,主节点和从节点都是必需的,主节点负责接受客户端的请求写入数据等操作,从节点则负责复制主节点上的数据,也可以提供给客户端读取数据的服务。仲裁者则是辅助投票修复集群。
复制集要完成数据复制以及修复集群依赖于两个基础的机制: oplog (operation log,操作日志)和心跳 (heartbeat)。oplog 让数据的复制成为可能,而“心跳”则监控节点的健康情况并触发故障转移。
在 Mongodb 里面存在另一种集群,就是分片技术,可以满足 MongoDB 数据量大量增长的需求。这类似于mysql中的分库分表。当 MongoDB 存储海量的数据时,一台机器可能不足以存储数据,也可能不足以提供可接受的读写吞吐量。这时,我们就可以通过在多台机器上分割数据,使得数据库系统能存储和处理更多的数据。
分片集群可以有效解决性能瓶颈及系统扩容问题,但是分片额外消耗较多,管理复杂,能不分片尽量不要分。
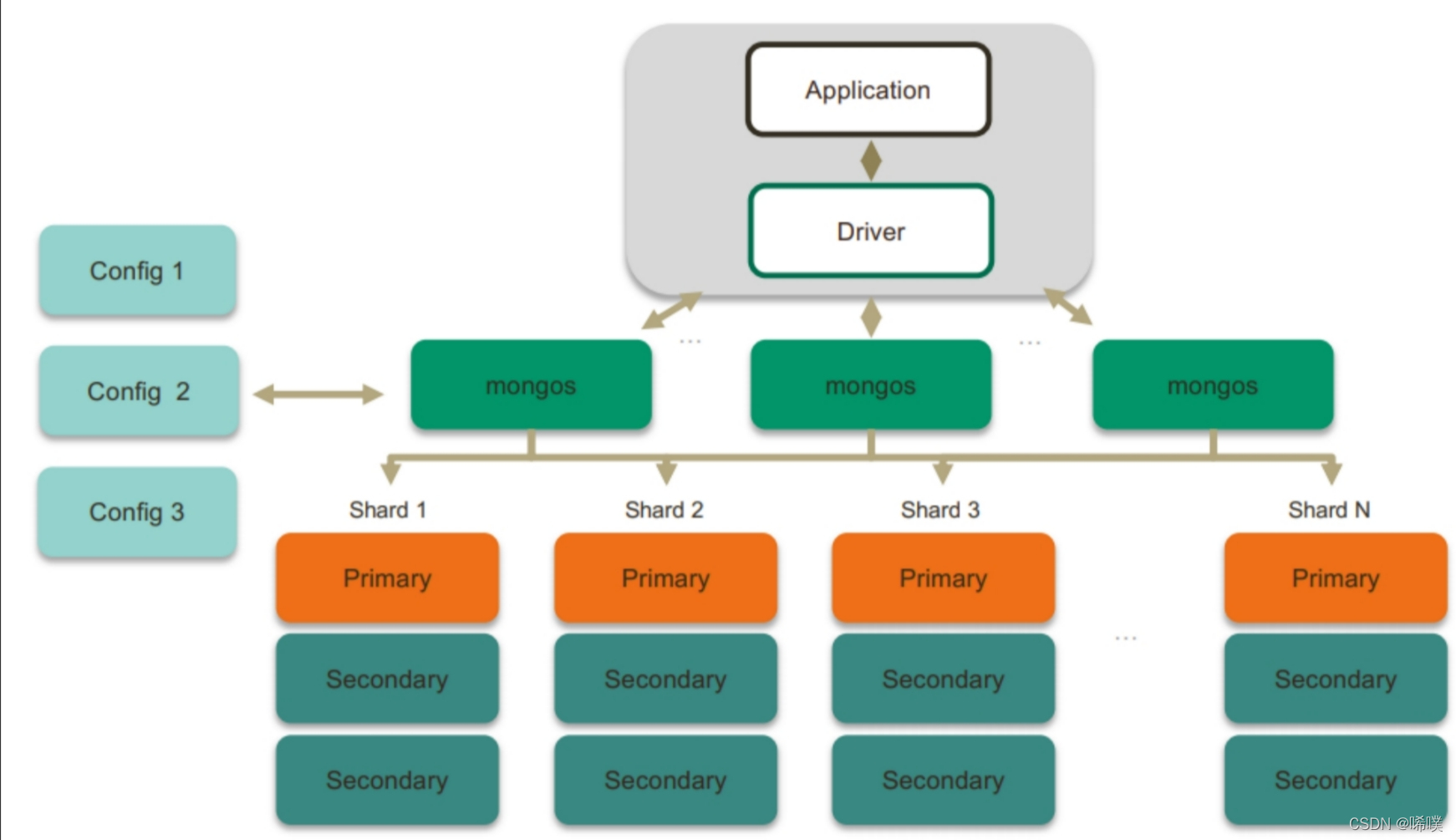
以HSBC为例:1台(primary),5台(secondary).
资源
https://segmentfault.com/a/1190000010556670
https://baijiahao.baidu.com/s?id=1709426775094926497&wfr=spider&for=pc

 浙公网安备 33010602011771号
浙公网安备 33010602011771号